Convolutional Neural Network
Convolution Layer
Activation Function
모델이 비선형성을 가질 수 있도록
Polling Layer
- Feature Map에 Spatial Aggregation을 시켜줌 (DownSampling)
-> Feature Map의 크기를 감소 : 모델파라미터 감소, Receptive Field 달라짐
AlexNet 모델 등장
ImageNet Large Scale Visual Recognition Challenge (ILSVRC)
- AlexNet (2012) : CNN기반으로 우승한 최초의 모델
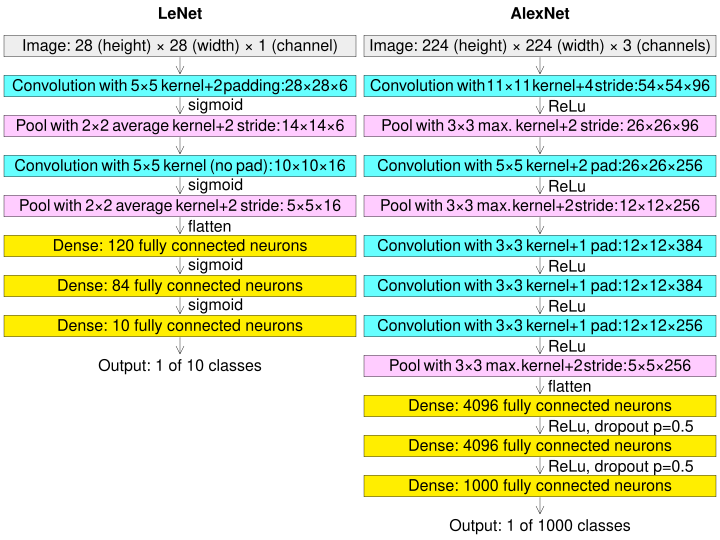
AlexNet의 구조
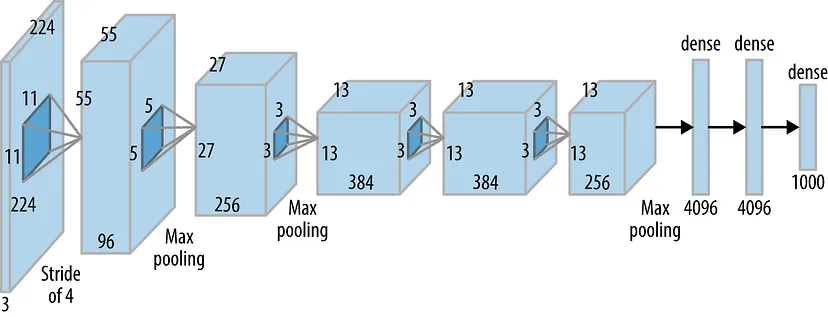
Step 1
Input : 224 X 224 X 3 (RGB)
Conv1 : 11 x 11 x 3 filters, stride = 4 , padding = 2
N = 224
F = 11
S = 4
P = 2
Output Size : (N-F+2P) / S + 1
(224 - 11 + 4) / 4
224 x 224 x 3 -> 55 x 55 x 96
Parameters : (11 11 3 + 1) * 96 = 34,944
ReLU
Pool1 : 3 x 3 filters, stride 2 -> 27 x 27 x 96
Norm1 : Normalization -> 27 x 27 x 96 (정규화)
Step 2
Conv2 : 256 5x5 filters, Stride = 1, Padding = 2 -> 27 x 27 x 256
N = 27
F = 5
S = 1
