High-Resolution Image Synthesis with Latent Diffusion Models
Abstract
Diffusion Model(DM)은 이미지 생성 분야에서 재학습의 필요 없이 훌륭한 성능을 보이고 있다. 하지만, DM은 일반적으로 픽셀 레벨에서 동작되기 때문에 많은 리소스가 필요한 문제가 있다.
본 논문에서는 pretrained auto encoder의 latent space에 DM을 적용하는 방법을 통해 이러한 제한 사항을 해결하는 방법을 제시한다. (Latent Space 학습 장점 : 복잡성 감소, 디테일 보존)
또한 제안하는 모델은 cross-attention layer를 추가함으로써 사용자의 입력(prompt)으로부터 유연해지고, 컨볼루션한 방법으로 고해상도 합성이 가능하다.
결론적으로 Latent Diffusion Model(LDM)은 pixel based DM 모델보다 계산 요구 사항도 많이 줄고, 다양한 생성 테스크(inpainting, class-conditional image synthesis, text-to-image, unconditional image generation, super-resolution)에서 경쟁력 있는 퍼포먼스를 보인다.
Introduction
최근 DM모델은 class conditional image synthesis와 super resoltuion 분야에서 sota를 기록하고 있고, 또한 unconditional DM는 다른 생성 모델과는 달리 image inpainting 및 colorization, stroke-based synthesis와 같은 task에 쉽게 적용할 수 있다.
likelihood 기반 모델이기 때문에 GAN과는 달리 학습에 불안정을 보이지 않고 파라미터 공유를 최대한 활용하기 때문에 AR처럼 수십억의 파라미터를 사용하지 않고도 복잡한 자연 이미지를 모델링할 수 있다.
Democratizing High-Resolution Image Synthesis
DM은 리소스 문제가 존재하는데, 초기 denoising 단계에서 이를 해결하는 것을 목표로 하지만 Pixel Level에서 모델을 학습하고 평가하는 과정이 수행되기 때문에 여전히 계산적으로 제한을 받는 상황이다.
논문 저자는 DM의 성능을 손상시키지 않으면서 많은 리소스 소비를 줄이기 위해서는 훈련과 샘플링에 대한 계산 복잡성을 줄이기 위한 방법이 필요함을 언급했다.
Departure to Latent Space
본 논문의 연구는 픽셀 공간에서 pretrained diffusion model에 대한 연구로 시작되며, 이와 관련해서 Fig 2에서 pretrained model의 rate-distortion trade-off를 보여준다.
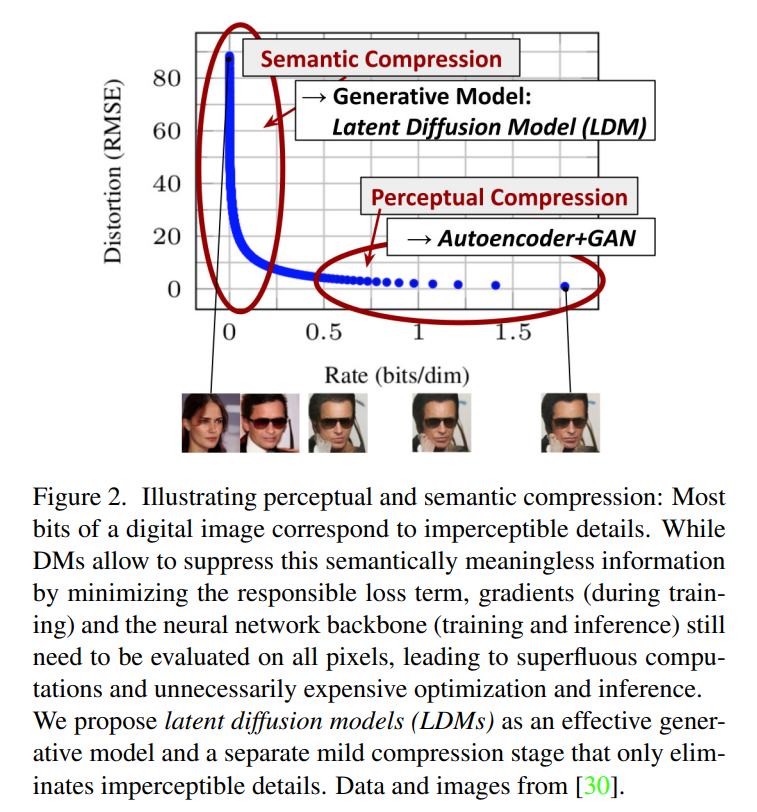
학습 과정은 크게 두 단계로 나눌 수 있다.
