[ICLR 2025] PAPAGEI: Open Foundation Models for Optical Physiological Signals
Foundation Models for Health
PPG(Photoplethysmography) 는 스마트 워치나 병원에서 모니터링에 널리 쓰이는 생체 신호 기술이지만, 기존 연구는 대부분 특정 태스크를 목적으로 진행되어 일반화가 어렵거나, 공개되지 않은 모델/데이터셋이 많았다. 본 연구는 Nokia Bell Labs에서 진행된 것으로, 코드가 공개된 Foundation Model 연구이며, 개인적으로는 최근 리뷰한 Health Foudnation Model 중 가장 잘 쓰인 페이퍼이지 않나 싶다. 아무래도 Apple이나 Google은 해당 연구의 디테일을 공개하는데 있어 좀 조심스러운 느낌이었다면, 본 논문에서는 궁금할 만한 것은 모두 설명해 놓은 느낌이었다. 해당 논문에서는 10개의 public 데이터셋을 기반으로 contrastive learning 기반 SSL으로 20개의 downstream 태스크(심혈관 건강, 수면 장애, 임신 모니터링, 감정 맞추기 등)를 성공적으로 수행하였다.
Github: https://github.com/Nokia-Bell-Labs/papagei-foundation-model
Paper: https://arxiv.org/pdf/2410.20542v2
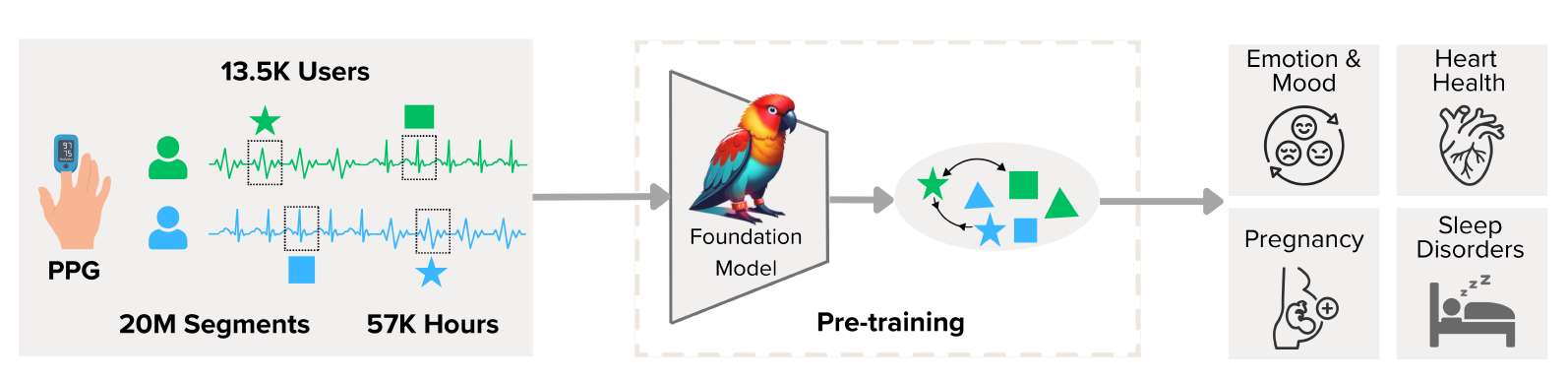
🖋️ 연구 배경
- PPG는 병원(산소포화도 모니터, 수술 중 모니터링)부터 웨어러블(스마트워치)까지 널리 활용.
- 하지만 노이즈, 움직임 아티팩트, 피부색·체형 차이 등으로 인해 모델 일반화가 매우 어려움.
- 기존 연구들은 단일 데이터셋, 모델 코드 비공개 → 재현성 부족 & 다양한 환경에 적용 어려움.
🦜 PAPAGEI 모델 개요
Pretraining public 데이터셋 (아래 세 데이터는 모두 finger-tip PPG에서 얻은 것임)
- VitalDB (수술 중 환자, 6,388명)
- MIMIC-III (ICU 환자 모니터링, 10,282명)
- MESA (수면 연구, 2,055명)
- 총 13,517명 환자, 57,641시간, 20,751,206 segments (10초 단위).
모델 구조:

- 간단한 ResNet 스타일 CNN 인코더 (18개 convolution block).
- Projection head (512차원 embedding).
- Morphology-aware MoE heads (2개의 sequential layers, sizes 256 and 1, -> IPA, SQI 예측에 사용됨).
PAPAGEI는 두 가지 변형이 있다.
- PAPAGEI-P (Participant-aware): 같은 사람의 PPG 세그먼트를 positive pair로 묶는 contrastive learning.
