Python의 다양한 활용
파이썬에 대해 배우게 되면 단순히 계산이나 분석에 사용하는 것 뿐만아니라 생산성을 늘릴 수 있는 다양한 활용이 가능해진다.
파이썬의 기본 문법에 대해서 익히고 나서
Selenium 기반 크롤링과 FastAPI를 통한 웹 API활용법에 대해 공부해보았다.
Crawling
구글 플레이스토어에 수많은 앱이 있는데 이러한 앱의 댓글들을 크롤링을 통해서 수집하여, 데이터를 저장하는 코드를 만들어보았다.
구글 플레이스토어 댓글 수집
조건
- 조건1: 내가 입력한 검색어를 기반으로 첫 번째 앱을 선택합니다.
- 조건2: 댓글 수집이 100개 이상 수집되어야 합니다. (댓글 갯수가 100미만인 앱은 예외)
- 조건3: 댓글에서 아래의 정보를 가져오세요.
- 작성자명, 별표 갯수, 작성일, 작성 내용
- 조건4: 크롤링한 데이터를 오늘 날짜를 기준으로 엑셀에 저장하시오. (파일명: 2023-04-18)
selenium을 불러오자
from selenium import webdriver
from selenium.webdriver.common.by import By
from datetime import datetime크롤링을 원하는 앱을 입력하자
# (1) 링크 생성
keyword = input("수집하고자 하는 앱 이름을 입력하세요 : ")
url = f'https://play.google.com/store/search?q={keyword}&c=apps'
print(url)페이지를 이동하자
# (2) 브라우저를 열고, 페이지 이동
browser = webdriver.Chrome()
browser.get(url)댓글 수집을 위해 앱의 상세페이지로 이동한다.
# (3) 앱의 상세 페이지로 이동
app_url = browser.find_element(By.CLASS_NAME, 'Qfxief').get_attribute('href')
browser.get(app_url)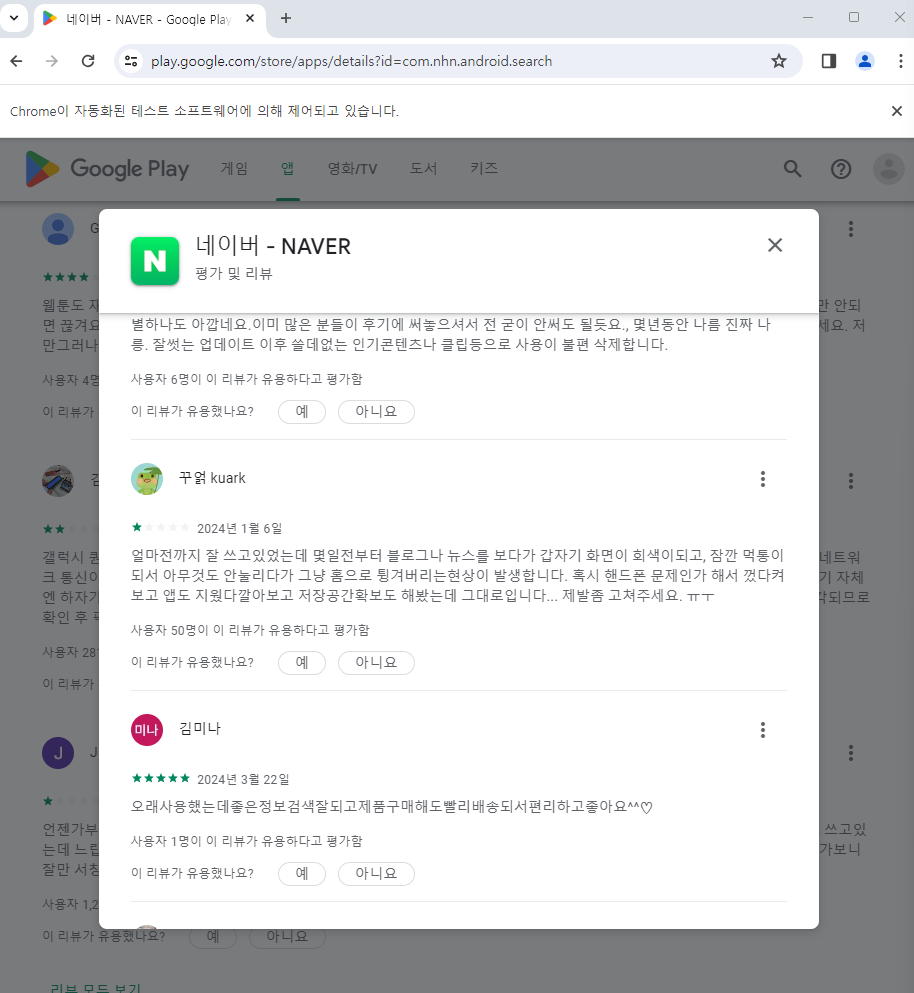
XPATH를 찾아 리뷰 더 보기 버튼을 클릭해주고
# (4) 리뷰 더 보기 클릭
browser.find_element(By.XPATH, '//*[@id="yDmH0d"]/c-wiz[2]/div/div/div[1]/div/div[2]/div/div[1]/div[1]/c-wiz[5]/section/div/div[2]/div[5]/div/div/button/span').click()자바스크립트 코드를 활용해 스크롤 하여 요소를 불러와준다.
