DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
Computer Vision
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
Abstract
논문에서는 text-to-image diffusion model의 "Personalization"을 위한 새로운 접근법을 제시한다.
이 방법은 subject에 대한 몇 개의 이미지를 입력으로 주면 pretrained text-to-image model에 대해서 finetuning을 진행하여 특정 subject와 고유 식별자를 묶는 방법을 학습한다.
이를 통해 subject의 key feature를 보존하면서 subject의 recontextualization, text-guided view synthesis, artistic rendering 등 기존에 해결할 수 없었던 Task를 해결한다.
Introduction
최근 개발된 text-to-image 모델은 text prompt 기반으로 고품질의 다양한 이미지 합성을 가능하게 했지만, 주어진 reference 집합에서 subject의 모습을 모방하여 다른 context로 동일한 subject를 새롭게 연출하는 능력이 부족한 상황이다.
이에 대한 주요 이유는 output domain이 한정적이기 때문이고, instance에 대한 자세한 텍스트 설명이 있는 경우나 text embedding이 shared language-vision space에 존재하는 경우에도 부정확한 결과를 얻을 수 있게 된다.
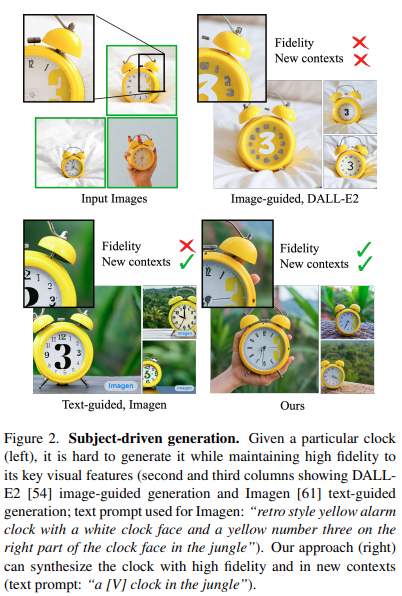 Subject-driven generation 예시
Subject-driven generation 예시
논문에서는 사용자가 생성하고자 하는 특정 subject와 새로운 단어를 결합하도록 모델의 language-vision dictionary를 확장함으로써 text-image diffusion model의 "Personalization"을 지원하는 것을 목표로 한다.
 DreamBooth 예시
DreamBooth 예시
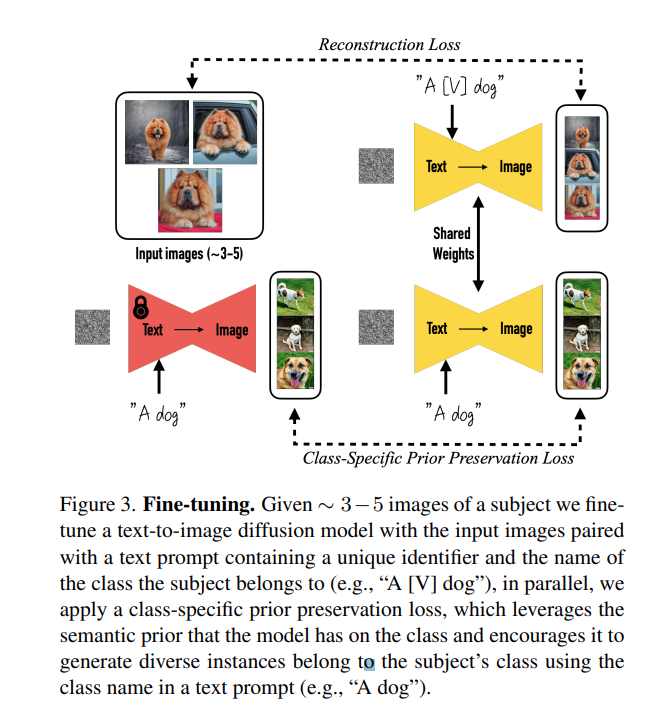
DreamBooth는 몇 개의 subject(e.g. 3~5) 이미지가 주어질 때 subject를 모델의 output domain에 입력하여 고유 식별자와 합성할 수 있도록 유도한다. 이를 위해 논문에서는 희귀한 토큰 식별자로 주어진 subject를 표현하고, pretrained diffusion model based text-to-image framework를 fintuning하는 기술을 제안한다.
text-to-image 모델을 finetuning시에는 input image, text prompt, unique identifier(e.g. A [V] dog) 형태를 같이 입력한다. 여기서 unique identifier를 쓰는 이유는 모델이 subject class에 대한 prior knowledge를 사용할 수 있도록 하기 때문이다. 또한 모델이 클래스 이름(e.g. "dog")을 특정 instance와 연관시키는 language drift를 방지하기 위해 모델에 포함된 클래스에 대한 semantic prior를 활용하고, subject와 동일한 클래스의 다양한 instance를 생성하도록 유도하는 class-specific prior preservation loss를 제안한다.
