
이번 글은 DGIST 학부 컴퓨터 구조 수업 때 수행했던 프로젝트인 "간단한 MIPS Assembler 만들기"를 정리한 글이다. 프로젝트 보고서와 Background를 합쳐서 정리해보았다.
만약 이 글을 보러 온 여러분이 컴퓨터 구조를 수강하고 있는 DGIST 학부생이라면, 글과 코드를 참고하는 것은 괜찮지만, 이 코드를 그대로 사용하거나 이 글을 보고서용으로 베껴서 사용하는 거는 절대로 해서 안되는 일이라는 점을 알아뒀으면 한다. 너무 과제가 힘들다면 차라리 밑에 있는 메일 주소로 어려운 점을 보내주면 최대한 답변해주도록 하겠다.
Background
1. MIPS architecture
MIPS architecture는 RISC 계열 명령어 집합(Instruction Set Architecture)이다. 구조가 간단해서 많은 학교에서 ISA를 다룰 때 많이 사용한다. 그렇다고 교육용으로 만들어진 ISA는 아니고, 플레이스테이션 1, 2에도 사용되거나, 다양한 임베디드 시스템에 사용되는 등 이전에 활발히 사용되던 아키텍쳐이다. 현재는 개발사가 개발을 중단한 상태이다.
.data
var: .word 5
.text
main:
la $8, var
lw $9, 0($8)
addu $2, $0, $9
jal sum
j exit
sum: sltiu $1, $2, 1
bne $1, $0, sum_exit
addu $3, $3, $2
addiu $2, $2, -1
j sum
sum_exit:
addu $4, $3, $0
jr $31
exit:MIPS Assembly Code는 위와 같은 형식으로 이루어졌는데, 이 코드들을 32bit 바이너리 코드로 바꿔주는 것이 이번 프로젝트의 목표이다.
2. MIPS Instruction 형식
MIPS 32 bit 명령어는 다음과 같이 R형식, I형식, J형식으로 구성된다.
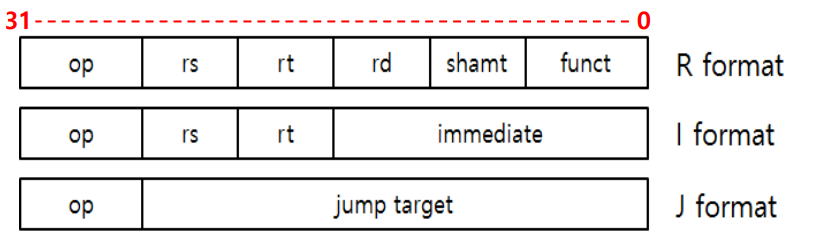
MIPS 명령어들은 모두 맨 앞 6bit에 op code가 있다. op code를 이용해 명령어의 형식을 구분할 수 있다. R형식의 경우에는 op code과 맨 뒤 6bit funct 영역을 조합해 명령어를 파악한다.
R 형식은 레지스터 세 개를 이용해 연산을 하거나, shift 연산을 하는 명령어들이 있다.
- rs, rt : 계산될 피연산자 레지스터
- rd : 연산 결과를 저장할 레지스터이다.
- shamt : shift 연산 시 shift 양. 사용되지 않으면 0으로 채워진다
I 형식은 분기 명령어나, 상수 연산 명령어들이 있다.
- rs : 계산될 피연산자 레지스터
- rt : 연산 결과를 저장할 레지스터
- immediate : 계산할 상수나 분기에 사용되는 주소
J 형식은 Jump 명령어이다.
- jump target : Jump 할 곳의 word 단위 주소. 여기에 4를 곱하면 실제 Jump할 주소가 된다.
3. Label
어셈블리 코드에는 "main:"과 같은 부분이 있는데, 이를 Label이라고 부른다. label은 그 다음에 나오는 코드의 위치를 알려주는 일종의 표식이다.
bne $1, $0, sum_exit예를 들어, 위 코드는 "sum_exit"이라는 label을 가지고 있다. BNE은 입력 받은 두 레지스터 속 값이 다를 때 label에 해당하는 코드로 jump하는 명령어이다. 어셈블러는 이 label의 실제 메모리 주소를 파악한 다음 BNE의 바이너리 코드 속 offset 영역에 메모리 주소의 offset을 넣어야 한다.