- PAPAGEI-S (Signal morphology-aware): 혈관 저항, dicrotic notch 등 파형 지표(sVRI, IPA, SQI)를 활용한 self-supervised 학습.
🧩 Method
1. PAPAGEI-P (Participant-aware Objective)
기본 아이디어: 같은 사람의 PPG 신호는 서로 닮아있다는 점을 이용.
- Positive pair = 동일한 참가자의 두 PPG 세그먼트.
- Negative pair = 다른 사람의 PPG.
- Contrastive learning (SimCLR 변형)으로 학습.
- Time-series Augmentation 방법론: random cropping, Gaussian noise, time flipping, magnitude scaling, negation 등.
- 즉, 동일한 사람의 서로 다른 segment를 embedding space에서 가깝게, 다른 사람의 신호는 멀게 학습하도록 설계.
2. PAPAGEI-S (Morphology-aware Objective) 🌟
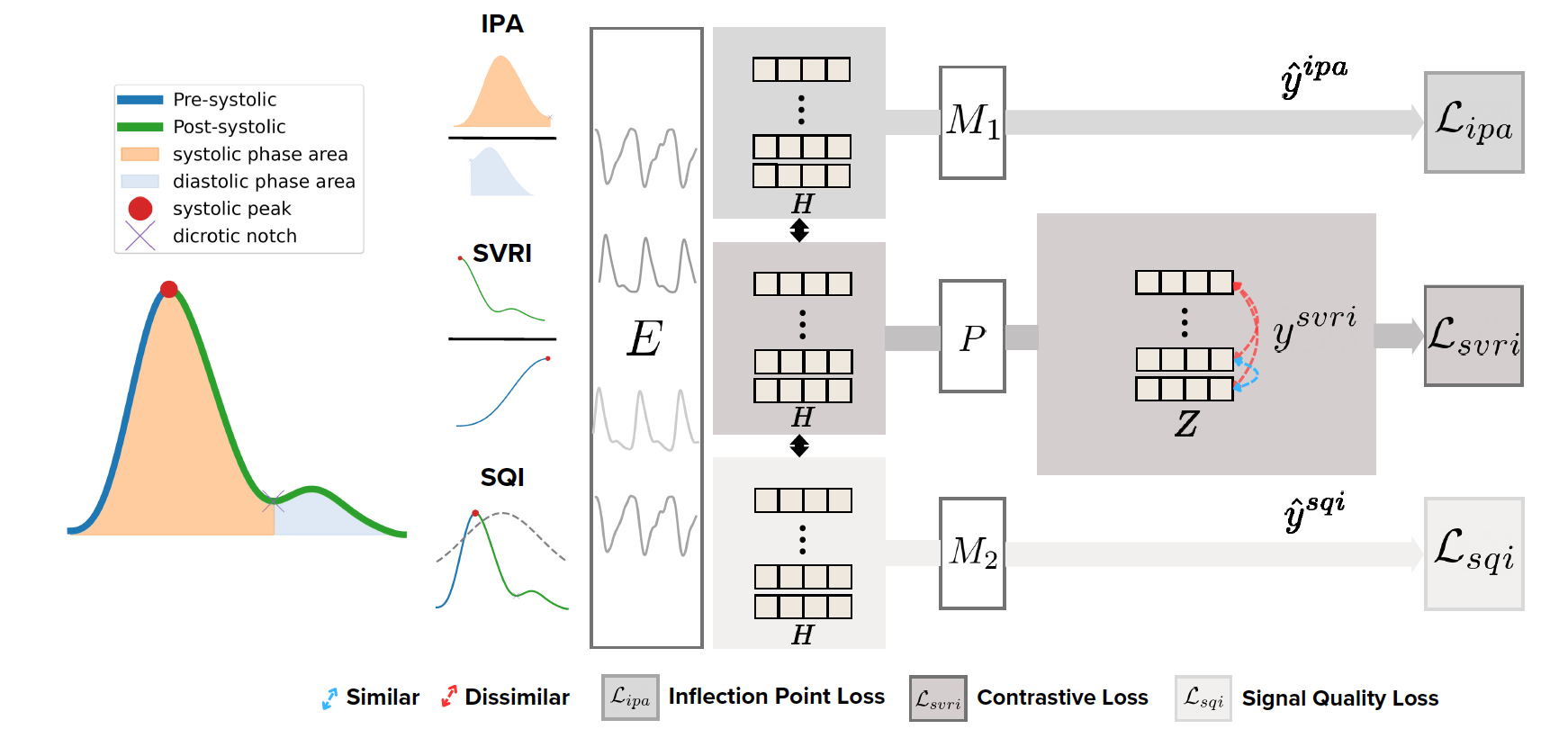
PPG 파형은 단순한 시간 신호가 아니라, 혈류역학적 특성이 반영된 생리학적 신호이다. 이러한 특성을 기반으로 비슷한 신호적 특성을 가진 segment를 positive pair로 짝지었다.