- high-frequency detail를 없애지만, 약간의 semantic variation을 학습하는 perceptual compression stage
- 실제 generative model이 데이터의 semantic과 conceptual composition를 학습하는 semantic compression stage
따라서 본 논문은 고해상도 이미지 합성을 위해 perceptuality가 동등하지만, 계산적으로 더 안정적인 space를 찾는 것을 목표로 한다. 이를 위해 논문에서는 학습을 위해 독립된 두 가지 단계 과정을 거친다.
- 데이터 공간과 perceptualy 동등한 낮은 차원 representational space을 제공하는 auto encoder를 학습
- complexity가 감소되어 single network pass만으로 latent space에서 효율적인 이미지 생성을 제공
이러한 모델을 Latent Diffusion Model이라 칭한다.
이 접근 방식의 이점은 범용적인 auto encoding 단계를 한번만 훈련하면 되어서 여러 DM 학습시에 재사용하거나 완전히 다른 task에 적용할 수 있다. 이를 통해 다양한 image-to-image, text-to-image 작업에 대한 많은 DM을 효율적으로 탐색할 수 있다.
본 논문에 기여는 다음과 같다.
-
제안하는 방법은 고차원 데이터에 훌륭하게 확장가능하여 다음을 가능하게 한다.
(a) 이전의 연구들보다 더 충실하고 섬세한 reconstruction을 제공하는 compression level
(b) megapixel 이미지의 high-resolution synthesis에 효율적으로 적용 -
계산 비용을 낮추면서 여러 Task 및 데이터 셋에서 경쟁력이 있는 성능을 달성했고, Pixel Level Based DM에 비해 추론 비용 또한 크게 절감
-
Encoder-Decoder와 Score based Architecture를 동시에 학습하는 제안하는 방식은 충실한 재구성을 보장하고 latent space의 정규화가 거의 필요없다.
-
Super Resoltuion, Inpainting, Semantic Synthesis과 같이 섬세한 조건의 작업에 대해 Stable Diffusion 모델은 컨볼루션 방식을 적용할 수 있으며 pixel의 이미지에 일관되게 랜더링할 수 있다.
-
Cross Attention 기반으로 general purpose conditioning 매커니즘을 설계하여 multi modal 학습이 가능하게 한다.

Related Work
Generative Models for Image Synthesis
Generative Adversarial Network(GAN)은 고해상도 이미지를 효율적으로 샘플링할 수 있지만, 전체 데이터 분포를 캡처하지 못하는 한계가 있다.
이와 반대로 likelihood based method는 최적화를 잘 수행한다. 특히 Variantional Auto Encoder(VAE)와 Flow based Model은 고해상도 이미지의 효율적인 합성이 가능하지만, 품질이 좋지 않다.
Auto Regressive Model(ARM)은 밀도 추정에서 좋은 성능을 보이지만, 계산 비용이 많이 드는 구조와 sequential sampling process의 한계로 저해상도를 대상으로 제한한다.
최근 DM은 밀도 추정 및 샘플 품질면에서 sota를 기록했다. (UNet의 이미지 데이터 편향에 대한 강점) 일반적으로 최적의 결과는 DM에 대해서 reweight 과정을 수행하면서 얻게 되는데 Pixel Level에서는 추론 속도가 낮고 학습 비용이 비싼 문제가 있다.
본 논문에서는 low dimension의 latent space에서 동작하도록 하여 이러한 문제를 해결했다.
Two-Stage Image Synthesis
individual generative approach의 단점을 완화하기 위해 two stage approach에 대한 연구가 진행됐다.
이와 관련해서 대표적으로 VQ-VAE, VQGAN 등이 있는데, ARM 훈련에는 수십억의 파라미터 수가 필요해서 압축을 많이 하게 되면 성능이 저하되고, 계산 비용이 크기때문에 압축을 많이 할 수 없는 문제가 있다.