Related Work
Image Composition
Image Composition은 주어진 subject를 새로운 배경으로 복제하여 subject가 scene에 자연스럽게 배치되는것을 목표로 한다.
일반적으로 새로운 포즈로의 구성을 고려하기 위해 일반적으로 경직된 object에 적용되고, 많은 뷰가 필요한 3d reconstruction 기술을 적용한다. 일부 단점은 scene integration(e.g. lighting, shadows, contact)와 새로운 scene를 생성할 수 없다는 것인데, 논문에서는 새로운 pose와 context에서 subject를 생성할 수 있도록 한다.
Text-to-Image Editing and Synthesis
Text-driven image manipulation은 최근 ClIP과 같은 image-text representation과 결합된 GAN을 사용하여 많은 발전을 이뤘다. 하지만, 구조화된 시나리오(e.g. human face editing)에 대해서만 잘 동작하고 다양한 데이터 셋에서 어려움을 겪는다.
최근 Diffusion Model을 활용하여 다양한 데이터 셋에 대해 생성 품질을 향상시켰다. 하지만, 대부분 전역 속성을 수정하거나 주어진 이미지를 로컬로 편집하는 것에 국한되고 새로운 context에서 주어진 subject를 새롭게 연출하지 못했다.
한편 text-to-image synthesis 연구도 진행되고 있는데, 최근에는 Imagen, DALL-E2, Parti, CogView2, Stable Diffusion과 같이 large text-to-image model들이 높은 퍼포먼스를 보여주었다. 이러한 모델들은 생성된 이미지에 대한 세밀한 제어를 제공하지 않고 오직 텍스트 기반 guidance를 제공한다. 특히, 합성된 이미지에 걸쳐 subject 일관성을 유지하는 것이 어렵다.
Controllable Generative Models
generative model을 제어하기 위한 다양한 연구들이 있는데, 그 중에는 subject-driven prompt-guided image synthesis가 있다.
subject modification을 극복하기 위한 방법으로 기존에는 수정된 영역을 제한하기 위해 user-provided mask를 가정하거나, inversion을 활용했다. 이외에도 prompt-to-prompt를 통해 input mask없이 로컬 및 전역 편집을 하려는 방식이 있지만, 이러한 방법은 새로 생성된 subject를 보존하지 못하는 문제가 있다.
GAN의 맥락에서 Pivotal Tuning은 inverted latent code anchor로 모델을 fintuning하여 실제 이미지 편집이 가능하게 했으며, Nitzan et al.은 이 작업을 약 100개의 이미지와 face domain으로 제한하여 personalized prior을 학습했다. 그리고 Casanova et al.은 모든 subject의 세부 정보를 보존하지 못하지만, instance의 변형을 생성할 수 있는 instance conditioned GAN을 제안했다.
마지막으로 Gal et al.은 frozen text-to-image model의 embedding space에서 새로운 token을 통해 object 또는 style과 같은 시각적 개념을 표현하여 작은 personalized token embedding을 생성하는 방법을 제안한다. 이 방법의 경우 frozen diffusion model의 표현성에 의해 제한되지만, 제안하는 fintuning 방법은 모델의 output domain 내에 subject를 embedding할 수 있어 주요 시각적 특징을 보존하는 subject의 새로운 이미지를 생성할 수 있다.
Method
본 논문의 목표는 특정 subject를 포함한 몇 장의 이미지(e.g. 3~5)를 통해 text prompt에 의해 제공되는 변형과 높은 fidelity를 가지는 subject를 포함한 새로운 이미지를 생성하는 것이다.
3.1 Text-to-Image Diffusion Models
Diffusion 모델은 가변적으로 노이즈가 발생하는 이미지 또는 latent code 에 대해서 노이즈 제거를 위해 다음과 같이 squared error loss를 사용하여 학습한다.
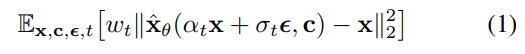
여기서 각 파라미터의 의미는 다음과 같다.
- pretrained text-to-image diffusion model
- 초기 noise map ~
- conditioning vector ( = text encoder, =text prompt)
- generated image
- : noise schedule
- : sample quality
- : diffusion process의 function
3.2. Personalization of Text-to-Image Models
먼저, 논문에서는 subject의 새로운 여러 이미지에 대해서 model에서 query할 수 있도록 subject instance를 model의 output domain에 삽입했다.
논문 저자는 fine tuning 실험과 관련하여 large text-to-image diffusion 모델의 경우 이전의 정보를 잊거나(forgetting), small train dataset에 대해서 과적합하지 않고 새로운 정보를 domain에 통합한다는 사실을 발견했다.
Designing Prompts for Few-Shot Personalization
논문에서는 finetuning을 위해 diffusion model의 dictionary에 (unique identifier, subject)쌍을 implant하는 방법을 제시했다.
