Selenium 기반 크롤링
from selenium import webdriver
from selenium.webdriver.common.by import By
url = 'https://www.google.com/search?q=%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5+%EC%B1%97%EB%B4%87&sca_esv=30c375223fbe6df1&biw=929&bih=864&tbm=nws&ei=t1IPZs_OB4Dc2roP1eSCuAs&udm=&ved=0ahUKEwiPhov_9KmFAxUArlYBHVWyALcQ4dUDCA0&uact=5&oq=%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5+%EC%B1%97%EB%B4%87&gs_lp=Egxnd3Mtd2l6LW5ld3MiE-yduOqzteyngOuKpSDssZfrtIcyCxAAGIAEGLEDGIMBMgUQABiABDIFEAAYgAQyBRAAGIAEMgUQABiABDIFEAAYgAQyBRAAGIAEMgUQABiABDIFEAAYgAQyBRAAGIAESKAPUNIEWJgOcAB4AJABAJgBYqAB7AeqAQIxMbgBA8gBAPgBAZgCCqACrQfCAgoQABiABBiKBRhDwgIEEAAYHsICBhAAGB4YD8ICBhAAGAgYHpgDAIgGAZIHAzkuMaAHzEM&sclient=gws-wiz-news'
browser = webdriver.Chrome()
browser.get(url)
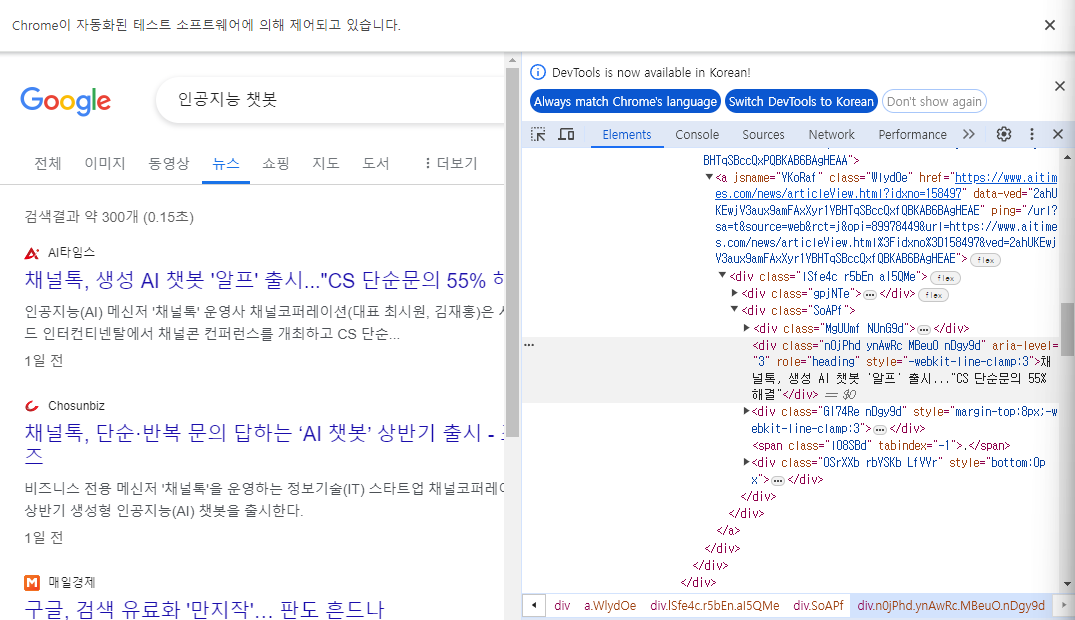
뉴스의 요소 크롤링하기
# 언론사
news_company = browser.find_element(By.CLASS_NAME, 'MgUUmf').text
# 제목
news_title = browser.find_element(By.CLASS_NAME, 'n0jPhd').text
# 내용
news_content = browser.find_element(By.CLASS_NAME, 'GI74Re').text
# 작성일
news_date = browser.find_element(By.CLASS_NAME, 'rbYSKb').text
print(news_company)
print(news_title)
print(news_content)
print(news_date)news_date가 제대로 들어오지 않음
span 태그를 못 읽어 왔나?
