[ICML 2025] Beyond Sensor Data: Foundation Models of Behavioral Data from Wearables Improve Health Predictions
Foundation Models for Health
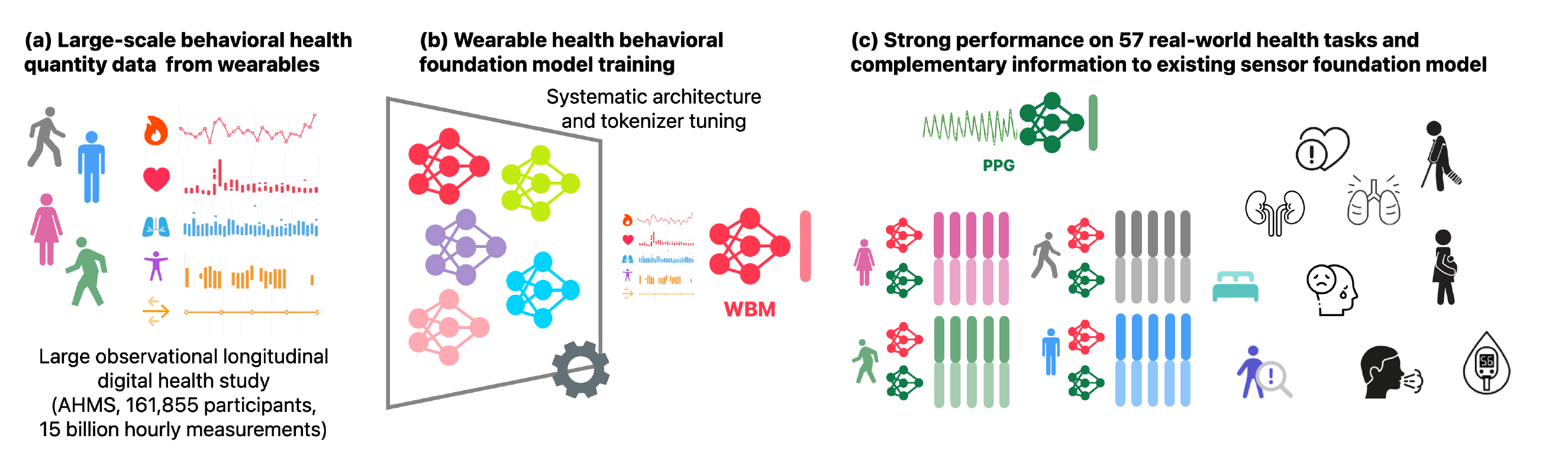
최근 몇 년간 Apple은 웨어러블 데이터를 활용한 Foundation Model 연구를 주도하고 있다. 이전에는 심박수(🫀PPG), 움직임(📈ACC)과 같은 raw biosignals을 처리하여 미시적인 문제를 푸는데에 집중했다면, 이번에는 한 단계 더 나아가 행동 기반 데이터(behavioral data)로 거시적인 헬스 문제를 해결할 수도 있다는 가능성을 보여주었다. 본 논문에서 사용한 데이터셋은 162,000명의 개인에게서 수집한 2.5B hours 데이터이고, 특징으로는 한 시간을 하나의 data point로 해석했다는 것이다. 2025년 ICML에 채택되었다.
📊 Input Data
기존의 웨어러블 기반 Foundation Model은 보통 아래와 같은 raw data를 직접 input으로 사용하였다:
- PPG (혈류 기반 심박수 측정)
- ECG (심전도)
- ACC (가속도)
이런 신호는 매우 정밀하지만, 하루 24시간 내내 측정되지 않거나, 전반적인 생활 패턴 변화를 예측하는데에는 쓰이기 힘들었다.
본 논문은 이러한 한계를 극복하기 위해 사용자의 행동을 반영한 데이터(behavioral data)를 활용하여 Foundation Model을 구축하였다.
