DBSCAN
Density-Based Spatial Clustering of Applications with Noise
- K-means나 Hierarchical Clustering의 경우 군집 간의 거리를 이용한 Clustering 기법
- DBSCAN은 밀도 기반의 기법이며 세밀하게 몰려 있어서 밀도가 높은 부분을 Clustering 하는 기법
방법
- 점 p가 있다고 할 때, 점 p에서 부터 거리 e(epsilon)내에 점이 m(minPls)개 있으면 하나의 군집으로 인식함
- 따라서 e와 m이 Hyperparameter임
특징
- K-means와 같이 Cluster의 수를 정하지 않아도 됨
- Cluster의 밀도에 따라 Cluster를 서로 연결하기 때문에 기하학적인 모양을 갖는 군집도 잘 찾을 수 있음
- DBSCAN을 활용하여 이상치를 발견할 수 있음
- DBSCAN은 Cluster 결과가 이상치에 영향을 받지 않음
- 다양한 모양의 Cluster 패턴도 잘 잡아 낼 수 있음
- 구현이 비교적 쉬움
- 고차원 데이터 대해서 잘 작동하지 않음
- Sparse Data에 대해 결과가 좋지 못함
HDBSCAN
Hierarchical Density-Based Spatial Clustering of Applications with Noise
- DBSCAN은 Local density에 대한 정보를 반영해 줄 수 없으며 Data들의 계층적 구조를 반영한 Clustering이 불가능함
- HDBSCAN의 경우 더 이상 epsilon(e)이 필요하지 않음
• 밀도/희소도에 따라 공간을 변환합니다.
- Distance를 더 Robust하게 만들어주는 작업
- 𝒄𝒐𝒓𝒆𝒌(𝒂) : a의 이웃과의 거리
- 𝒄𝒐𝒓𝒆𝒌(𝒃) : b의 이웃과의 거리
- 𝐝(𝒂,𝒃) : a, b의 자체 거리
- dense한 지점의 data는 𝒄𝒐𝒓𝒆𝒌가 매우 작기 때문에 𝐝(𝒂,𝒃) 값을 사용하고, dense가 낮은 지점의 경우 𝒄𝒐𝒓𝒆𝒌 의 주변 정보를 사용하게 됨
- Distance의 robustness를 늘리고, 최종적으로는 더 효율적인 Clustering을 가능하게 함
• 거리 가중치 그래프의 minimum spanning tree를 구축합니다.
- Robust Distance를 계산한 정보를 가지고 Minimum spanning tree를 구축함
- Spanning Tree는 모든 정점들이 연결 되어 있어야 하고 사이클을 포함해서는 안됨
• 연결된 구성 요소의 클러스터 계층 구조를 구성합니다.
- 계층 (Hierarchy)를 만드는 과정 중 하나
- Robust Distance의 Cut을 점점 높여가며 하나씩 Graph의 Edge를 끊어 나감
- 그리고 만들어진 Minimum spanning tree를 가장 가까운 거리부터 묶어줌
- HC에서 군집들 간 거리를 계산해서 묶어 주는 것과 같은 원리
• 최소 클러스터 크기를 기준으로 클러스터 계층을 축약합니다.
- Robust Distance가 0.4 이하로는 거의 모든 데이터가 1개로 떨어져 나오는 지저분한 상황이 발생함
- 이러한 경우 Noise 처럼 보일 수 있음
- 따라서 minimum size 이상의 크기를 가진 component 들만 남게 만들다
- minimum size는 HDBSCAN의 Hyperparameter
• 축약된 트리에서 안정된 클러스터를 추출합니다.
