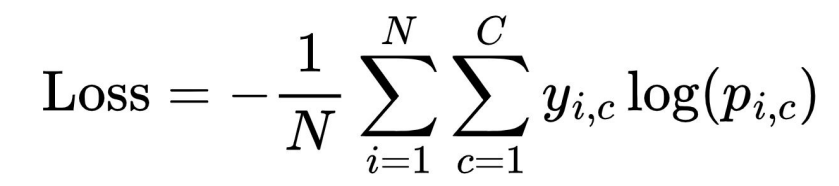Semantic Segmentation
- Semantic segmentation: Pixel-wise로 각각의 Class를 예측하여 물체 Category 별로 분할
- Category: 각 픽셀의 Label 예측
- Architecture: Backbone (Encoder) + Decoder
- Pixel-Wise IoU
Semantic Segmentation Dataset
-
KITTI
● 차량 주행중 촬영된 자동차 및 사물 이미지 데이터
● Semantic Label이 있는 200개의 Train Set과 200개의 Test Set으로 구성 -
Cityscape
● 도시 거리 장면 이미지 데이터
● 50개의 도시의 다양한 시간/계절/날씨를 촬영한 장면 내의
30개의 물체(Class)
● Classes: Group 기준 Flat road, Human, Vehicle,
Construction, Object, Nature, Sky, Void 등
● 5,000장의 이미지 Annotation (Fine-annotation 기준) -
Pascal VOC (Visual Object Classes)
● 시각 객체 클래스 인식을 위한 20개의 사물 클래스 이미지 데이터
● 2012년 데이터 기준 11,530개의 이미지와 6,929개의
Segmentation Annotation
Intersection-over-Union (IoU)
● Pixel-wise IoU 사용
Semantic Segmentation vs Instance Segmentation vs Panoptic Segmentation

Sliding Window
문제점
● 픽셀 주변의 정보밖에 고려하지 못함
● 많은 패치가 중복되는 영역을 처리하기 때문에 계산 비용 증가
Size Preserving Convolutional Layers
문제점
● Receptive field가 여전히 제한적
Downsampling + Upsampling
장점
● 큰 Receptive Field를 가짐
FCN (Fully Convolutional Networks)
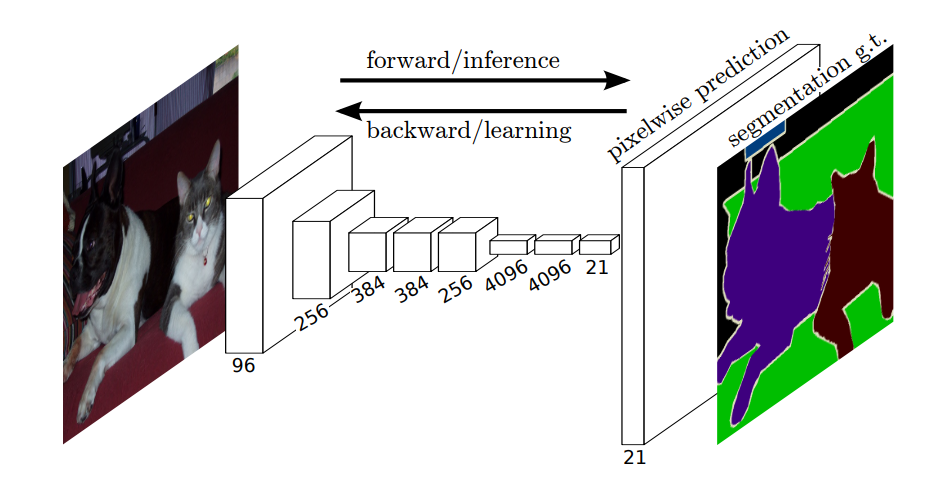
Convolution (Downsampling)
● Backbone (Convolution Layers)를 통해 Features 추출
뒷 레이어로 갈 수록
Receptive Field가 커진다
Deconvolution (Upsampling)
● Feature Map을 확장하여 입력 이미지와 동일한 크기의 Segmentation
Map 생성
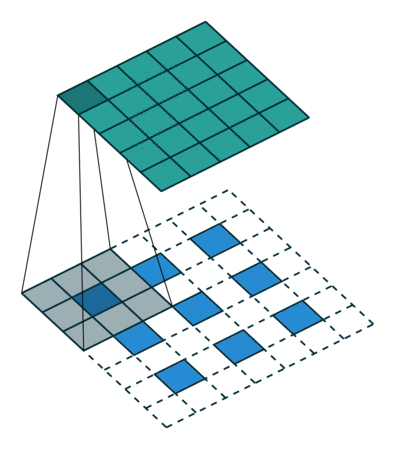
● Stride (S): Filter를 얼마만큼의 간격으로 움직이는 지를 나타냄
Training Process : Loss
● Loss Function: Pixel-wise Softmax Cross-Entropy Loss
● 각 픽셀마다 모델이 예측한 클래스 확률 분포와 실제 레이블의 차이 계산
● Cross-Entropy Loss를 계산