.find_element(By.TAG_NAME, 'span').text그 다음 클래스네임을 써보자
OSrXXb rbYSKb LfVVr 중에서 2번째인 rbYSKb 사용
AI타임스
채널톡, 생성 AI 챗봇 '알프' 출시..."CS 단순문의 55% 해결"
인공지능(AI) 메신저 '채널톡' 운영사 채널코퍼레이션(대표 최시원, 김재홍)은 서울 그랜드 인터컨티넨탈에서 채널콘 컨퍼런스를 개최하고 CS 단순...
1일 전
find_element => 요소를 찾아줘.
fine_elements => 요소 들을 찾아줘. => return list [ ]
# 언론사
news_companys = browser.find_elements(By.CLASS_NAME, 'MgUUmf')
# 제목
news_titles = browser.find_elements(By.CLASS_NAME, 'n0jPhd')
# 내용
news_contents = browser.find_elements(By.CLASS_NAME, 'GI74Re')
# 작성일
news_dates = browser.find_elements(By.CLASS_NAME, 'rbYSKb')
for company in news_companys:
print(company.text)AI타임스
Chosunbiz
동아일보
MSN
비즈니스포스트
네이트뷰
하이테크정보
한국경제
인공지능신문
법률신문
컨테이너 방식
뉴스의 요소를 담고있는 상위컨테이너를 불러옴
news_containers = browser.find_elements(By.CLASS_NAME, 'SoaBEf')for container in news_containers:
title = container.find_element(By.CLASS_NAME,'n0jPhd').text
company = container.find_element(By.CLASS_NAME,'MgUUmf').text
content = container.find_element(By.CLASS_NAME,'GI74Re').text
create_at = container.find_element(By.CLASS_NAME,'rbYSKb').text
print(company,title,content,create_at)
AI타임스 채널톡, 생성 AI 챗봇 '알프' 출시..."CS 단순문의 55% 해결" 인공지능(AI) 메신저 '채널톡' 운영사 채널코퍼레이션(대표 최시원, 김재홍)은 서울 그랜드 인터컨티넨탈에서 채널콘 컨퍼런스를 개최하고 CS 단순... 1일 전
Chosunbiz 채널톡, 단순·반복 문의 답하는 ‘AI 챗봇’ 상반기 출시 - 조선비즈 비즈니스 전용 메신저 '채널톡'을 운영하는 정보기술(IT) 스타트업 채널코퍼레이션이 올 상반기 생성형 인공지능(AI) 챗봇을 출시한다. 1일 전
동아일보 세종시, 전자증명-AI챗봇으로 ‘민원혁신’ 세종시가 공무원이 디지털로 증명서를 직접 확인해 민원인이 제출하는 증명서를 없애는 제도를 시행하겠다고 2일 밝혔다. 시는 최근 행정안전부와... 2일 전
...
Link를 부르고 싶다면?
링크 추출 => html
링크는 보통 a태그안에 담겨있다.