- DBSCAN은 Dense를 제대로 못 잡아 내고 주변에 있는 데이터를 전부 Noise 처리를 함
- epsilon의 문제가 발생하는 것
[HDBSCAN]
Hyperparameter Tuning using for Loop
[HDBSCAN Parameters]
Packge : https://hdbscan.readthedocs.io/en/latest/how_hdbscan_works.html
min_cluster : Cluster 안에 적어도 몇개가 있어야 하는지
cluster_selection_epsilon : combining HDBSACN with DBSCAN
평가지표
Clustering 평가 지표
- Clustering 평가 지표를 활용하여 Clustering의 결과를 확인해야 함
- Elbow point 찾기
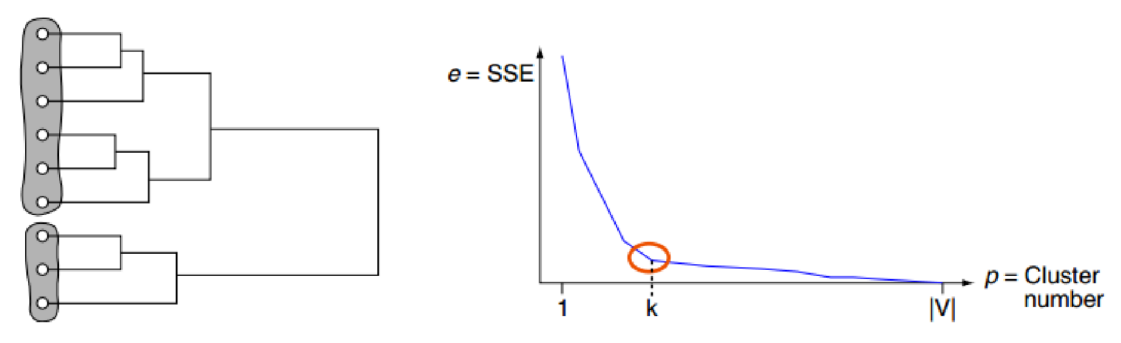
- Clustering 결과에 대한 평가지표는 확실한 것이 없음
- Clustering은 비지도 학습이기 때문에 정답과 비교할 수 없기 때문
Clustering의 결과 평가 지표는 크게 3개의 카테고리가 존재함
- External : 우리가 알고 있는 정답(Label)과 비교해 봄 (있을 수 없음)
- Internal : Cluster들의 공간들을 확인해보는 방법