이를 위해 모든 입력 이미지에 대해서 [identifier] [class noun] 형태로 레이블을 지정했는데, 여기서 [identifier]는 subject와 연결된 unique identifier, [class noun]은 피사체(e.g. 고양이, 개, 시계 등)의 대략적인 class descriptor를 의미한다.
여기서 class descriptor는 사용자에 의해 제공되거나, 분류기를 사용하여 얻을 수 있다.
Rare-token Identifiers
논문에서는 unique identifier(e.g. xxy5syt00)를 생성하기 위해 무작위 문자를 선택하고 연결하는 방식을 사용했다.
이를 위해, 먼저 vocabulary로부터 rare-token lookup을 수행하고, rare token identifier 의 sequence를 얻는다. 여기서, 는 tokenizer, 는 에서 파생된 decode된 text를 의미한다. sequence는 가변 길이 를 가지며, 상대적으로 짧은 의 시퀀스에서 동작이 잘되는 것을 확인했다. 그리고나서 로부터 detokenizer를 사용해서 vocabulary로 변환한다.
Class-specific Prior Preservation Loss
모델의 전체 구조에 대해서 fine tuning을 진행했을 때 다음과 같은 두 가지 이슈가 발생했다고 주장한다.
- 언어 드리프트 유사 현상 : large diffusion model에서 fine tuning을 진행했을 때, 모델이 target subject와 동일한 클래스의 subject를 생성하는 법을 잊는 현상 발생
- output diversity 감소
언어 드리프트 현상이란?
large text corpus에서 pretrain 된 상태에서 fine tuning을 진행했을 때 모델이 language에 대한 syntactic과 semantic knowledge를 잃어버리는 현상
이 문제를 해결하기 위해 class-specific prior preservation loss를 제안한다. 본질적으로 제안하는 방법은 few-shot fine tuning을 수행할 때 이전 prior를 보존할 수 있도록 자체 생성된 샘플로 모델을 supervised learning을 진행하는 것이다.
generated data 는 random initial noise ~ 와 conditioning vector 를 포함한 frozen pretrained diffusion model에 대해서 ancestral sampler를 사용하여 얻을 수 있다. 이를 통해 얻은 loss 수식은 다음과 같다.
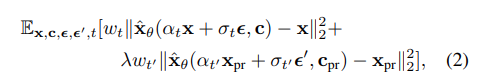
여기서, 두 번째 항은 자체 생성된 이미지로 모델을 supervise하는 prior-preservation 항이며, 는 이 항의 상대적인 weight를 조절하는 역할을 한다.
Fig 3에서 class-generated sample과 prior preservation loss를 사용한 fine tuning을 보여준다. 단순함에도 불구하고 prior preservation loss는 output diversity와 language drift를 극복하는데 효과적이라는 것을 발견했으며, overfitting의 위험없이 더 많은 iteration에 대해서 모델을 학습할 수 있었다.
Experiments
 Dataset Example
Dataset Example
 Textual Inversion과의 정성 비교 평가 결과
Textual Inversion과의 정성 비교 평가 결과
 Fidelity Performance 정량 평가 및 user 평가
Fidelity Performance 정량 평가 및 user 평가
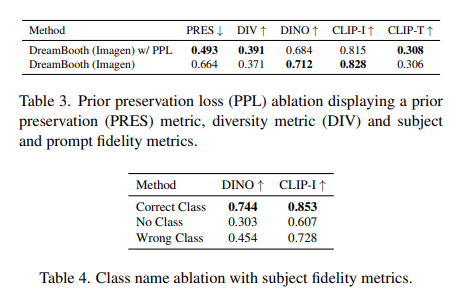 Ablation Study - Prior Preservation Loss & Class Name
Ablation Study - Prior Preservation Loss & Class Name
 Ablation Study - prior preservation loss
Ablation Study - prior preservation loss
 Recontexualization
Recontexualization
 Fine Tuning with Ohter Tasks
Fine Tuning with Ohter Tasks
Limitations
Limitations는 다음과 같다.
- context에 대한 weak prior 또는 train dataset에서 subject와 specified concept이 동시에 발생할 가능성이 적은 이유로 인해 prompted context를 정확하게 생성할 수 없다.
- context-appearance entanglement : prompted context로 인한 subject의 외형 변형 발생
- prompt가 subject가 원래 보였던 original setting과 유사할 때 발생하는 overfitting 현상
 Limitations
Limitations
Conclusion
논문에서는 몇 개의 subject 이미지와 prompt의 guidance를 사용하여 subject의 새로운 구성에 대한 합성의 접근법을 제시했다.
핵심 아이디어는 subject를 unique identifier에 binding하여 text-to-image diffusion model의 출력 영역에 주어진 subject instance를 내장하도록 하는것이다. 특히 제안하는 방법은 3-5개의 subject 이미지만으로 fine tuning을 할 수 있는 장점을 가지고, 생성된 이미지 대부분의 경우 실제 이미지와 구별할 수 없을 정도로 높은 fidelity를 가질 수 있다.
