" Attention is all you need "
딥러닝을 공부하는 사람이라면 한번쯤은 들어봤을, transformer라는 새로운 구조를 제안한 논문제목이 바로 "Attention is all you need"이다. transformer는 attention 메커니즘을 기반으로 설계되어 기존의 모델들보다 우월한 성능을 보인, 기계번역이나 영문번역같은 분야에서 SOTA를 찍은 모델이다. 오늘 리뷰할 Swin Transformer는 이름에서 알 수 있듯이 transformer의 구조를 object detection에 적용한 모델이다.
Abstract
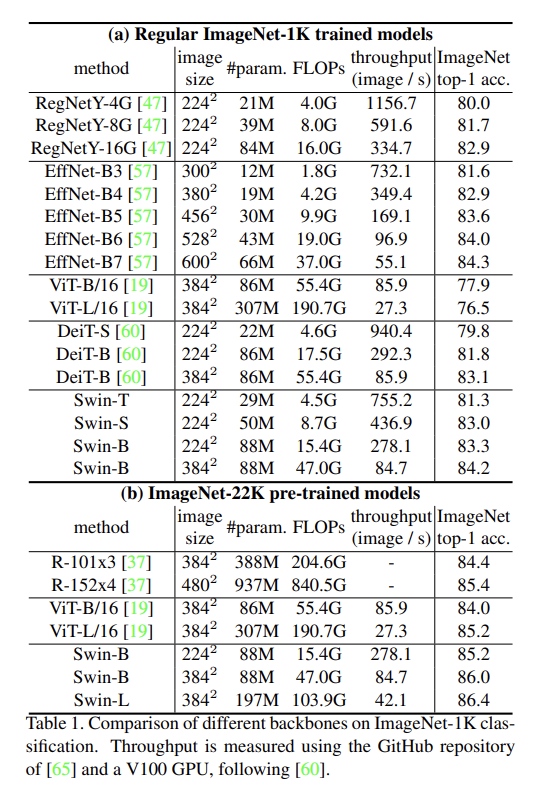
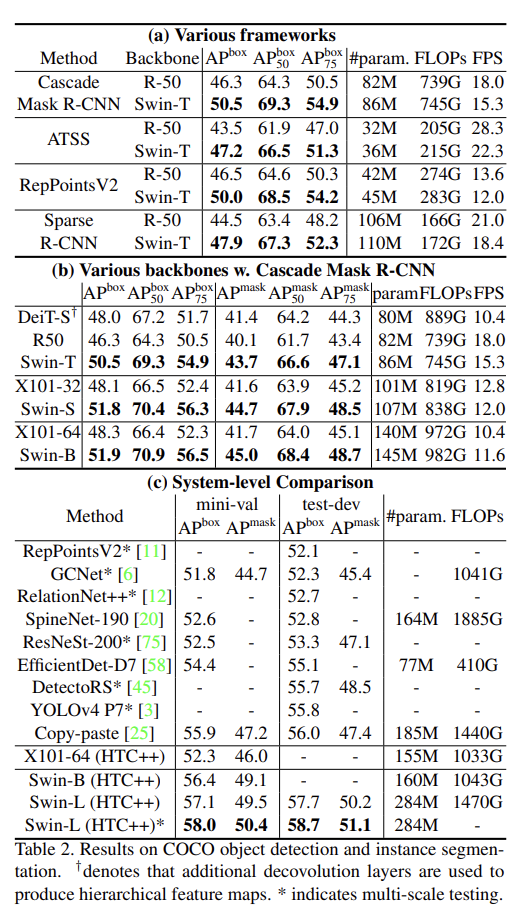
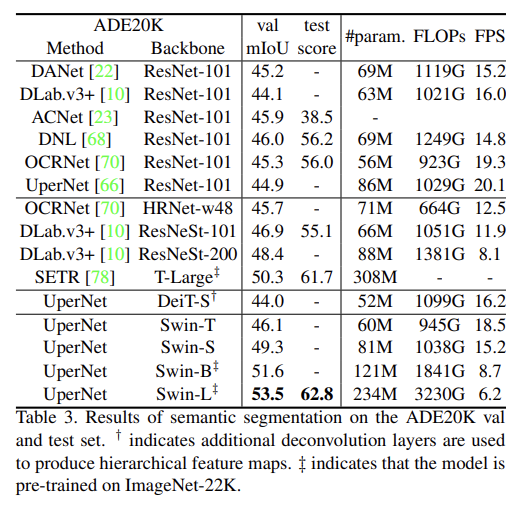
이 논문은 computer vision영역에서 backbone이 될 수 있는 Swin Transformer라고 하는 새로운 vision Transformer를 제안한다. transformer는 원래 text data를 대상으로 적용되는 것이기 때문에 vision으로 적응시키는데에 있어 스케일의 차이와 text data에 비해 image data의 높은 해상도와 같은 두 도메인의 차이로 어려움이 나타난다. 이러한 차이를 해결하기 위해 이 논문에서는 Shifted Windows로 구현한 hierarchical(계층적) transformer를 제안한다. Shifted Windowing 체계는 전체적인 data를 attention하는 것이 아닌, 중복되지 않는 로컬 window를 attention하기 때문에 더 큰 효율성을 제공한다. Swin Transformer는 다양한 규모로 모델링할 수 있는 유연성과 이미지 크기에 대한 선형 계산 복잡성을 가지고 있는 특징이 있기 때문에 다른 vision task(clasification, detection, semantic segmentation)에 호환이 된다. Swin Transformer는 COCO dataset과 ADE20k dataset에서 성능이 SOTA를 기록하였기에 vision분야에서의 Transformer기반 model의 가능성을 입증하였다. 이런 계층적 구조나 shifted window 접근법은 모든 MLP구조에 도움이 된다.
