[ICLR 2024] Large-scale Training of Foundation Models for Wearable Biosignals (Apple)
Foundation Models for Health
현업에서 데이터를 다루다 보면, 데이터는 많지만 라벨이 없는 경우가 굉장히 많다. 특히 웨어러블 기기에서 수집된 생체 신호는 더더욱 그렇다. 이런 경우, 기존의 지도학습(supervised learning) 방식만으로는 한계가 있기 때문에, Self-supervised Learning(자기 지도 학습) 기법이 매우 유용하게 사용될 수 있다.
예를 들어, 생체 신호를 활용해서 수면 단계 분류, 혈압·심박수 예측, 수면 무호흡증 탐지, 스트레스 수치 예측, 특정 질병의 위험도 예측 등의 다양한 태스크가 정의된다. 이 태스크들은 대부분 동일한 입력 신호(예: PPG, ECG, 가속도 등)를 사용하고, 출력만 다른 경우가 많다.
"같은 입력을 바탕으로 다양한 태스크를 해결할 수 있다면, 생체 신호에 대한 좋은 representation을 먼저 학습해 놓고, 그 뒤에 태스크마다 분류기만 바꾸어가면서 원하는 문제를 해결할 수 있지 않을까?"
이러한 접근에서 출발한 개념이 바로 Foundation Model(기초 모델)이다.
텍스트 분야의 BERT, GPT처럼, 생체 신호에서도 다양한 downstream task에 활용 가능한 범용 모델을 만들 수 있다면, 의료 AI의 개발 속도는 훨씬 더 빨라질 것으로 예상된다.
본격적인 논문 리뷰를 시작하기 전에, 생체 신호가 수집되는 센서와 Foundation Model의 핵심인 SSL의 개념에대해 간단히 짚고 가자.
1. PPG
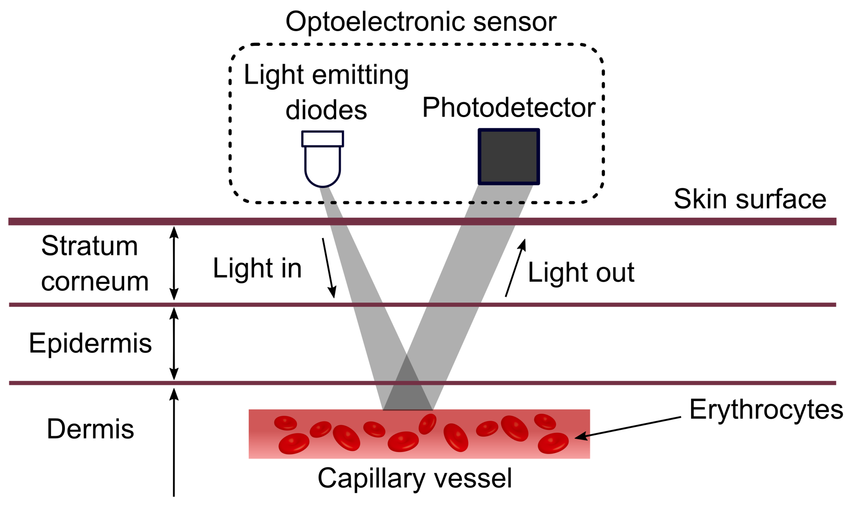
- PPG 센서는 심장 박동에 따른 혈관 용적 변화를 감지하여 맥박을 측정하는 광학 센서이다. 주로 LED를 통해 신체 조직에 빛을 쏘고, 반사 또는 투과되는 빛의 양을 분석하여 맥박 파형을 얻는다.
- PPG 센서에서 피부로 빛을 쏠 때, 혈류량에 따라 흡수되는 빛의 양이 달라진다. 따라서 빛이 얼마나 흡수됐는지를 측정하면, 혈액량의 변화를 알 수 있다.
- PPG로 맥파뿐만 아니라 산소포화도도 측정할 수 있다. 적외선 및 적색광을 이용해 혈류량 변화를 계속 지켜보면서 혈중 산소 포화도(SpO2)를 측정할 수 있다. 이때는 적혈구에 결합된 산소화 헤모글로빈과 비산소화 헤모글로빈의 광 흡수도 차이를 검출해서 측정하게 된다. 맥파 측정에는 적색광 대신 녹색광을 주로 쓴다.
- 대표적으로 웨어러블 기기에서 수집되는 신호 중 하나이다.
- 이 외에도 ECG(심전도), ACC(가속도계), 피부 온도 센서 등이 있다.
2. SSL (Self-supervised learning)
- Self-supervised learning이란, 라벨이 없는 데이터를 활용하여 학습하는 방식으로, 데이터셋의 representation을 학습하는 방법이다.
- Unsupervised learning이라고 볼 수 있는데, 최근에는 self-supervised learning이라고 부르고 있다. 그 이유는 라벨 없이 인풋 자체를 타겟으로 변형시켜 (self 자체를 target으로 정해서 supervision 방식으로 모델 학습) 학습하기 때문.
- SSL의 태스크를 "pretext task", 일부러 어떤 구실을 만들어서 푸는 문제라 부른다. pretext task를 학습한 모델은 downstream task에 transfer 하여 사용할 수 있다.
- SSL의 목적은 downstream task를 잘 푸는 것이기 때문에, 기존의 unsupervised learning과 다르게 downstream task의 성능으로 모델을 평가한다.
- 자세한 내용은 블로그 참고
Large-scale Training of Foundation Models for Wearable Biosignals (ICLR2024) [Apple]
이 논문은 Apple에서 ICLR2024 학회에 발표한 논문으로, PPG와 ECG 를 각각 활용하여 Foundation Model을 구축하였고, 이러한 모델들이 개인의 demographic과 health condition을 잘 예측하는 것을 보였다.