# (5) 리뷰 스크롤 => JS // 검색 => 적용
# 모달창을 클릭한다.
browser.find_element(By.CLASS_NAME, 'fysCi').click()# javascript코드를 통해서 스크롤을 내려준다. (네이버 로그인)
modal_elem = browser.find_element(By.CLASS_NAME, 'fysCi')
import time
for i in range(5):
js_code = 'arguments[0].scrollTo(0, arguments[0].scrollHeight)'
browser.execute_script(js_code, modal_elem)
time.sleep(1)불러온 요소를 Dict 형태로 저장하여 데이터프레임을 만든다.
datas = browser.find_elements(By.CLASS_NAME, 'RHo1pe')
data_list = []
for data in datas:
username = data.find_element(By.CLASS_NAME,'X5PpBb').text
content = data.find_element(By.CLASS_NAME,'h3YV2d').text
rank = data.find_element(By.CLASS_NAME,'iXRFPc').get_attribute('aria-label')[10:11]
pre_review_date = data.find_element(By.CLASS_NAME, 'bp9Aid').text
pre_review_date = pre_review_date.replace("년", "-").replace("월", "-").replace("일", "").replace(" ", "")
review_date = datetime.strptime(pre_review_date, "%Y-%m-%d").date()
data_list.append({
'유저명' : username,
'별표' : rank,
'작성일' : review_date,
'작성내용': content
})
CSV형태로 저장하면 완료
import pandas as pd
df = pd.DataFrame(data_list)
df.to_csv('naver_playstore.csv',encoding='utf-8-sig',index=False)

이렇게 저장한 데이터에 자연어처리를 하면 워드클라우드 형태로 댓글 확인도 가능하고, 감성분석이나 키워드 분석등의 자연어 처리기술과 결합하면 다양한 분석을 할 수 있을것으로 생각되었다.
FastAPI 활용하기
FastAPI 와 Tensorflow의 mobileNet V2 모델을 활용해서
웹페이지에 이미지를 업로드하면 바로 모델을 사용해볼 수 있도록 데모페이지를 제작해 보았다.
main.py
기본적으로 FastAPI 웹페이지를 호스팅할 main.py가 필요하다.
# 필요한 라이브러리와 모듈을 임포트합니다.
from fastapi import FastAPI, File, UploadFile # FastAPI와 파일 업로드를 위한 클래스를 임포트합니다.
from PIL import Image # 이미지 처리를 위해 PIL 라이브러리의 Image 모듈을 임포트합니다.
from io import BytesIO # 바이트 스트림을 다루기 위해 BytesIO를 임포트합니다.
from predict import predict # 예측 함수를 포함하고 있는 사용자 정의 모듈을 임포트합니다.
# FastAPI 애플리케이션 인스턴스를 생성합니다.
app = FastAPI()
# "/predict/image" 경로에 POST 요청이 들어왔을 때 실행할 함수를 데코레이터로 등록합니다.
@app.post("/predict/image")
async def predict_api(file: UploadFile = File(...)): # 비동기 함수로, 파일을 업로드 파일로 받습니다.
