Collaborative Large Language Model for Recommender Systems (WWW 2024)

INTRODUCTION
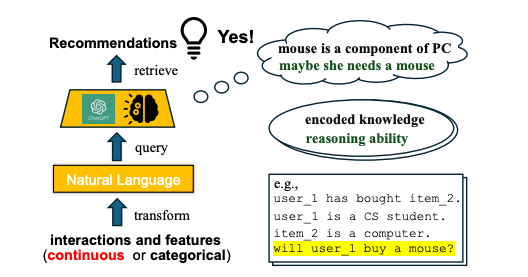
- 현재 Recommender System(RS)는 ID-based
- History, Interaction 기반 embedding model
- LLM은 textual features, biograph, description, content, review, explanation이 모두 가능
- LLM을 활용한 선행 연구는 크게 two step으로 요약됨
- ID Embedding 대신, context 정보를 통해 user, item 정보를 전달
- 정보를 바탕으로 recommendation을 textual output으로 retrive (zero-shot)
- GT가 존재할 경우, pretrained model에 update
- 그럼에도, NL과 user/item semantics와의 gap이 존재함
- user_i, item_j 등으로 psuedo-ID를 만드는 방법이 존재하지만, LLM은 이를 다 tokenizing하기에 break down될 가능성이 있음
- Description based method는 item title, 소량의 user, item token을 사용할 수 있지만, 강한 inductive bias로 실제 bias가 희소화됨
- 또한 interaction based는 시간 순서가 무시되지만, NL은 시간이 고려되야 하기에 자연스럽게 시간에 관련된 bias가 생성될 수 있으며, LLM의 특성상 필요없는 NL의 noise가 포함될 수 있음
- 우리의 CLLM4Rec은 Pretraining 단계에서 사용자/아이템 token을 soft token으로, 나머지 contextual information을 hard token으로 분리하고 두 LLM이 각각 예측하게 하여 ID를 faithful하게 반영
- 또한 probabilistic sort를 통해 아이템 토큰의 순서를 무시할 수 있게 함
- Fine tuning시 pretrained LLM 백본에 multinomial likelihood를 add하여 LLM이 Auto regressive하게 item을 효과적으로 generate하게 함
METHODOLOGY
- Implicit Feedback 가정
- Xi,Xj : user i, item j의 textual information
- Xij : user i에 대한 item j의 textual information
- 이를 sequential하게 text로 concat
- item sequence는 text가 아닌 stacked self attention을 통해 latent sequence로 변환하여 input으로 변환
- LLM은 text기반으로 pretrained 되었기에, textual 정보만을 활용할 가능성을 줄임
- user/item semantic을 align함과 동시에 LLM의 추론 능력을 동시에 확보
Extension of User/Item Tokens
Vocab Expansion
- <user_i>, <item_j> 등 bracket notation을 통해 새로운 token 생성
Token Embeddings
- 초기 임베딩이 contents와 collaboratrive 정보를 동시에 함유할 수 있도록, prior precision에서 conditional precision을 계산하는 방법으로 samling
CLLM4Rec Base Model
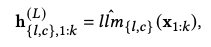
- xk는 vocab, user, item을 one hot encoding한 token
- llml,c는 각각 user/item token에만 trainable하며, vocab embedding은 다른 backbone LLM을 통해 수행됨
Mutually-Regularized Pretraining
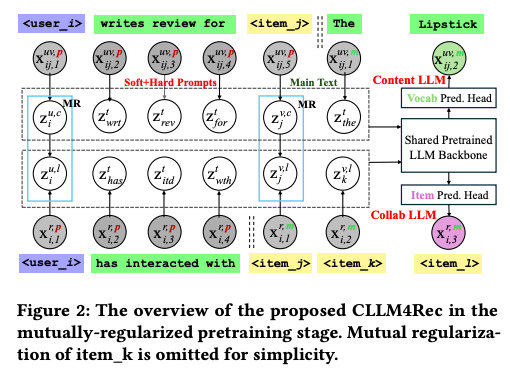
- user/item, context를 모두 반영하기 위한 pretraining stage
Recommendation-Specific Corpora

- 다음과 같은 형식으로 formulation 됨, 다만 원시 vocab에서 language modeling을 수행하는 것은 어려움 (user/item token의 semantic이 align되어 있지 않음)
Soft+Hard Prompting
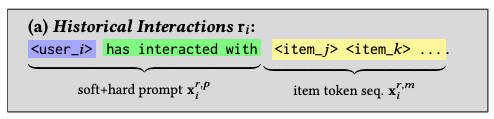
- 위 challenge를 해결하기 위한 soft+hard prompting
- 위 figure에서 ri와 xi,x_j,x{ij}$의 두 개로 분리할 수 있음
- 전자는 soft, hard token이 이질적, 후자는 동질적
- 따라서, 단순히 main text (item token들) 에만 Language modeling을 하여 베타적으로 학습하게 함
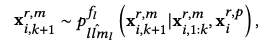
- 이후 last hidden state에 softmax하여 다음 item을 prediction하는 layer를 사용해 user와 상호작용한 item들 간의 embedding을 유사하게 함
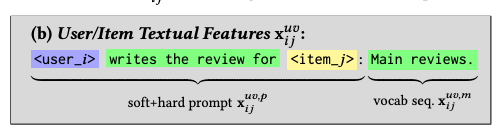
- 비슷하게, document도 heterogeneous한 soft+hard prompt와 homogeneous한 vocab token으로 split할 수 있음, 이를 통해 hidden state를 통해 다음 vocab을 예측하게 함으로써 content 정보를 함유하게 함

- 그 예시로, content LLM은 item의 context와 user의 context를 인지할 것
Discussion
- Hard token들은 pretrained LLM이 잘 이해할 수 있도록 설계되어 있음
- 새로운 phrase "has interacted with"는 user가 사용자 주체임을 이해하게 할 것
- 또한 "write the review for"은 content LLM에게 본문의 본질을 더 잘 이해하게 할 것
- phrase는 바뀔 수 있으며, 중요한 것은 일관성있게 유지하는 것임
Mutually-Regularization

- LLM의 inductive bias는 recommendation에 적합하지 않음
- sparse한 data 특성상 overfitting 가능성이 높음
- 우리의 mutually-regularization은 collaborative LLM이 recommendation-oriented information을 content LLM에게 전달하고, content LLM이 side information을 collaborative LLM에게 전달하도록 함
- 위 수식은 3가지 part
- Language modeling for collaborative, content LLM
- mutual regularization that connect user/item token to two LLM
- prior
