Exploiting Diffusion Prior for Real-World Image Super-Resolution
Abstract
논문에서는 Blind Super Resolution(SR)을 위해 Pre-trained Text to Image Diffusion Model의 사전 지식을 활용하는 새로운 방법론을 제시한다. 본 논문에서 소개하는 방법론의 이점은 다음과 같다.
- Pre-trained Synthetic Model을 변경하지 않고 Time-Aware Encoder를 사용함으로써 교육 비용 최소화 및 성능 향상
- Realism과 Fidelity 사이의 Trade off를 조정할 수 있는 Feature Wrapping Module 제안
- Pre-trained Diffusion Model의 고정 사이즈 제약을 극복하기 위해 progressive aggregation sampling 전략 사용
Introduction
본 연구에서는 Super Resolution 분야에서 diffusion prior를 사용했을 때의 잠재적인 이점에 대해서 검토한다.
기존 Diffusion model은 확률적 특성과 대조적으로 높은 이미지 fidelity를 요구하기때문에 어려움을 겪는다. 일반적인 해결 방법은 SR 모델을 처음부터 훈련시키는 것인데, 이 방법의 경우 성능은 어느정도 보장이 되지만, 모델을 훈련시키기 위한 리소스가 매우 많이 소요된다는 단점과 일반화 문제를 포함.
이러한 한계는 pre-trained synthesis model의 reverse diffusion processs에 제약 조건을 통합하는 것을 포함한 몇가지 대안적인 접근법에 영감을 주었지만, 이 방법 역시 image degradations에 대해서 사전에 알고 있다는 가정이 필요하므로 적용하기 어려운 문제가 존재.
그래서 이 연구에서는 성능 저하에 대한 명시적인 가정을 하지 않고, pre-trained diffusion priors를 보존하는 접근법인 StableSR을 제시한다.
StableSR의 핵심 아이디어는 다음과 같다.
-
time-aware encoder와 일부 feature modulation layer에 대한 fine-tuning을 진행함으로써 training efficiency 향상
→ encoder에서 time embedding layer를 통합하여 time-aware feature를 생성하여 diffusion model의 feature가 서로 다른 time step에서 적응적인 특성을 지님
-
original diffusion model을 frozen 상태로 유지하여 generative prior를 보존
-
encoding process로 인한 정보 손실과 diffusion model의 확률성을 억제하기위해 조정가능한 상관계수를 가진 feature wrapping module을 적용
-
임의의 해상도를 처리하기 위해 이미지를 중복 패치로 나누고 각 diffusion iteration에서 Gaussian kernel을 사용하여 합치는 방식인 progressive aggregation sampling strategy를 도입
Related Work
Image Super-Resolution
기존의 SR 접근법들은 보통 사전 정의된 degradation process를 가정한다. (e.g. bicubic downsampling, blurring) 이러한 접근법들은 real-world 시나리오에서 제한된 일반화 능력으로 인해 성능 저하로 이어지게 된다.
최근 연구들은 synthetic setting에서 blind SR로 초점을 옮겼다. 이와 관련해서 학습을 위한 real-world pair set을 구하기 어렵기 때문에 CycleGan과 contrastive learning과 같이 unsupervised 방법으로 해결하려는 접근 방식을 주로 사용했다.
unsupervised learning 이외에도 실제 데이터와 유사한 LR-HR image pair를 합성하는 접근 방식도 연구되었는데, 이와 관련해서 BSRGAN과 Real-ESRGAN은 real world에서 blind SR을 위한 효과적인 degradation pipeline을 제시했다.
이러한 degradation pipeline을 기반으로한 diffusion model과 같은 최근 연구들은 real-world image SR에서 경쟁력있는 퍼포먼스를 보이고 있다. 본 연구에서는 SR을 위한 diffusion model에 대해서 fine-tuning을 orthogonal direction으로 고려함으로써 네트워크 학습 계산 비용을 줄이고 synthesis model의 generative prior을 활용하여 더 나은 성능을 얻도록 했다. → 모델 재사용성 강조
Prior for Image Super-Resolution
복잡한 real-world SR 시나리오에서 성능을 높이기 위해 다양한 prior-based 접근법들이 제안되어 왔다. 이러한 기법들은 texture 생성을 강화하기 위해 이미지를 추가로 배치한다.