예를 들어:
- 수축기 파형 (Systolic peak)
- 이중절흔 (Dicrotic notch)
- 이완기 구간 (Diastolic phase)
등이 있음 (위 그림 참고)
PAPAGEI-S는 이런 형태적 지표(morphological indices)를 학습에 포함시켰다.
세 가지 주요 지표:
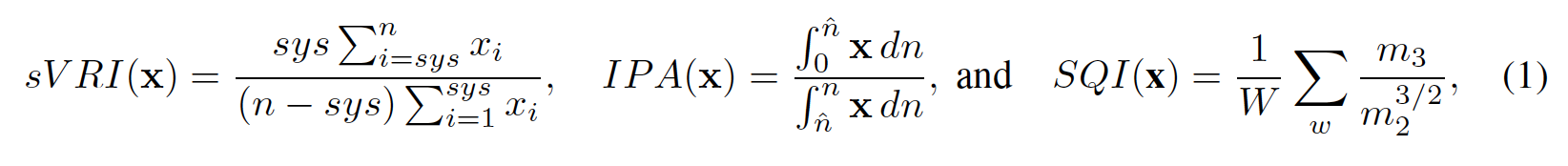
1. sVRI (Stress-induced Vascular Response Index): 수축기 전후 평균값 비율, 혈관 저항 변화를 반영.
2. IPA (Inflection Point Area ratio): 수축기 영역 vs 이완기 영역 면적 비율, 파형의 폭/넓이를 반영.
3. SQI (Signal Quality Index): 파형 왜도(skewness) 기반 신호 품질.
👉 이 세 가지를 이용해서 "비슷한 morphology를 가진 세그먼트끼리 embedding을 가깝게" 학습!
학습 Process:
- CNN 스타일의 Encoder (E) → Embedding (H) 추출.
- Projection head (P): sVRI 기반 contrastive loss.
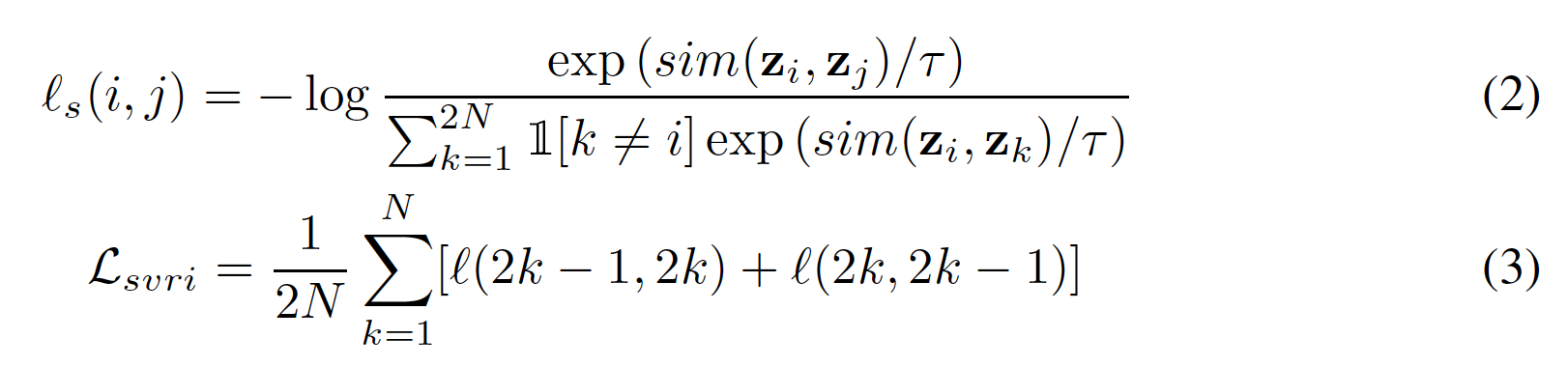
- 는 positive pair를 의미.
- (2) 가 anchor이고 가 positive pair일 때의 temperature-scaled cross entropy loss. 의 의미는 자기 자신과의 비교를 제외하기 위함.
- (3) 의 의미: 훈련 시 각각의 positive pair를 쌍으로 바로 옆 인덱스로 배치하여 넣어주기 때문.
- Mixture-of-Experts heads (M1, M2): IPA, SQI regression 학습.
