
이번 글이번 글은 DGIST 학부 컴퓨터 구조 수업 때 수행했던 프로젝트인 "MIPS Instruction Emulator"를 정리한 글이다. 프로젝트 보고서와 Background를 합쳐서 정리해보았다.
만약 이 글을 보러 온 여러분이 컴퓨터 구조를 수강하고 있는 DGIST 학부생이라면, 글과 코드를 참고하는 것은 괜찮지만, 이 코드를 그대로 사용하거나 이 글을 보고서용으로 베껴서 사용하는 거는 절대로 해서 안되는 일이라는 점을 알아뒀으면 한다. 너무 과제가 힘들다면 차라리 밑에 있는 메일 주소로 어려운 점을 보내주면 최대한 답변해주도록 하겠다.
Background
MIPS architecture와 관련된 내용은 지난번 글에서 다뤘기 때문에, 이번 글에서는 다루지 않을 예정이다.
다뤄 볼 내용은 Big-endian과 Little-endian 정도인 거 같다. 메모리는 주소별로 바이트 단위만큼 데이터를 저장한다. Big-endian과 Little-endian은 데이터를 메모리에 바이트 단위로 저장할 때 어떤 순서대로 저장할 지를 나타내는 개념이다. Big-endian은 least significant byte를 가장 나중에 저장하고, Little-endian은 least significant byte를 가장 먼저 저장한다.
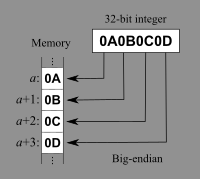
32bit (4B = 1word) 정수를 메모리에 저장할 때를 예를 들면, Big-endian으로 저장하면 위 그림과 같이 맨 앞부터 순서대로 1바이트 씩 저장하면 된다.
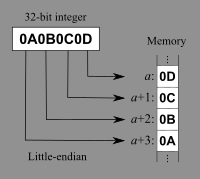
Little-endian으로 저장한다면 맨 뒤 바이트 0D부터 거꾸로 1바이트 씩 메모리에 저장한다.
Big-endian이 직관적이고 구현하기 쉬울 거 같아 보인다. 그러면 Little-endian은 어떤 점에서 장점을 가질까? 우선 Little-endian은 제일 작은 부분의 바이트에 접근할 때 Big-endian보다 연산을 적게 해도 된다. 예를 들어, "0x1110"이라는 정수에서 맨 뒤 "10" 부분만 필요하다고 하자. 그러면 각각 다음과 같이 메모리에 저장되어 있을 거다.
| 주소 | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| Big-endian | 00 | 00 | 11 | 10 |
| Little-endian | 10 | 11 | 00 | 00 |
Little-endian은 메모리 주소인 0에 바로 접근하면 10을 얻을 수 있지만, Big-endian은 메모리 주소 0에 3을 더하는 과정을 거쳐야 10을 얻을 수 있다.
그리고 Little-endian은 자료형의 크기를 바꿀 때 Big-endian보다 연산을 적게 해도 된다. 예를 들어, 기존에 있던 정수 0x1110을 32bit 공간에 저장하는게 아니라 64bit 공간에 저장한다고 했을 때, Big-endian은 기존 주소에 있던 값들을 뒤로 4칸씩 미루는 연산을 해야 하지만, Little-endian은 단순히 0으로 이루어진 4B를 붙이기만 하면 된다.
Big-endian과 Little-endian은 각각 장단점이 있지만 어느 하나가 지배적으로 사용되지는 않는다. 대부분 데스크탑 컴퓨터에 사용되는 x86 기반 아키텍처에서는 Little-endian이 사용되고, 네트워크에서는 Big-endian이 사용된다.
Objective
이번 프로젝트의 목표는 지난 프로젝트에서 만든 Assembler로 만든 바이너리 코드를 실행하는 Emulator를 만드는 것이다.
States
사용되는 레지스터는 R0~R31과 PC(Program Counter)가 있고, text 영역의 메모리 주소는 0x40 0000부터, data 영역의 메모리 주소는 0x1000 0000부터 시작한다. jal 명령어에 사용되는 $ra는 R31이다.
레지스터, 메모리에는 음수가 올 수 있고 음수는 two's complement로 처리해 sign extended 상태로 저장된다.
레지스터와 메모리의 초기값은 다음과 같다.