Introduction
1. Foundation Model의 장점은 다음과 같다.
- 라벨이 있는 supervised model 보다 더 적은 labeled 데이터를 필요로 한다. 특히 헬스케어 산업에서 돈이 많이 들고 시간이 오래 걸리는 의료진의 데이터 라벨링 없이도 동일한 성능의 모델을 학습할 수 있다.
- 여러 downstream task가 존재할 때, 각각의 모델을 from scratch로 학습시킬 때 보다, pretrained 파운데이션 모델을 활용하면 downstream target마다 fine-tuning만 하면 되므로, 좀 더 높은 성능을 적은 컴퓨팅 리소스를 가지고 빠르게 달성할 수 있다.
- 마지막으로, 이와 같이 생체 신호를 임베딩으로 표현할 수 있다면, 유저들 사이 혹은 시그널들 사이의 similarity를 계산할 수 있도록 함으로서, 더 빠른 information retrieval을 가능하게 한다. 즉 라벨이 없더라도 신호 간의 유사도를 측정할 수 있고, 이걸 기반으로 검색, 분류, 이상 감지, 개인화 등에 활용할 수 있다는 뜻이다.
- 예를 들면, 과거에 “심방세동”이 있었던 사람들의 임베딩을 미리 저장해두고, 새롭게 들어온 사용자의 PPG 임베딩이 그것들과 유사하다면 → 의심되는 징후를 미리 포착 가능
2. 논문의 Contribution Point
- Large-scale pre-training for biosignals: 총 141,207 환자의 wearable device (Apple Watch Series) 를 통해 수집한 PPG와 ECG 데이터를 활용하여 파운데이션 모델을 구축하였다.
- Self-supervised learning network: stochastic participant level augmentation module을 사용하였고, InfoNCE loss를 사용하여 학습하였다.
- Studying information encoded by the pretrained foundation models across various targets: 여러 타겟 다운스트림 태스크 (인구통계적 정보 예측, 헬스 컨디션 예측 등)
- Abalation studies: 대표적인 SSL 구조인 SimCLR와 BYOL모델과 우리 모델의 성능을 비교하여, 그 우월성을 검증하였다.
Model Architecture
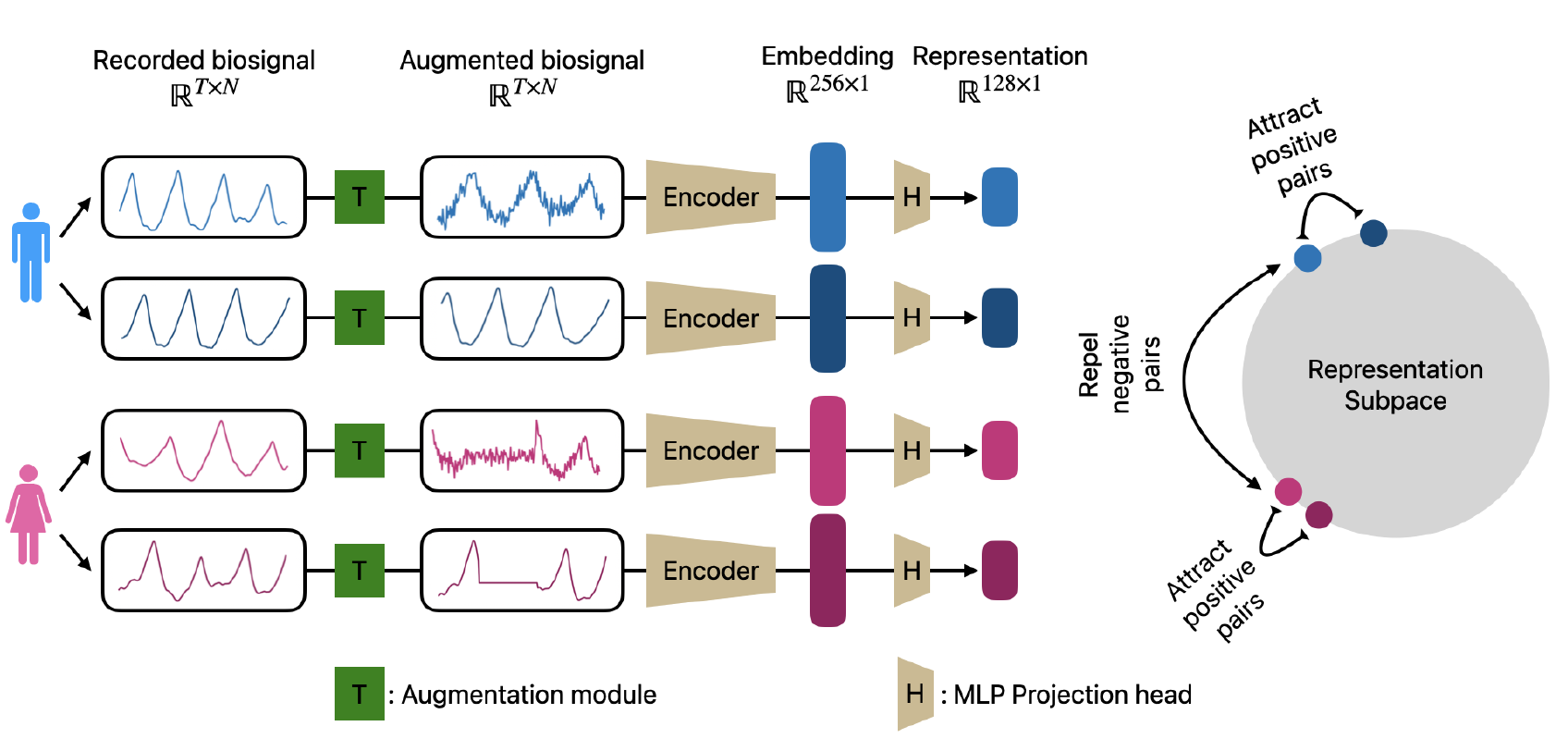
1. Positive Pair Selection and Augmentations
- 한 명의 환자에서 서로 다른 signal segment를 골라 positive pair를 생성한다.