제안하는 LDM은 Convolution Backbone을 통해 더 높은 차원의 latent space로 확장 가능하므로 이러한 문제를 방지할 수 있다. 따라서, 높은 fidelity reconstruction을 보장하면서 diffusion model을 생성할때까지 많은 압축이 필요없고 자유롭게 압축 수준을 선택할 수 있다.
encoding/decoding 모델과 score based prior을 함께 혹은 개별로 학습하는 접근 방식이 있지만, 전자의 경우는 generative와 reconstruction capability사이를 조절하기 어려운 문제가 있고, 후자의 경우는 고도로 구조화된 이미지(사람 얼굴)에 집중되는 경향이 있다.
Method
Stable Diffusion 모델은 generative learning phase에서 명시적으로 압축 과정을 분리하여 기존 DM에 요구되는 많은 리소스 제한을 피한다. 이를 위해 image space와 perceptuality가 동일하지만, 계산 복잡도를 크게 줄일 수 있는 auto encoding model을 활용한다.
이 방식의 이점은 다음과 같다.
- 저차원 공간에서 샘플링이 수행되므로 계산적으로 이득을 볼 수 있는 DM을 얻는다.
- UNet 아키텍처로부터 상속된 DM의 inductive bias를 활용하여 공간 구조를 가진 데이터에 효과적이고 이전 접근 방식과 달리 품질이 낮은 압축 수준이 필요없다.
- 잠재 공간으로부터 여러 생성 모델을 학습할 때 활용할 수 있고, 여러 다운 스트림 테스크에 활용될 수 있는 범용 압축 모델을 얻는다.
Perceptual Image Compression
제안하는 perceptual compression model은 perceptual loss, patch based adversarial objective의 조합으로 학습된 auto encoder로 구성된다.
이를 통해 local realism을 적용하여 reconstruction은 image manifold에 제한되고, L2 또는 L1 objective와 같은 pixel space loss에만 의존하여 blur를 피할 수 있다.
이 과정은 다음과 같이 수행된다.
- RGB 공간의 원본 에 대해서 Encoder 을 통해 latent space로 변환한다.
- Decoder 는 latent를 image로 변환한다.
여기서, 는 에 의해 의 비율로 Downsample된다. 그리고 을 나타낸다.
본 연구에서는 임의의 높은 변동성을 가진 latent space를 피하기 위해 두 가지의 다른 종류 정규화 실험을 진행했다.
KL-reg는 VAE와 유사하게 학습된 latent state에서 standard normal에서 약간의 KL 패널티를 부과하는 반면에 VQ-reg.는 디코더 내에서 vector quantization layer를 사용한다.
이 모델의 경우 VQGAN으로 해석될 수 있지만, 디코더에 의해 흡수된 quantization layer를 가지고 있다. 이어서 DM은 학습된 latent space 의 2차원 구조와 함께 동작되도록 설계되어 비교적 가벼운 압축 속도와 높은 재구성 성능을 보인다.
이와 관련해서 이전 연구에서는 latent space 의 임의적인 1 순서에 의존하여 분포를 auto regressive하게 모델링하여 의 고유 구조를 무시했던 이전 연구와는 큰 차이가 있다.
Latent Diffusion Models
Generative Modeling of Latent Representations
과 로 구성된 trained perceptual compression model을 통해 high-frequency, imperceptible details가 추상화되는 latent space에 접근할 수 있다.
latent space에 접근함으로써 데이터의 중요한 semantic bit에 집중하고, 더 낮은 차원에서 동작하므로 계산적 이점을 가지게 된다.
또한, 제안하는 모델은 UNet 아키텍처를 활용하여 이미지의 inductive bias를 활용할 수 있고 reweighted bound를 사용하여 관련성이 높은 비트에 더 집중한다.
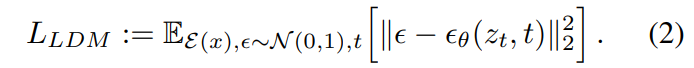
Conditioning Mechanisms
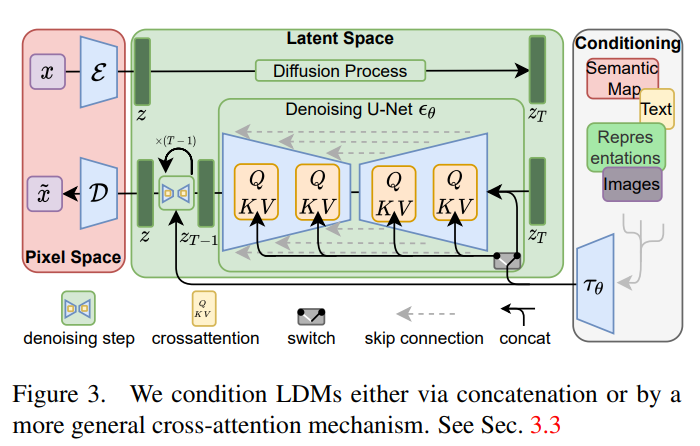
논문에서는 다양한 입력 양식의 attention based model을 학습하는데 효과적인 corss attention mechanism을 소개한다.