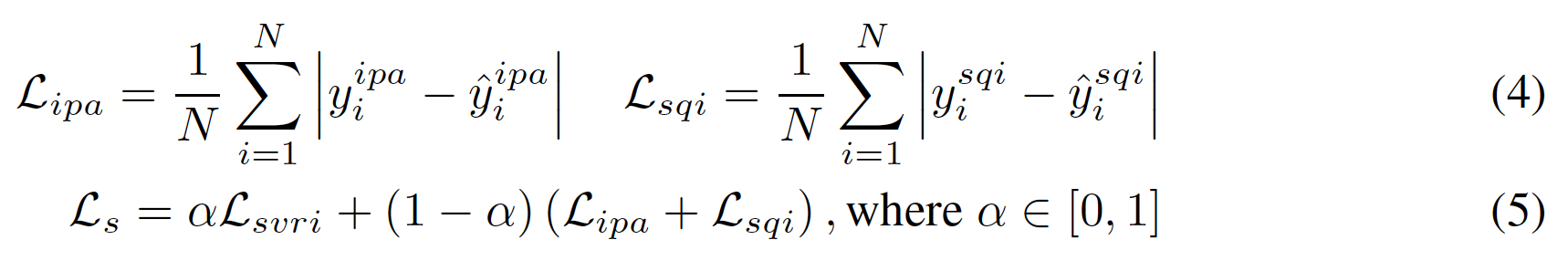
- (4) 나머지 IPA, SQI head는 간단한 FCNNs로 구성.
- (5) weighted sum으로 더해주어 최종 loss function 구현.
💎 Results
Downstream Tasks
- 총 20개의 Downstream Task를 진행.
- Training에 쓰이지 않은 새로운 DB에서도 Downstream Task를 정의하여 검증함 (아래 표 참고).
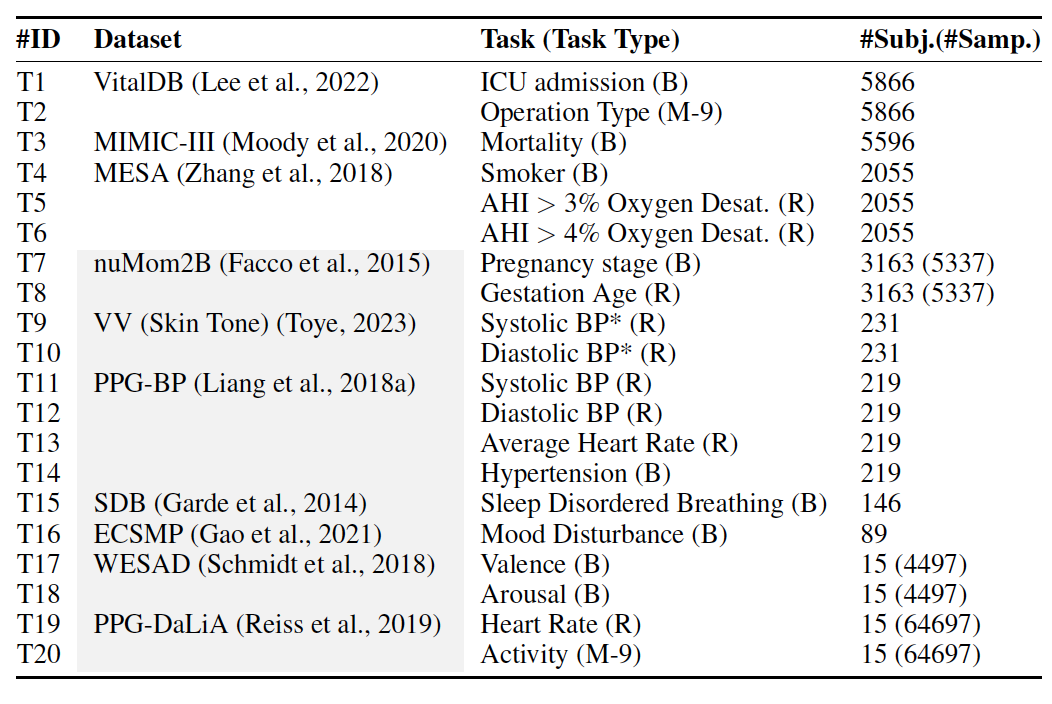
- Binary classification은 linear probe로 logistic regression model을 사용하고 AUROC로 평가.
- Regression task로는 ridge regression을 사용하고 mean absolute error (MAE)로 평가.
- Multi-class classification은 random forest model을 사용하였고 accuracy를 기준으로 평가.