P = 2
27 x 27 x 96 -> 27 x 27 x 256
ReLU
Pool2 : 3 x 3 filters, stride 2 -> 13 x 13 x 256
Norm2 : Normalization -> 13 x 13 x 256 (정규화)
Step 3
Conv3 : 384 3x3 filters, Stride = 1, Padding = 1 -> 13 x 13 x 384
ReLU
Conv4 : 384 3x3 filters, Stride = 1, Padding = 1 -> 13 x 13 x 384
ReLU
Conv5 : 384 3x3 filters, Stride = 1, Padding = 1 -> 13 x 13 x 384
ReLU
Pool3 : 3 x 3 filters, stride 2 -> 6 x 6 x 256
Step 4
FC1 : 4096 neurons
FC2 : 4096 neurons
FC3 : 1000 neurons (class scores)
Overlapping Pooling
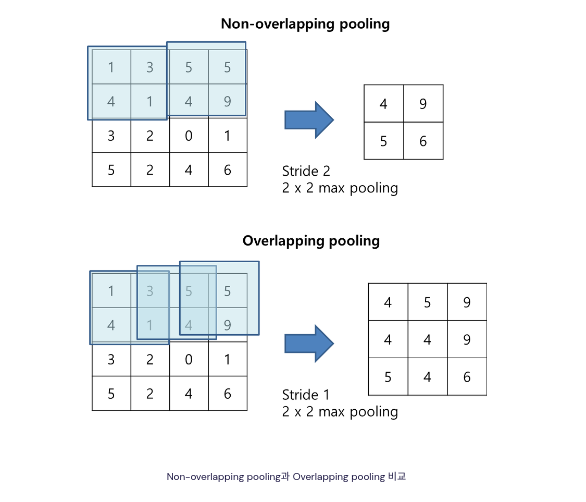
Pooling Layer에서 3x3 filters & stride 2 : 일반적 경우 (F=2, S=2)보다 성능 향상
Local Response Normalization (LRN)
Lateral Inhibition 현상 : 강하게 활성화된 뉴런이 다른 뉴런의 값을 억제하는 현상
- 너무 강하게 활성화된 뉴런이 있을 경우 주변 뉴런에 대해 Normalization 진행
- Normalize를 통해 강하게 활성화된 뉴런의 값을 감소시켜, 특정 뉴런만 활성화되는 것을 막음
- 이후에는 Batch Normalization을 주로 사용