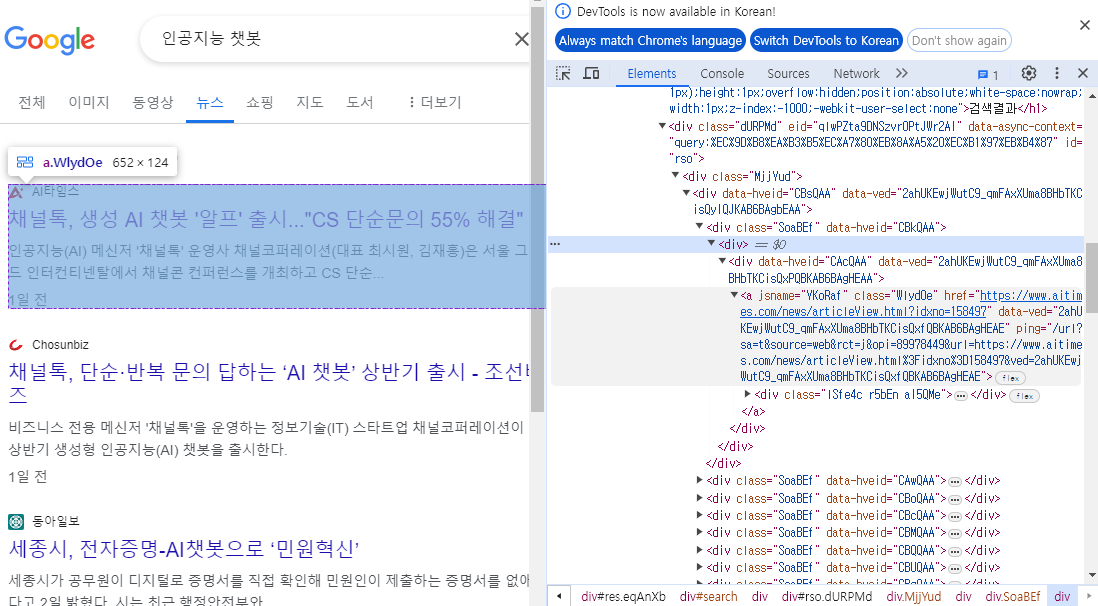
browser.find_element(By.CLASS_NAME, 'WlydOe').get_attribute('href')'https://www.aitimes.com/news/articleView.html?idxno=158497'
for container in news_containers:
title = container.find_element(By.CLASS_NAME,'n0jPhd').text
company = container.find_element(By.CLASS_NAME,'MgUUmf').text
content = container.find_element(By.CLASS_NAME,'GI74Re').text
create_at = container.find_element(By.CLASS_NAME,'rbYSKb').text
link=container.find_element(By.CLASS_NAME, 'WlydOe').get_attribute('href')
print(company,'\n',title,'\n',content,'\n',create_at,'\n',link,'\n')
AI타임스
채널톡, 생성 AI 챗봇 '알프' 출시..."CS 단순문의 55% 해결"
인공지능(AI) 메신저 '채널톡' 운영사 채널코퍼레이션(대표 최시원, 김재홍)은 서울 그랜드 인터컨티넨탈에서 채널콘 컨퍼런스를 개최하고 CS 단순...
1일 전
https://www.aitimes.com/news/articleView.html?idxno=158497
Chosunbiz
채널톡, 단순·반복 문의 답하는 ‘AI 챗봇’ 상반기 출시 - 조선비즈
비즈니스 전용 메신저 '채널톡'을 운영하는 정보기술(IT) 스타트업 채널코퍼레이션이 올 상반기 생성형 인공지능(AI) 챗봇을 출시한다.
1일 전
https://biz.chosun.com/industry/company/2024/04/03/XU3SE3JDLJC6HPS62EYWJ7Z5IQ/
...
동아일보
세종시, 전자증명-AI챗봇으로 ‘민원혁신’
세종시가 공무원이 디지털로 증명서를 직접 확인해 민원인이 제출하는 증명서를 없애는 제도를 시행하겠다고 2일 밝혔다. 시는 최근 행정안전부와...
2일 전
https://www.donga.com/news/Society/article/all/20240402/124288744/1
이런 방식을 통해서, 구글 뉴스의 언론사, 제목, 내용, 일자, 링크를 불러와서 변수에 저장할 수 있다.