- Robustness를 위해 bootstrapping을 통한 95% interval을 계산 (500 sampling runs with replacement)
Baselines
- 최신의 time-series FM 모델: Chronos, MOMENT
- 가장 널리 쓰이는 SSL 기법들: SimCLR, BYOL, TF-C
- REGLE (pre-trained on UK Biobank's PPG signals)
- statistical features (mean, median, maximum, minimum, 25th, 50th, 75th percentiles)
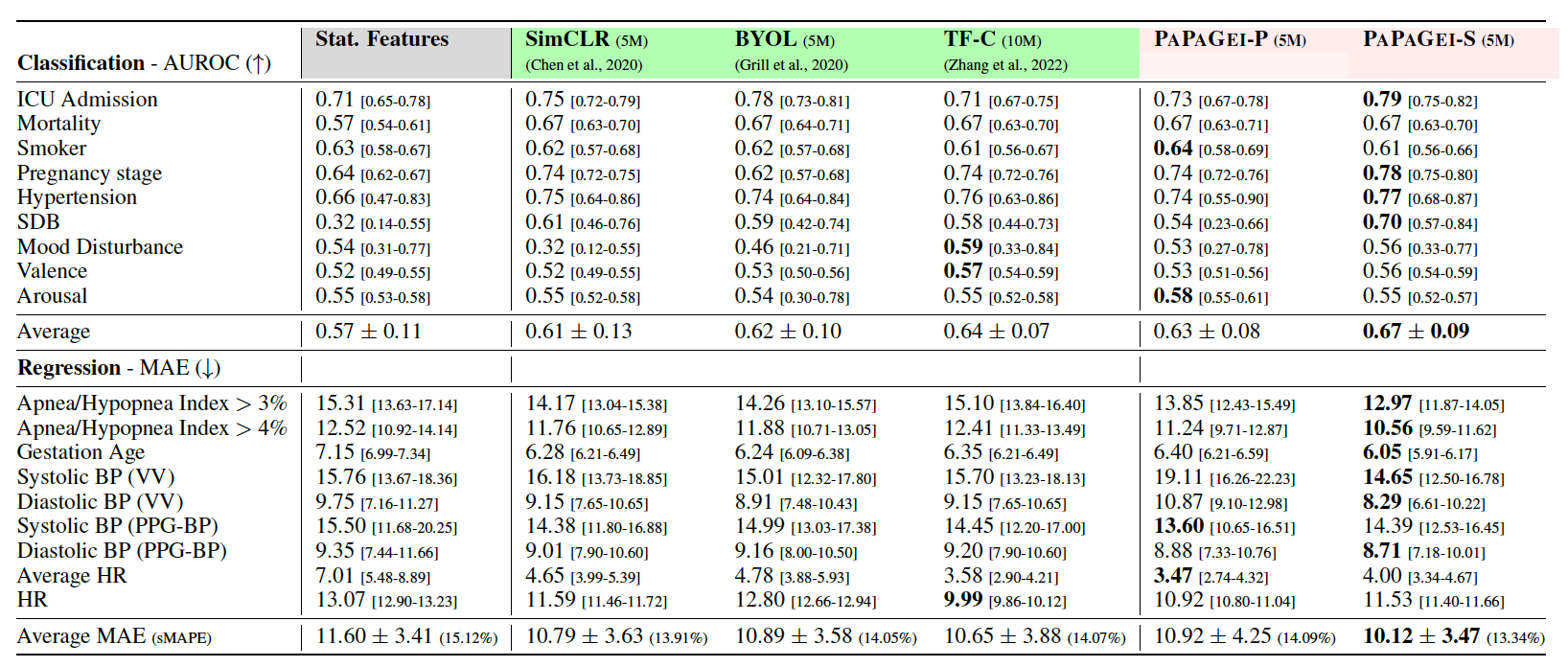
결과
- 각 태스크에 대한 Baseline 모델과 PaPaGei 모델의 결과. 위는 classification 태스크에 대한 AUROC를 나타낸 것(넓을 수록 좋음)이고, 아래는 regression 태스크에 대한 MAE(작을 수록 좋음)를 나타낸 것이다.
