Adding Conditional Control to Text-to-Image Diffusion Models
Abstract
ControlNet은 추가적인 input condition을 지원하여 large diffusion model를 제어하기 위한 모델이다. ControlNet은 end-to-end 방식으로 학습하며, 학습 데이터 세트가 적은(<50k) 경우에도 좋은 성능을 보이고 학습 속도 또한 diffusion model의 fine tuning만큼 빠른 장점을 가진다.
Introduction
저자는 기존 large text-to-image 모델의 prompt에 대한 의존성과 특정 task에서 활용함에 있어서 발생할 수 있는 현실적인 문제를 언급했다. 이와 관련해서 세 가지 측면에서 검토하고 제안했다.
-
task-specific domain의 경우 일반적인 text-to-image 데이터 스케일만큼 크지 않으므로 large model을 특정 문제에 대해 학습시킬 때는 과적합을 방지하고 일반화 능력을 보존할 수 있는 방법이 필요하다.
-
large model를 항상 large computation cluster에서 사용할 수 없기 때문에 제한된 시간 및 메모리 공간내에서 사용가능한 학습 전략이 필요하다. 이를 위해 fine-tuning이나 trasfer learning 뿐만 아니라 pretrained weight의 활용이 필요하다.
-
다양한 image processing은 denoising process 제한, multi-head attention activation 편집등과 같은 hand crafted 룰을 따른다. 이러한 문제는 필수적으로 raw data에 대한 object-level이나 scene-level에서 이해가 필요하므로 실현 가능성이 떨어지게 되어 end-to-end 학습이 필요하다.
이에 따라 이 논문에서는 대규모 image diffusion model(e.g. Stable Diffusion)을 제어하여 task-specific 입력 조건을 학습하는 end-to-end 구조의 ControlNet을 제안한다.
ControlNet은 대규모 diffusion model로부터 trainable copy와 locked copy를 복제한다. 여기서, locked copy은 대용량 이미지 데이터 셋에서 학습된 weight를 보존하고, trainable copy는 task-specific dataset에서 conditional control를 학습한다.
trainable과 locked network는 convolution weight가 0에서부터 학습되면서 점진적으로 증가하는 zero convolution이라 불리는 layer와 연결된다. zero convolution은 deep feature에 새로운 노이즈를 추가하지 않으므로 처음부터 훈련시키는 것에 비해 diffusion model을 fine tuning하는 것 만큼 빠르다.
본 논문에서는 canny-edge, hough line, keypoint, depth map등과 같은 서로 다른 condition으로부터 ControlNet 실험을 진행했다. 그리고 다양한 크기의 데이터 셋(50K 혹은 1K 미만과 같은 작은 데이터 셋, milions의 큰 데이터 셋)에 대해서 실험을 진행했다.
Related Work
HyperNetwork and Neural Network Structure
HyperNetwork는 작은 recurrent neural network가 더 큰 network의 weight에 영향을 미치도록 훈련시키기 위한 신경망 처리 방법에서 유래했다. HyperNetwork는 GAN이나 다른 machine learning task에서 좋은 성능을 보였으며, ControlNet은 HyperNetwork과 신경망 동작에 영향을 미치는 방식에서 유사성을 보인다.
Weight Initialization와 관련해서 Gaussian Distribution으로 초기화하거나 0으로 초기화하는 방법 및 이로 인해 발생할 수 있는 위험들에 대한 많은 논의가 이뤄졌다. 그리고 최근에는 zero convolution 개념과 유사하게 훈련을 개선시키기 위해 diffusion model의 몇몇 convolution layer의 initial weight를 스케일링하는 방법에 대한 논의가 이뤄졌고 이와 더불어서 ProGAN, StyleGAN, Noise2Noise 등에서도 언급된다.
Diffusion Probabilistic Model
Diffusion Probabilistic Model은 Diffusion 논문에서 제안되었으며, DDPM과 DDIM 등의 샘플링 방법 및 score-based diffusion 등의 방법을 통해 개선되었다. image diffusion은 본질적으로 U-Net 신경망을 사용하고 계산량을 줄이기 위해 Latent Diffusion Model이 제안되었고 이는 Stable Diffusion으로 추가 확장되었다.
Text-to-Image Diffusion
Diffusion 모델들은 CLIP과 같은 Pre-trained Language Model을 사용하여 Text Input을 Latent Space로 Encoding하여 Text-to-Image를 수행할 수 있다.
이와 관련한 방법론들은 다음과 같다.
