
추천 시스템 기초
개요
- 사용자의 의도가 담긴 검색 Pull (관련된 키워드로 검색)
- 사용자의 의도가 없더라도 노출 Push
- 과거에는 유저가 접할 수 있는 상품, 컨텐츠가 제한 적
- 현재는 정보의 홍수로 찾는데 시간이 오래 걸림
- 유저 본인이 어떤 키워드로 검색해야 할지 모를 수도 있음
개인화 추천
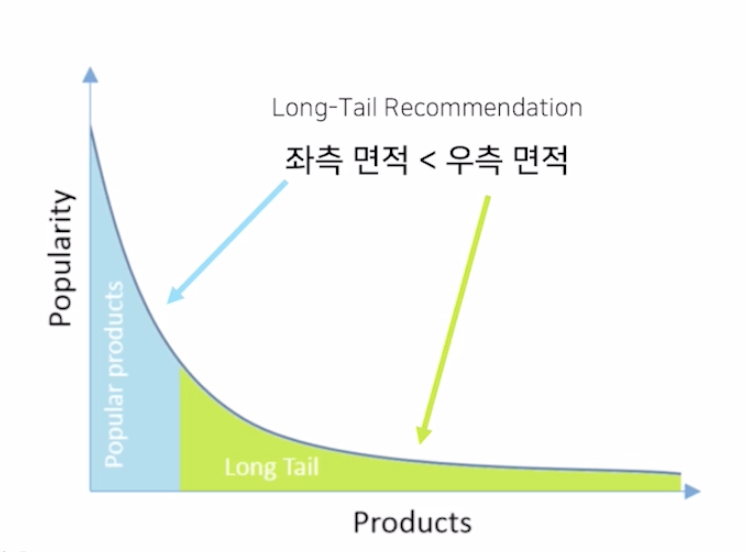
- 유튜브 동영상과 같이 조회수가 높지 않은 Long Tail의 영상을 추천
- SNS 친구 추천과 같이 수 많은 유저 중 내가 알만한 사람을 추천
데이터
유저 관련 정보
- 유저 프로파일링
- 식별자 (ID, 쿠키)
- 데모그래픽 정보 (메타 데이터)
- 유저 행동 정보 (Log)
아이템 관련 정보
- 아이템 ID
- 아이템의 고유 정보 (메타 데이터)
- 아이템의 고유 정보는 도메인마다 천차만별
유저 - 아이템 상호작용 정보
- 오프라인, 온라인 등 상호작용 할때 로그로 남음
Explicit Feedback
- 만족도를 직접 물어본 경우
- 평점 등
Implicit Feedback
- 유저가 아이템을 클릭, 구매
- 체류 시간 등
- 비교적으로 Explicit Feedback보다 많으며, 고려하기 어려움
문제 정의
- 특정 유저에게 적합한 아이템을 추천한다
- 특정 아이템에게 적합한 유저를 추천한다
- 유저 - 아이템을 평가할 Score가 필요
랭킹
- 유저에게 적합한 아이템 Top K개를 추천
- 정확한 선호도를 가질 필요는 없음 (정렬하면 됨)
예측
- 유저의 선호도를 정확하게 예측 (평점 or 클릭/구매 확률)
추천 시스템의 평가 지표
- 모델 평가는 어떻게 해야하는가?
- 비즈니스적으로는 매출, PV, CTR 등
- 품질적으로는 연관성, 다양성, 새로움, 참신함 등
Offline Test
- Test data의 성능을 평가하는 것과 동일
- 실제 서비스에서는 Serving Bias가 존재 (오프라인 테스트와 실제 서비스에서 차이를 보이는 것)
Precision @ K
- 우리가 추천한 K개 아이템 가운데 실제로 관심있는 아이템의 비율
Recall @ K
- 유저가 관심있는 전체 아이템 가운데 우리가 추천한 아이템의 비율
MAP @ K
- Precision @ 1 부터 Precision @ K 까지의 평균 값
- 관련 아이템을 더 높은 순위에 놓을 수록 성능이 좋음
Normalized Discount Cumulative Gain (NDCG)