다양한 modality로부터 를 전처리하기 위해, 를 intermediate representation에 투영하고 cross attention layer를 통해 UNet의 intermediate layer에 매핑하는 domain specific encoder 를 도입한다. ()
여기서, cross attention layer는 UNet의 intermediate representataion을 flatten하여 Query에 사용하고, domain specific encoder를 각각 Key, Value에 사용한다.

LDM 모델의 전체 구조는 다음과 같다.
Experiments
저자는 먼저 학습과 추론 모두에서 pixel based diffusion model에 비해 모델의 이점을 분석합니다. 흥미롭게도, VQ 정규화된 latent space에서 훈련된 LDM이 때때로 더 나은 샘플 품질을 달성한다는 것을 발견했다.

On Perceptual Compression Tradeoffs
 LDM의 First Stage Model의 Parameter 별 Reconstruction 성능
LDM의 First Stage Model의 Parameter 별 Reconstruction 성능
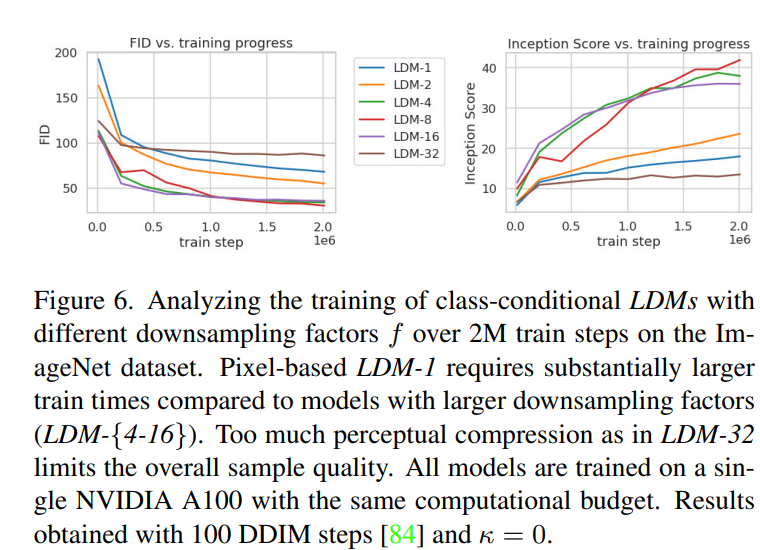 ImageNet에서 class-conditional model의 2M steps 학습 과정 Sample Quality
ImageNet에서 class-conditional model의 2M steps 학습 과정 Sample Quality
DownSample Factor는 학습을 느리게하며 (LDM-1, LDM-2), 지나치게 큰 f 값은 비교적 적은 step에서 품질의 정체를 일으킨다는 사실 확인 가능 (LDM-32)
-> perceptual compression을 대부분 DM에서 수행 (학습 속도 저하)
-> 많은 압축으로 인한 정보 손실로 품질 제한