예를 들면:
- 걸음 수, 이동 거리, 계단 수
- 운동 시간, 수면 효율
- 체력 지표 (VO2max, 6-minute walk distance)
- 걸음 패턴(보폭, 안정성, 대칭성 등)
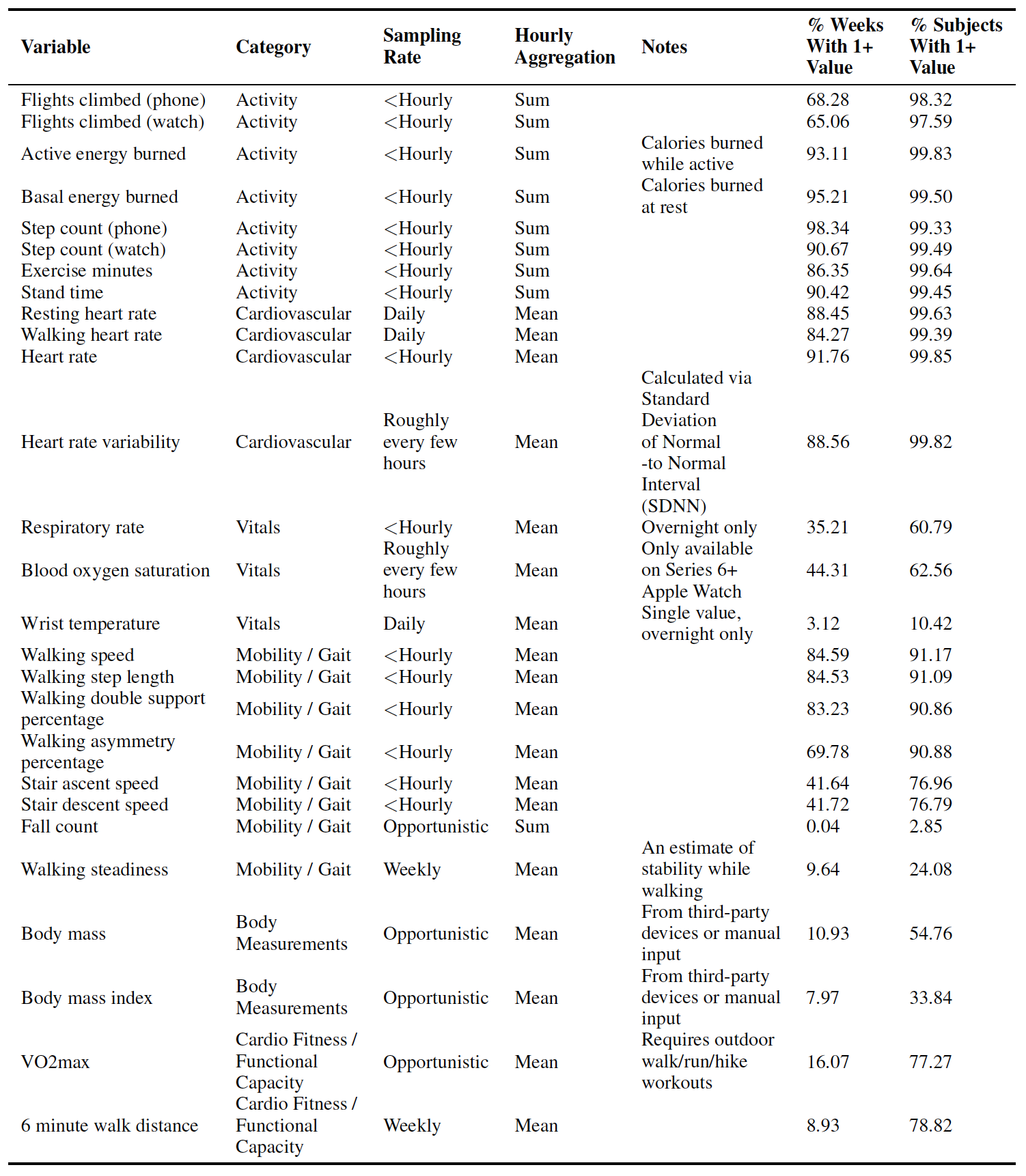
위와 같은 데이터를 지속적으로 수집하였으며, 시간 단위(hourly)로 정리된 27개 지표로 구성되어 사용자 행동을 보다 현실적으로 반영할 수 있다.
