Adversarial Diffusion Distillation

Abstract
논문에서는 Adversarial Diffusion Distillation(ADD)를 통해 1-4 step만으로 높은 이미지 퀄리티를 생성할 수 있는 효과적인 Diffusion 모델을 소개한다.
구체적으로는 score distillation을 통해 large scale diffusion model을 teacher 모델로써 사용하여 adversarial loss를 얻음으로써 low sampling step에서도 high fidelity를 달성했다.
제안하는 모델은 1 step만으로도 기존의 방법(e.g. GAN, Latent Consistency Models)보다 높은 성능을 보이고, 4 step만으로 SDXL 모델의 성능에 도달할 수 있는 것을 확인 할 수 있었으며 real-time image synthesis을 달성할 수 있었다고 주장한다.
Introduction
저자는 Diffusion 모델은 높은 sampling quality를 가지지만, 상당 수의 sampling step이 필요한 점과 GAN 모델은 단일 추론으로 빠른 생성 속도를 가지지만, large scale dataset에서의 낮은 생성 퀄리티를 문제로 삼으며 real-time이면서 high quality image generation을 위한 방법을 제시한다.
이를 위해 저자는 adversarial loss와 score distillation sampling (SDS)에 해당하는 distillation loss를 적용한 학습 전략을 소개한다.
본 논문의 기여는 다음과 같다.
- 1-4 sampling step만으로 pretrained diffusion model의 high fidelity를 달성할 수 있는 ADD를 소개
- adversarial training과 score distillation의 조합을 사용하고, 몇몇의 design choice 제거
- ADD를 통해 기존의 생성 알고리즘(e.g. LCM, LCM-XL, 1-step GAN)을 능가하는 성능을 보이고, 1-step만으로 high image realism 달성
- 4-step으로 의 해상도에서 teacher model인 SDXL-Base 모델의 성능을 능가
Background
최근 diffusion model에서는 sampling step을 줄이기 위한 전략으로 빠른 sampler를 활용하는 것 이외에도 progressive distillation이나 guidance distillation에 대한 연구가 진행되고 있다.
이러한 접근 방식의 경우 iterative sampling step을 줄일 수 있지만, 여전히 sampling step을 필요로 하고 성능이 낮아지는 한계점이 존재한다.
한편, Consistency Model은 ODE 궤적에 consistency regularization을 적용하여 위의 문제를 해결하고, few-shot setting에서 pixel-based model에 대해 높은 성능을 보였다.
이와 관련하여 latent space에서 distillation을 성공적으로 도입한 LCM, LCM-LoRA이 제안되었고, Instaflow는 Rectified Flow를 통해 더 나은 distillation process를 제시했다.
이러한 방법들은 여전히 공통적으로 low-sampling으로 인해 흐릿하거나 부자연스러운 artifact가 생성되는 문제가 존재한다.
한편, Score Jacobian Chaining이라 불리는 Score Distillation Sampling(SDS)는 T2I Model의 knowledge를 3D synthesis model에 distillation하기 위해 제안된 방법으로, text-to-3d-video-synthesis나 image context editing Task에 활용되고 있다.
최근 저자들은 score-based model과 GAN 사이의 높은 연관성을 보여주었고, discriminator 대신 diffusion model의 score-based flow를 사용하여 학습된 score GAN을 제안하였다.
이와 반대로 adversarial training을 사용하여 diffusion process를 개선하는 것을 목표로 접근한 방법들도 있다. faster sampling을 위한 몇 가지 step의 sampling을 가능하도록 Denoising Diffusion GANs이 도입되었다. 여기서, 생성 품질을 향상시키기 위해 Adversarial Score Matching의 score matching objective와 CTM의 consistency objective loss가 추가된다.
논문에서 제안하는 방식은 현재 low sampling으로 최적의 성능을 보이는 모델들의 문제를 해결하기 위해 hybrid 목표에서 adversarial training과 score distillation을 결합했다.
Method
본 논문의 목표는 가능한 적은 sampling step으로 sota 모델의 이미지 생성 품질과 일치시키는 것이다.
한편, GAN을 사용하게 되면 large-scale dataset에 대해서 성능이 떨어지기 때문에 pretrained diffusion model을 기반으로 score-based distillation을 통해 sample quality를 향상시켰으며, pretrained diffusion model로 초기 가중치를 초기화시킨 상태로 학습을 진행했고 GAN 학습에 사용되는 decoder framework 대신 diffusion model framework를 도입하여 자연스럽게 iterative refinement가 가능하도록 설계했다.
Training Procedure