- Augmentation module은 여러 time-series augmentation 기법을 적용하였는데, 대표적으로 crop, Gaussian noise, time warp, magnitude warp, channel swap 등의 기법이 있다.
2. Regularized InfoNCE Loss
- InfoNCE loss란, 나의 positive pair과는 가깝게, 다른 positive pair 그룹과는 멀어지게 학습시키는 loss이다.
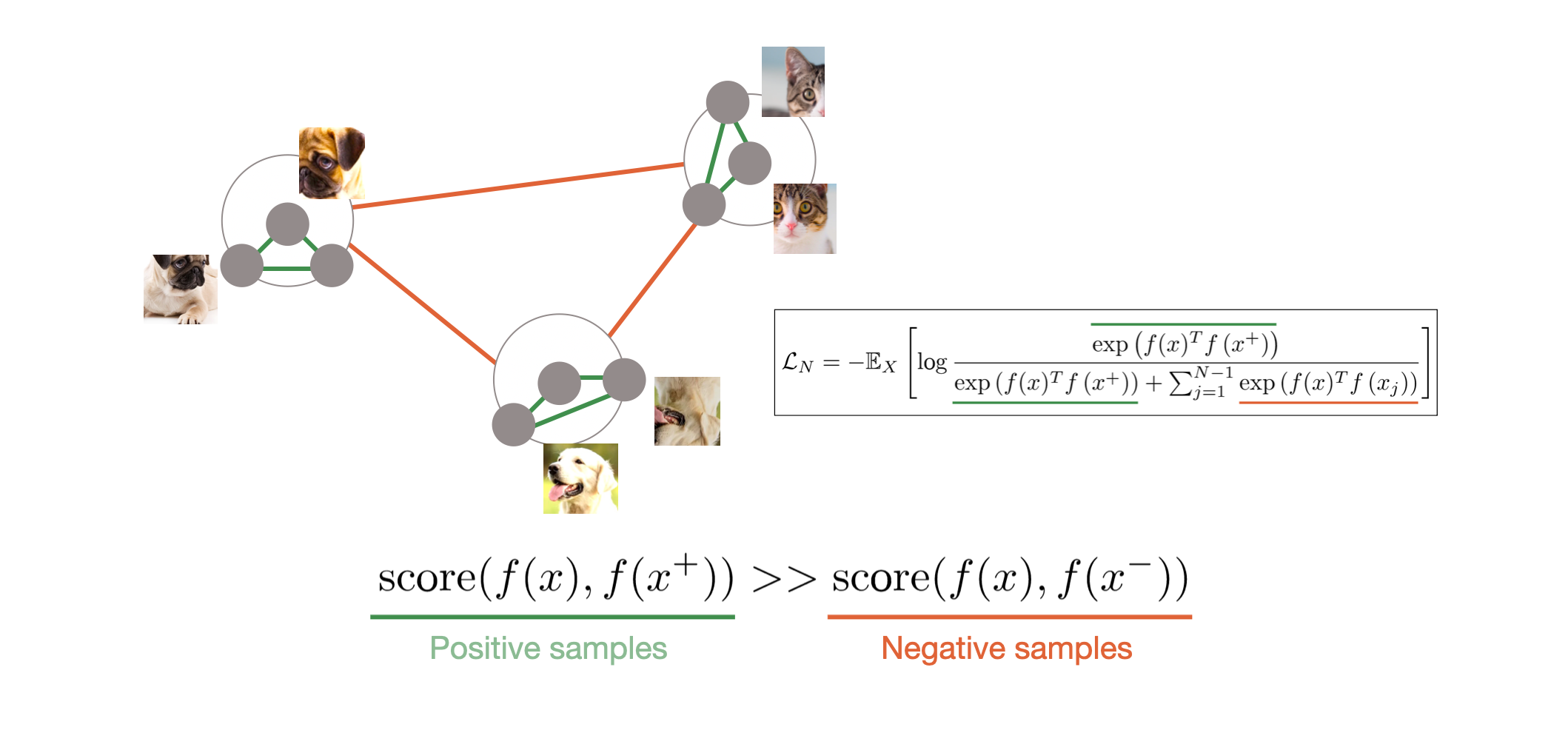
- 위 그림에서 score는 보통 cosine similarity를 사용한다.
- 논문에서는 다음과 같이 설명한다.

- 각 batch에서 서로 다른 환자들에서 생성된 positive pair 끼리는 멀리, 같은 환자 내의 positive pair 사이의 거리는 가깝게 하고 싶음.
- 여기에 KoLeo(Kozachenko-Leonenko) regularization term을 추가해서, embedding 벡터들이 batch 내에서 고르게 퍼지도록 한다.
- 이러한 정규화가 필요한 이유는, InfoNCE loss는 positive pair는 서로 가깝게, negative pair는 서로 멀게 만들도록 학습시킨다. 이렇게 학습하다 보면 모델이 모든 embedding을 좁은 공간에 몰아넣는 경향을 보일 수 있다 (representation collapse / embedding space collapse).
- 이 정규화는 embedding 벡터에서 다른 pair 벡터까지의 거리를 기반으로, 샘플들의 분포가 얼마나 퍼져있는지 (entropy) 추정한다.
- : 번째 샘플의 1번 embedding (1번, 2번 중)
- : 를 제외한 나머지 중 가장 가까운 샘플과의 거리
3. Implementation Detail
- 모델은 EfficientNet-style 1D CNN을 사용하였고, 16 mobile-inverted bottleneck block을 사용하였다. 256-dimensional embedding을 사용하였다.