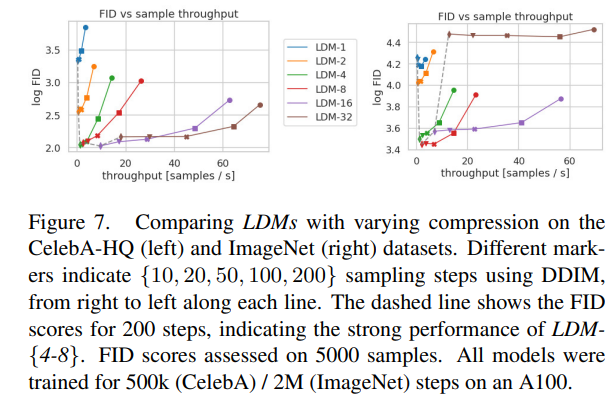 CelebA / ImageNet에서의 LDM 샘플링 속도와 FID 비교
CelebA / ImageNet에서의 LDM 샘플링 속도와 FID 비교
LDM 4, LDM 8의 성능이 가장 최적임을 확인
Image Generation with Latent Diffusion
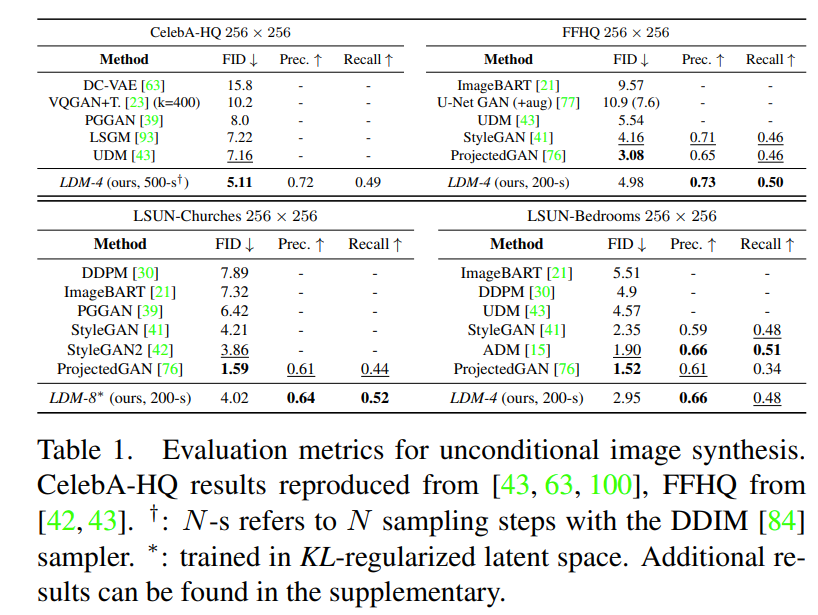 Unconditional LDM 성능 평가 결과
Unconditional LDM 성능 평가 결과
 Unconditional LDM 정성 평가 결과
Unconditional LDM 정성 평가 결과
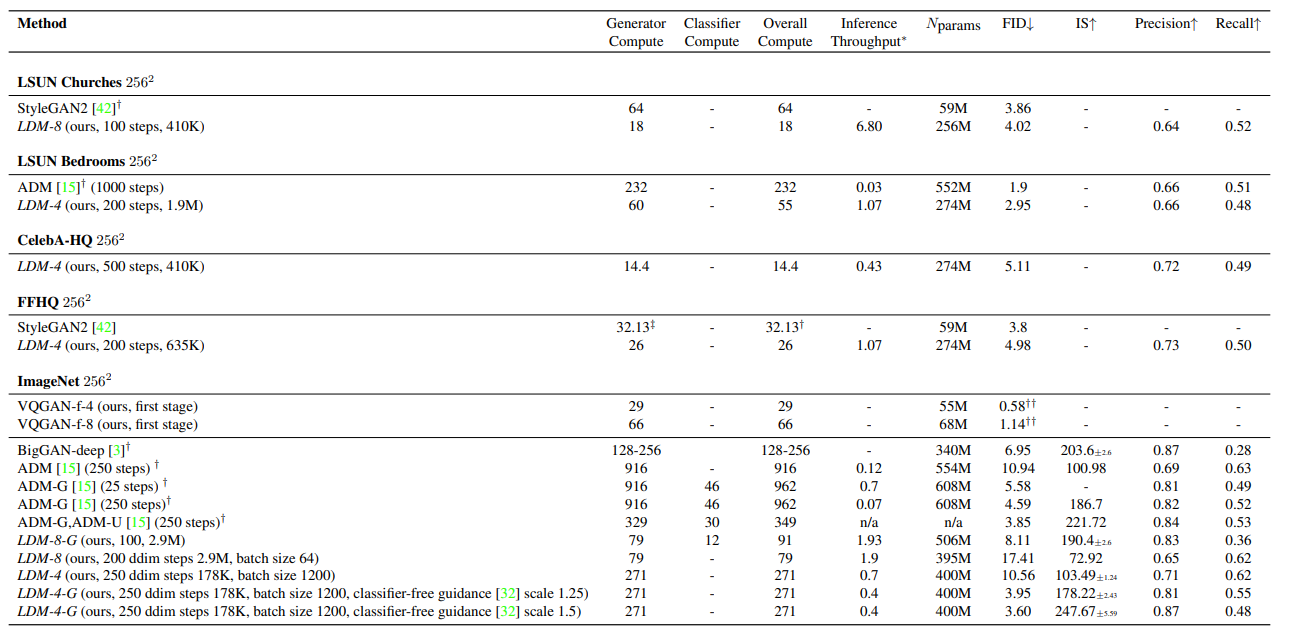 Computing Resource 비교
Computing Resource 비교
LDM은 DM, GAN에 대해서 더 적은 Computing Resouce를 사용하면서도 높은 성능을 보임
Conditional Latent Diffusion
Transformer Encoders for LDMs
Cross Attention based LDM의 성능 확인을 위해 여러 Modality를 대상으로 실험 진행
 LAION Dataset 기준 Text-to-Image LDM-8 (KL) 모델 정성 평가 결과
LAION Dataset 기준 Text-to-Image LDM-8 (KL) 모델 정성 평가 결과
 COCO Dataset 기준 Layout-to-Image LDM 모델 정성 평가 결과
COCO Dataset 기준 Layout-to-Image LDM 모델 정성 평가 결과
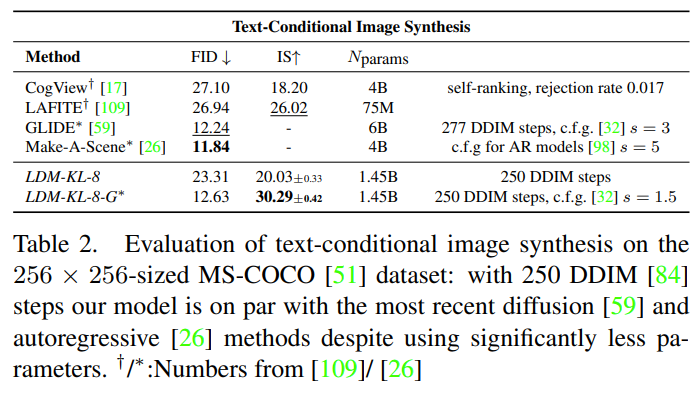 COCO Dataset 기준 LDM Text-to-Image 성능 평가 결과
COCO Dataset 기준 LDM Text-to-Image 성능 평가 결과
Convolutional Sampling Beyond