제안하는 training procedure는 Fig 2.와 같고, 연관된 3가지 network는 다음과 같다.
- ADD-Student()
- Discriminator()
- DM-Teacher()
학습 과정동안 forward diffusion process 을 통해 real image 를 noised data로 변환하고, ADD-Student는 noisy data 로부터 sample 를 생성한다. 여기서, 와 는 동일한 coefficinet를 사용했으며, sample 는 에서 N개를 균일하게 선택했다. 논문에서는 , 으로 할당했으며, 추론시에 모델은 순수한 노이즈로부터 샘플링해야 하므로 학습시에는 zero-terminal SNR을 강제로 적용했다.
adversarial objective를 위해 생성된 샘플 와 real image 를 discriminator로 전달한다. 그리고 DM Teacher의 knowledge를 distillation하기 위해 student sample 를 teacher forward process로 전달하여 를 생성하고, teacher의 denoising prediction을 통해 reconstruction target인 을 생성한다.
이 과정에 대한 전체적인 loss 수식은 다음과 같다.
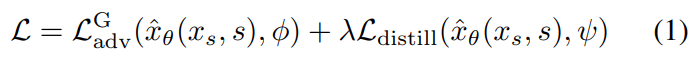
추가적으로 논문에서는 pixel space에서 distillation loss를 계산하는 것이 latent diffusion model에 대해서 distillation할 때 gradient 측면에서 더 안정적이므로 pixel space에서 계산했다.
Adversarial Loss
discriminator의 경우는 StyleGan-t에서 제안된 설계 및 학습 절차를 따른다.
그리고 모델 파트를 pretrained frozen feature network 와 trainable lightweight discriminator head 로 분류했다. 는 ViT를 사용했으며, 는 서로 다른 feature network layer 에 적용했다.
논문에서는 성능 향상을 위해 discriminator로부터 projection을 통해 추가 정보를 conditioning했다. 구체적으로 주어진 생성 샘플 에 대해서 로부터 얻은 정보로부터 discriminator를 conditioning할 수 있다. 이를 위해, image embedding을 생성하기 위한 additional feature network를 사용한다.
ADD-Student의 adversarial objective Loss Function 와 discriminator Loss Function은 각각 다음과 같다.

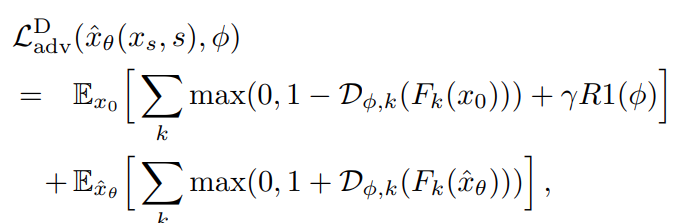
여기서, 은 gradient penalty를 의미한다. 픽셀 값에 대한 gradient penalty를 계산하는 대신 각 Discriminator head 의 입력으로 계산하는 것이 의 해상도에서 특히 유용하다는 것을 파악.
Score Distillation Loss
distillation Loss Function은 다음과 같다.

여기서, sg는 stop-gradient operation을 의미한다. 직관적으로 loss는 ADD-Student에 의해 생성된 sample 와 DM Teacher의 output인 간의 miss match를 측정하기 위한 distance metric 를 사용한다.
논문에서는 가중치 함수 와 관련하여 다음 두 가지 옵션을 고려했다.
- exponential weighting (여기서, 이고 higher noise level이 더 적게 기여)
- score distillatioin sampling(SDS) weighting
Expoeriments
실험을 위해 논문에서는 ADD-M(860M parameter), ADD-XL (3.1B parameter)을 학습했다. ADD-M의 경우, Ablation Study를 위해 SD 2.1 backbone을 사용하고 다른 baseline과 비교할 떄는 SD 1.5 모델을 사용했다. 그리고 ADD-XL은 SDXL backbone을 사용했다. 모든 실험은 해상도에서 진행했다.
이외의 파라미터 설정은 다음과 같다.
- distillation weighting factor
- penalty strength
- discriminator conditioning model : pretrained CLIP-VIT-g-14(text embedding), DINOv2-VIT-l's CLS embedding(image embedding)
- baseline models : LDM(SD1.5, SDXL), cascaded pixel diffusion model(IF-XL), distilled diffusion model(LCM-1.5, LCM-1.5-XL), OpenMUSE etc.
Ablation Study