- 원래 검색에서 사용되는 지표
- Top K 리스트를 만들고 유저가 선호하는 아이템을 비교
- MAP @ K 와 마찬가지로 추천의 순서에 가중치를 더 많이 두어 1에 가까울수록 좋음
- MAP와 달리 이진 값이 아닌 수치로 나타낼 수 있기에, 유저에게 얼마나 더 관련있는 아이템을 상위로 노출시키는지 알 수 있음
Onlie A/B Test
- 실제 서비스를 통해 결과를 서빙
- 한 번에 대조군과 실험군의 성능을 평가
- 보통 트래픽을 50% 로 나누어서 비교
- 보통 비즈니스 지표를 사용하여 비교
인기도 기반 추천
- 머신러닝이 아닌 통계적 추천
- 서비스 런칭 초반에 주로 사용
- 단순히 가장 인기있는 아이템을 추천 (평점, 조회수, 리뷰 개수, 좋아요/싫어요 수)
Most Popular
- 조회수가 가장 많은 아이템
Hacker News Formula
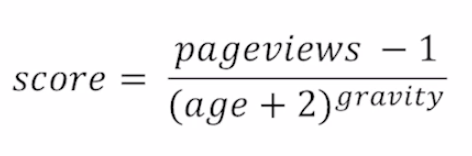
- 시간이 지날수록 age가 점점 증가하므로 score는 작아짐
- 시간에 따라 줄어드는 score를 조정하기 위해 gravity라는 상수를 사용
Reddit Formula
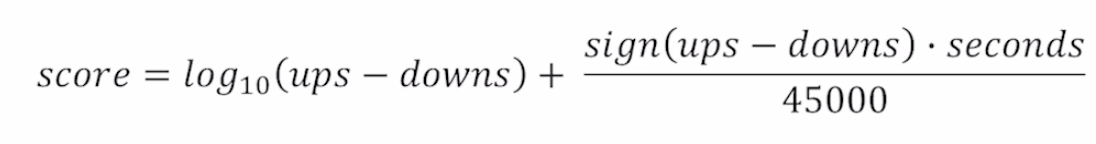
- 첫 번째 term은 popularity, 두 번째 term은 포스팅이 게시된 절대 시간
- 첫 vote에 대해 높은 가치를 부여하며, vote가 늘어날 수록 score의 증가 폭이 작아짐
Highly Rated
- 평균 평점이 가장 높은 아이템
- rating과 rating의 개수를 모두 고려해야 함
Steam Rating Formula
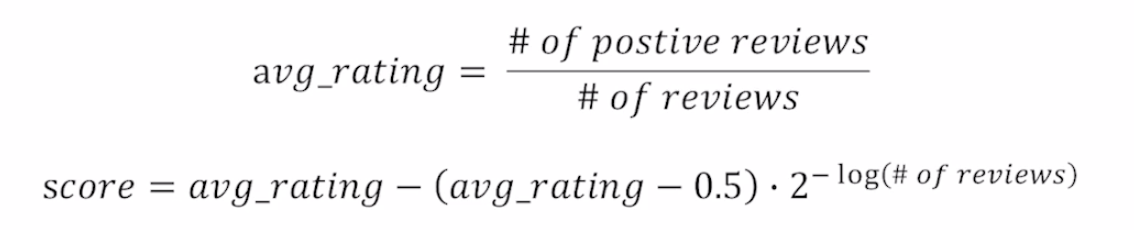
- 뒤에 있는 # of review로 평점을 보정
- 리뷰의 개수가 아주 많을 경우 score는 평균 rating과 거의 유사해짐
Movie Rating
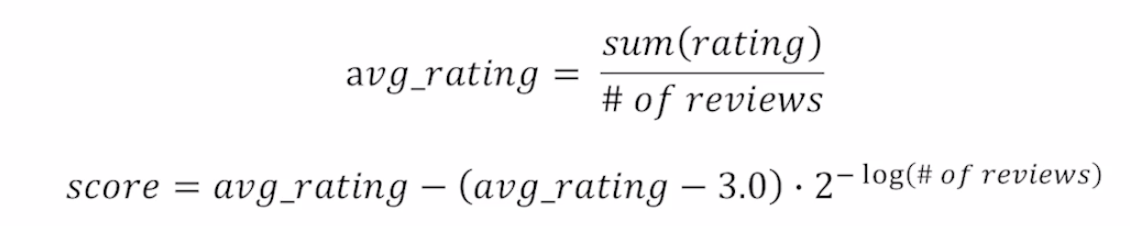
- Steam과 유사하지만 보정 수치를 중간값인 3으로 사용
- 마찬가지로 review 개수가 많아질수록 score는 평균과 같아짐
기법 개요
- 인기도 기반
- 연관 분석
- 컨텐츠 기반 분석
- CF
- Item2Vec
- 딥 러닝 관련 모델
왜 딥 러닝 모델을 자주 사용하지 않는가?
- 대용량 트래픽을 감당하려면 Inference가 짧은 머신 러닝 모델이 유효함
연관 분석
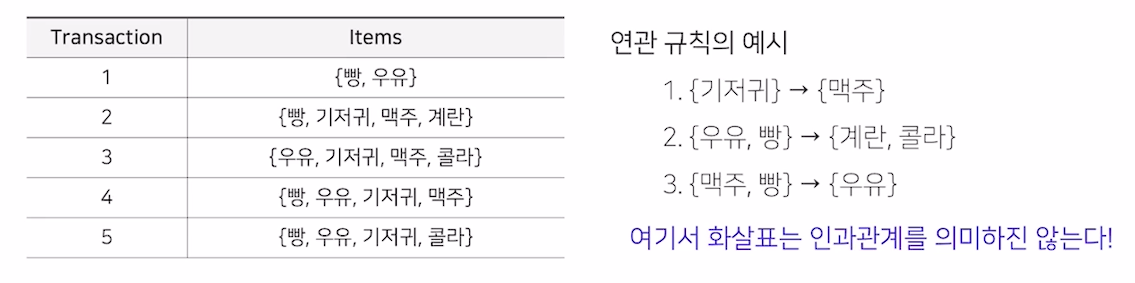
- 연관 규칙과 탐색하는 알고리즘
- Association Rule Analysis
- 장바구니 분석, 서열 분석
- 연속된 거래들 사이의 규칙을 발견하기 위해 적용

