Dive to Machine Learning
1.데이터 분석
Zero 비율이 0.95 이상인 경우 -> 분석에 의미가 없으므로 drop독립변수 간 상관관계가 높은 경우 -> 다중공선성 의심Class Imbalance 체크 -> 비율이 0.9 이상인 경우, 샘플링 고려실제 데이터는 Imabalance 하므로, 데이터를 drop하기
2.머신러닝 - 회귀 (1)
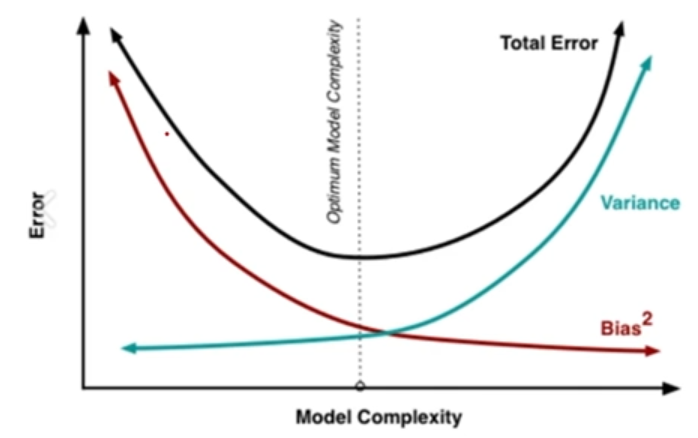
Loss Function 모델의 성능을 측정하는 척도를 지정하기 위해 사용 Error를 낮추는게 학습의 목표 -> Error에 대해 정의하는 것이 중요 Error = Variance + Bias Variance: 추정값의 평균과 추정 값 들 간의 차이 Bias
3.머신러닝 - 회귀 (2)

Ridge Regression $\beta^2$에 Penalty Term을 부여하는 방식 Penalty Term을 추가한 Regularized Model 의 경우 Feature간 Scaling이 필수 $L(\beta) = \min{\beta} \sum{i=1}^{
4.머신러닝 - 분류모델 개요

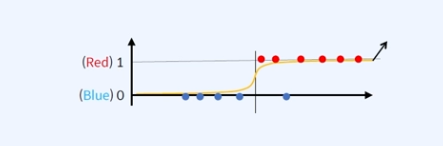
분류모델의 Loss Function Regression Loss Function은 Error의 크기를 측정할 수 있으나 Classification Loss Function은 Yes or No 두가지 밖에 없다. 단, 클래스가 2개 이상일 순 있다. Classific