Objective
1. 지원해야 하는 명령어
이 Project의 목표는 MIPS ISA assembler를 만드는 것이다. Assembler가 지원해야 하는 명령어는 다음과 같다.
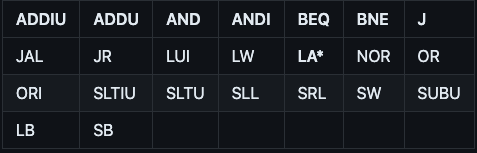
구체적인 명령어 설명이나, opcode 등의 정보는 https://inst.eecs.berkeley.edu/~cs61c/resources/MIPS_Green_Sheet.pdf 를 참고하면 된다.
2. LA 명령어
여기서 LA(Load Address) 명령어는 실제 명령어가 아닌 의사 명령어이므로, 이 명령어는 immediate 영역의 수를 레지스터의 상위 16bit에 저장하는 LUI 명령어와, immediate 영역의 수를 레지스터 속 값과 or 연산을 한 수 다시 레지스터에 저장하는 ORI 명령어의 조합으로 이루어진다.
예를 들어, 다음과 같은 LA 명령어가 주어져 있다고 하자
la $4, array2이 명령어는 4번 레지스터에 array2에 해당하는 주소를 넣는 명령어이다. 만약 array2의 주소가 "0x1000 0000"과 같이, 상위 16bit만 존재하는 경우에는 다음과 같이 LUI 명령어 하나만 이용하면 된다
lui $4 0x1000하지만, array2의 주소가 "0x1000 0040"과 같이, 하위 16bit도 존재하는 경우에는 ORI 명령어도 같이 이용해 다음과 같이 표현한다
lui $4 0x1000
ori $4 0x00403. 이외의 목표사항
LB(Load Bit)와 SB(Store Bit)을 제외한 나머지 load, store 관련 명령은 4B word만 지원하면 된다
그리고 이 Assembler는 10진수와 16진수를 모두 지원해야 한다. 16진수는 숫자 앞에 "0x"가 붙어 10진수와 구분된다
레지스터의 이름은 항상 "$n"과 같은 형태이고, n은 0부터 31까지이다.
메모리 주소는 ".text" 영역과 ".data" 영역으로 이루어져 있다. ".text" 영역은 0x00400000부터 시작하고, ".data" 영역은 0x10000000 부터 시작한다.
Approach Detail
최종 코드는 내 깃허브에 있다.
1. 빌드 방법과 실행 방법
C++을 이용해 개발했다. 소스 코드는 src 폴더에, 헤더 파일들은 include에 있다. Ubuntu 20.04, g++ 9.4.0에서 Make를 이용해 빌드했다. 다음 명렁어로 빌드할 수 있다
make clean; make이후 Assembler를 사용할 때는 다음과 같이 변환하고자 하는 어셈블리 코드 파일을 인자로 넘기면 된다.
/mipsAssemblerFinal sample.s실행 후 인자로 넣은 파일의 이름과 동일한 형태의 *.o 바이너리 파일이 생성된다
2. 코드의 구조
코드는 다음 네 부분으로 이루어져있다.
- 00_main.cpp : 어셈블러의 메인 함수가 있다. 어셈블리 코드를 읽고 라인별로 저장한 뒤, 코드 속 .data와 .text를 분리해 16진수 바이너리 코드로 만든다.
- 01_DataManage.cpp : 데이터를 변환하고 판별하는 함수들이 있다. 여기에 있는 함수들 중 일부는 이후 프로젝트에서도 사용된다.
- DecimalToHex : 10진수 integer를 받아 16진수 문자열로 반환한다
- SplitLine : separator 문자를 기준으로 문자열을 분리해 std::vector<std::string> 형태로 반환한다
- StrHaveChar : 입력된 문자열이 특정 문자를 가지고 있는지 판별해 bool 값으로 결과를 반환한다.