- Relative : Cluster의 공간과 Cluster들 간 떨어진 정도를 가지고 판단할 수 있음

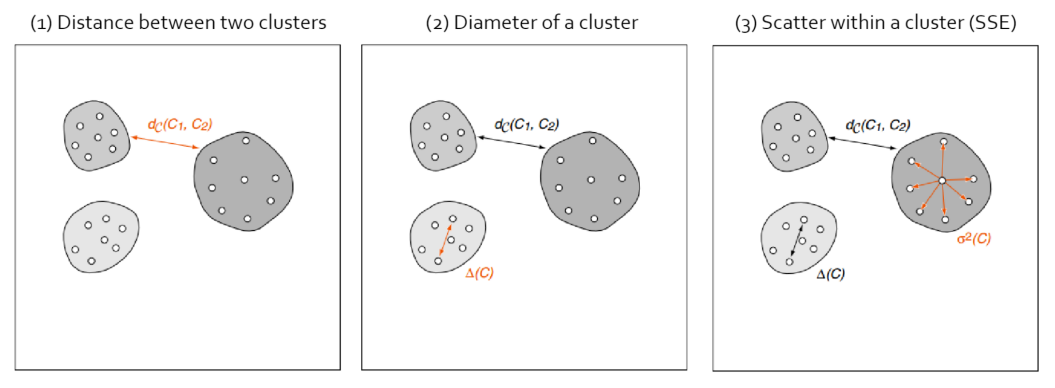
Dunn Index
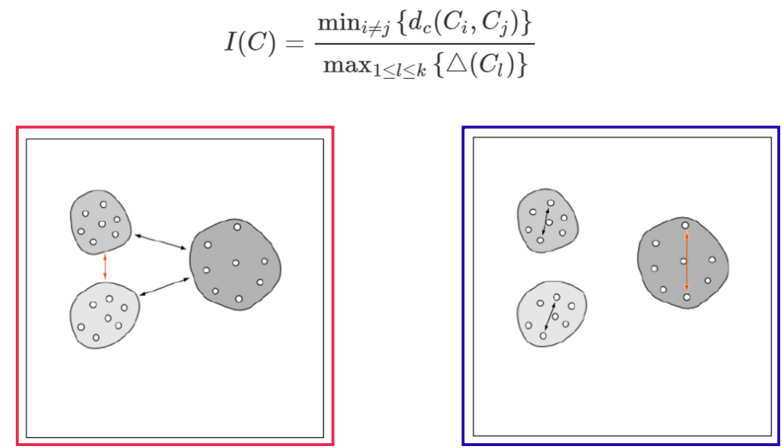
- 만약 Clustering이 잘 작동 했다면 (1) 값은 커야하며, (2), (3) 값은 작아야 함
- 군집 간 거리의 최소 값(좌측 하단)을 분자, 군집 내 요소 간 거리의 최대 값(우측 하단)울 분모로 하는 지표
- 군집 간 거리는 멀수록, 군집 내 분산은 작을 수록 좋은 군집화 결과라고 말해주는 지표
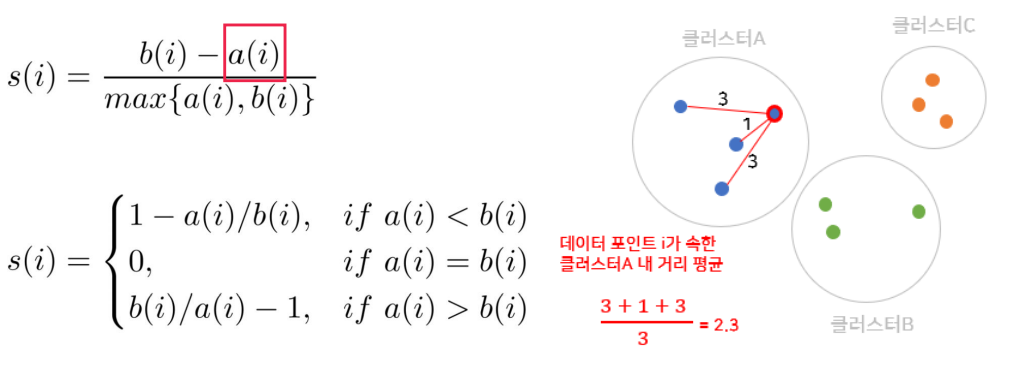
Silhouette Score
-
Dunn Index의 경우 Clustering의 유효성을 검증하기 위한 하나의 값이 있음
-
Silhouette Score는 개체별로 그 적합성이 평가 됨
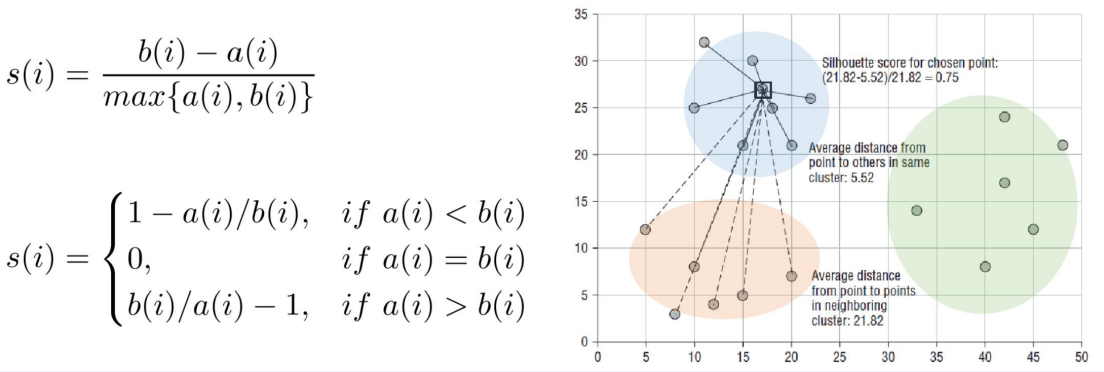
-
Dunn Index의 경우 Clustering의 유효성을 검증하기 위한 하나의 값이 있음
-
Silhouette Score는 개체별로 그 적합성이 평가 됨 (값이 1에 가까울수록 군집화가 잘 되었다고 판단함)
Clustering 종류

AI가 재밌는 걸