UNet 아키텍처의 inductive bias의 효과로 공간적으로 정렬된 condition 정보가 LDM 모델에 입력되어 효율적인 범용 image-to-image translation model을 얻을 수 있다.
 Semantic Synthesis Task에서의 2562 pretrained LDM의 512 x 1024 결과
Semantic Synthesis Task에서의 2562 pretrained LDM의 512 x 1024 결과
적은 해상도 (e.g. 256)으로 학습되었지만, 더 큰 해상도(e.g. mega-pixel)로 일반화될 수 있음을 확인
-> inpainting과 super resolution task로의 실험 확산
Super-Resolution with Latent Diffusion
 ImageNet Super Resolution 정성 평가 결과
ImageNet Super Resolution 정성 평가 결과
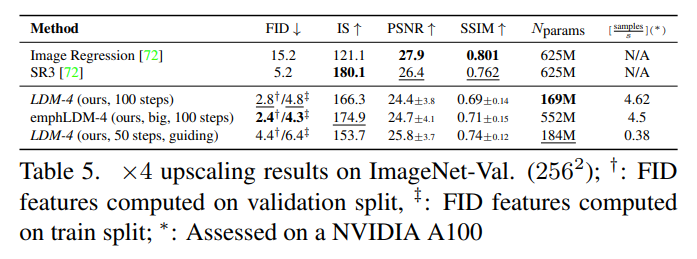 ImageNet Super Resolution 정량 평가 결과
ImageNet Super Resolution 정량 평가 결과
Inpainting with Latent Diffusion
 Inpainting 정성 평가 결과 - 1
Inpainting 정성 평가 결과 - 1
 Inpainting 정성 평가 결과 - 2
Inpainting 정성 평가 결과 - 2
 Inpainting 정량 평가 결과
Inpainting 정량 평가 결과
Limitations & Societal Impact
- 여전히 GAN 모델보다 느린 샘플링 속도
- fine-grained accuracy가 필요한 이미지 생성 Task(e.g. Super-Resolution)에서 autoencoder에서 bottoleneck이 발생할 수 있음
- 다양한 창작물을 만들 수 있으나 잘못된 정보를 퍼뜨리는데 사용될 수 있음
- 데이터에 이미 존재하는 편향을 재현하거나 악화시키는 경향 발생