- NumToBit : std::string 형태의 수와 크기를 받으면 이에 해당하는 이진수 값의 std::string 을 크기에 맞춰서 반환한다
- 02_InstructionConvert : instruction을 16진수 문자열로 반환하는 함수와 instruction의 opcode, funct 정보를 가지고 있는 std::map이 있다.
- InstrConvert_R : R형식 instruction을 16진수 문자열 바이너리 코드로 바꾼다
- InstrConvert_I : I형식 instruction을 16진수 문자열 바이너리 코드로 바꾼다
- InstrConvert_J : J형식 instruction을 16진수 문자열 바이너리 코드로 바꾼다
- InstrConvert_Control : instruction을 받아 명령어 형식 별로 적절한 변환 함수를 불러온다
- 03_CodeManage.cpp
- DataLabeling : .data 영역의 코드 중 label이 있으면 label에 해당하는 메모리 주소를 계산한 다음 label을 key로 사용하는 std::map에 저장한다
- TextLabeling : DataLabeling과 유사하게, .text 영역의 코드 중 label이 있으면 label의 메모리 주소를 계산한 다음 label을 key로 하는 std::map에 저장한다
- DataSave : .data 영역의 코드를 16진수 문자열 바이너리 코드로 바꾼다
- InstrSave : .text 영역의 코드를 16진수 문자열 바이너리 코드로 바꾼다. 코드 위치는 "PC"를 이용해 추적한다.
3. 코드의 flow
- 어셈블리 코드를 읽으면서 .data 영역과 .text 영역으로 구분한다.
- 이후 .data 영역과 .text 영역의 label들의 메모리 주소를 구한다
- DataSave와 InstrSave에서 앞서 구한 label 메모리 주소를 활용해 명령어를 바이너리 코드로 변환한다.
- 변환된 바이너리 코드를 반환한다
4. 보완해야 할 점
이 프로젝트 코드는 예전에 만들었는데, 지금 다시 정리하면서 보면 보완해야 할 점이 몇가지 보인다.
일단 03_CodeManage.cpp에 있는 함수들은 한 번만 사용되니까, main 함수 안에 해당 코드를 그대로 집어 넣는게 더 좋지 않았을까 하는 생각이 든다.
그 다음은, 다음 프로젝트 코드들에도 해당되는 이야기인데, bit 연산을 처리할 때 모두 bitset과 string을 이용해 처리했는데, 이거를 그냥 bit 연산자와 매크로로 처리하면 훨씬 간단하고 빠른 코드를 만들 수 있었을 거 같다.
string InstrConvert_I(vector<string> instr, unsigned int PC){
string converted_instr = "";
unsigned int temp_converted_instr = 0;
string op = NumToBit(to_string(InstrInfo[instr.at(0)].first), 6);
string rs = "";
string rt = "";
string imm_or_offset = "";
...
temp_converted_instr = stoul(op+rs+rt+imm_or_offset, nullptr, 2);
converted_instr = DecimalToHex(temp_converted_instr);
}위 코드는 InstrConvert_I의 일부를 들고왔는데, 여기서 op, rs, rt, imm 모두 string으로 처리한 다음, string 연산을 이용해 바이너리 코드로 만들고 있다. 이것보다는 op, rs, rt, imm을 모두 unsigned int라 할 때, 이들을 모두 합쳐서 바이너리 코드로 만들 때 다음과 같이 처리할 수도 있다. 그러면 int를 string으로 변환했다가 다시 unsigned long으로 변환했다가 다시 string으로 변환하는 헛짓거리를 안 할 수 있다.
binary_code = (op << 26) & (rs << 21) & (rt << 16) & imm;이 프로젝트를 할 때 어떤 능력자는 이 코드를 C로 300줄 정도만에 만들었다고 하는데(...) 아마 매크로를 사용하고 여러 규칙들을 잘 찾아서 사용하면 그정도로 코드를 줄일 수 있지 않을까 싶다.