자세한 인풋 데이터와, 이를 어떻게 1시간 단위로 계산하였는지는 아래 표를 참고하자.
🔧 Model Architecture
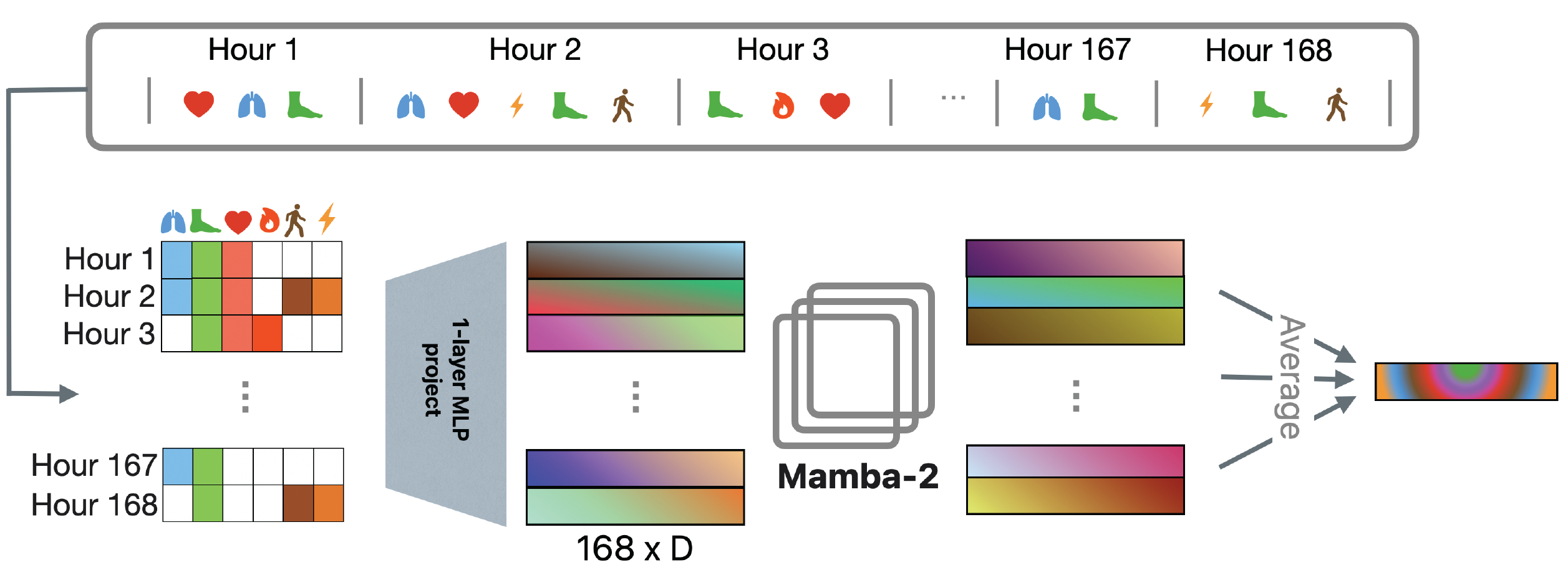
- Input tokenizer: 168시간(1주)의 행동 데이터를 정규화하고 결측값을 마스킹하여 168×54 행렬로 변환하는 과정.
- TST (Time Series Transformer) vs. mTAN (multi-time attention) vs. Tuple 세 가지 방법을 사용.