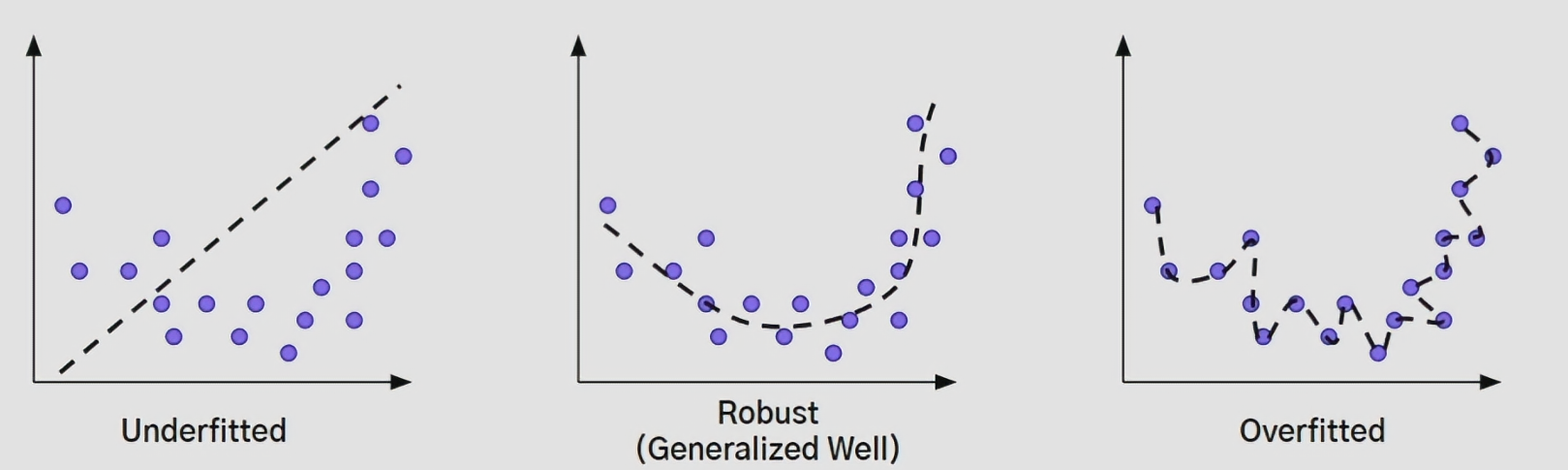
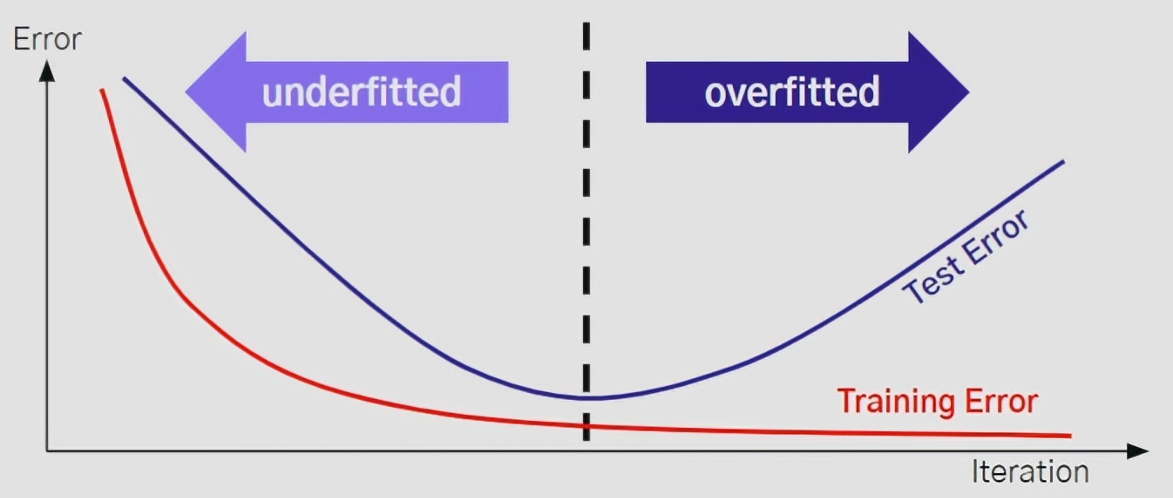
Overfitting 방지
- 학습데이터에 너무 과적합되어 학습되는 경우
- Overfitting 된 모델의 경우 학습 데이터에 대해서 좋은 성능을 나타내지만, 학습 데이터에서 본 적 없는 테스트 데이터에 대해서는 매우 낮은 성능을 보이게 됨
- 학습 데이터에서 보지 않은 데이터에 대해서 좋은 성능을 보이는 일반화가 잘 된 모델을 만드는 것이 궁극적인 목표이므로 Overfitting을 피하기 위한 방법들이 필요함
Data Augmentation
- 학습 데이터에 변형을 가해서 좀 더 다양성을 지닌 데이터로 학습될 수 있도록 하는 방법
Dropout
- 뉴런 중 일부를 일정 비율로 생략하면서 학습을 진행하는 방법
- 몇몇 뉴런의 값을 0으로 바꾸어서 학습 시에 영향을 미치지 못하도록 만들어 일정 뉴런의 값에 치중해 학습되는 것을 방지함
- Dropout은 학습 시에만 행해지고, 테스트를 할 떄는 모든 뉴런을 사용함
VGG
- Small Filters, Deeper Networks
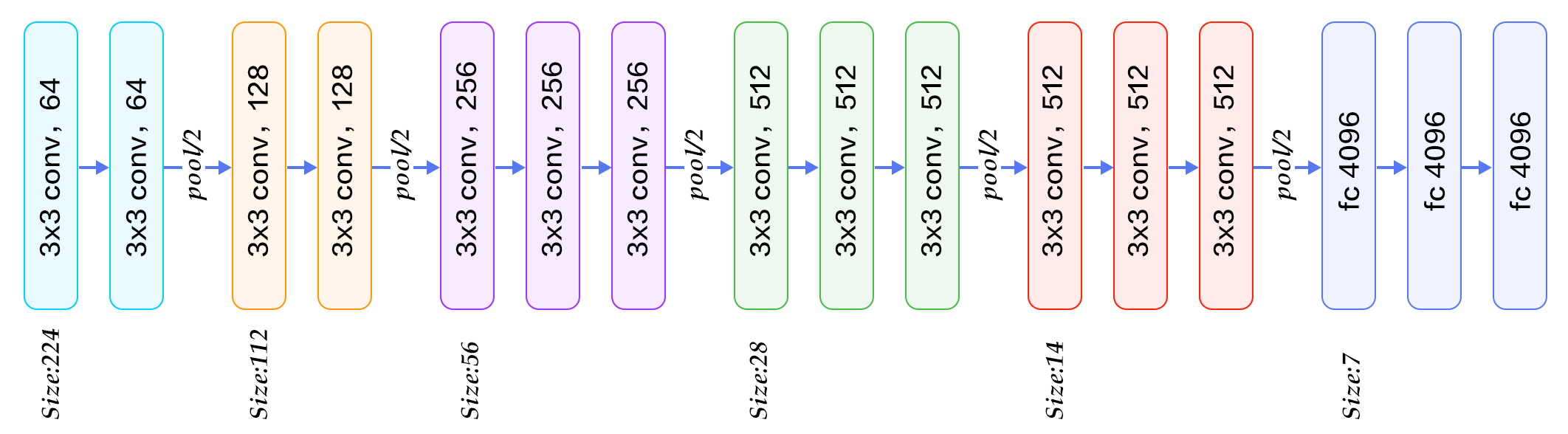
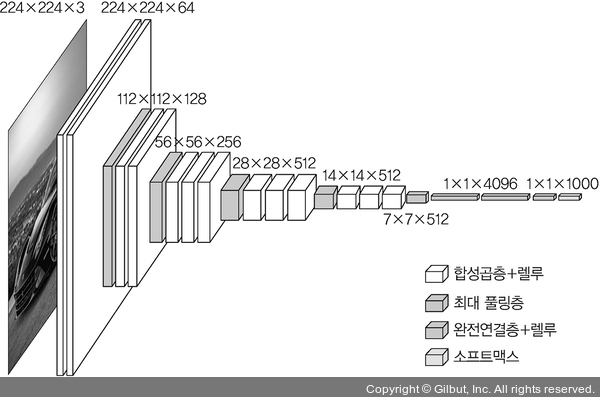
3 x 3 conv 세 개가 7 x 7 conv 하나와 비슷한 효과 (= effective receptive field)
더 적은 파라미터로 구현 가능
C = 레이어당 채널수
3 x (3 x 3 x C x C) vs 7 x 7 x (C x C)
더 많은 레이어를 쌓았을 떄 non-linearities를 높일 수 있음

AI가 재밌는 걸