최근에는 implicit prior에 기반한 접근법으로 성능을 향상시키는 연구가 진행됐다. 이와 관련해서 Wang et al.은 semantic segmentation 확률맵을 feature space에서 SR을 guide하기 위해 최초로 제안했다. 후속 작업에서는 LR input의 HR latent space을 탐색하는 pre-trained GAN을 채택했다.
이러한 방법론들은 효과적이지만 제한된 범주에 맞게 조정되는 경우가 많기 때문에 복잡한 real-world SR에 대한 일반화 성능이 부족한 문제가 있다.
논문에서는 기존 전략과 대조적으로 pre-trained diffusion model에서 robust하고 extensive generative prior을 탐색하는것을 목표로한다. 최근 연구에서는 pre-trained diffusion model의 높은 generation 성능을 강조했지만, super-resolution에 내제된 high fidelity 요구 사항은 이러한 방법을 사용하기 어렵게 만든다. StableSR은 LDM과 달리 처음부터 학습시키는 대신, 소수의 학습가능한 매개 변수만을 fine-tuning함으로써 우수한 성능을 얻었다.
Methodology

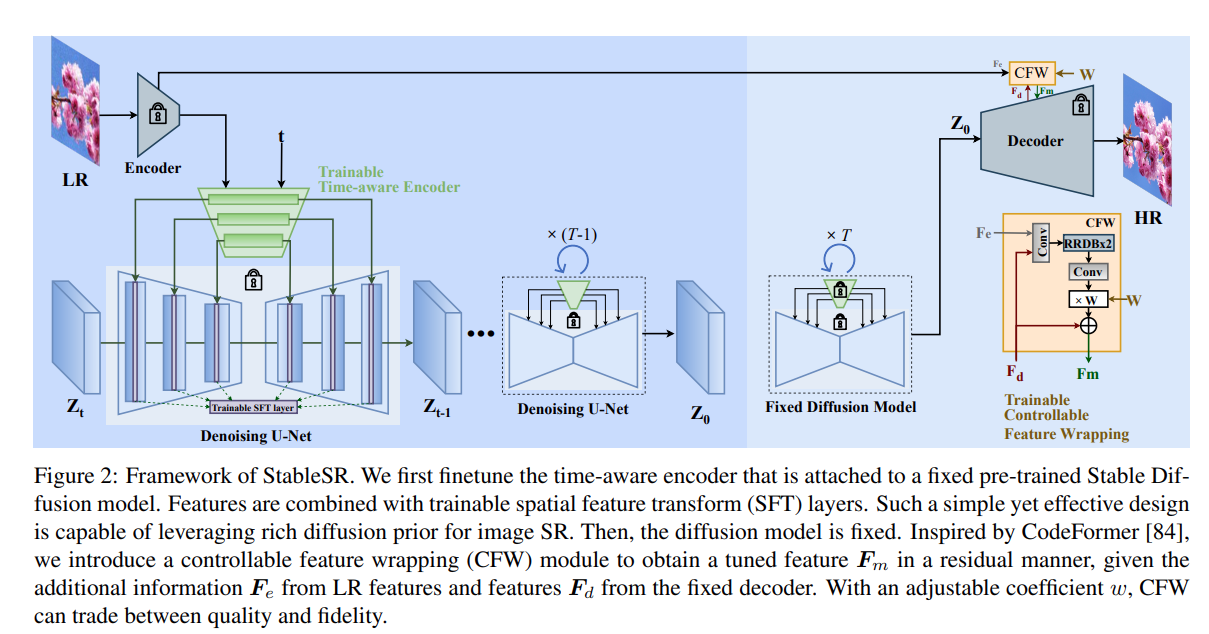
StableSR의 주요 구성 요소는 time-aware encoder로, input image을 기반으로 조절가능한 frozen Stable Diffusion model과 함께 학습된다. 그리고 realism과 fidelity 사이의 trade-off을 더 용이하게 하기위해 CodeFormer를 따라 제어 가능한 feature wrapping module을 도입했다.