- Glide : image generation & edit을 지원하는 text-guided diffusion model
- Disco Diffusion : text prompt를 처리하기위해 clip-guided 구현
- Stable Diffusion : latent diffusion을 통해 text-to-image 지원
- Imagen : latent image를 사용하지 않고 피라미드 구조를 사용하여 픽셀을 직접 diffusion하는 text-to-image model
Personalization, Customization and Control of Pretrained Diffusion Model
최근 image diffusion model은 기본적으로 text guided 방식을 통해 이미지를 제어하는데, CLIP Feature를 조작을 통해 가능하다. image diffusion process는 자체적으로 color-level detail variation을 얻기 위한 기능들을 제공한다.
image diffusion 알고리즘은 inpainting도 지원한다. 그리고 textual inversion과 dreambooth는 동일한 subject나 subject가 갖는 작은 image dataset를 사용하여 Personalization을 제공한다.
Image-to-Image Translation
image-to-image translation은 다른 도메인의 이미지 간 매핑을 학습하는 것을 목표로 한다면, ControlNet은 task-specific condition을 통해 diffusion model을 control하는 것을 목표로 한다는 점에서 차이가 있다.
본 논문에서는 image-to-image translation에서 가장 강력한 method에 대해 논의했으며, 관련 연구는 다음과 같다.
- Taming Transformer : 이미지를 생성하고 image-to-image translation을 수행하는 vision transformer 모델
- Palette : unfied diffusion based image-to-image translation framework
- PITI : large scale pretrain을 활용한 diffusion based image-to-image method
- sketch-guided diffusion : diffusion process를 조작하는 optimization 기반 방법
Method
ControlNet
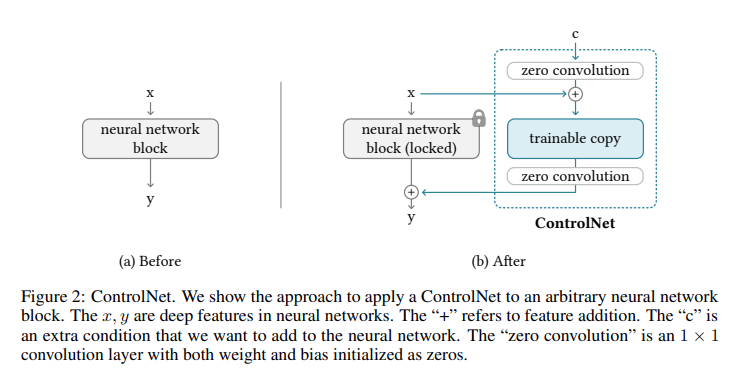
ControlNet의 동작 과정은 Figure 2와 같다.
먼저, 전체 파라미터에 대해서 lock한 뒤에 trainable copy에 복제한다. 그리고 복제된 는 input condition vector 와 함께 학습된다. 이와 같이 original weight를 직접 훈련하는 것보다 복사함으로써 과적합을 방지하고 대규모 데이터 셋으로부터 학습된 대용량 모델의 품질을 유지하도록 유도할 수 있다.
그리고 neural block은 가중치와 바이어스가 0으로 초기화된 1x1 convolution layer인 "zero convolution layer"와 연결되어 최종 출력인 를 얻게 된다.
결론적으로 일부 neural block에 ControlNet을 적용했을 때, 대용량 모델의 품질을 유지하면서도 optimization 과정은 fine tuning 만큼 빠르게 동작할 수 있게 된다.

1x1 convolution layer에서 weight=, bias=, spatial position=, channel-wise index=, input map=라고 가정하면 forward pass는 위와 같다.
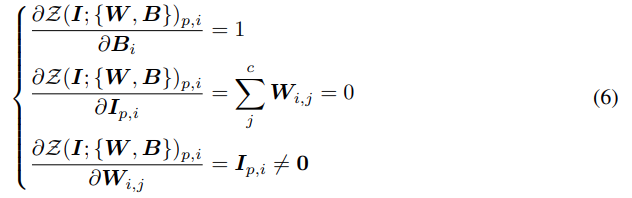
그리고 위의 Gradient 수식을 통해 zero convolution은 feature term 의 Gradient를 0으로 만들면서도 와 의 Gradient는 영향을 받지 않음을 알 수 있다. 또한 feature term 는 첫 번째 Gradient Descent에서 0이 아닌 값으로 최적화되고 특히, ControlNet에서는 dataset에서 sampling된 condition vector를 사용하므로 0이 아닌 를 보장할 수 있다.