- TST를 사용한 것이 아니라 TST에서 사용한 입력 전처리 아이디어 방식을 모방했다는 뜻
- 매 한 시간(hour) 단위를 하나의 patch로 보고, 각 patch (1 × 54 vector)에 1-layer MLP (즉, 선형 projection) 을 적용하여 시퀀스 임베딩을 생성함 → 최종적으로 168개의 벡터 시퀀스가 만들어짐
- 여기에서 TST를 사용할 때 결측값 대치를 global mean으로 했을 때가 가장 성능이 좋았음. 이도 놀라웠는데, subject-specific mean보다 global mean이 더 성능이 좋은 것은 특정 subject에게 있는 high level noise 때문인 것으로 보인다.
- 27개의 feature + 27개의 missingness mask = 54
- TST (Time Series Transformer) vs. mTAN (multi-time attention) vs. Tuple 세 가지 방법을 사용.
- Backbone Model Architecture:
- Self-Attention Transformer, Rotary Transformer와 Mamba-2을 모두 테스트 해봄
- Rotary Transformer: absolute position이 아닌 relative positional encoding을 사용.
- Tunning and Best Model Creation:
- 위의 Tokenizer * Backbone의 모든 조합 (6개)을 비교
- Task: age prediction - 보통 이러한 learned embedding의 quality를 평가하기 위해 사용됨.
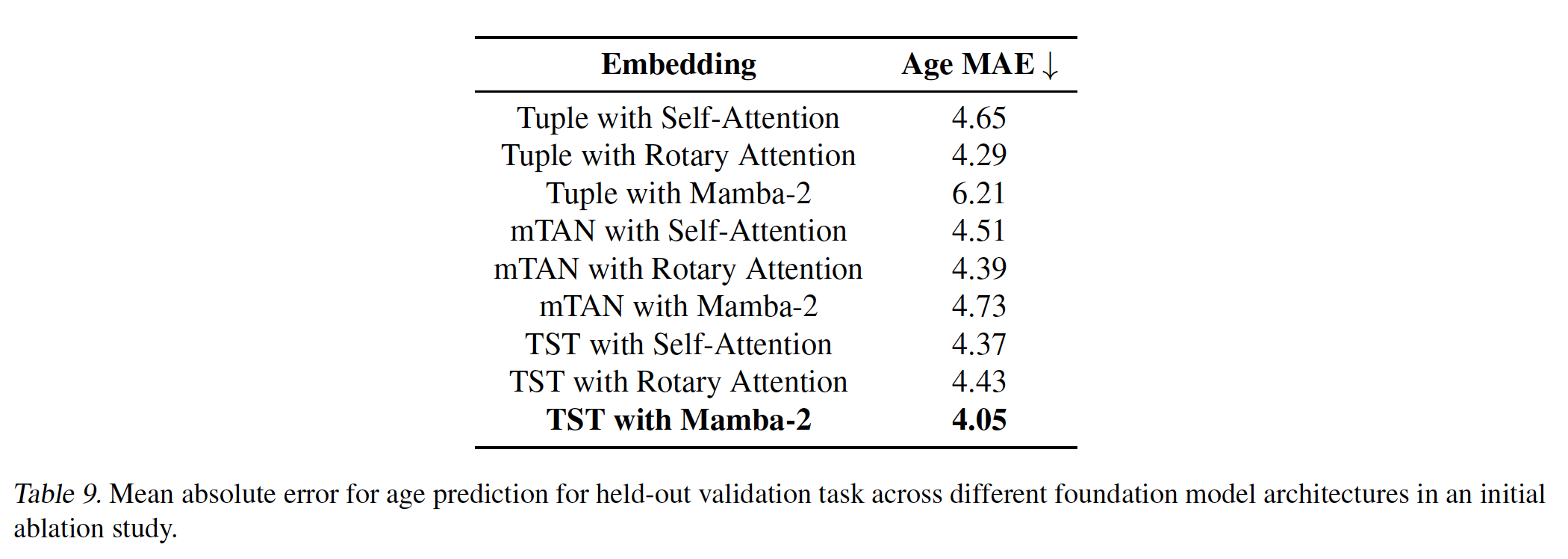
- 위 결과와 같이 TST + Mamba-2 조합의 성능이 가장 좋았음.