Guided Finetuning with Time Awareness
SR을 위한 Stable Diffusion의 prior knowledge를 활용하기 위해 논문 저자는 모델 설계할 때 다음과 같은 제약 조건을 설정했다.
1) 모델은 관측된 LR 입력에 따라 신뢰할 수 있는 HR 이미지를 생성할 수 있어야 한다.
2) 모델은 original Stable Diffusion 모델로부터 최소한의 변경만 도입해야한다.
Feature Modulation
generation process를 보다 정확하게 유도하기 위해 LR image feature로부터 multi-scale feature({} )를 추출하기 위한 추가 encoder를 사용했고, 이를 사용해서 spatial feature transformation을 통해 Stable Diffusion에서 intermediate feature map(} )을 조정한다. 이 과정의 식은 다음과 같다.

여기서, 과 은 SFT에서의 affine 파라미터를 의미하고, 는 convolution network로 구성된 small network를 의미한다. 그리고 은 Stable Diffusion의 Unet 구조의 spatial scale을 의미한다.
fintuning 동안 Stable Diffusion의 weight는 freeze되고 오직 encoder와 SFT layer만 학습된다.
Time-aware Guidance
제안하는 Encoder에 대해서 시간 정보를 통합함으로써 LR feature에서 파생된 condition strength를 적응적으로 조정하여 generation quality와 ground truth fidelity를 향상시켰다. generation process 동안 노이즈는 점차 제거됨에 따라 생성된 이미지의 SNR(Signal to Noise Ratio)이 점진적으로 증가한다. 이와 관련해서 최근 연구에 따르면 SNR이 5e-2일때 이미지 컨텐츠가 빠르게 채워진다고 주장했고, 이러한 연구에 따라 제안된 encoder는 SNR이 5e-2를 만족하는 범위내에서 diffusion model이 비교적 강한 조건을 제공하도록 설계되었다.
논문에서는 SFT 전후의 Stable Diffusion의 feature간에 cosine similarity를 사용하여 encoder가 제공하는 조건 강도를 측정했다. 서로 다른 timestep에서의 cosine similarity는 아래 Fig 3에 제시되어 있다.
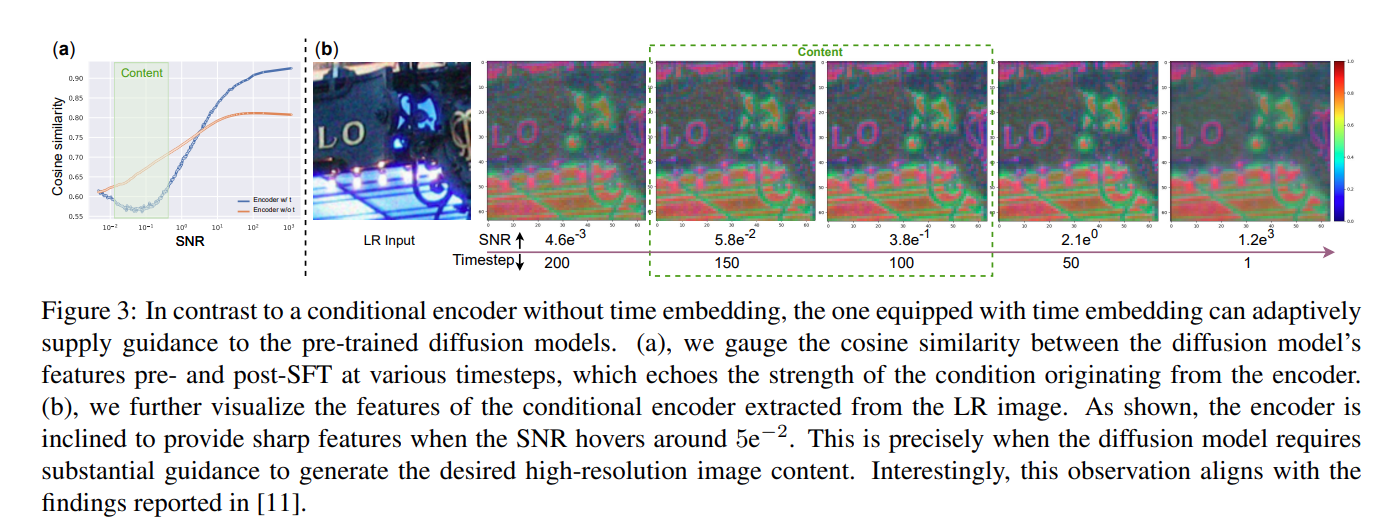
측정 결과, timestep에 따라 SNR은 점차 감소했고, SNR이 5e-2인 구간에서 Cosine Similarity가 저점을 기록한 것을 확인할 수 있다. 그리고 feature map을 시각화 했을때 이 구간에서 더 상세한 이미지 구조를 가지는 것을 확인할 수 있다.
