
Batch
Batch의 사전적인 의미는 “집단, 무리”라는 뜻입니다. 딥러닝에서 Batch는 전체 데이터를 n개의 묶음으로 나누는 것으로, 한 묶음 당 모델의 가중치를 한번씩 업데이트시킵니다. 예를 들어 1000개의 데이터가 있을 때 Batch size가 10이라면 10개의 데이터마다 묶어서 총 100개의 Batch로 나눠서 훈련을 진행한 것입니다.
Internal Covariate Shift
Batch size만큼 훈련하고 모델을 한번 업데이트 시키는 방법을 MSGD(Mini-batch Stochastic Gradient Descent)라고 하는데, 이렇게 학습을 하게 되면 발생하는 문제점이 있는데 바로 Internal Covariate Shift입니다. Internal Covariate Shift란 Layer가 깊어질수록 가중치의 미세한 변화들이 누적되어 뒤의 Layer에 큰 영향을 미치는 문제를 말합니다. 예를 들어 Training data의 분포와 Test data의 분포가 다르면 학습이 잘 안 되는 것과 같이 학습 과정에서도 Layer의 깊이가 깊어질수록 변화가 누적되어 feature의 분포가 변화되어 학습이 힘들어지는 것입니다. 이 문제를 해결하기 위해 weight 초기화를 잘 해주거나 learning rate를 작게 주어서 변화량을 줄이는 방법이 사용되기도 했으나 다른 문제를 야기했기 때문에 새롭게 탄생한 방법이 바로 Batch Normalization입니다.
Batch Normalization
Batch Normalization은 Hidden Layer에서의 변화량이 크지 않으면 학습도 안정될 것이라는 뜻으로 만들어졌습니다. 그래서 Batch Normalization은 weight와 Input의 연산 결과를 Batch 단위로 Normalization해서 조정해서 변화를 줄어들게 합니다.
<Batch Normalization 정의>

위의 식에서 는 추가 스케일링을 뜻하고 는 편향을 뜻합니다. 두 파라미터는 activation function에 적합한 분포로 변환해 비선형성을 잃지 않게 조정해주는 값으로, 학습을 통하여 값이 결정됩니다. 따라서 Batch Normalization은 학습 가능한 파라미터가 존재하는 하나의 Layer가 되기 때문에 기존의 구조에서 Convolution Layer와 Activation Layer사이에 Batch Normalization이 들어간 형태로 발전했습니다.
추론 단계의 Batch Normalization
Batch란 것은 학습할 때 사용하는 것 일뿐, 추론 단계에서는 사용하지 않습니다. 그렇다면
추론 단계에서 Batch Normalization을 어떻게 사용할까요?
<추론 단계에서의 Batch Normalization 정의>
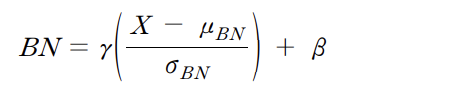
학습 단계에서는 Batch별로 Batch Normalization이 계속 변경되고 업데이트되지만 추론 단
계에서는 학습 단계에서 이동 평균 또는 지수 평균에 의하여 고정된 값을 사용합니다.
Batch Normalization의 장점
Internal Covariate Shift 문제를 해결하여 학습의 결과가 좋아졌고, 큰 Learning rate를 사
용할 수 있게 되어 학습의 속도도 개선하였습니다. 또한 Weight initialization에 훨씬 덜 민
감해지고, Sigmoid같은 Activation function을 사용할 때의 기울기 소실문제를 개선하였습니
다. 그리고 Batch마다의 평균과 분산이 변하는 과정을 통하여 분포가 조금씩 바뀌게 되고
이러한 현상은 모델의 Overfitting을 방지하는 효과도 냅니다.
Batch Normalization의 단점
Batch를 이용하는 것이기 때문에 Batch의 크기에 영향을 많이 받습니다. Batch가 너무 작
을 경우, 가령 1이게 되면 평균이 그 값 하나가 되기 때문에 정상적으로 동작할 수 없습니
다. 반대로 Batch의 크기가 너무 커진다면 gradient를 한 번에 계산하게 되는 것이므로 학
습에 악영향이 있을 수 있습니다. 이러한 단점을 계산하기 위해 후에는 Weight
Normalization이나 Layer Normalization이 등장합니다.