- Pretraining Objective:
- Contrastive loss 기반 Self-Supervised Learning (positive pair: 동일인의 서로 다른 주간 데이터), MAE도 사용해 보았으나 성능이 좋지 않았음. MAE는 기존 input signal을 다 reconstruct 해야하는 부담이 있는데, 논문에서는 그 원인으로 행동 데이터에 존재하는 높은 noise를 지적하고 있다.
- 결론: 기존 연구들에서는 Transformer + Masked Autoencoder가 많이 쓰였지만, behavioral data에서는 simple imputation (TST) + contrastive learning + Mamba 조합이 가장 좋았다고 함.
🔬 학습 데이터 규모
- 출처: Apple Heart and Movement Study (AHMS)
- 참여자: 16만 명 이상
- 데이터 규모: 15.1M 주간 데이터, 총 25억 시간의 행동 데이터
- AHMS는 Apple Watch, iPhone 사용자로 구성되어 있어 다소 selection bias가 있긴 하지만, 규모와 정밀도 면에서는 지금까지 발표된 논문 중 최고 수준.
🧪 Downstream Task 성능
- Embedding을 구성할 때 총 4가지 방법을 활용.
- Baseline: learned model embedding을 사용하는 것이 아니라 mean과 std를 단순하게 사용하여 embedding.
- WBM: 위와 같은 1시간 단위의 data point를 활용한 embedding