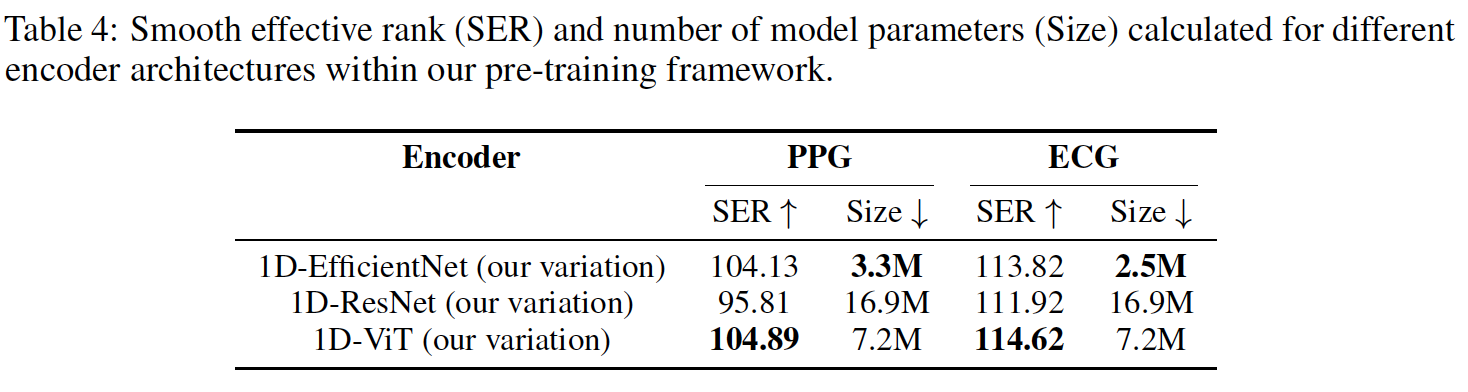
- Abalation Study에서 여러 Encoder architecture를 비교했는데, 거의 비슷한 성능을 보였지만 size면에서 1D-EfficientNet이 가장 효율적이었기 때문에 (wearable device에서 돌아가야 하기 때문) 이를 선택하였다.
Dataset
- 본 연구에 사용된 데이터셋은 free-living 상황에서 Apple Watch를 통해 수집되었으며, 141K의 환자들의 3년간의 데이터이다.
- PPG pre-training dataset:
- 각 환자들에서 최소 4개의 PPG segment (60 seconds)를 뽑았고,
- 각 환자들마다의 segment 개수는 최대한 동일하게 맞추었다.
- 4 channels, pre-processed using dark subtraction, bandpass filtering, down-sampling to 64Hz, channel-wise z-scoring for each segment.
- ECG pre-training dataset:
- 30 seconds, 512 Hz
- downsampling to 128Hz, temporal z-scoring for each segment.
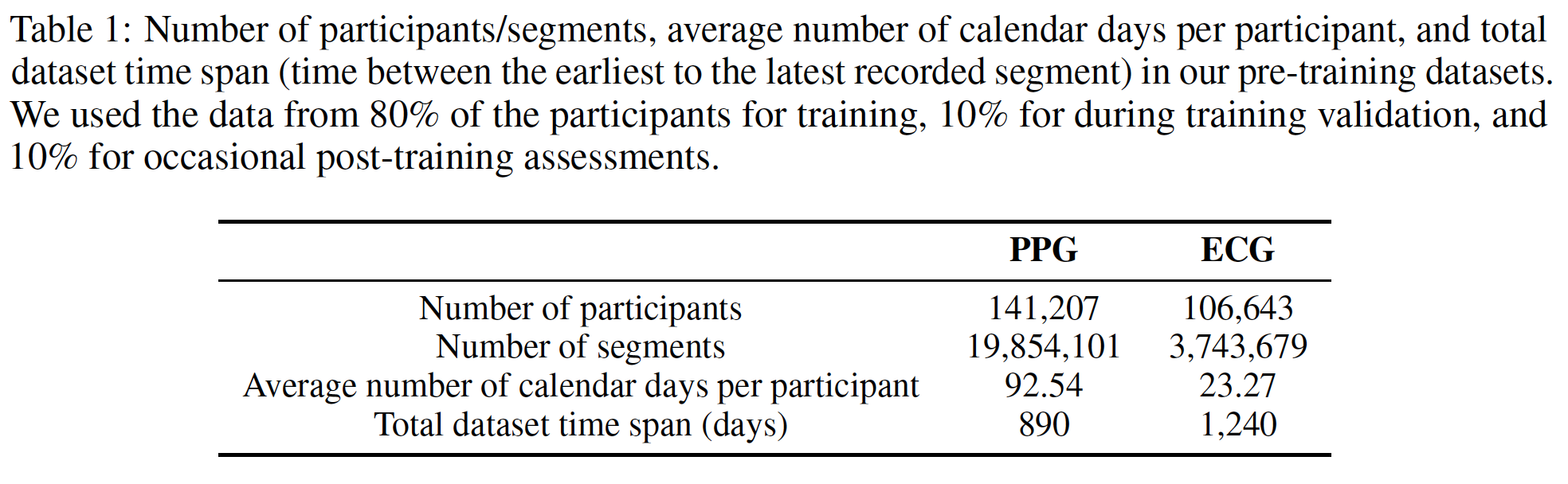
Evalution
1. Linear probing age, BMI, and biological sex & Linear probing for targets from AHMS survey questions
- 사전 학습된 모델의 encoder를 고정(freeze)시켜 놓고, 그 위에 선형 분류기(linear classifier) 하나만 얹어서 성능을 평가하는 방법.
- 논문에서는 PPG/ECG로부터 각각 임베딩을 뽑은 후, 그 위에 ridge regression 기반의 linear classifier 를 학습해서 다음을 예측하였다.
- 나이 (50세 이상 vs 이하 분류 & 값 맞추기)
- BMI (30 이상 vs 이하 분류 & 값 맞추기)
- 생물학적 성별
- Survey Question에 자가 보고한 건강 상태 (e.g. 고혈압, 약물 복용 여부)
- 각 환자들의 embedding은 모두 mean-aggregate 시켜서, 각 환자별로 하나의 샘플만 사용하도록 했다.