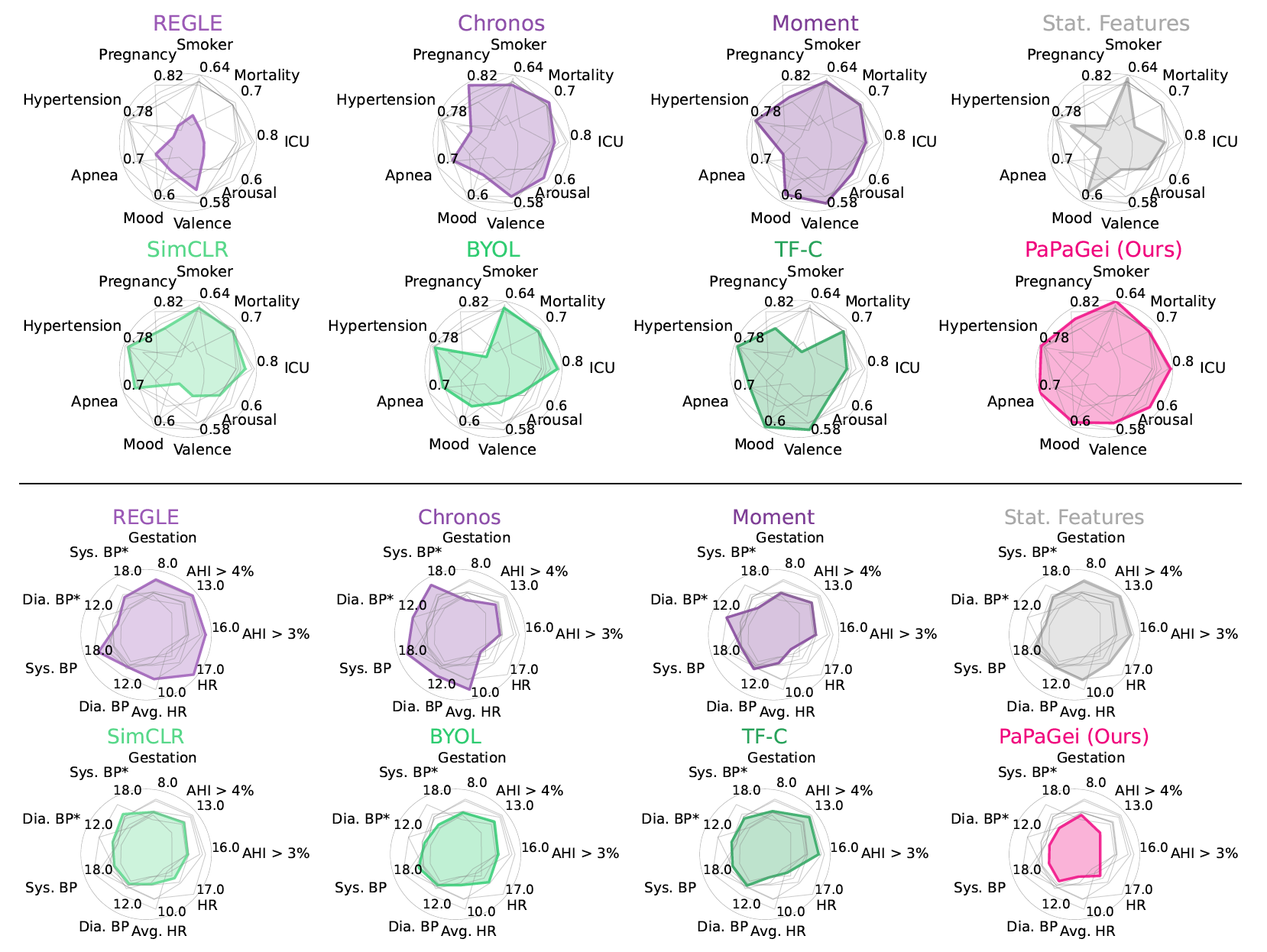
- Pre-trained model과 비교한 성능. PAPAGEI-S가 대부분의 태스크에서 가장 높은 성능을 달성하였다.
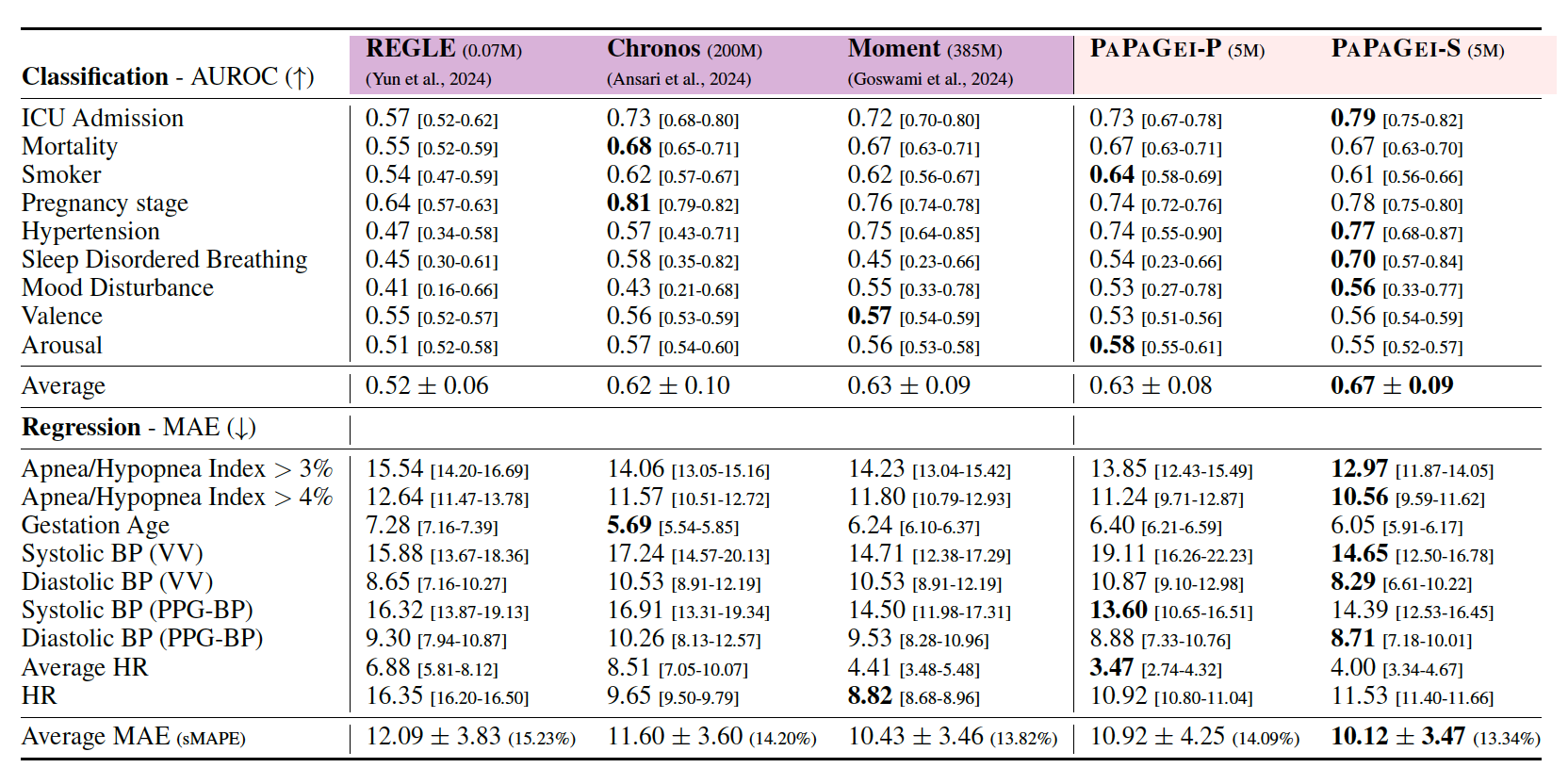
- Chronos는 Mortality, Pregnancy stage, smoking에서 좋은 성능을 보였는데 이는 해당 요인이 서서히 바뀌는 것이고 세분화된 PPG signal보다는 장기적인 변화에 더 연관이 있기 때문으로 추측된다.
- 그 외에 PPG-specific한 태스크 (heart-rate prediction, blood pressure estimation, sleep apnea)는 PaPaGei의 feature extraction 이후 더 높은 성능을 보였다.
- SSL 방법론들과의 비교한 결과 대부분의 태스크에서 PaPaGei가 가장 높은 성능을 달성.
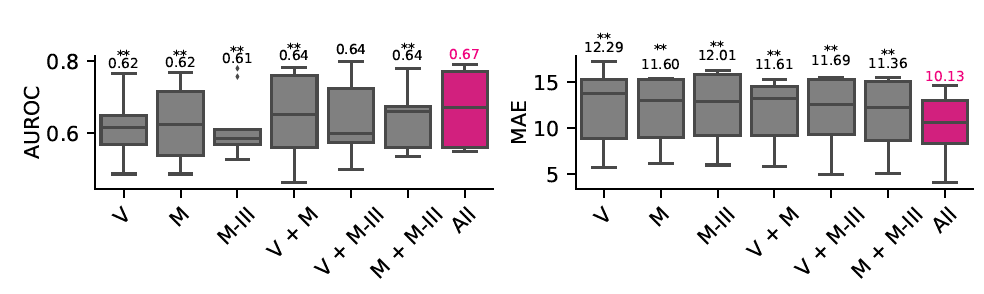
Abalation Studies
1. Pre-training data abalation
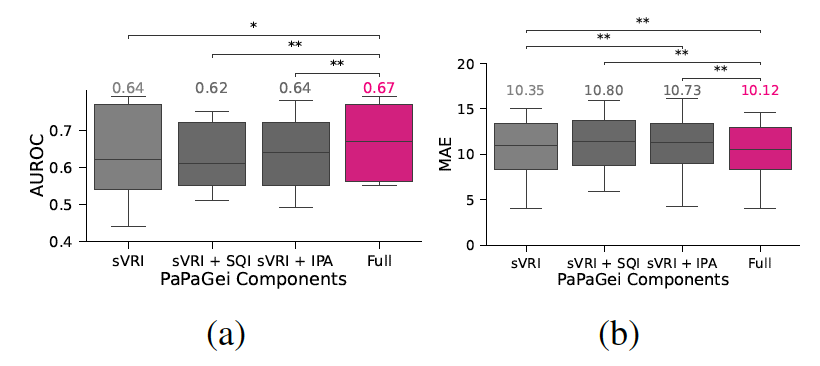
2. PaPaGei-S component abalation
3. Downstream data-efficiency analysis