# 업로드된 파일의 확장자를 확인하여 jpg, jpeg, png인지 검사합니다.
extension = file.filename.split(".")[-1] in ("jpg", "jpeg", "png")
if not extension: # 확장자가 이들 중 하나가 아니라면 에러 메시지를 반환합니다.
return "Image must be jpg or png format!"
# 업로드된 파일을 PIL 이미지로 변환합니다. 이를 위해 파일을 바이트로 읽고, BytesIO로 이미지 데이터를 메모리에 로드합니다.
image = Image.open(BytesIO(await file.read()))
# 사용자 정의 `predict` 함수를 사용하여 이미지에 대한 예측을 수행합니다.
prediction = predict(image)
# 예측 결과를 반환합니다.
return prediction
# 스크립트가 직접 실행될 때만 아래 코드가 실행됩니다.
if __name__ == "__main__":
import uvicorn # ASGI 서버인 uvicorn을 임포트합니다.
# uvicorn을 사용하여 앱을 호스트합니다. 여기서 "main:app"는 이 스크립트(main.py)에 정의된 app 인스턴스를 가리킵니다.
uvicorn.run("main:app", port=8000, log_level="info")
predict.py
# 필요한 라이브러리를 임포트합니다.
from PIL import Image # 이미지 처리를 위한 PIL 라이브러리
import numpy as np # 수치 연산을 위한 NumPy 라이브러리
from tensorflow.keras.applications.imagenet_utils import decode_predictions # 예측 결과를 해석하기 위한 함수
from model_loader import model # 사용자 정의 모듈에서 학습된 모델을 임포트합니다.
# 이미지를 입력받아 예측 결과를 반환하는 함수를 정의합니다.
def predict(image: Image):
# 입력 이미지를 224x224 크기로 조정하고, RGB 채널만 유지하며 NumPy 배열로 변환합니다.
image = np.asarray(image.resize((224, 224)))[..., :3] # RGB
# 변환된 이미지 배열에 배치 차원을 추가합니다. 이는 모델이 배치 처리를 기대하기 때문입니다.
image = np.expand_dims(image, 0)
# 이미지 데이터를 -1에서 1 사이의 값으로 정규화합니다. 이는 많은 사전 훈련된 모델의 입력 요구사항입니다.
image = image / 127.5 - 1.0 # Scaler(정규화)
# 로드된 모델을 사용하여 이미지에 대한 예측을 수행하고, 상위 3개의 예측 결과를 디코드합니다.
result = decode_predictions(model.predict(image), 3)[0] # 상위 3개의 결과 반환
# 예측 결과를 저장할 리스트를 초기화합니다.
result_list = []
# 예측 결과를 순회하며 각 클래스의 이름과 신뢰도를 결과 리스트에 추가합니다.
for res in result:
print(res) # 콘솔에 결과를 출력합니다.
# 결과 리스트에 클래스 이름과 신뢰도(확률)를 사전 형태로 추가합니다. 신뢰도는 백분율로 변환됩니다.
result_list.append({"class": res[1], "confidence": f"{res[2]*100:0.2f} %"})
# 최종적으로 구성된 결과 리스트를 반환합니다.
return result_list
model_loader.py
# TensorFlow 라이브러리를 tf라는 별칭으로 임포트합니다.
import tensorflow as tf
# 사전 훈련된 모델을 로드하는 함수를 정의합니다.
def load_model():
