이전의 헬스 파운데이션 모델들은 웨어러블 신호를 직접 모델 인풋으로 넣어주었다면, 이제는 Raw Signal을 아예 LLM 모델 인풋으로 넣었을 때도 꽤 괜찮은 예측을 하는 연구 결과들이 나오고 있다. 웨어러블 데이터는 ‘언어로 표현하기 어려운 비언어적 신호’인데, AI가 이 신호를 이해하고 해석하려면, 데이터의 맥락을 읽고 의미를 언어로 풀어낼 수 있어야 한다. 이 문제를 풀기 위해 최근 연구들이 언어 모델(LLM) 과 웨어러블 센서 데이터를 결합하기 시작했다. 대표적인 두 연구가 바로 MIT의 「Health-LLM」(CHIL 2024) 과 Google Research의 「SensorLM」(arXiv 2025) 이다.
이 두 논문은 접근법은 다르지만, 공통적으로 “LLM이 인간의 생리 신호를 이해하고 설명하는 능력”을 보여주었다.
Health-LLM: Large Language Models for Health Prediction via Wearable Sensor Data (CHIL 2024)


1. Introduction
- LLM이 의료 분야에서 잠재력이 크지만, 비언어적·시계열 데이터(예: 심박수, 수면시간) 를 다루는 것은 아직 미흡.
- Wearable sensor 데이터를 이용해 소비자 건강 예측을 수행하는 LLM의 가능성을 평가.
- 12개의 최신 LLM(GPT-4, Gemini-Pro, Llama2 등)을 대상으로 10개 소비자 건강 예측 과제 수행.
2. Related Work
- Wearable + LLM 연구는 거의 없으며, 기존 연구는 텍스트 중심.
- 본 연구는 비언어적 센서 데이터와 사용자 맥락 정보(나이, 성별, 수면패턴 등) 를 함께 활용하는 최초의 종합적 시도.
3. Methods
3.1. Prompting 전략
-
Zero-shot Prompting: Pretrained LLM을 평가하기 위한 prompting. 센서 데이터를 자연어로 요약하여 LLM에 입력. 4가지 종류의 Context를 포함시킴 (User Context, Health Context, Temporal Context, All - 그림 참고)

-
Few-shot + CoT(Self-consistency): 몇 개의 예시를 포함하고, 논리적 추론 유도.
- Chain-of-Thoughts (CoT): 사람의 생각하는 과정처럼 모델이 단계를 밟아가며 문제를 해결하도록 유도하여 정확성을 높이는 방법.
- Self-Consistency (SC): 같은 질문을 5번 시도하게 한 뒤, 각각의 reasoning이 약간 다르더라도 가장 자주 등장한 응답을 선택하는 방법.
- Instruction tuning (fine-tuning):
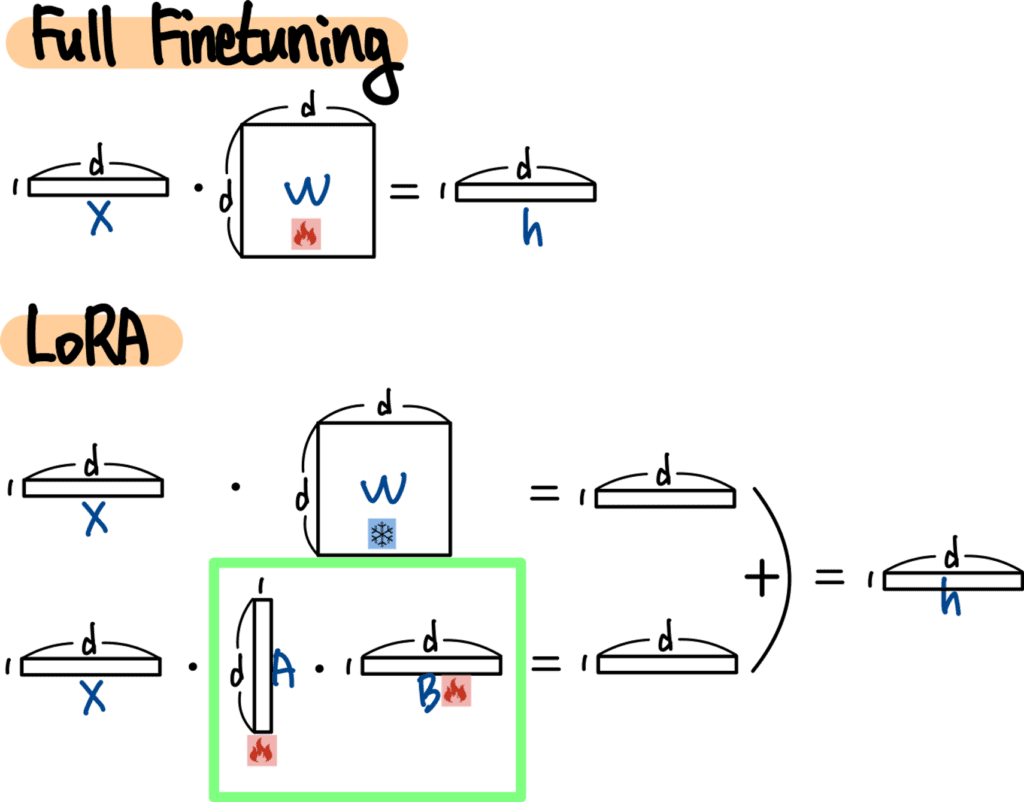
- LoRA (Low-Rank Adaptation) 기반 fine-tuning
- 전체 가중치를 학습시키지 않고, 작은 보조 행렬 2개만 추가해서 저차원 보정을 하는 방식
- 이 과정에서 LLM은 physiological terminologies, mechanisms, context 등을 학습하게 된다.