2. Smooth effective rank
- 라벨 없이도 임베딩의 sigualar value distribution 을 통해 임베딩의 다양성, 다차원성을 entropy로 계산하는 방법.
- 이 값이 높을 수록 downstream 성능이 좋다고 증명됨.
- 높다: embedding 공간이 여러 차원에 고르게 퍼져 있음 → 다양성 ↑, 표현력 ↑
- 낮다: 대부분의 정보가 소수의 차원에만 집중되어 있음 → 표현력 ↓, collapse 위험 ↑
Result
1. EEG vs. PPG 모델
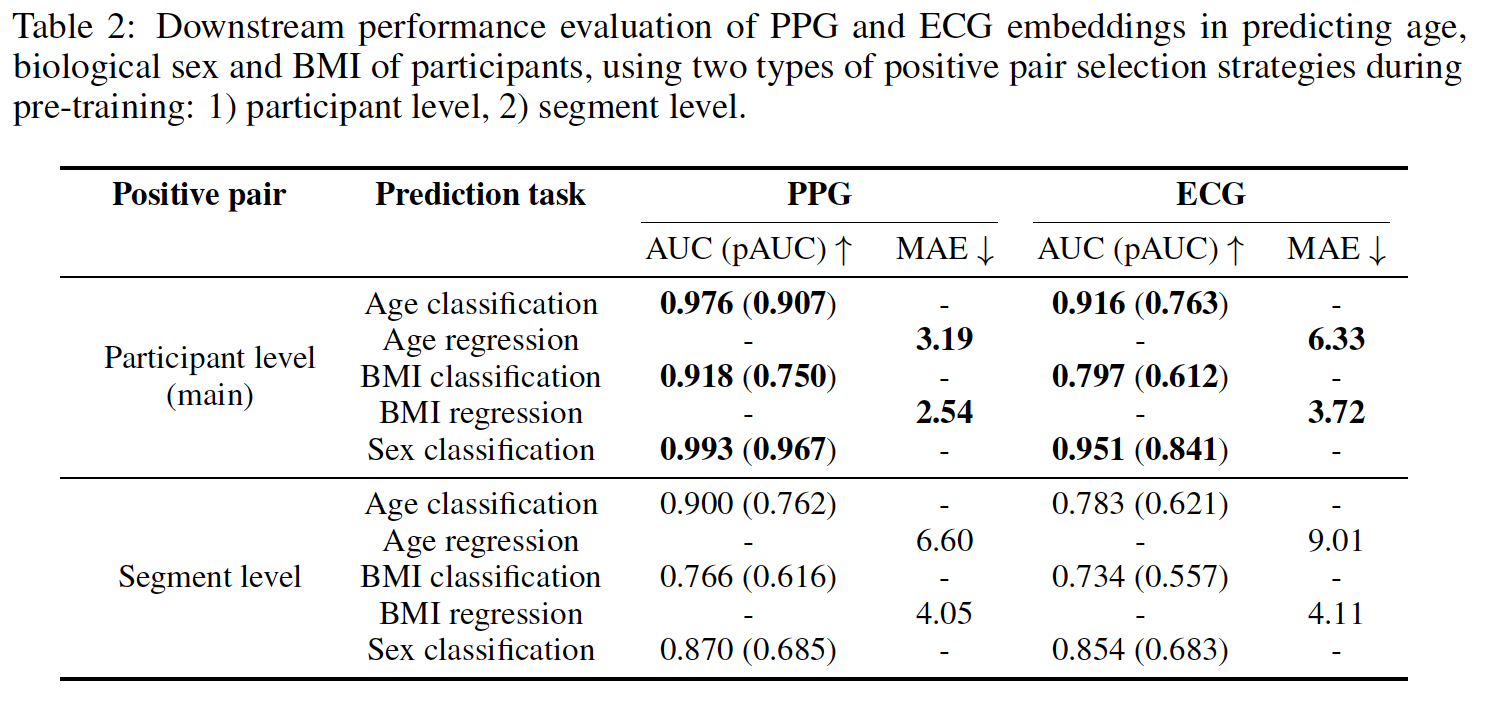
- segment level: 같은 segment안에서 다른 augmentation을 취해서 postive pair를 만드는 것.
