AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Computer Vision
AnimateAnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Abstract
논문에서는 개인화된 T2I(Text-to-Image) 모델에 대해서 영상을 생성할 수 있는 프레임워크에 대해서 소개한다. 제안된 프레임워크의 핵심은 Frozen T2I 모델에 Motion Modeling Module을 삽입하여 영상을 생성하는 것이고, 학습된 Motion Module은 개인화된 T2I 모델에 General하게 적용이 가능하여 각 모델에 따른 별도의 Tuning 비용을 줄일 수 있다고 주장한다.
Introduction
T2I 모델을 기반으로 한 일반적인 T2V(Text-to-Video)모델은 Time Modeling을 결합하여 Large Video Dataset으로부터 Fine Tuning하는 방식이 제안되어 왔다. 하지만, T2V 모델로부터 개인화 모델을 만들기 위해선 하이퍼파라미터 조정, 개인화된 영상 수집, 고성능 리소스 등이 필요한 상황이기 때문에 논문에서는 Dreambooth, LoRA 등을 통해 생성된 개인화된 T2I 모델로부터 범용적으로 적용할 수 있는 AnimateDiff 방법론을 제안했다. 구체적으로 Motion Modeling Module을 설계하고, T2I 모델에 삽입하여 대규모 비디오 클립으로부터 Motion Modeling Module을 Fine Tuning하는 방식을 제안한다.
논문에서는 Dreambooth나 LoRA와 같은 개인화 방법론이 적용된 T2I 모델에 대해서 AnimateDiff를 적용하여 평가를 진행했으며, 모델에 대한 별도의 Fine Tuning 없이 영상 생성이 가능하다고 주장한다. 또한, time dimension에서 vanilla attention만으로도 motion modeling module이 충분히 학습하는 것을 확인했다고 주장했다. 결론적으로 T2I 모델에 대한 리소스를 할당하면 개인화된 애니메이션을 얻을 수 있다고 주장한다.
Method
Preliminaries
General text-to-image generator
먼저, 논문에서는 AnimateDiff를 적용하기 위한 Base T2I Model에 대해서 언급한다. AnimateDiff의 Base T2I Model 구조는 Stable Diffusion Model로 채택했으며, 전체 수식은 다음과 같다.

Stable Diffusion Model(Latent Diffusion Model)의 과정에 대해서 간략하게 설명하면 다음과 같다.
1. 입력 이미지에 대해서 VQ-GAN 혹은 VQ-VAE와 같은 AutoEncoder를 통해 Latent Vector 생성
2. Forward Process : Latent Vector에 대해서 Markov Process 기반 노이즈 생성(확산)
3. Reverse Process : Latent Vector로부터 UNet 모델 기반 디노이즈 수행. 여기서, 입력된 text prompt에 대해서 CLIP 모델을 기반으로 sequence vector를 생성하고 time step과 노이즈가 추가된 latent vector를 UNet 모델을 통해 노이즈를 제거한다.
Personalized image generation
여기서는 Personal Text-to-Image Generation 방법론인 Dreambooth와 LoRA를 소개한다.
Deambooth는 Pretrained T2I 모델을 적은 데이터셋을 가지면서 새로운 도메인에 대해서 학습시킬 때 발생하는 Overfitting이나 Forgetting 상황을 해결하기 위해 희귀 문자열 및 Original T2I 모델 기반 Augmentation을 도입했다.
한편, LoRA는 모델 가중치의 residual을 fine tuning하는 방식을 제안했다. 즉, Fine Tuning 후의 Weight를 라고할 때 를 학습한다. 여기서, 는 Fine Tuning의 영향을 조정할 수 있는 하이퍼 파라미터를 의미한다.