Quantitative Comparison to State-of-the-Art

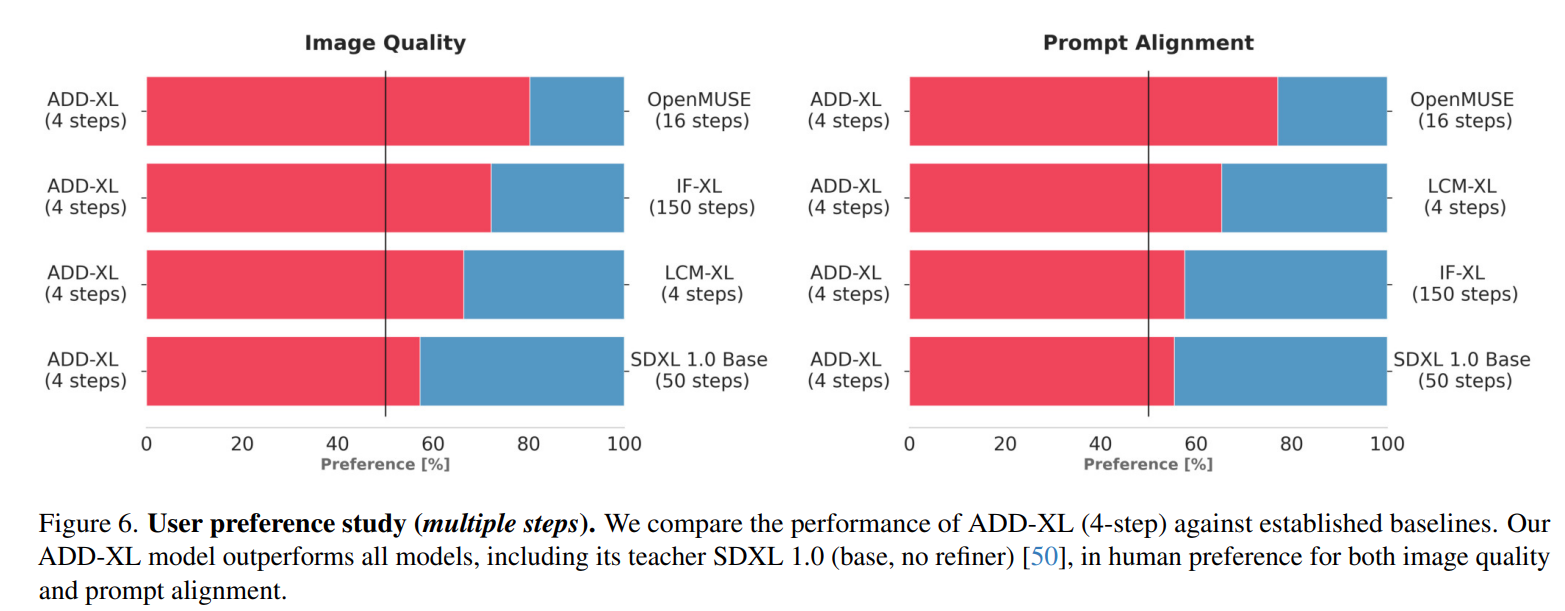
Qualitative Results



Discussion
본 연구에서는 pretrained diffusion model을 fast and low sampling step의 image generation model로 distillation하기 위한 Adversarial Diffusion Distribution 방법을 제시했다. 제안하는 방법으로 생성된 모델을 통해 low sampling step(1-4)으로 고품질 이미지를 생성할 수 있으며, 기존 SOTA 모델보다 능가하는 성능을 보였다. 또한, real-time image generation의 가능성을 보여줬다.