- PPG: 선행 연구 (Abbaspourazad et al., 2024a)에서의 PPG Foundation Model에서의 embedding 사용
- WBM + PPG: 위 두 embedding vector를 concat 하여 하나의 인풋으로 사용.
✅ Inter-subject Tasks (정적인 상태 예측)
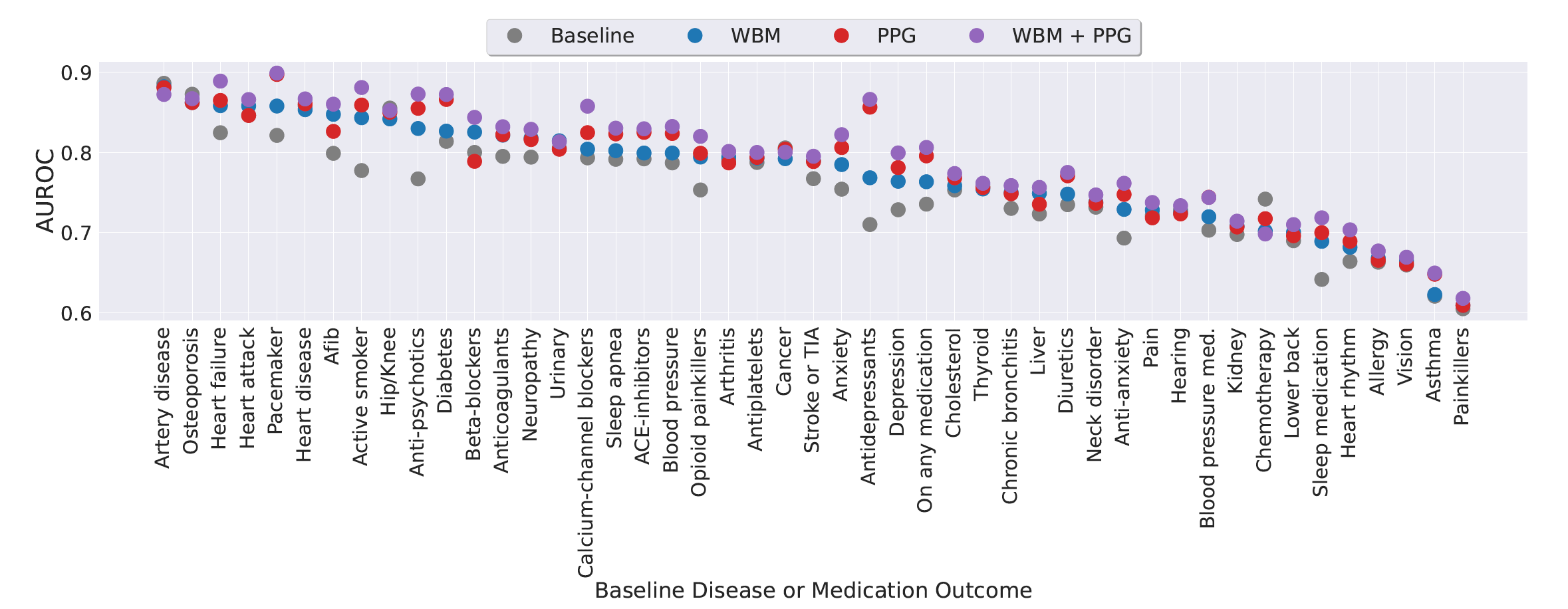
- 예: 나이, 성별, 당뇨병 여부, 고혈압 병력, 약물 복용 등
- WBM은 대부분의 task에서 기존 baseline을 상회
- PPG 모델보다도 우수한 경우도 다수
🔄 Intra-subject Tasks (시간에 따른 상태 변화 감지)
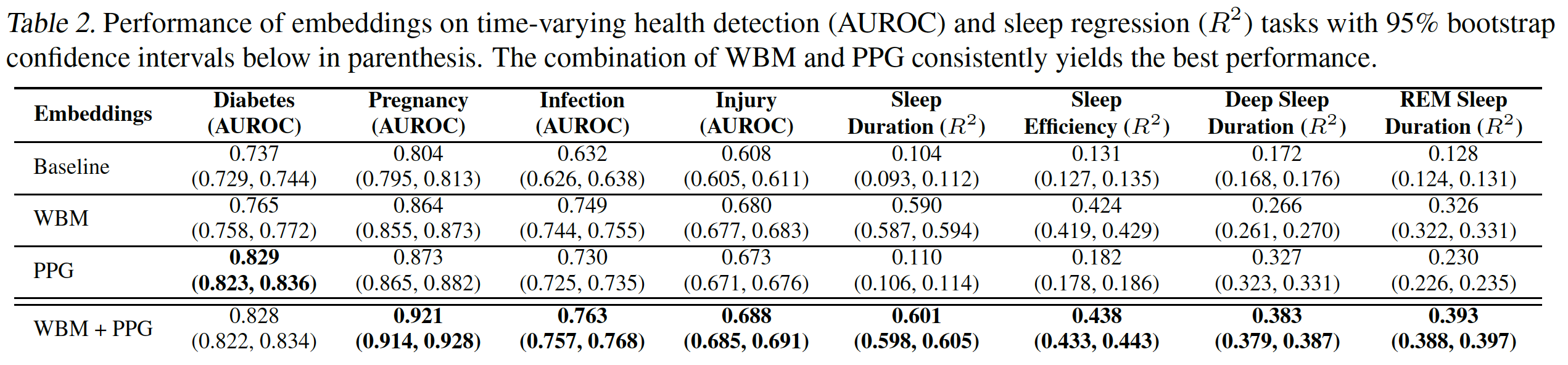
- 예: 감염 여부, 임신, 부상 여부, 수면의 질 등
- Behavioral data 특성상 이런 동적 예측에 탁월
- Sleep duration, REM, Deep sleep 예측에서 특히 좋은 성능 (R² 최대 0.6 이상)
1. Sleep metrics:
- Apple Watch의 ACC-based sleep stage algorithm을 reference로 사용함.
- 총 32.2K 참여자들의 671.6K의 unique participant-weeks 데이터를 활용.
- FM 모델이 어떠한 수면 데이터로도 훈련되지 않았음에도 불구하고 weekly summaries of sleep data를 꽤 잘 설명함.
🤔 왜 로 평가했는지, 수치가 0.3~0.4면 그리 높지 않은데도 왜 의미가 있는지?