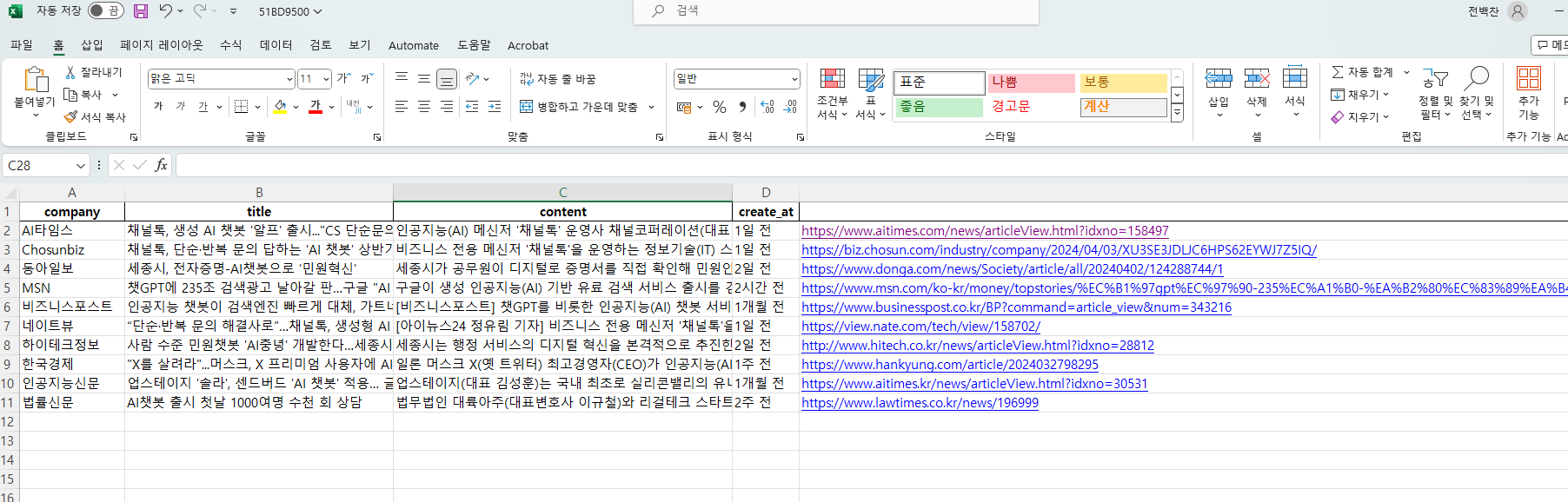
이렇게 만든 변수를 활용하여 엑셀에 크롤링한 데이터를 저장해보았다.
import pandas as pd
# 뉴스 정보를 저장할 빈 리스트 생성
news_data = []
news_containers = browser.find_elements(By.CLASS_NAME, 'SoaBEf')
for container in news_containers:
title = container.find_element(By.CLASS_NAME,'n0jPhd').text
company = container.find_element(By.CLASS_NAME,'MgUUmf').text
content = container.find_element(By.CLASS_NAME,'GI74Re').text
create_at = container.find_element(By.CLASS_NAME,'rbYSKb').text
link=container.find_element(By.CLASS_NAME, 'WlydOe').get_attribute('href')
print(company,'\n',title,'\n',content,'\n',create_at,'\n',link,'\n')
news_data.append({
'company': company,
'title': title,
'content': content,
'create_at': create_at,
'link': link,
})
# pandas DataFrame으로 변환
df_news = pd.DataFrame(news_data)
# Excel 파일로 저장
excel_writer = pd.ExcelWriter('news_data.xlsx', engine='openpyxl')
df_news.to_excel(excel_writer, index=False)
excel_writer.close()
print("뉴스 데이터가 엑셀 파일에 저장되었습니다.")
이미지를 get하는 다양한 방법이 있을 수 있다
# TAG_NAME을 사용하는 방식
container.find_element(By.TAG_NAME, 'img').get_attribute('src')
# ID를 사용하는 방식
container.find_element(By.ID, 'dimg_1').get_attribute('src')파일을 저장할 때도 CSV파일로 저장하는 것도 가능하다.
import pandas as pd
# 뉴스 정보를 저장할 빈 리스트 생성
news_data = []
news_containers = browser.find_elements(By.CLASS_NAME, 'SoaBEf')
for container in news_containers:
title = container.find_element(By.CLASS_NAME,'n0jPhd').text
company = container.find_element(By.CLASS_NAME,'MgUUmf').text
content = container.find_element(By.CLASS_NAME,'GI74Re').text
create_at = container.find_element(By.CLASS_NAME,'rbYSKb').text
link=container.find_element(By.CLASS_NAME, 'WlydOe').get_attribute('href')
image=container.find_element(By.TAG_NAME, 'img').get_attribute('src')
#print(company,'\n',title,'\n',content,'\n',create_at,'\n',link,'\n')
news_data.append({
'제목':title,
'언론사':company,
'내용':content,
'작성시간':create_at,
'링크':link
})
len(news_data)
df = pd.DataFrame(news_data)
df.to_csv('google_news.csv',encoding='EUC-KR',index=False)