ControlNet in Image Diffusion Model
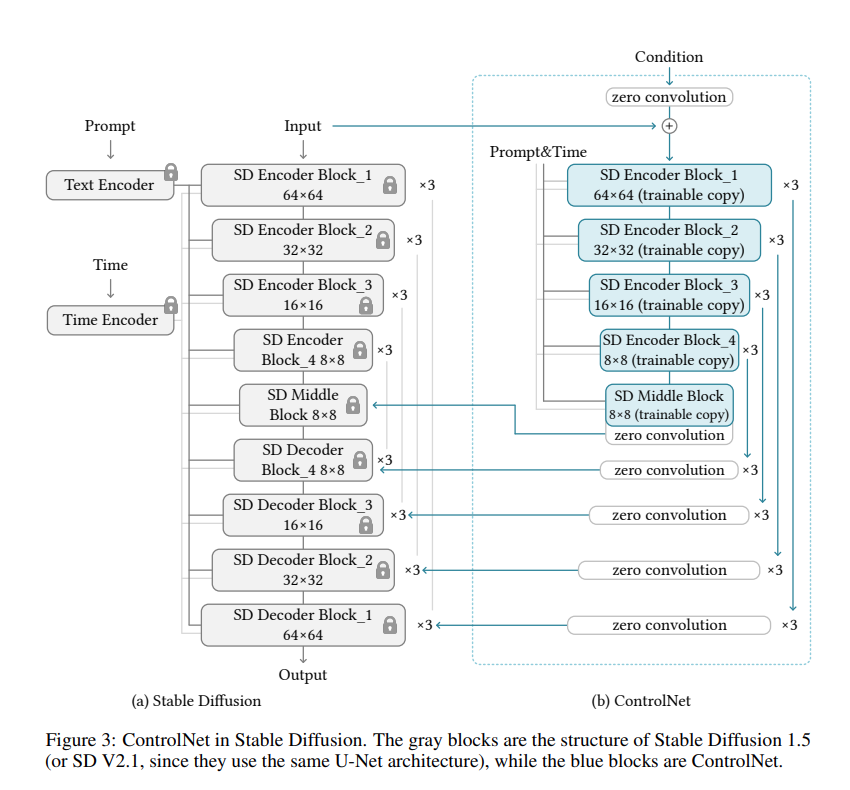
본 논문에서는 ControlNet을 사용하기 위해 Stable Diffusion 모델을 베이스로 사용했다.
Stable Diffusion 모델은 Text Encoder(OpenAI CLIP), Time Encoder 그리고 UNet 구조의 Encoder, middle block, skip connected Decoder로 구성되어 있다. 그리고 내부적으로는 unsampling / downsampling convolution layer와 ViT를 포함하고 있다.
또한 Stable Diffusion Model은 VQ-GAN과 유사한 pre-processing method를 통해 512x512 이미지의 데이터 세트를 64x64의 latent space로 변환한다. ControlNet에서는 512x512 이미지를 64x64의 latent image로 변환하기 위해 convolution layer로 구성된 tiny network를 구성했다.
Figure 3과 같이 ControlNet을 적용했을 때, Encoder의 Gradient 계산이 필요하지 않으므로 Full Training보다 절반의 계산량을 가질 수 있으므로 학습 속도 및 GPU 메모리 절약 효과를 얻을 수 있다. 추가적으로 Stable Diffusion은 전형적인 UNet 아키텍처를 따르므로 다른 Diffusion 모델에서도 ControlNet을 활용할 수 있다.
Training
일반적으로 학습 과정은 기존 Stable Diffusion과 매우 유사하다. 이것과 관련해서는 이전에 포스팅한 Stable Diffusion 논문 리뷰를 참고하면 좋을 것 같다.
ControlNet 학습시에 특이한 점은 전체 Text Prompt중에서 50%를 Empty String으로 대체하는 것인데, 이는 input condition maps(e.g. Canny edge map, human scribbles)으로부터 semantic content를 인식하는 ControlNet의 기능을 용이하게 한다.
이게 가능한 이유는 SD 모델은 주로 prompt가 없을 때, Encoder에서 prompt를 대체하기 위해 input control map에서 더 많은 semantic을 학습하기 때문이다.
Improved Training
논문에서는 몇 가지 제한적인 환경에서 ControlNet의 학습을 개선시키기 위한 전략에 대해서 소개한다.