3.2. Temporal Encoding Methods
- Time-series data 를 text 포멧으로 바꾸는 방법
- Natural Language String Method: 14일의 센서 데이터가 있다면 {Nan, 991.0, ..., Nan} 과 같은 식으로 숫자 자체를 넣어줌.
- Physiological data by specific time windows (daily, weekly, monthly)를 명시하여 모델이 이해할 수 있도록 함.
4. Experiments
- PMData
- N=16, Fitbit Versa 2, 5 months
- 태스크: Stress, Readiness, Fatigue, Sleep Qualit
- LifeSnaps
- N=71, Fitbit Sense, 4 months
- 태스크: Stress Resilience, Sleep Disorder
- GLOBEM
- N=497, Fitbit, Multi-year
- 태스크: Depression, Anxiety
- AW-FB
- N=49, Apple Watch, Fitbit, 104 hours
- Calorie Burn, Acticvity
5. 모델 비교
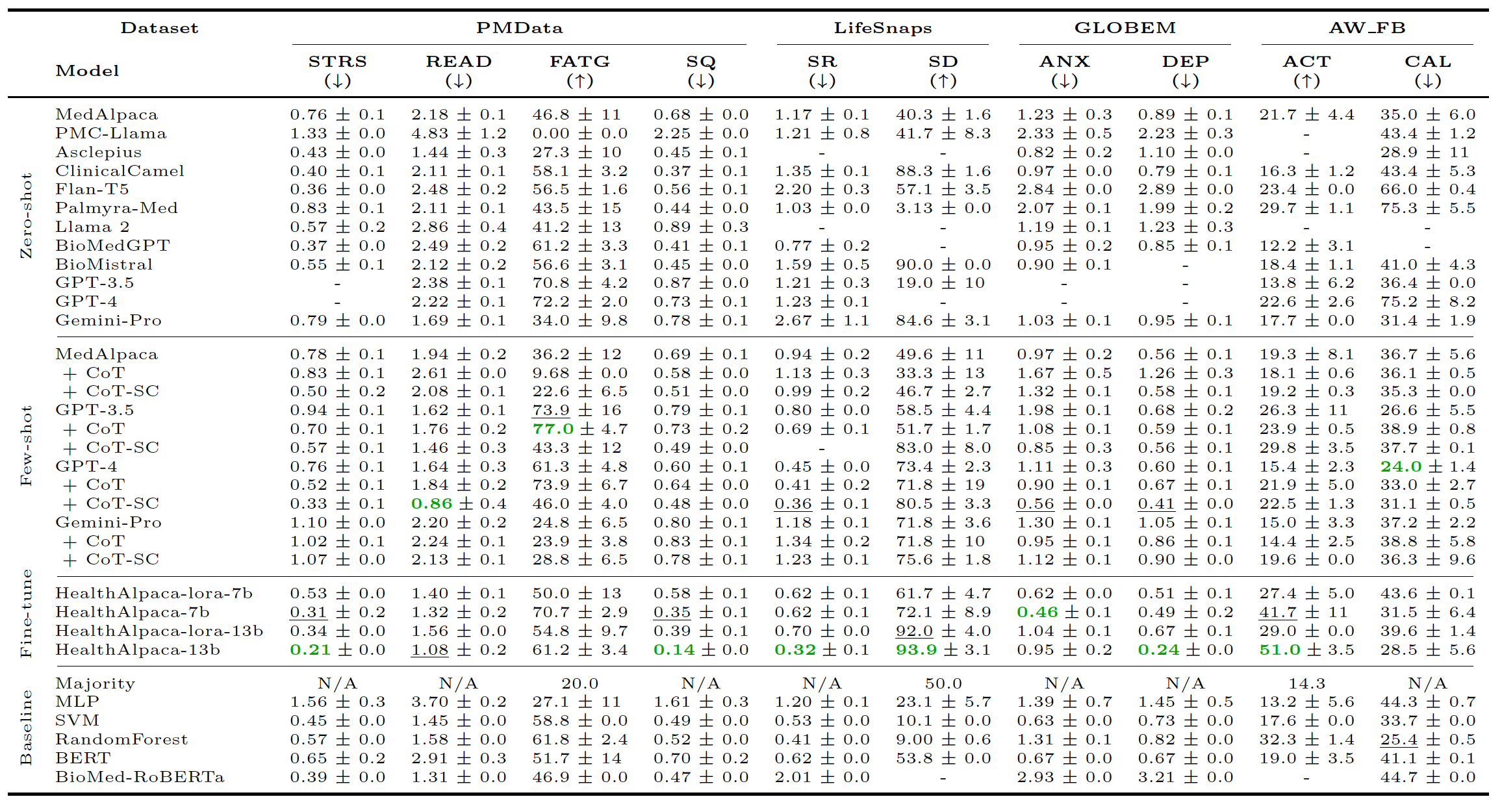
- 결론: 본 연구에서 제시한 Alpaca-based fine tuned model(instructional fine-tuning)인 Health Alphaca가 가장 좋은 성능을 보임.
6. Conclusion
- LLM이 단순 텍스트 처리뿐 아니라, 웨어러블 센서 기반 건강 예측에도 활용 가능함을 입증.
- Context-rich prompting이 핵심.
- HealthAlpaca를 오픈소스로 공개, 헬스 LLM 연구의 기반 제시.
- 한계: False and Hallucianted Reasoning from LLMs에 대해 아직 해결되지 못함.
SensorLM: Learning the Language of Wearable Sensors (Google Research, 2025)