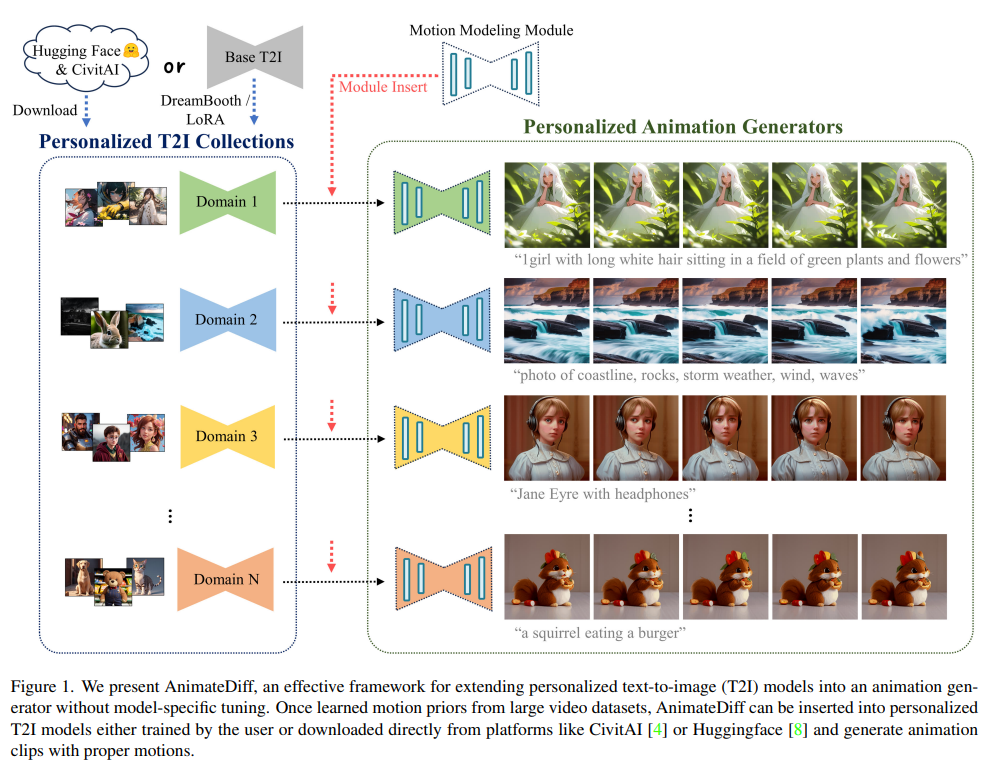
Personalized Animation
논문에서는 AnimateDiff의 타겟을 다음으로 선정했다.
1. Dreambooth 또는 LoRA로 학습된 모델
2. CivitAI 혹은 HuggingFace에서 다운로드된 모델
그리고 AnimateDiff의 목표는 위의 모델을 약간의 학습 Cost(혹은 Free)로 original domain knowledge와 quality를 보존하면서, animation generator로 변환하는 것임을 명시했다.
이를 위한 방법으로 개인화된 T2I 모델을 Freeze하고 Motion Modeling Module을 삽입하여 학습시키는 방식을 언급했고, ControlNet 모델의 사례를 통해 이 방법의 효율성 및 정당성을 주장했다.
Motion Modeling Module
Network Inflation
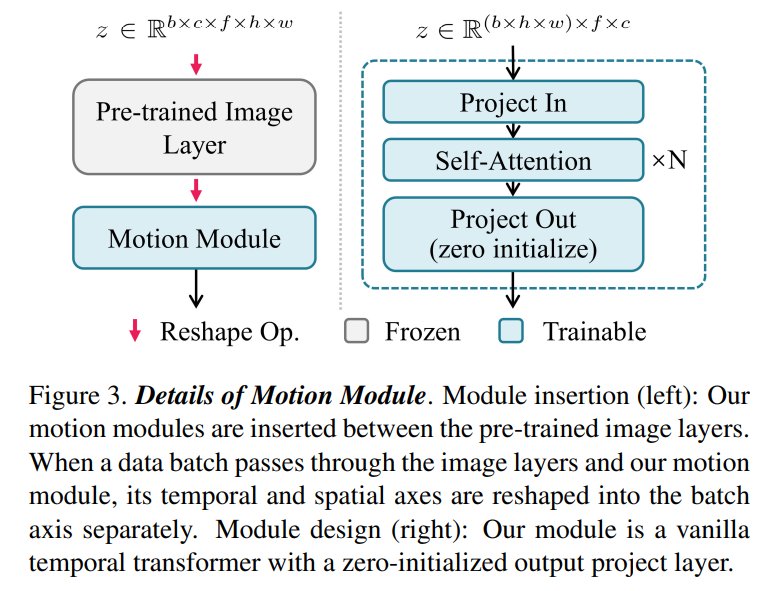
Motion Modeling Module을 적용하기에 앞서, Stable Diffusion Model은 일반적으로 2D 이미지의 배치 데이터만 처리할 수 있으므로, 입력된 batch x channel x frame x height x width의 5차원 텐서에 대해서 frame 축을 batch 축으로 형태를 바꿈으로써 원래의 이미지 모델의 2D Convolution 및 Attention Layer를 Pseudo-3D Layer로 변환하는 방법을 적용했다. (Video Diffusion Model 방법 응용)
Module Design
논문에서는 Motion Modeling Module의 design 관련하여 여러 temporal transformer architecture를 기반으로 실험을 진행했으며, 기본적인 vanilla temporal transformer만으로도 충분한 성능을 보임을 언급했다. 그리고 더 나은 motion module architecture는 추후 연구로 남겨두었다.