- 일반적으로 가 0과 0.5 사이이면 모델이 variance의 50% 정도는 설명할 수 있다는 의미이다. 일단 reference로 사용한 것이 PSG가 아니기 때문에 accuracy로 평가하기 어렵고 (nosiy target), 모델의 embedding quality를 잘 평가할 수 있는 지표이기 때문에 이를 사용한 것.
2. Pregnancy:
- 일상적인 행동 데이터를 통해 임신 여부를 예측할 수 있다는 것 자체가 매우 파격적임 (실제로 언론이 가장 주목한 부분이기도 함).
- 385명의 환자들에게서의 430개의 pregnancy delivery 이벤트를 데이터로 활용.
- delivery를 기준으로 9개월 전, 1개월 후는 "positive"로, 그 외는 "negative"로 라벨링.
- 50세 미만의 24,225명의 여성 참가자들은 non-pregnant control로 사용.
💬 Key Takeaways
🎯 WBM + PPG 조합의 힘
- 두 모델의 임베딩을 concatenate하여 downstream task에 사용했더니 거의 모든 task에서 단일 모델보다 높은 성능을 기록함.
- 특히 임신 예측(AUROC 0.921), 심방세동, 베타차단제 복용 여부 등의 task에서 큰 향상을 보여줌.
- 이런 모델은 wearable 하나로 수면, 감염, 임신, 약 복용 상태 등을 모니터링할 수 있는 가능성을 보여줌.
- 기존에는 raw sensor signal이 없으면 분석이 어렵다고 여겨졌지만, 이번 연구는 고수준 behavioral 지표만으로도 의미 있는 embedding 학습이 가능함을 증명. 행동 데이터도 충분히 predictive할 수 있다.
- 이러한 사실은 wearable data를 저장하는데 있어서도 효과적인데, 모든 사용자들의 모든 raw data를 서버에 저장하려면 너무 많은 리소스가 소모되기 때문. low resolution의 데이터 포인트도 충분히 거시적인 관점에서의 행동 변화를 예측하는 데 쓰일 수 있다는 것을 보여줌.
💬 Limitations
-
행동 데이터의 노이즈와 결측치
- Behavioral data는 sampling이 불규칙하고, 결측값이 많으며, 개별 사용자마다 수집 밀도도 다름.
- 특히 일부 변수는 일주일에 한두 번만 수집되기 때문에, 전체적으로 노이즈 수준이 높고 sparse합니다.
- 이로 인해 MAE 기반 reconstruction loss (예: masked autoencoder)가 잘 작동하지 않았음.
- 📌 대응: 미래에는 더 정교한 imputation 기법 또는 joint embedding 예측 구조가 나을 수 있음.
-
데이터 편향
- 데이터는 Apple Heart & Movement Study(AHMS) 기반으로 수집되었고, iPhone과 Apple Watch 사용자들이 자발적으로 참여
- 결과적으로, 기술 접근성, 건강에 대한 관심도, 사회경제적 수준 등에서 편향이 존재할 수 있음
- 특히 여성, 노년층, 인종 소수집단이 상대적으로 과소 대표됨
- 📌 대응: 이는 모델의 일반화 성능에 영향을 줄 수 있으며, 후속 연구에서 형평성(equity)을 고려한 확장 필요
-
Self-supervised loss 설계의 한계
- Contrastive learning을 사용했지만, Positive/Negative 쌍의 정의가 설계자 의존적이고, 특정 downstream task에는 최적이 아닐 수 있음
- 예: 시간 민감도가 중요한 예측(질병 악화 등)에는 부적합
- 📌 대응: 향후에는 masked prediction, joint embedding-prediction architectures 등 다른 SSL objective들도 고려할 수 있음
-
미래 상태 예측은 불가
- 현재의 WBM은 단지 현재 상태(state)를 embedding으로 표현하는 encoder-only 구조
- 즉, 시간 흐름에 따른 미래 상태 예측 (forecasting)은 불가능
- 📌 대응: 미래에는 decoder 또는 autoregressive 구조를 추가한 forecasting용 foundation model이 필요할 수 있음
📚 Reference