- participant level: 같은 환자 내의 서로 다른 segment를 augmentation 하여 positive pair를 만든 것. (성능이 훨씬 좋았음)
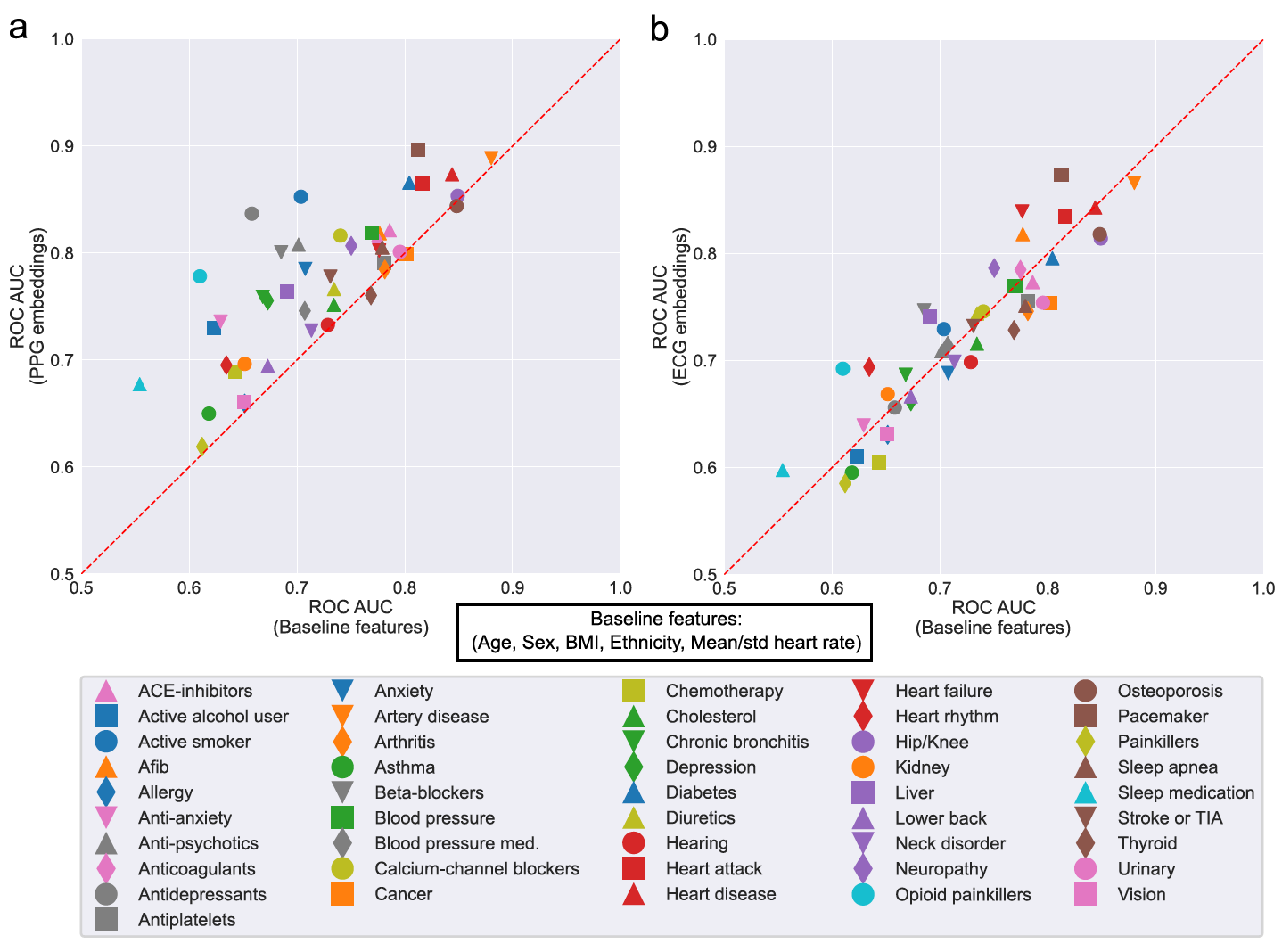
- baseline feature: 나이, 성별, BMI, ethinicity, avg. HR & std. HR 등을 baseline feature로 만들어 ridge regression 모델 학습.
- 두 태스크 모두 일관적으로, PPG 모델이 downstream task에서 더 좋은 성능을 보였다.
2. t-SNE representations / InfoNCE loss / Dispersion ratio
- 아래 실험들은 ECG 임베딩과 PPG 임베딩의 차이를 보여주고 있다.
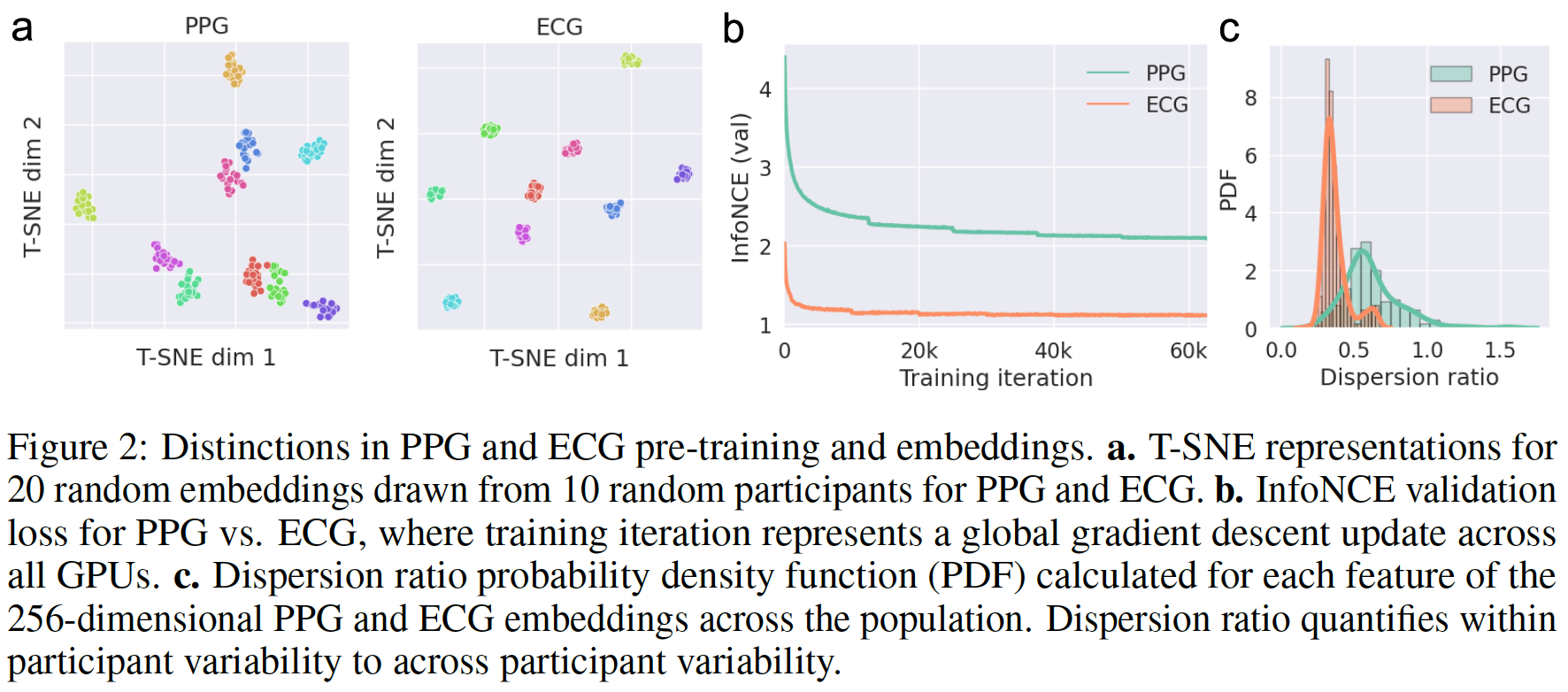
- t-SNE representation을 보면, ECG 임베딩 클러스터가 환자별로 좀 더 모여있는 것을 볼 수 있다. 환자 안에서도 PPG보다 ECG 임베딩끼리 더 비슷하다는 것을 보여주고 있다. (이 때문에 ECG augmentation을 PPG보다 더 높은 확률로 주었다)
- InfoNCE loss 또한, ECG가 월등히 낮은데, 이는 ECG를 가지고 환자를 구분하는 것이 더 쉽다는 것을 뜻한다.