- 빈번하게 발생하는 규칙을 의미 (threshold로 구분)
빈발 집합
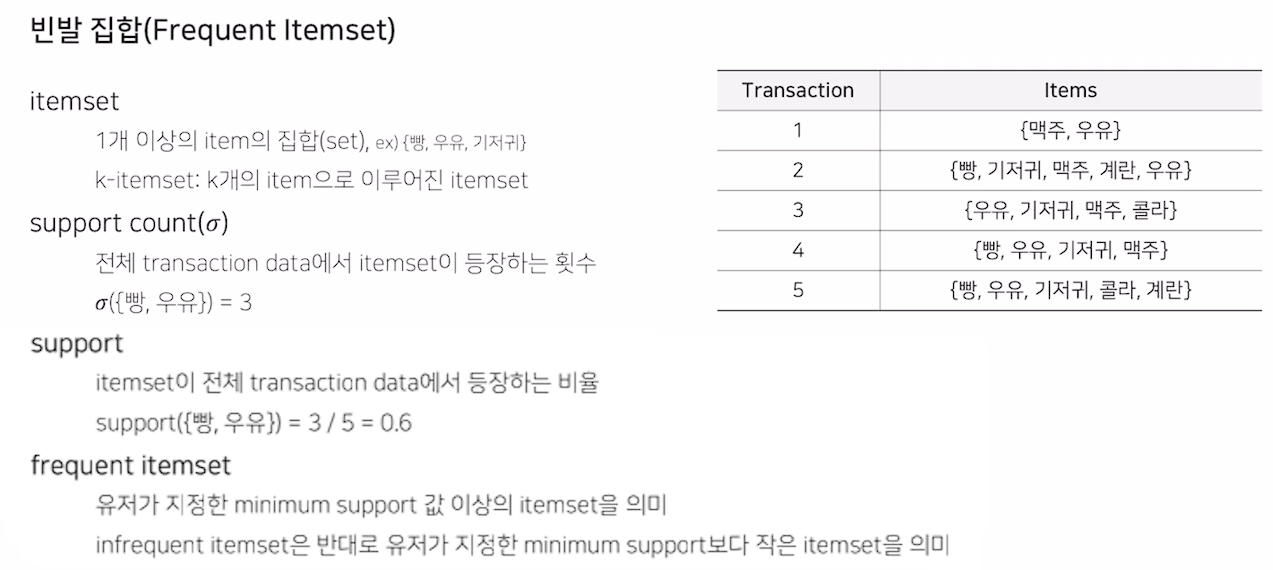
- Frequent Itemset
- 각각의 Transaction 집합은 k개의 Itemset의 집합
척도
Support

