Reindex-Then-Adapt: Improving Large Language Models for Conversational Recommendation (preprint)
Paper Review
목록 보기
47/51

Introduction
- Conversational Recommender System(CRS) Task에서 LLM의 강점이 대두
- 특히 Context knowledge에서 강점을 가진 다는 것이 증명됨
- 우리는 CRS에서 LLM을 사용하는 Task를 Differential Search Index(DSI)로 간주
- 여기서 Ability와 Limitation을 발견
- Ability: LLM은 대부분의 popular movie를 indexing할 수 있으며, 복잡한 conversation context를 이해할 수 있음
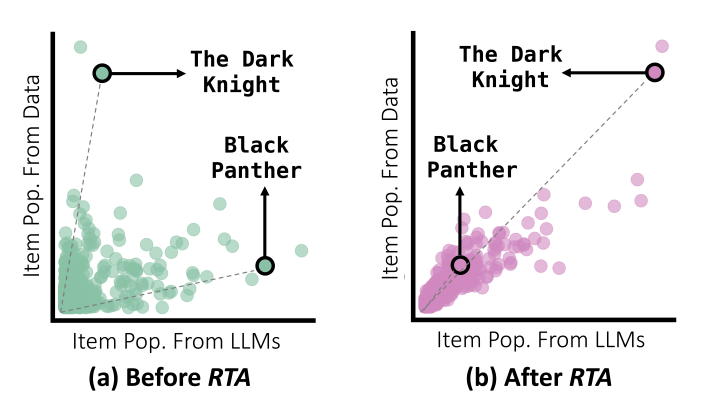
- Limitation: Data ditribtion에서 misalignment를 보임 (figure를 보면 population이 다름)
- 우리는 LLM의 Target Dstn을 조정하는 것으로 misalignment를 개선하려 함
- 이를 통해 CRS의 accuracy를 improve하며 controllability와 fairness를 가져옴
* 그러나 이를 LLM에 적용하기에는 여러 문제가 존재하는데, 전통적인 Recsys 모델과 달리, Logit Vector가 단일 벡터가 아닌 여러 단어 token의 결합임
- 이를 통해 CRS의 accuracy를 improve하며 controllability와 fairness를 가져옴
- 이를 해결하기 위해 framework를 제안
- Reindex Step: multi-token item title을 single token으로 변환
- Adapt Step: single token의 logit을 바탕으로 dstn을 변환
- 기깔나는 성능을 보여줌
Preliminaries
Differential Search Index
- Transformer architecture가 retrieval task에 적합하다는 것을 보여준 DSI
- 여기서 Learn to Index(L2I)와 Learn to Retrieve(L2R)를 Recommendation에 적합하게 변환