- Dispersion ratio에서 ECG가 더 낮은 ratio를 보였는데, 이는 ECG가 동일 환자 내에서 variance가 낮고, 서로 다른 환자들 사이에서는 variance가 크다는 것을 의미한다.
3. Pre-training framework 비교
- 구글에서 발표한 SSL의 유명한 framework인 SimCLR (contrastive) 와 BYOL (non-contrastive)을 데이터에 적용하여 본 논문에서 제시한 framework와의 성능을 비교하였다.
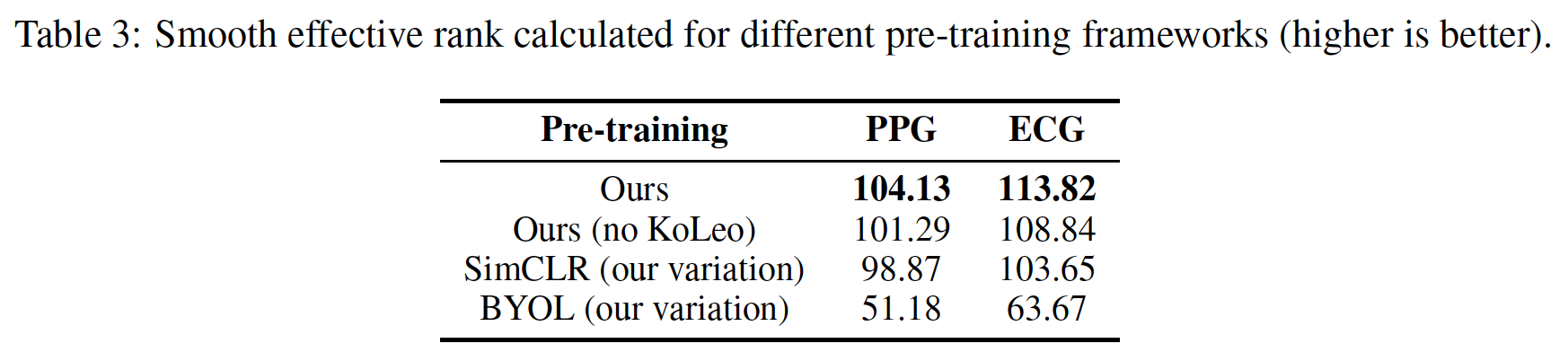
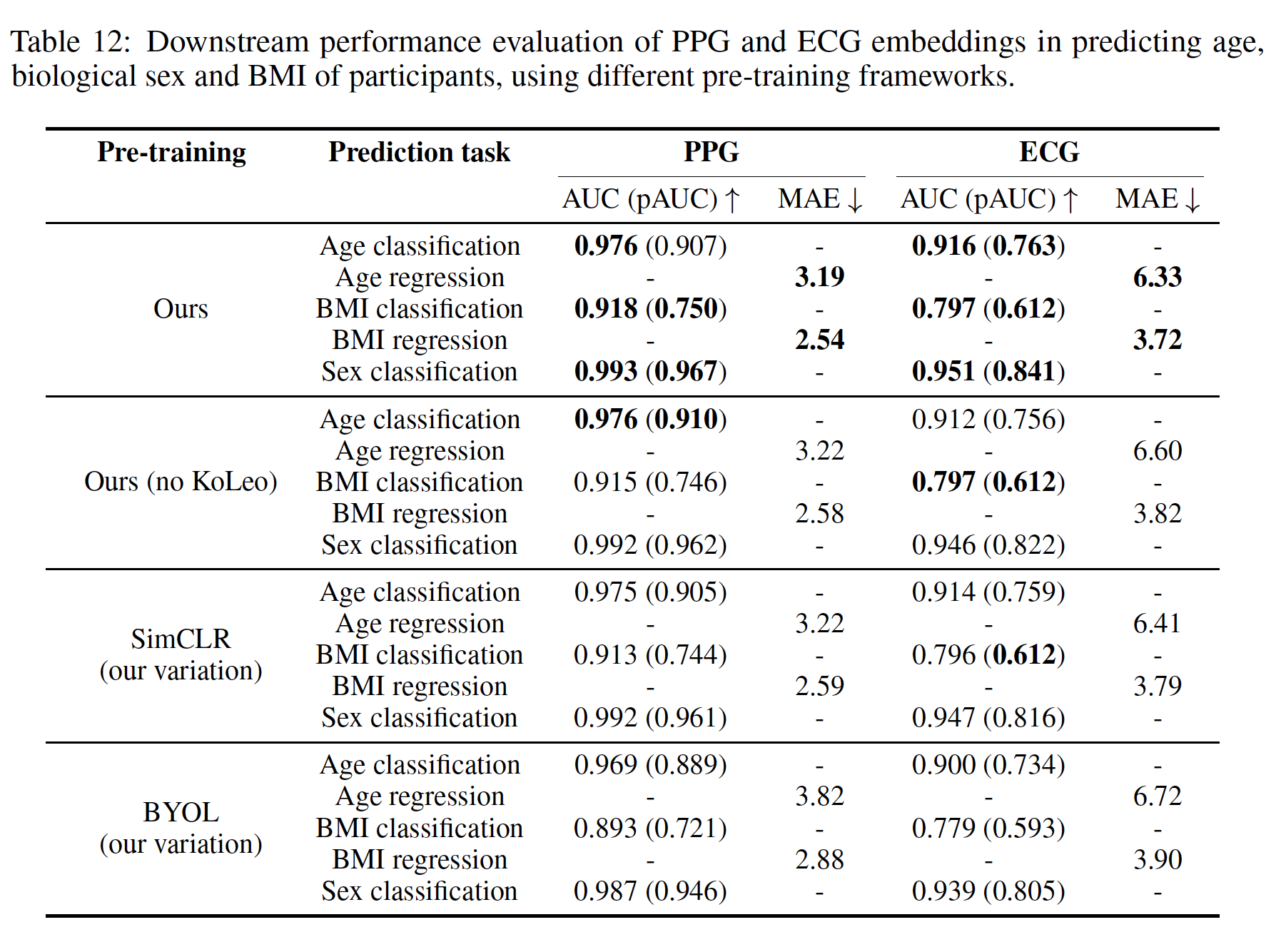
- 본 논문에서 제시한 pre-trained framework가 가장 성능이 좋았으며, contrastive framework인 경우 더 robust한 성능을 보였다. 또한 KoLeo 정규화가 없는 경우에도 성능이 하락하는 것을 보여주었다.