- PC : text 영역의 시작 주소인 0x40 0000
- 레지스터들 : 0
- 메모리 : 바이너리 코드에서 불러온 text 영역과 data 영역을 제외하면 모두 0
Instruction 실행
Emulator는 현재 PC 값에 해당하는 주소에서 Instruction을 읽어 온 다음 Instruction들을 수행해야 한다. 수행하면서 PC, 레지스터, 메모리에 값의 변화가 있다면 이것이 정확하게 반영되어야 한다.
Instruction Set은 프로젝트 1과 동일하나 다음과 같은 조건들이 있다.
lb: 8 bit를 load한 뒤 32bit로 sign-extension 한 뒤 지정된 레지스터에 값을 저장한다sb: least significant 8 bit를 지정된 메모리 주소에 저장한다
MIPS는 Big-endian으로 값을 저장한다
Emulator 실행 option
Emulator는 다음 인자들을 받아 다음 기능들을 수행할 수 있어야 한다
$./runfile [-m addr1:addr2] [-d] [-n num_instruction] input_file-m: Emulator가 끝난 이후 addr1에서 addr2 사이 메모리 주소 범위에 있는 내용들을 출력한다.-d: 한 Instruction이 끝난 이후 현재 레지스터의 상태를 출력한다. 이때,-m옵션이 설정되어 있다면, 해당하는 범위의 메모리 주소도 출력한다. 이 옵션이 없으면 프로그램이 끝날 때만 레지스터의 상태를 출력하면 된다.-n: 실행할 Instruction의 수를num_instruction만큼 제한한다. 이 옵션이 없으면 프로그램이 끝날 때 까지 실행한다.input_file: 바이너리 코드 파일
Approach Details
최종 코드는 [다음 깃허브]((https://github.com/saychuwho/undergraduate_learning/tree/main/Computer_Architecture/project2)에 있다.
빌드 방법과 실행 방법
C++을 이용해 개발했다. 소스 코드는 src 폴더에, 헤더 파일들은 include에 있다. Ubuntu 20.04, g++ 9.4.0에서 Make를 이용해 빌드했다. 다음 명렁어로 빌드할 수 있다. cmake가 설치되어 있어야 사용할 수 있다.
make clean; makeEmulator 사용 방법은 "Objective-3. Emulator 실행 option"과 동일하다.
코드 구조
코드는 다음 네 부분으로 이루어졌다
- 00main.cpp : 메모리 레지스터 선언 및 초기화, 바이너리 코드를 메모리에 load, Emulator 옵션을 받아서 실행 방식 설정, instruction 수행 등 전반적인 흐름을 담당한다.
- 01datamanage.cpp : Project 1의 "01_DataManage.cpp"에서 몇몇 함수들이 추가되었다.
- DecimalToHex : Project 1의 함수에서
isSigned인자를 추가해 기본값인 false - SplitLine : Project 1과 동일하다
- StrHaveChar :
str에 char c가 있는지 여부를 확인하고 true/false를 반환한다 - NumToBit : String 형식의 수를 받으면 이 중 least significant bit를
size의 크기에 맞춰서 string 형식으로 반환한다. - StrIsNum :
str이 숫자인지 판별한다.isHex가 true일 때는 16진수를 기준으로 판별한다 - BitExtended : string 형식의 bit를 받으면
isSingEx가 true일때는 sign-extended, false일때는 zero-extend한 후 string 형식의 bit로 반환한다.
- DecimalToHex : Project 1의 함수에서
- 02doInstr.cpp : Instruction을 수행하는 함수들이 있다.
- doInstr_R : R형식 Instruction을 수행한다
- doInstr_I : I형식 Instruction을 수행한다
- doInstr_J : J형식 Instruction을 수행한다
- 03memRegManage.cpp : 메모리 access를 관리하는 함수들이 있다
- RegMemCout : 현재 레지스터와 지정된 메모리 범위 속 내용들을 형식에 맞춰서 출력한다
- instDecode : PC 값이 가리키는 메모리에서 Instruction을 불러온 후 이를 instruction 형식에 맞춰서 decode 한 다음 형식에 맞는 함수들을 불러온다
- MemLoad / MemWrite : 주소에 맞는 메모리에서
isWord가 true인 경우에는 word 단위로, false일때는 byte 단위로 load, store 연산을 수행한다
코드 flow
- Emulator가 시작되면 레지스터 Reg, PC, 메모리 Mem을 초기화한다
- Emulator가 실행될 때 받은 flag들을 해석해서 실행 옵션을 설정한다. 이때 유효하지 않은 설정이 들어오면 종료한다.