Small-Scale Training
저자는 computation device가 제한적일 때 ControlNet과 Stable Diffusion 사이의 연결을 부분적으로 끊는 것이 수렴 가속화를 얻을 수 있음을 발견했고, 특히 Figure 3에서 SD Decoder Block 1,2,3,4에 대한 링크를 끊고 Middle Block만을 연결함으로써 약 1.6배 학습 속도를 얻을 수 있음을 언급했다.
Large-Scale Training
여기서 Large-Scale Training은 강력한 computation device(e.g. 적어도 8개의 A100 80G이상)과 large dataset(e.g. 1 million이상의 학습 이미지)를 사용할 수 있는 상황을 의미한다.
이 경우에는 과적합의 위험이 적으므로 많은 수의 iteration(e.g. 50k 이상)로 ControlNet을 학습 시킨 뒤, Stable Diffusion의 모든 weight를 unfreeze하여 전체 모델 구조를 공동으로 훈련시키는 것을 제안한다.
Implementation
논문에서는 large diffusion model을 다양한 방식으로 제어하기 위해 이미지 기반 조건이 다른 ControlNet의 여러 구현을 제시했다. 종류는 대표적으로 다음과 같다.
Canny Edge, Hough Line, Hed Boundary, User Sketching, Human Pose, Semantic Segmentation, Depth, Normal Maps, Cartoon Line Drawing
Experiment
Experimental Settings
공통적으로 CFG-scale은 9.0으로 통일했으며, Sampler는 20step의 DDIM을 적용했다. 그리고 model을 test하기위해 세 가지의 prompt 타입을 사용했다.
- No prompt : empty string ""
- Default Prompt : Default Prompt로 "an image", "a nice image", "a professional image"를 추천하며, 본 논문에서는 "a professional, detailed, high-quality image"를 사용
- Automatic prompt : BLIP과 같은 이미지 캡션을 통해 prompt를 생성하고 해당 prmopt를 통해 diffusion 적용
- User prompt
Qualitative Results
 Canny Example
Canny Example
3.5 절에서 언급된 ControlNet Input Condition에 따른 결과는 논문에 제시되어 있다.
Ablation Study
 Ablation Study Result : ControlNet
Ablation Study Result : ControlNet
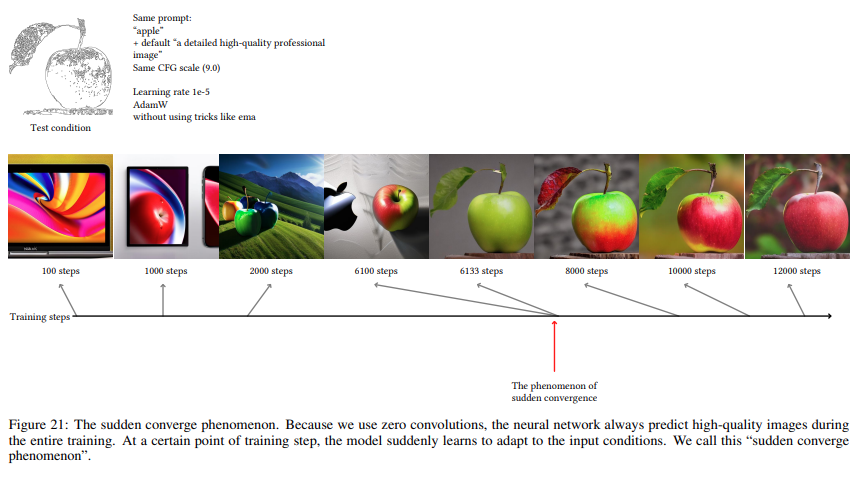 Ablation Study Result : Sudden Convergence Phenomenon
Ablation Study Result : Sudden Convergence Phenomenon
 Ablation Study Result : Dataset Size
Ablation Study Result : Dataset Size
Comparison of pre-trained models
 pre-trained model comparision : Canny vs Hed vs M-LSD Line
pre-trained model comparision : Canny vs Hed vs M-LSD Line
 pre-trained model comparision : Canny vs Hed vs M-LSD Line
pre-trained model comparision : Canny vs Hed vs M-LSD Line
 pre-trained model comparision : Canny vs Hed vs M-LSD Line
pre-trained model comparision : Canny vs Hed vs M-LSD Line
More Aplications
 Simple Object & Diffusion Iteration Effect
Simple Object & Diffusion Iteration Effect
Limitation
 Semantic information in the input image is incorrectly recognized
Semantic information in the input image is incorrectly recognized