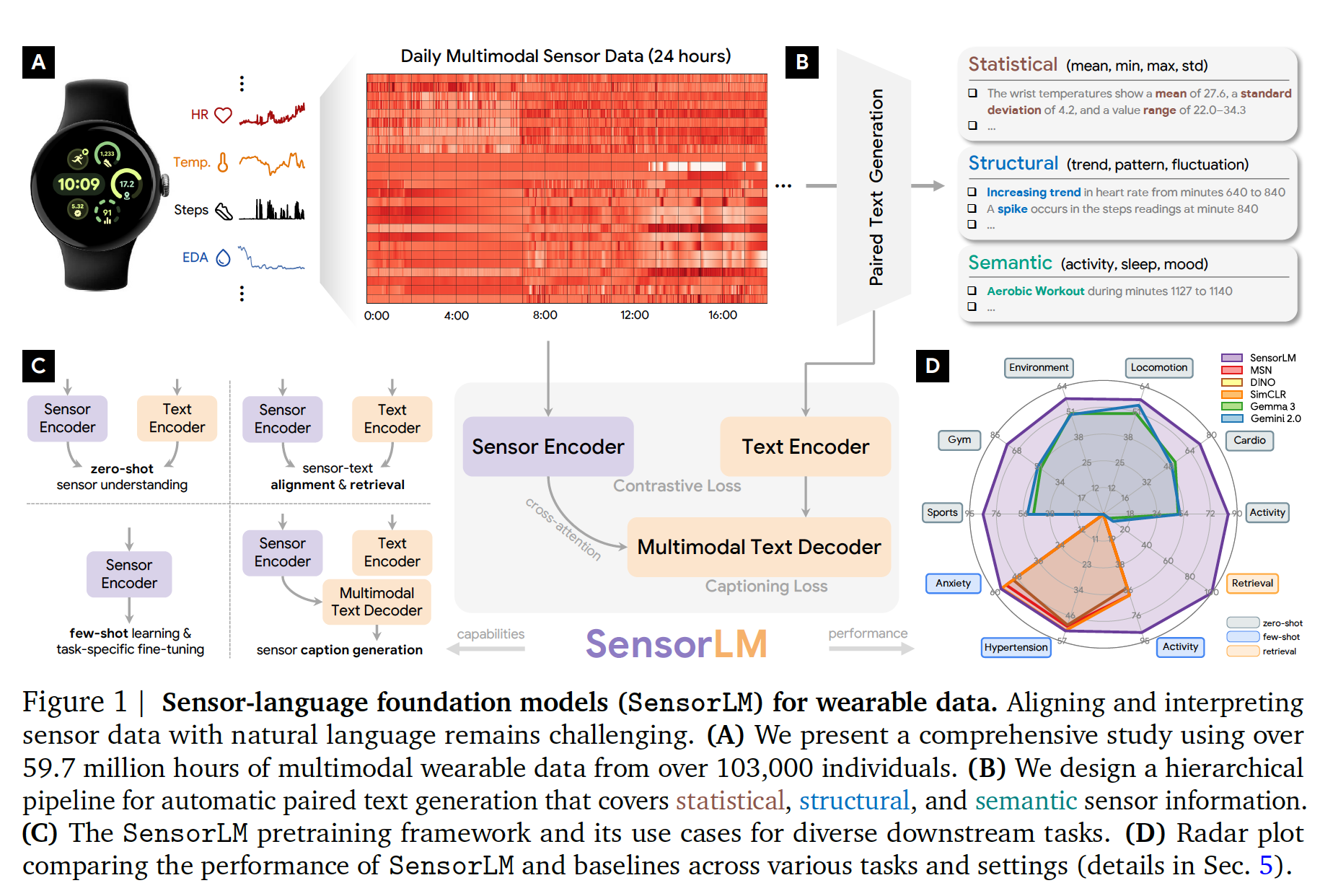
1. Introduction
- Wearable 센서는 방대한 연속 데이터(예: 24시간 분당 단위 심박수, 걸음 수)를 생성하지만, 자연어로 해석하기 어려움.
- 기존 LLM은 토큰 제한과 비정형 데이터 처리 한계로 부적합.
- 이를 해결하기 위해 SensorLM, 즉 센서 데이터를 언어로 표현할 수 있는 멀티모달 파운데이션 모델을 제안.
- 심박 변화는 다음과 같이 low-level "heart rate spikes from 65 to 90" 에서 high level semantic abstractions "periods of strength training noted"로 서술될 수 있음.
2. Related Work
- 기존 연구는 소규모 센서-텍스트 데이터셋에 의존하거나 수동 요약 기반, 혹은 tabular data를 직접 넣어주는 방식.