5.머신러닝 - 분류모델 Random Forest

Decision Tree Algorithm에 대한 Specialized Bagging두가지 방법을 통해 앙상블의 Diversity을 상승시킴Tree는 작은 Bias와 큰 Variance를 갖기 때문에, 매우 깊이 성장한(Depth가 깊은) 트리는 훈련 데이터에 대해 O
6.머신러닝 - 분류모델 Adaboost
이전에 잘못 분류된 기록에 보다 집중하여 훈련 데이터의 분포를 적응적으로 변경하는 반복적인 절차Parallel(병렬) 작업이 아니라 Sequential(순차적) 과정
7.머신러닝 - 분류모델 Gradient Boosting Machine
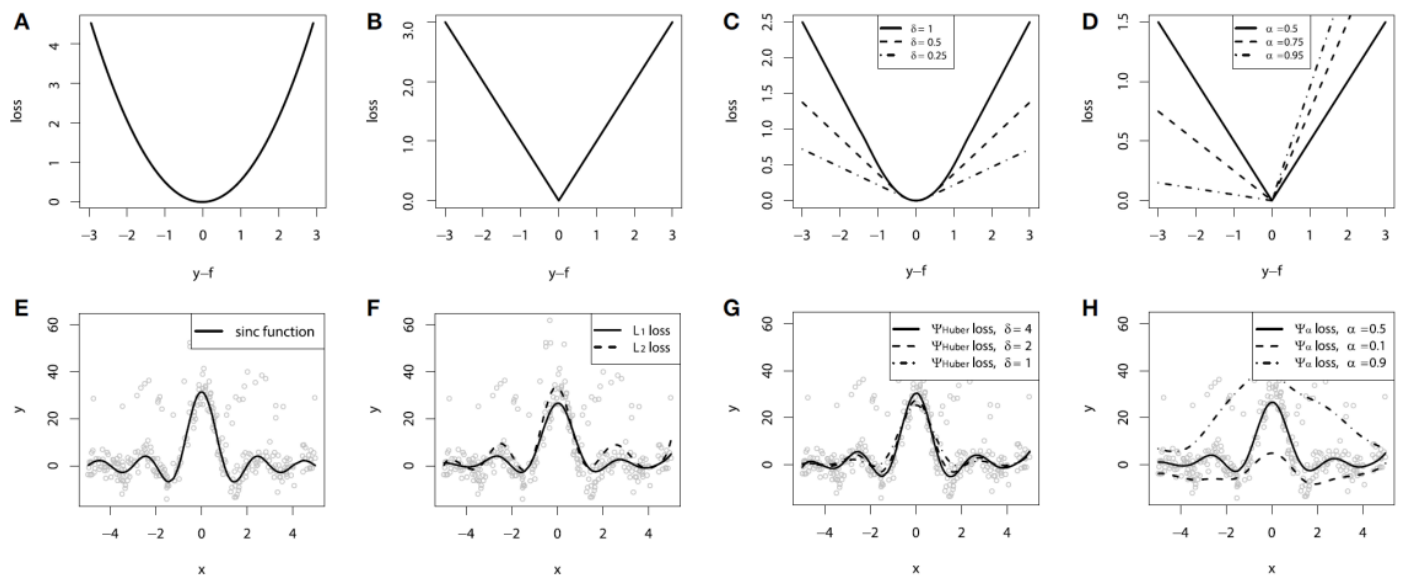
Classification 뿐만 아니라 Refression에서도 사용 가능족보 : GBM -> XGB -> LGBM -> CATB -> NGB머신러닝에서 Gradient Boosting 모델은 많은 발전을 이루어왔습니다. Adaboost, GBM, XGBoost, Li
8.머신러닝 - 분류모델 XGBoost
XGBoost - eXtreme Gradient Boosting A Scalable Tree Boosting System Optimized Gradient Boosting algorithm Missing Values Regularization to avoid over
9.머신러닝 - 분류모델 LightGBM