Architecture
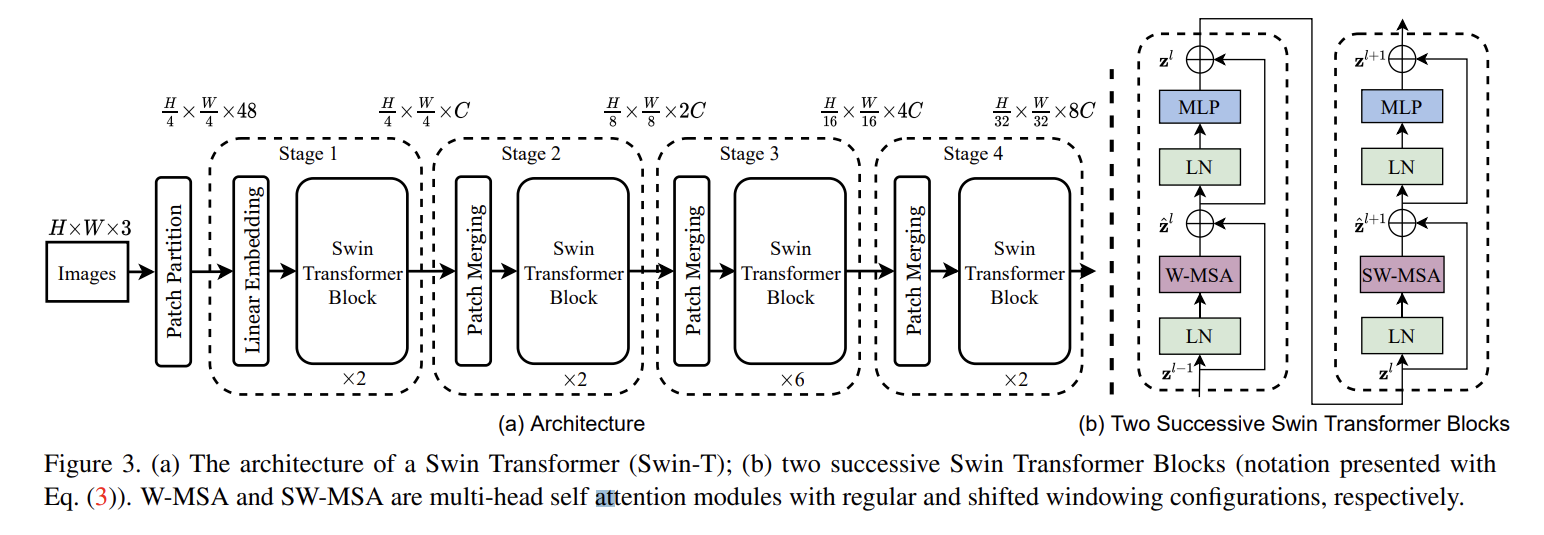
Patch partition
처음 input image에서 patch를 분할하는 부분이다. Patch partition을 진행하게 되면 한 점이 patch가 되고 각 patch의 픽셀정보가 channel이 된다.
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
Swin Transformer Block
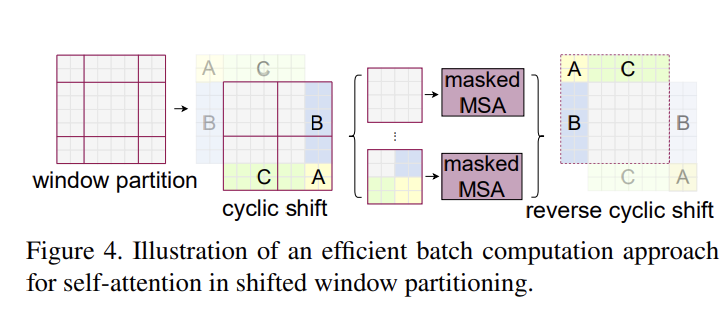
Swin transformer Block에서 W-MSA는 현재 window에 있는 패치들끼리만 self-attention을 수행하는 것이다. SW-MSA는 window를 shift해서 self-attention을 한번 더 수행하는 것이다.
Performance