- 전체 Transaction에서 Item이 등장하는 비율
Confidence

- 조건부 확률
Lift

- Lift가 1이면 독립
- 1보다 크면 양의 상관관계, 1보다 작으면 음의 상관관계
추천 방법
- 모든 Rule을 사용할 수 없음
- min support, min confidence로 의미없는 rule을 배제
- lift 값으로 내림차순 하여 의미 있는 rule을 평가
Mining Association Rules
- 연관 규칙을 찾는 알고리즘
Brute-Force
- 모두 찾기
- 계산량이 너무 높음
Frequent Itemset Generation
- 효율적인 빈발집합을 찾는 알고리즘
- Apriori 알고리즘
- transaction의 숫자를 줄이기
- 탐색 횟수를 줄이기
TF-IDF
- 텍스트를 다루는 가장 기본적인 방법
- 유저 X가 과거에 선호한 아이템과 비슷한 아이템을 유저에게 추천
- 컨텐츠 기반 추천
컨텐츠 기반 추천
- 사용한 Item을 기반으로 User Profile 생성
- User Profile로 비슷한 Item을 추천
장점
- 다른 유저의 데이터가 필요하지 않음
- 인기도가 낮은 아이템을 추천할 수 있음
- 추천 아이템에 대한 설명이 가능
단점
- 아이템의 적합한 Feature를 찾기 어려움
- 한 분야/장르에 대한 추천 결과만 나올 수 있음 (overspecialization)
- 다른 유저의 데이터를 활용할 수 없음
Item Profile
- 도메인 별로 상이
- 속성은 벡터 형태로 표현
TF-IDF

- 텍스트는 단어의 집합
- 중요한 단어에 대한 Score가 필요
- Term Frequency - Inverse Document Frequency
- 단어 w가 문서 d에 많이 등장하며, 전체 문서에서 적게 등장하는 단어라면 단어 w는 문서 d를 설명하는 중요한 Feature라는 가정
User Profile

- 유저가 선호한 문서를 평균 혹은 rating으로 가중평균낸 벡터가 Profile vector
- Cosine Similarity를 사용해 유저 벡터 u와 아이템 벡터 i에 대해 거리를 계산
- 유사도가 높은 Top k 추천
- 정확히 별점을 예측 하려면 아이템끼리 유사도를 계산 후, 유저의 별점과 가중 평균