# tf.keras.applications에서 제공하는 MobileNetV2 모델을 로드합니다.
# weights='imagenet'은 ImageNet 데이터셋으로 사전 훈련된 가중치를 사용하겠다는 의미입니다.
model = tf.keras.applications.MobileNetV2(weights="imagenet")
# 모델이 성공적으로 로드되었음을 콘솔에 출력합니다.
print("Model loaded")
# 로드된 모델을 반환합니다.
return model
# load_model 함수를 호출하여 모델을 로드하고, 이를 model 변수에 할당합니다.
model = load_model()
Using Page
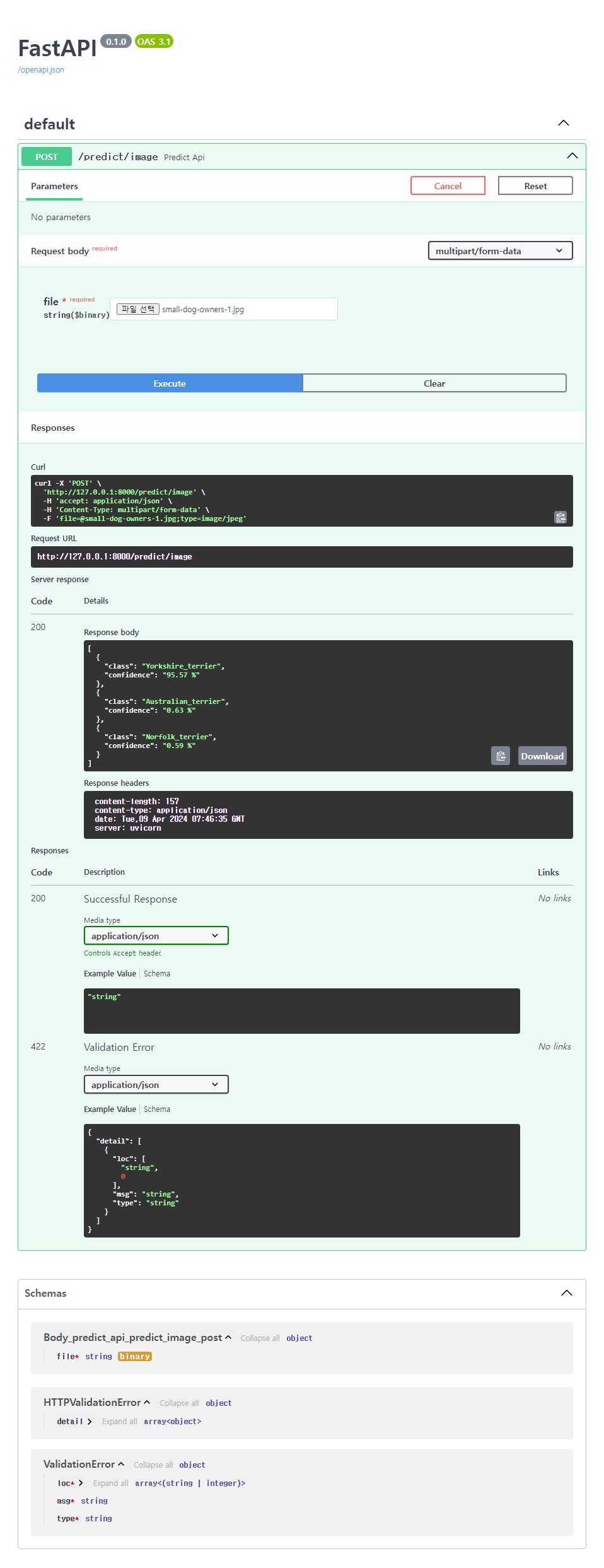
요크셔테리어 이미지를 모델에 넣어서 확인해보자.
강아지 이미지를 웹페이지에 업로드하여 execute 해보면 결과를 얻을 수 있다.
[
{
"class": "Yorkshire_terrier",
"confidence": "95.57 %"
},
{
"class": "Australian_terrier",
"confidence": "0.63 %"
},
{
"class": "Norfolk_terrier",
"confidence": "0.59 %"
}
]Yorkshire_terrier가 95.57%로 모델이 잘 작동해서 결과를 보여주는걸 확인할 수 있었다.
파이썬 활용 후기
파이썬으로 데이터분석이나 간단한 데모페이지를 한 경험이 있어서 약간씩은 아는 분야라 재미있게 잘 했던 것 같다.
다만 프로젝트에 실제로 적용해보기 위해서는 FastAPI든 Selenium이든 추가적인 공부와 구글링이 필수적일 것으로 생각이 된다.
할수록 성장하는 느낌이 뿌듯하고 좋은것같다.

AI가 재밌는 걸