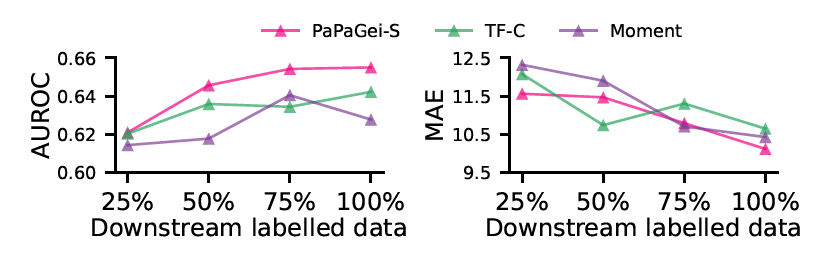
- Downstream task에서 label이 몇 %나 존재하는지에 따라서 그 성능을 비교(모든 binary classification의 성능을 평균, regression task 성능을 평균)
- Foundation Model의 장점은 라벨이 적은 현실 상황에서도 다양한 downstream task에 잘 작동해야 함. 따라서 이러한 limited-data 시나리오 실험을 진행.
- 25%, 50%, 75%, 100% 를 각각 학습 데이터로 사용 (테스트 데이터 셋은 따로 분리하여 존재함. 학습용 라벨 데이터의 양만 조절하는 것)
- PaPaGei는 라벨이 25%만 있어도 꽤 좋은 성능을 보이고, 라벨이 증가하는 상황에서 지속적인 performance gaind을 얻는 것을 볼 수 있음.
4. Model size and scaling analysis
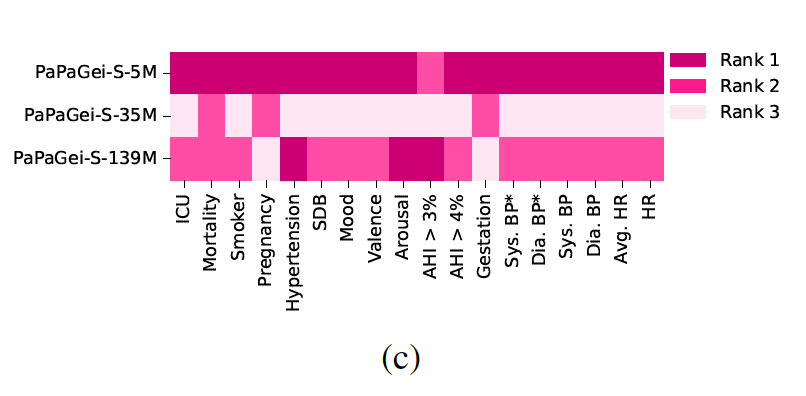
- Smallest model (5M parameters)가 지속적으로 좋은 성능을 보임.
- Non-monotonic 한 형태를 보이는 것으로 보아 scale은 성능에 큰 영향이 없는 것으로 보임.
- 의료기기나 웨어러블에 실용적임.
