
Abstract
SVM과 Factorization 모델을 결합한 FM이라는 모델
SVM과 마찬가지로 어떤 실수 값의 feature vector를 Input으로 받아도 잘 작동
특히, Factorized Parameter를 이용하여 sparse 한 상황에서도 Interaction을 잘 예측
SVM과 달리 dual form으로의 transformation은 필요하지 않으므로 Support Vector의 도움 없이 바로 모수를 예측할 수 있음
Introduction
SVM은 Sparse 하고 Complex 한 공간에서는 효과적인 Hyperplane을 만들어내지 못함
일반적인 Factorization model은 예측력이 떨어짐
본 논문의 새로운 모델인 FM은 범용적이며, Sparse 한 환경에서의 높은 예측력을 지님
또한 선형 방정식으로 계산되어 파라미터의 숫자에 따라 학습 시간이 결정 됨
Predict under sparsity
범주형 변수가 많을수록 데이터는 sparse해짐
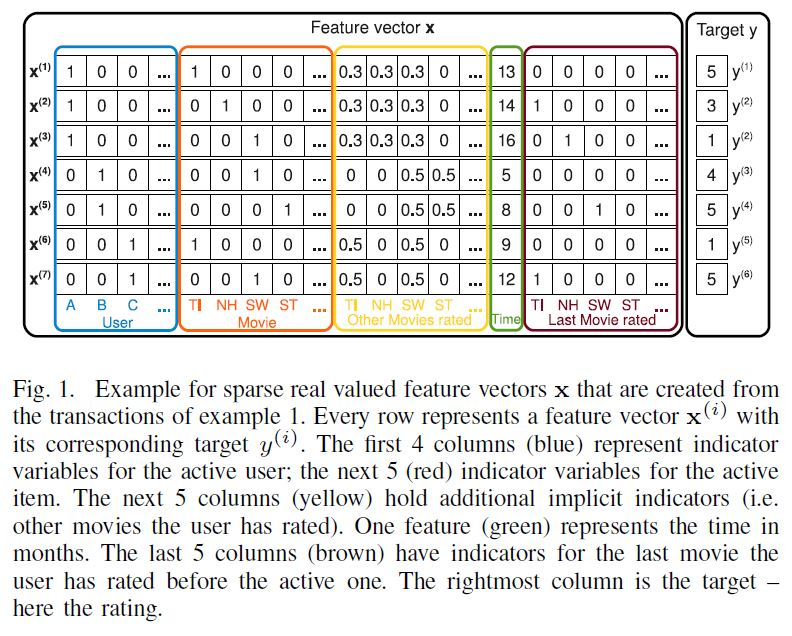
영화 평점 데이터를 가질 때, user가 특정 시점에 평점을 준 데이터를 feature vector로 생성한 것
한 행에 하나의 user, 하나의 item이 들어가며 모든 영화에 대한 평점 matrix는 normalized
Factorization Machine Model

위 식은 2차원 Factorization machine으로, 독립 변수와 종속 변수 뿐 아니라 독립변수 조합과 종속 변수 사이의 상호작용 또한 학습
- W0 : global bias
- Wi : ith weight
- Wi,j : i, j의 상호작용
- Vi : V 내부의 행으로 vi는 k개의 factor를 지닌 i번째 변수
- K : factorization의 차원
각 상호작용에 대해 factorizing 해서 사용하므로, sparse한 데이터에 잘 대처
Expressiveness

W행렬의 차원을 의미하는 k가 충분히 크다면, W에 대해 W= V dot V Transpose를 만족하는 V는 항상 존재
그러나 일반적으로 모든 Interaction을 계산하기에는 data가 충분하지 않으므로, 작은 k를 통해 일반화 성능을 높임
Parameter Estimation Under Sparsity
일반적으로 Sparse 한 데이터에서 변수간 Interaction 계산은 쉽지 않음
FM은 Interaction을 통해 Interaction을 계산하는 등의 방법으로 이에 대해 효과적으로 대처
Compute
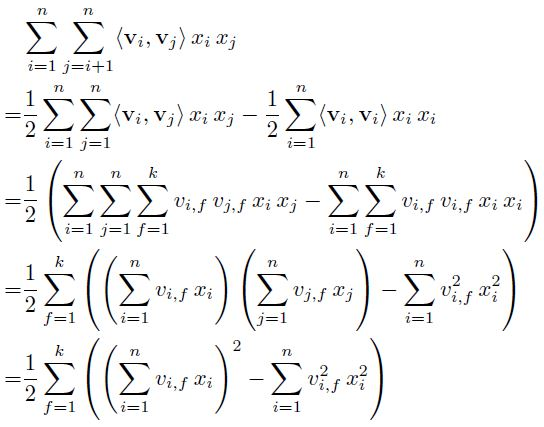
Interaction은 다음과 같은 방식으로 계산되며 X의 대부분 원소는 0이기에 실제로는 0이 아닌 원소에서만 계산이 수행 됨
Usage of Factorization Machine
- Prediction
회귀, Binary Classification, Ranking Task에서 사용 가능
Learning Factorization Machines
FM은 선형적인 모델 방정식이므로, W0, W, V 등 파라미터는 Gradient Descent 방법을 통해 학습할 수 있음
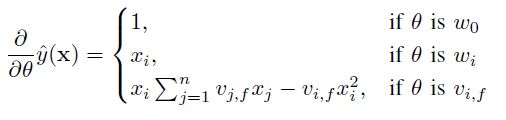
D-way Factorization Machine
FM은 d-way로 사용 가능하며 이 또한 Linear complexity를 지님
Summary
FM은 모든 feature vector 들 대신, factorized interaction을 사용해 feature vector x의 상관관계를 모델링
- 이를 통해 sparse에 잘 대응하며
- 선형화를 통해 SGD및 Loss function 최적화를 이루어 냄