- 다음과 같이 description을 통해 item을 Indexing
- Conversational context를 Query로 recommendation item을 generate(retrive)
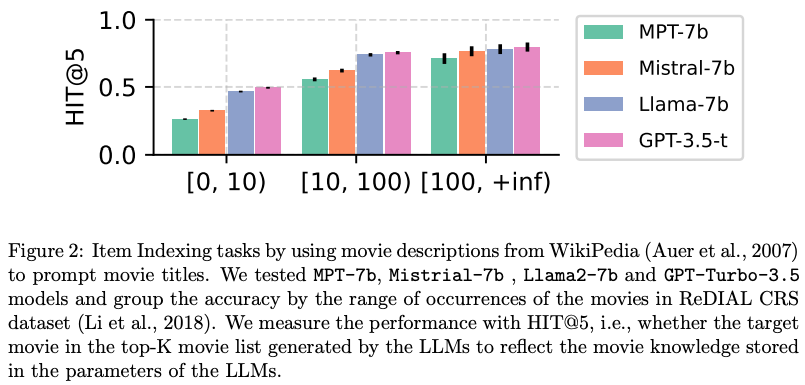
Item Indexing: LLMs Show Sufficient Item Content Knowledge
Observation
- ReDIAL로부터 6,281 pair를 수집해 연관된 wikipedia description을 통해 실험
Good Content Knowledge for Popular Items
- CRS에 존재하는 대부분의 영화를 Indexing하는데 성공
- 특히 popular movie의 경우, 대부분 indexing
Best LLMs
- GPT-3.5-t가 가장 우수
- Open source LLM의 경우 Llama2가 가장 우수하여, 실험의 base model로 선정
Impact
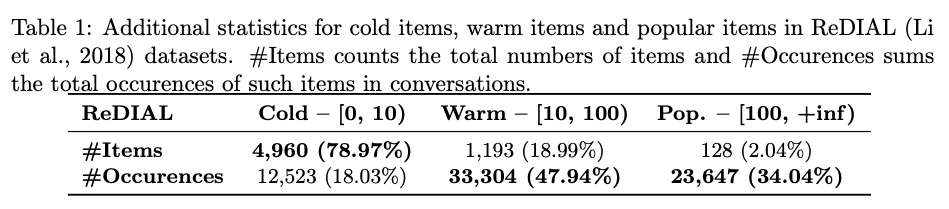
- LLM은 특별한 fine tuning 없이도 Indexing capability를 보유
- 표를 보면, Warm과 Pop item이 추천의 대다수를 차지함
- 현재의 Indexing 능력 만으로도 추천하는데에는 충분
- Cold Item은 future work로 남겨둠
Item Recommendation: LLMs Show Severe Distribution Misalignment
Observation
- LLM이 training중 얻은 Data dstn이 CRS의 target dstn과 일치하지 않음
Static Perspective
- 정적인 관점에서, 아이템의 인기도를 일부 반영하나 틀린 경우가 잦음
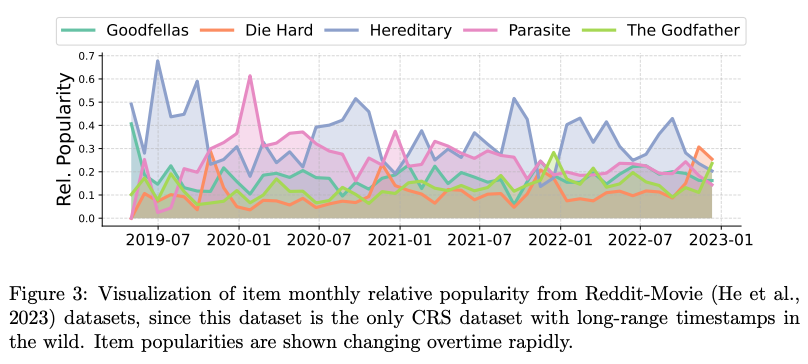
Dynamic Perspective
- Item 인기는 계절, promotion등에 의해 빠르게 변화함 (figure 3)
- 이는 Static LLM or finetuned LLM으로도 포착할 수 없음
Impact
- 분포의 불일치는 존재
- 이는 LLM이 CRS에서 분포를 align할 수 있다면 성능 향상의 여지가 있음을 시사
- 추천 플랫폼의 동적 특성으로 인해 target dstn은 빠르게 변하므로, 이를 조정하기 위한 효율적인 방법이 요구됨
Framework
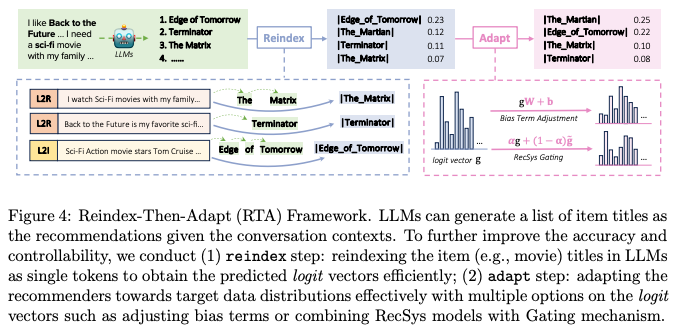
Overview
- Section 1에서, 우리는 varying token counts가 Rec dstn을 조정하는데 challenge임을 명시함
- 이를 다루기 위해, 이미 Indexing하는 능력은 충분하다고 보고 single token으로 Reindexing하는 작업을 수행
- 이후 재인덱싱 된 LLM의 Logit을 target dstn에 맞게 조정 (Logit vector 변환 및 Gating mechanism 사용)
Reindex Step: Single-Token Items in LLMs
- Reindexing의 핵심은 여러 토큰의 아이템 임베딩을 단일 토큰 아이템 임베딩으로 압축하는 것 + LLM generation에서 원래의 semantic을 보존하는 것
Identify Item Indices

-
- vocab으로 구성된 sentence (총 m개의 token)
- j는 아이템의 시작 토큰이며, n은 이 아이템을 나타내는 token의 수
- LLM을 통해 Embedding
Aggregate Multi-Token Embeddings

- aggregate된 embedding을 새로운 representation으로 사용
- RNN, Transformer 기반 모델을 aggregater로 사용 가능
Learning Process
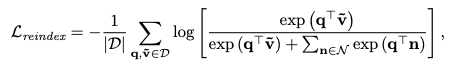
- negative sample을 준비해 contrastive loss 사용
- 원래 인덱싱된 아이템의 첫 번째 토큰을 생성하는 데 사용된 마지막 위치의 context embedding
- 여기서 우리는 aggregate 된 item embedding을 사용
- 학습 시에는 2가지 corpus 사용
- L2R: (query, target item) pair이며 conversation에서 나옴
- L2I: (content, target item) pair이며, content는 meta data와 같은 textual description에서 나옴
Adapt Step: Item Probabilities Adjustment
- 재인덱싱을 통해 표현된 단일 토큰 임베딩을 사용하여 one-step decoding을 가능케 함
- 2개의 adaptation method를 제안
- 위에서 얻은 logit vector
- probability vector는
Bias Term Adjustment
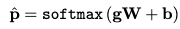
- affine transformation
-
- weight matrix
- parameter를 제한하기 위해 diagonal로 설정
- bias term
Trditional RecSys Gating
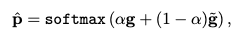
- LLM이 lack한 collborative information을 target
- tilda는 traditional Recsys model로부터 얻은 vector
- 는 0과 1사이에서 조절 가능한 값
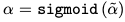
- 본 실험에서는 다음과 같이 learnable scalar로 설정했지만, 내부에 MLP 등을 넣어 learnable contextual embedding을 사용할 수도 있을 것
Learning Process
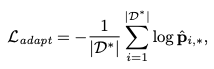
- MLE를 통해 adaptation에서의 loss를 산출 (LLM parameter를 포함하지 않음)
-
- GT dstn의 아이템 probability
Experiments