- 그러나 본 연구에서는 large-scale, hierarchical caption을 통해서 sensor-langauge representation을 align 함.
- 특히 기존의 Multimodal foundation model은 single model but multi-channel sensor data였지만, 본 foundation model은 multimodal sensor-language understanding을 제안하고 있음.
- SensorLM은 59.7M 시간, 10만 명 이상의 데이터를 이용한 최대 규모 sensor-language corpus를 구축.
3. Sensor-Language Dataset Construction
- 센서 종류: PPG, ACC, TEMP, EDA, ALT (심박, 가속도, 온도, 피부전도, 고도)
- Extract 12 featurs: 12 (HR, HRV from PPG), 10 (ACC), 2 (Skin Temp), 1 (EDA), 1 (ALT)
- one-day windows of minutely resolution - [26 features x 1440 minutes]
- 계층적 Caption 생성 파이프라인
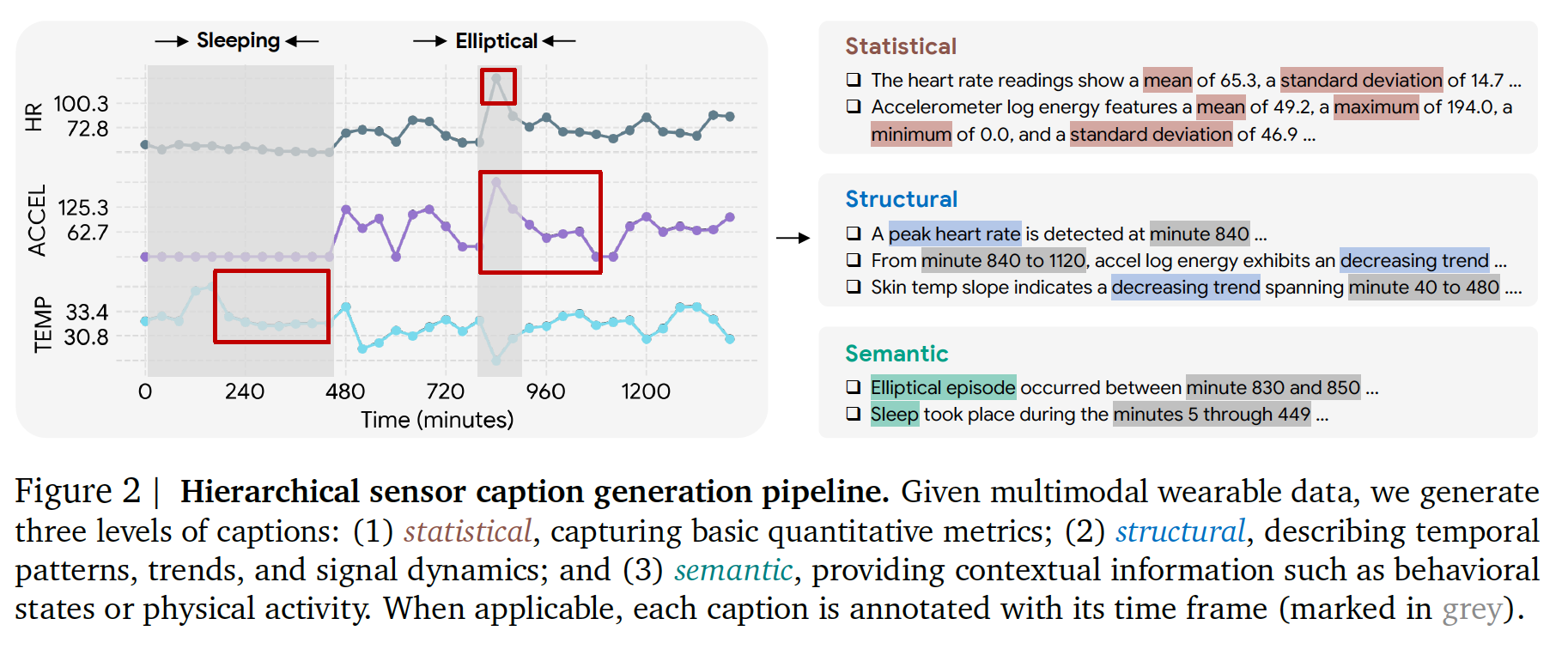
- 1️⃣ Statistical Caption: 평균, 표준편차 등 수치 요약한 내용
- 2️⃣ Structural Caption: 추세, 피크 등 시간적 패턴 요약
- 3️⃣ Semantic Caption: 활동·수면 구간, 감정 상태 등 high-level 의미. 예를 들면 "Observed Outdoor Bike activity from minute 550 to 561"
- 결과적으로 각 센서 스트림에 대해 자연어 설명 텍스트(캡션) 생성 → 센서-언어 쌍 데이터 구축.
4. SensorLM Architecture
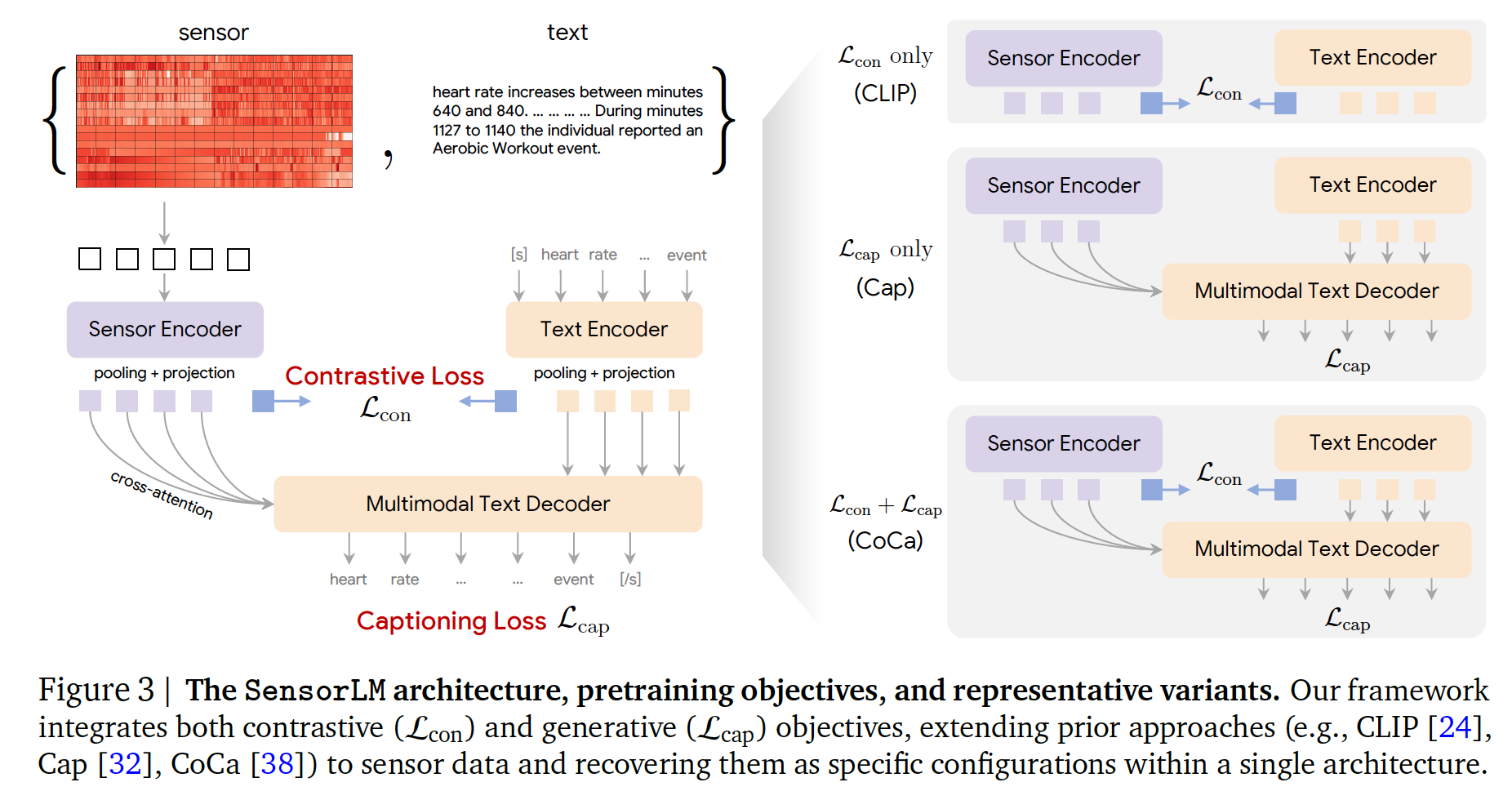
- 구조: Sensor Encoder + Text Encoder + Multimodal Text Decoder
- 학습 목표:
- Contrastive loss (Lcon): 센서 embedding-텍스트 embedding contrastive learning
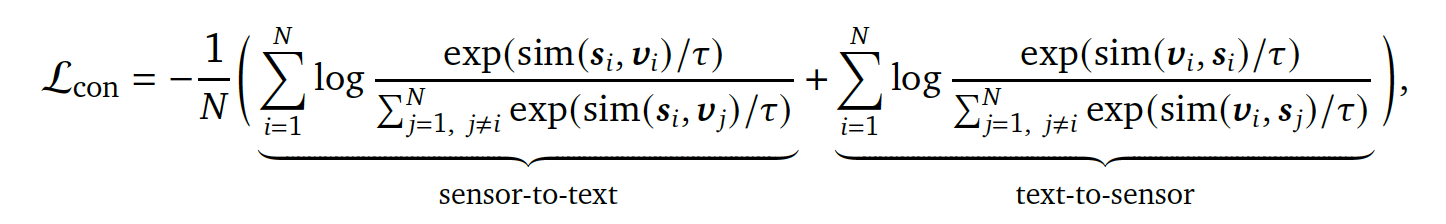
- Captioning loss (Lcap): 자연어 설명 생성, text decoder에서의 cross-entropy loss
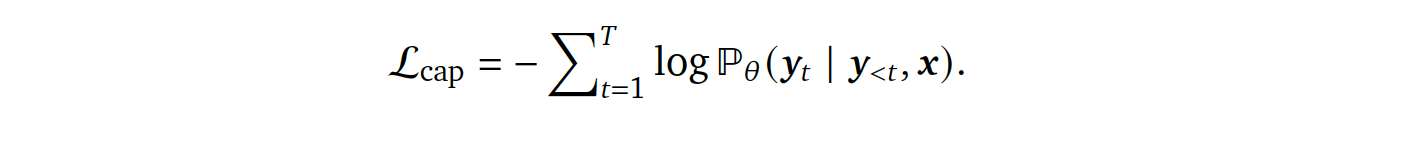
- Contrastive loss (Lcon): 센서 embedding-텍스트 embedding contrastive learning
- 이 두 Loss를 조합하는데, CLIP은 Captioning loss=0인 경우, Cap은 Contrastive loss=0인 경우, 둘 다 조합하면 CoCa
5. Experiments
1. Zero-shot 성능
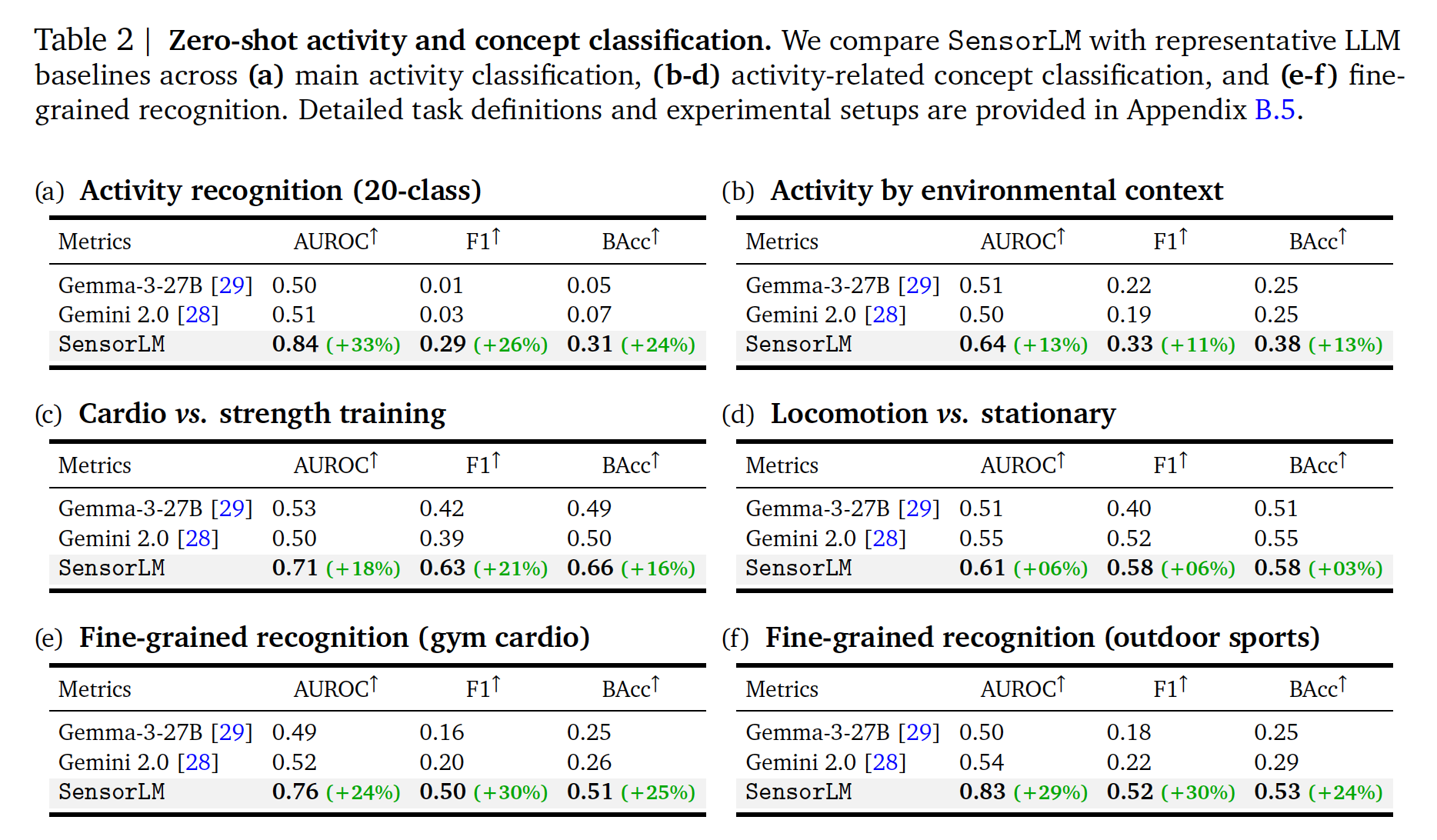
2. Zero-shot Cross-modal retrieval