5. Effect of Demographics
- Age와 Sex prediction을 평가해보았을 때, 기존의 Apple 모델보다는 성능이 떨어졌음. 그러나 Apple DB와 모델은 공개되어있지 않기 때문에 공정한 비교가 어려움.

- Demographic 정보를 feature와 함께 결합한 embedding의 경우 (당연히) 성능이 더 오르는 것을 확인함. 그러나 demographic 정보의 경우 실제 상황에서 쉽게 얻을 수 없을 뿐더러 real-time으로 예측해야 하는 blood pressure이나 heart rate에 적용하기 어렵다. 따라서 기본 모델에서는 제외시켰다. 그러나 확실히 demographic을 추가하는 것은 downstream task 성능을 올림.
📎 Discussion
- 최초의 공개 PPG 파운데이션 모델 → reproducibility & transferability 보장.
- morphology-aware SSL 접근 → 생리학적 특성을 반영한 representation 학습.
- 다양한 downstream 태스크에서 일관된 성능 향상.
- 데이터셋 편중: 아직 다양한 인종/디바이스 환경 반영 부족.
- 피부색 bias 문제 여전히 존재 (어두운 피부톤에서 BP 추정 성능 저하).
- 멀티모달 융합(ECG, Accelerometer 등) 확장 필요.