아래 두 방법은 Google에서 발표한 contrastive learning / non-contrastive self-supervised learning의 대표적인 모델이다.
3-1. SimCLR

- 왼쪽의 개 이미지와 오른쪽의 의자 이미지에 각각 augmentation을 적용하여 2개의 positive sample 쌍을 생성한다.
- positive pair는 같게, negative pair는 서로 멀어지도록 학습
- InfoNCE Loss 와 다른 점: 동일한 컨셉이지만 SimCLR는 batch 내 모든 augmented pair를 postitive/negative pair로 활용한다는 점에서 다르다. 예를 들면 batch size가 N이라면, 각 쌍(i, j)는 positive pair이고, 나머지 2N-2개는 negative로 간주한다 (실제로 8192의 매우 큰 batch size 사용). 그 외에 temperature scaling, cosine normalization 등을 추가해 성능을 높인 버전이다.
3-2. BYOL (Bootstrap Your Own Latent A New Approach to Self-Supervised Learning)
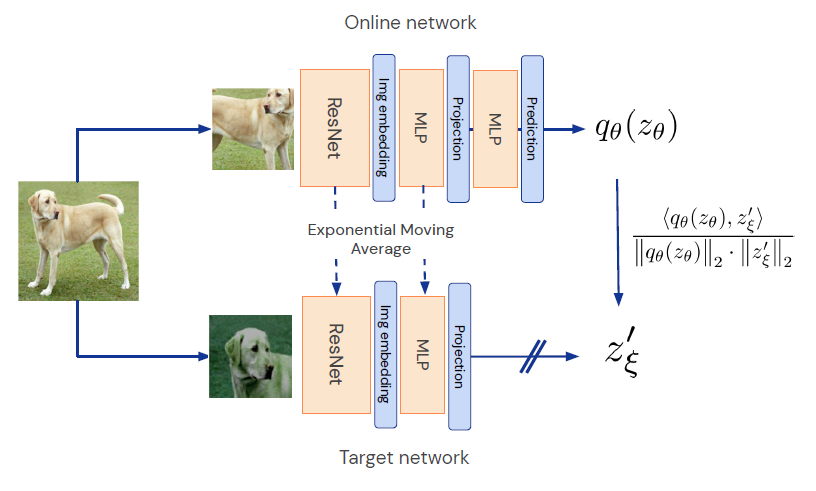
- BYOL에서는 negative sample이나 contrastive loss 없어도 더 좋은 성능을 낼 수 있다는 것을 보여주었다.
- 두 가지 네트워크, Online network와 Target network가 존재한다. 여기에서 두 augmented view를 각각 모델에 넣어주는데, 여기에서 Online network는 prediction을 하고, target network의 projection output을 가지고 학습을 한다. (즉, online이 target 출력을 모방하도록 학습)
- 그럼 target은 학습되지 않고, 대신 online network의 가중치를 느리게 (Exponential Moving Average) 따라간다.
- Online network와 Target network가 같은 구조가 아니기 때문에 같은 값으로 수렴하는 일이 일어나지 않으면서, 스스로의 출력을 바탕으로 점점 더 나은 표현을 만들어가는 과정(self-bootstrap)이 가능해진다.
Discussion
- Wearable device에서 수집한 대량의 데이터를 활용하여 pre-trained foundation models (PPG, ECG) 를 훈련.
- 각각 모델들은 인구 통계학적 정보와 환자들의 건강 상태를 예측하는데 성공적인 결과를 보임. 그 중에서도 PPG 모델이 EEG 모델보다 더 높은 성능을 기록하였음.
- Future work로는 multi-modality (PPG와 ECG를 동시에) 처리할 수 있는 encoder를 사용하거나
- CLIP-style의 multi-modal pre-training 방법을 사용하거나, (한 modality를 다른 modality의 target처럼 쌍으로 만들어서 학습시키는 것) multiple encoder를 동시에 사용하는 등의 방법들이 있을 것이다.
References
https://sanghyu.tistory.com/184
https://i-am-eden.tistory.com/47
https://nuguziii.github.io/survey/S-006/
https://arxiv.org/abs/2312.05409
https://arxiv.org/abs/2006.07733
https://arxiv.org/abs/2002.05709
https://github.com/google-research/simclr