- Sensor -> Text, Text -> Sensor
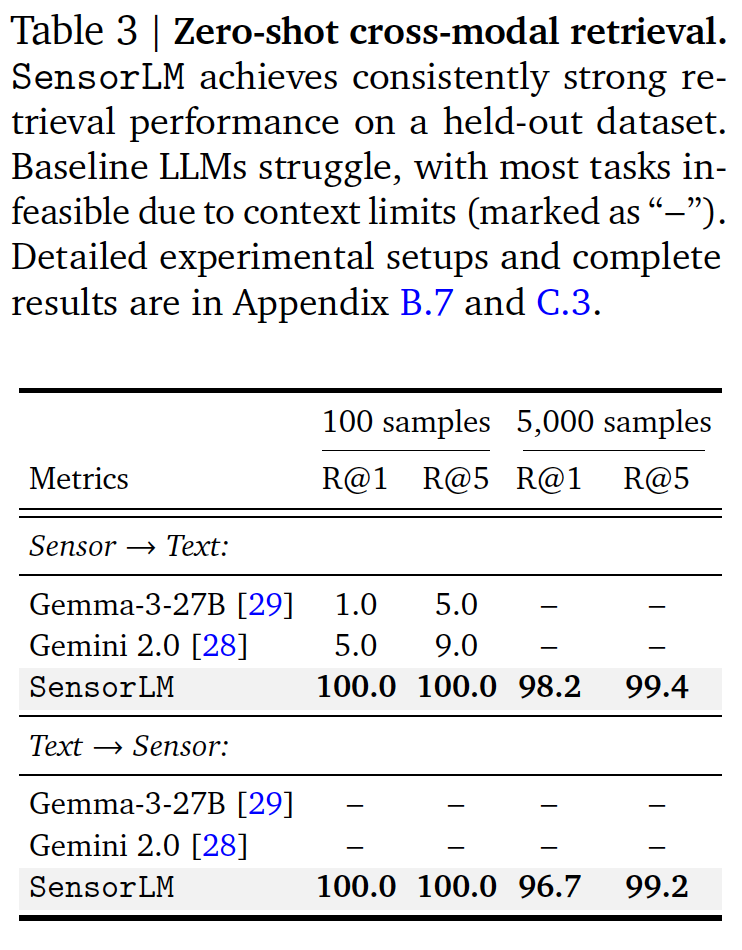
3. Few-shot Transfer Learning
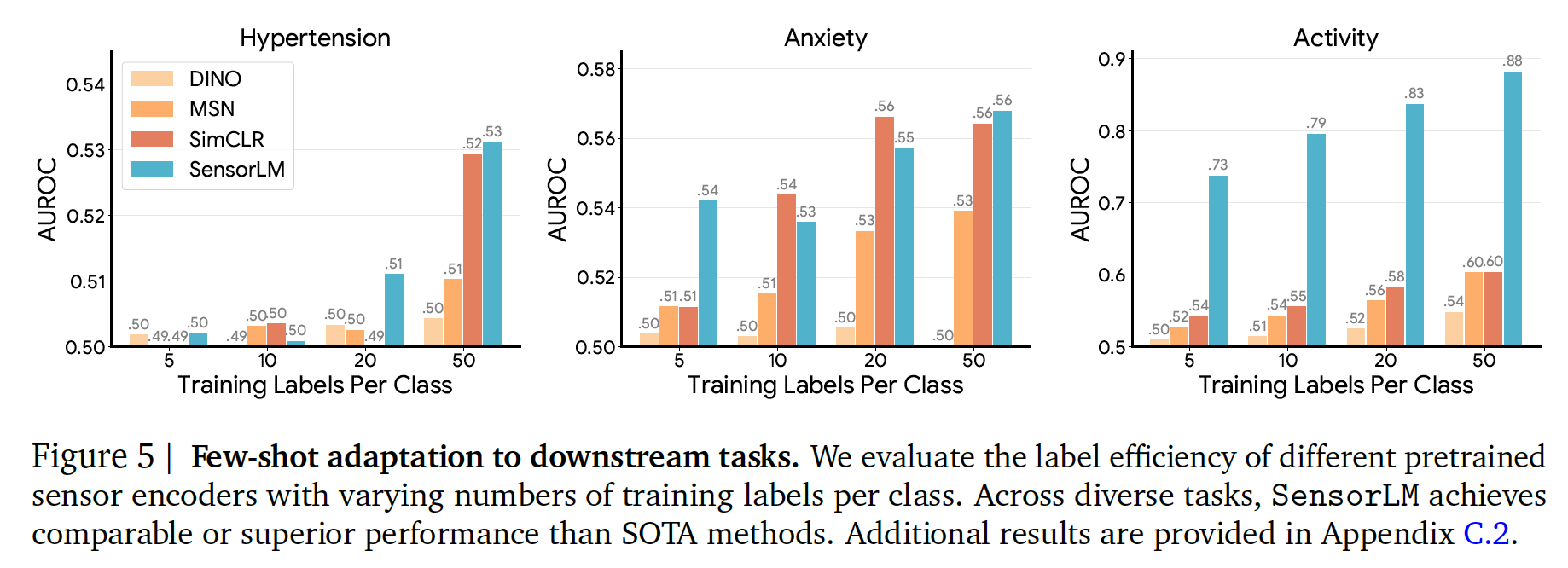
- sensor representation의 quality를 검증하기 위해 few-shot learning 진행.
4. Sensor-Caption Generation
- SensorLM의 강점은 encoder-decoder 구조로 generative objective 가 가능하다는 것이다.

6. Conclusion
- SensorLM은 센서 데이터를 언어로 표현하고 이해하는 센서-언어 파운데이션 모델의 첫 대규모 사례.
- 건강, 활동, 감정 분석 등 다양한 downstream task에 활용 가능.
- 향후 LLM 기반 헬스케어 인터페이스의 핵심 인프라로 발전 가능.
- 한계: clinically validation이 이루어지지 않음.

AI 세상에서 개발자로 살아남기