논문의 제목과 초록과 도표를 먼저보자!
논문 제목
논문의 제목은 "A Style-Based Generator Architecture for Generative Adversarial Networks"이다. Style(Style transfer)을 기반으로한 생성자 구조...GAN을 위한? 으로 해석할 수 있을것이다. 이 논문은 NVIDIA에서 만든 것으로 굉장한 성과를 거두었다고 한다.
논문 초록(abstract)
우선 이 논문에서 제안하는 것은 Style transfer을 이용한 GAN의 새로운 generator architecture이다. 이 새로운 generator architecture는 자동적으로 학습되고, high-level의 속성(예를 들면 사람의 얼굴에 대한 포즈나 정체성)의 분류와 생성된 이미지(예를 들면 주근깨, 머리카락)같은 것의 합성을 제어할 수 있다고 한다. 또한 interpolation과 disentangles을 향상시킬 수 있는 두 가지의 generator archotecture에서 쓰이는 method를 제안한다. 그리고 고품질의 얼굴 데이터셋을 소개한다!!이다.
도표 보기
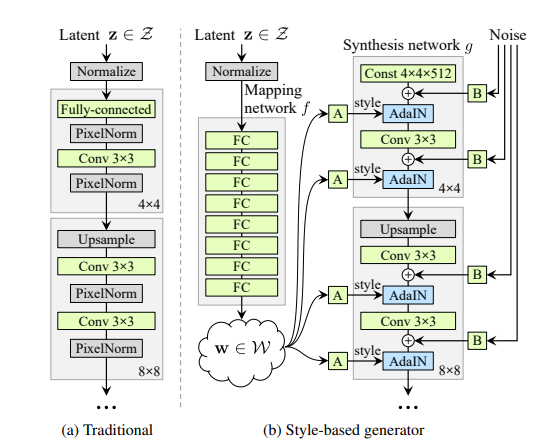
(a)그림은 그동안의 보통적인 GAN의 architecture이다. 그동안은 style의 mapping을 강제로 연결지었기 때문에 사람이 조정을 할 수 없었지만, (b)를 보면 AdaIN라는 것을 사용하여 이것을 조정할 수 있도록 하였다. AdaIN전에 있는 A에서는 affine transform(2D 변환 종류 중 하나인듯)을 학습하고 B에서는 Gaussian noise를 각각 layer에 더해준다.
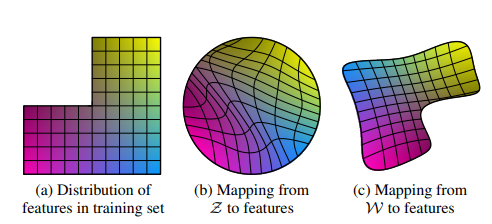
위 그림에서 두 가지 변동요소(예를 들면 머리카락 길이나 남성성)에 대한 그림으로 (a)는 훈련 데이터 셋의 feature가 분배되어 있는 모습이고, (b)는 기존 GAN이 생성할 때 Mapping을 한 모습, (c)는 StyleGAN에서 Mapping을 했을 때의 모습이다. (b)처럼 했을때는 잘못된 조합으로 sampling이 되기 때문에 (c)로 해서 덜 변경되기 때문에 W를 사용했다.
결론
style transfer를 기반으로 high level attribute를 잘 분리하며 잘 조정이 된다는 강점이 있는 모델이다.
논문을 읽고 해야할 것!
- 저자가 뭘 해내고 싶어 했는가?
style transfer를 기반으로 조정이 가능한 model을 만들고 싶었다. - 이 연구의 접근에서 중요한 요소는 무엇인가?
기존의 GAN처럼 latent Z가 아니라 W를 사용하여 feature들의 entangle한 성질을 고쳤다는 것이 중요하다고 생각한다. - 내가 참고하고 싶은 다른 레퍼런스에는 어떤 것이 있나?
Style transfer논문을 다시 리뷰해보고 싶고, 이후 나온 StyleGAN2도 리뷰해보고싶다.