- 바이너리 코드 파일을 연 후 유효한 파일인지 검사한다. 이후
text영역과data영역을 Mem에 load한다. - 이후 PC 값에 따라 Instruction을 실행한다. 이때 PC 값이 프로그램의 끝을 가리키면 실행을 중단한다.
보완해야 할 점
우선 나는 이번 프로젝트에서 그렇게 좋은 점수를 받지 못 했다. 마지막에 jump instruction들의 주소를 처리하는 과정에서 코드 상에서는 맞게 동작하는 것 처럼 보였지만 실제로는 PC 값이 이상하게 들어가서 jump instruction이 제대로 실행되지 않는 경우가 있었기 때문이다. 지금 깃허브에 있는 코드는 최종 제출본에서 doInstr_J()을 수정해서 제대로 동작하도록 바꿨다.
사실 이전 doInstr_J() 대로 실행하면 정상적으로 동작했지만, Jump Instruction에 사용되는 메모리 처리를 내가 Objective 대로 처리하지 않고 있다는 사실을 알아 마감 전 급하게 확인도 안하고 바꿔서 생긴 일이긴 하다.
코드의 잘못된 점은 지난 글에서도 언급했지만 내가 bit 연산을 std::bitset과 string 연산으로 처리하고 있었기 때문이다. string 으로 만들어진 bit를 stoul() 함수로 unsigned long으로 바꾸더라도 내가 의도한 대로 값이 안 나올 수 있다.
다음은 내 최종 제출본 doInstr_J()이다.
void doInstr_J(string op, string target){
unsigned int tmp_op = stoul(op, nullptr, 2);
unsigned int tmp_target = stoul(target, nullptr, 2);
// 주목해야 할 부분
// bitset으로 PC 값과 target * 4를 변환
bitset<28> bitAddr(tmp_target*4);
bitset<32> bitPC(PC);
// 이후 bitset을 string으로 변환 후 string 연산으로 address를 구한다
string temp_addr = bitPC.to_string().substr(4) + bitAddr.to_string();
unsigned int addr = stoul(temp_addr, nullptr, 2);
if(tmp_op == 2){ // j 형식
PC = addr;
}
else if(tmp_op == 3){ // jal 형식 : $ra는 R31이다
Reg[31] = PC + 4; // 다음에 실행할 Instruction이니까 PC + 4
PC = addr;
}
}위 주석대로, 이번 프로젝트를 비롯해 다음 프로젝트들에도 bit를 std::bitset과 string 연산으로 처리하고 있다. 위 코드가 의미적으로는 멀쩡해 보이지만, 실제로 이대로 doInstr_J()을 넣은 뒤 컴파일해서 Emulator에 sample2.o를 넣고 실행하면 Jump Instruction이 제대로 동작하지 않아 sample2.o의 의도대로 실행되지 않는다.
운영체제 프로젝트(추후에 올릴 예정이다)를 하면서 bit 연산에 자신감이 붙은 지금은 저렇게 복잡하고 비효율적으로 bit 연산을 하지 않고 C++의 기본 bit 연산만 가지고 제대로 동작하는 doInstr_J()를 만들 수 있다. 다음은 깃허브에 있는 수정된 doInstr_J()이다.
void doInstr_J(string op, string target){
unsigned int tmp_op = stoul(op, nullptr, 2);
unsigned int tmp_target = stoul(target, nullptr, 2);
// bit 연산을 이용한 코드로 바꿨다.
unsigned int addr = (PC & 0xff000000) | (tmp_target*4);
if(tmp_op == 2){ // j 형식
PC = addr;
}
else if(tmp_op == 3){ // jal 형식 : $ra는 R31이다
Reg[31] = PC + 4; // 다음에 실행할 Instruction이니까 PC + 4
PC = addr;
}
}바뀐 부분을 다음과 같이 들고왔다.
// 이전 코드
string temp_addr = bitPC.to_string().substr(4) + bitAddr.to_string();
unsigned int addr = stoul(temp_addr, nullptr, 2);
// 바뀐 코드
unsigned int addr = (PC & 0xff000000) | (tmp_target*4);이전 코드는 bitset<32> bitPC의 상위 4bit를 .to_string().substr(4)를 이용해 bitset<28> bitAddr의 앞에 붙였다면, 바뀐 코드는 PC & 0xff000000을 이용해 PC의 상위 4bit를 가져오고, 이를 or 연산을 이용해 tmp_target*4 앞에 붙였다.
앞으로도 bit 연산을 다룰 일이 있다면, 자료형의 구조를 정확히 이해하고 있다면 정확하고 빠르게 다룰 수 있다.