Fig 3을 보면, vanilla temporal transformer는 시간 축을 따라 동작하는 여러 개의 self-attention block으로 구성된 것을 알 수 있다. 여기서, temporal transformer에 입력하기 전에 featuremap의 height와 width를 batch 축으로 reshape해서 frame의 길이를 갖는 새로운 batch x height x width 시퀀스를 생성한다.
vanilla temporal transformer의 self-attention blcok의 연산을 통해 동일한 위치에서 feature 간의 시간에 따른 temporal dependency를 포착할 수 있다. 논문 저자는 motion module의 receptive field를 확장하기 위해 U-shaped diffusion network의 resolution level에서 motion module을 삽입했다. 추가적으로 sinusoidal position encoding을 self-attention block에 추가하여 현재 프레임의 temporal location을 인식할 수 있도록 유도했다. 마지막으로 효과적으로 motion module을 pretrained T2I 모델에 삽입하기 위해 output projection layer의 초기 가중치를 zero initialization했다. (ControlNet에서 검증된 방법)
Training Objective
Motion Modeling Module의 학습 과정을 Latent Diffusion Model과 유사하다.
1. 샘플 비디오 데이터로부터 pretrained auto encoder를 통해 latent vectore로 인코딩
2. forward diffusion process 기반 노이즈 추가
3. latent vector와 입력받은 프롬프트를 기반으로 latent vector에 추가된 노이즈를 예측하고 L2 loss term 기반 학습 진행
Experiments
Implementation Details
Training
논문에서 실험한 환경은 다음과 같다
1. Stable Diffusion v1
2. Dataset : Webvid-10M
3. Frame Sampling : 4 / Frame Length : 16 / Resolution : 256
추가적으로 실험을 통해 T2I 모델 학습시에 사용된 diffusion schedule을 수정했을 때, 새로운 데이터 분포에 잘 적응할 수 있는 것을 발견했고 이를 기반으로 , 로 수정했다.
Evaluations

개인화된 T2I 모델에 대해서 AnimateDiff의 효과를 확인하기 위해, 위의 모델들을 기반으로 평가를 진행했다. 텍스트 프롬프트의 경우는 개인화된 T2I 모델에 맞는 텍스트 프롬프트를 입력으로 사용했다.
Results
 Qualitative results over the personalized T2I models
Qualitative results over the personalized T2I models
 Baseline comparison results
Baseline comparison results
 Ablation Study
Ablation Study
Limitations and Future Works
 Failure cases
Failure cases
AnimateDiff는 Webvid-10M을 기반으로 학습되는데 이는 현실적인 비디오 데이터들을 다루고 있기 때문에 현실적이지 않은 데이터(e.g. 2d disney)에 대해서 일부 artifact가 나타나거나 모션 생성이 힘든 경우를 확인할 수 있다. 이를 해결하기 위해선, 해당 도메인의 영상을 수집한 뒤 일부 fine tuning을 진행해야된다고 주장한다.
Conclusion
본 논문에서는 AnimateDiff라는 실용적인 프레임워크를 제시했다. AnimateDiff의 motion modeling model은 vanilla temporal transformer architectrue만으로 개인화된 T2I 모델로부터 적절한 모션을 가진 애니메이션을 생성할 수 있고, 한번 학습된 motion modeling model은 여러 T2I 모델에 사용이 가능한 범용적인 장점을 가지고 있다.