전통적으로 GBM계열의 알고리즘은 모든 Feature에 대해, 모든 Data에 대해 Scan하여 Information Gain을 획득하게 됨Idea사용하는 Feature와 Data를 줄여보자Gradient based One Side Sampling (GOSS)Infor
10.머신러닝 - 클러스터링 모델
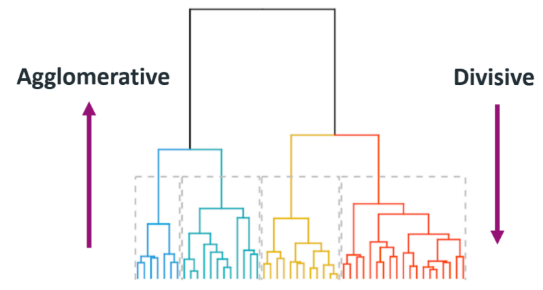
Distance와 Similarity유클리디안 거리 : 벡터거리맨하탄 : 좌표간 절댓값차이코사인 거리 : 벡터사이 각도민코프스키 거리 : 맨하탄과 유클리디안 사이의 동적관계체비셰프 거리 : 인근 8개 셀에 같은 거리처리리벤슈타인 거리 : 편집거리 (문자열 A와 B가 같
11.머신러닝 - 클러스터링 모델
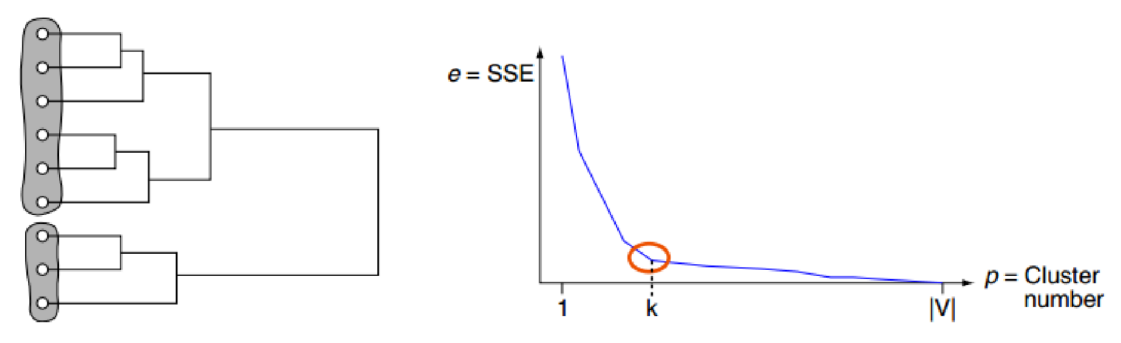
K-means나 Hierarchical Clustering의 경우 군집 간의 거리를 이용한 Clustering 기법DBSCAN은 밀도 기반의 기법이며 세밀하게 몰려 있어서 밀도가 높은 부분을 Clustering 하는 기법점 p가 있다고 할 때, 점 p에서 부터 거리 e
12.머신러닝 - 차원축소
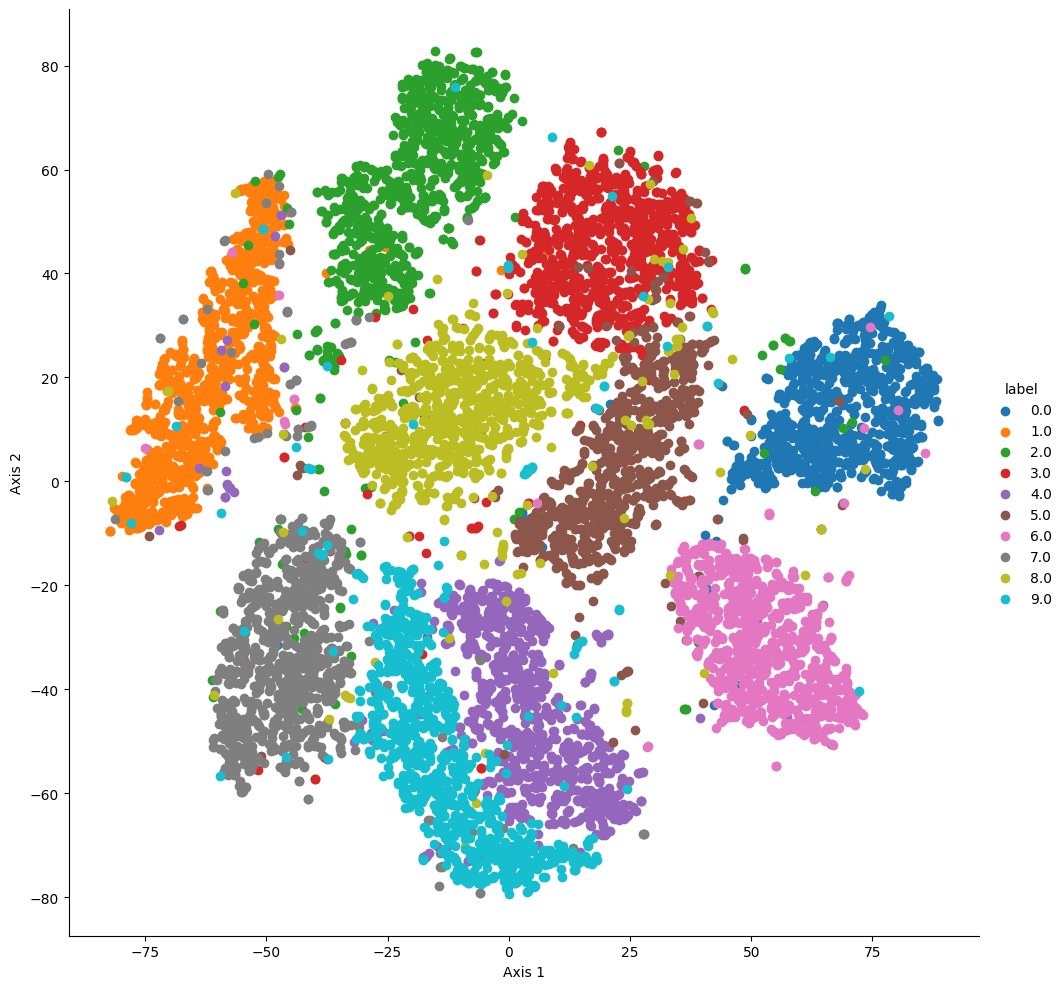
PCAPCA ParametersPackge : https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.htmlncomponents : 몇개의 축으로 차원을 축소할 것인가explai