Color Correction
Diffusion Model은 color shift 문제를 가지고 있는데, 본 논문에서는 이러한 문제를 해결하기 위해 다음과 같이 Color Normalization을 수행한다.
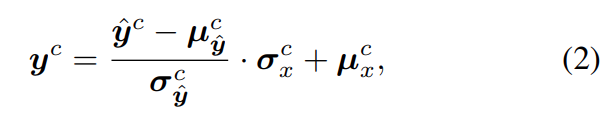
여기서 각 파라미터의 의미는 다음과 같다.
- : LR input image
- : HR output image
- ∈ {} : color channel
- , : 각 와 에서의 c 채널의 평균 및 표준편차 값
Fidelity-Realism Trade-off
제안된 접근의 출력은 시각적으로 설득력이 있지만, Diffusion Model의 고유한 확률성으로 인해 가끔 ground truth와 편차가 발생하게 된다. 본 연구에서는 이라한 문제를 해결하기 위해 Controllable Feature Wrapping(CFW) module을 소개한다.
CFW의 수식은 다음과 같다.
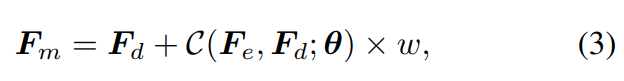
여기서, 각 파라미터 수식은 다음과 같다.
- : Encoder Feature
- : Decoder Feature
- : Convolution Layers
- : Trainable Parameter
- : adjustable coefficient
는 값이 작으면 high realism, 반대로 높으면 fidelity를 높이는 역할을 한다.
Aggregation Sampling
StableSR의 경우, 학습 설정과 다른 해상도에서 안좋은 성능을 보이는 경향이 있다. 이러한 문제에 대한 일반적인 해결책은 여러 개의 중첩된 작은 패치로 분할하여 각각의 패치의 결과를 합치는 방식이다. 그러나 이러한 방법들은 패치들 간의 불일치로 인해 문제가 발생된다. 이와 관련한 사례는 Fig 4에 제시되어 있다.

본 논문에서는 임의의 해상도의 이미지를 처리하기 위해 progressive patch aggregation sampling algorithm을 적용했다.
먼저, LR 이미지를 latent feature map으로 인코딩한 뒤, 64x64 resolution의 multiple overlapping small patch로 분할한다. rever sampling에서의 각 timestep에서 각각 StableSR을 통해 처리되고, 처리된 patch들은 이후에 합쳐진다. 그리고 중복되는 patch들을 합치기 위해 가우시안 커널을 통해 64x64 크기의 가중치 맵을 생성하고 중첩 픽셀은 각 가우시안 가중치 맵에 의해 가중치가 부여되어 합쳐진다.
Experiments
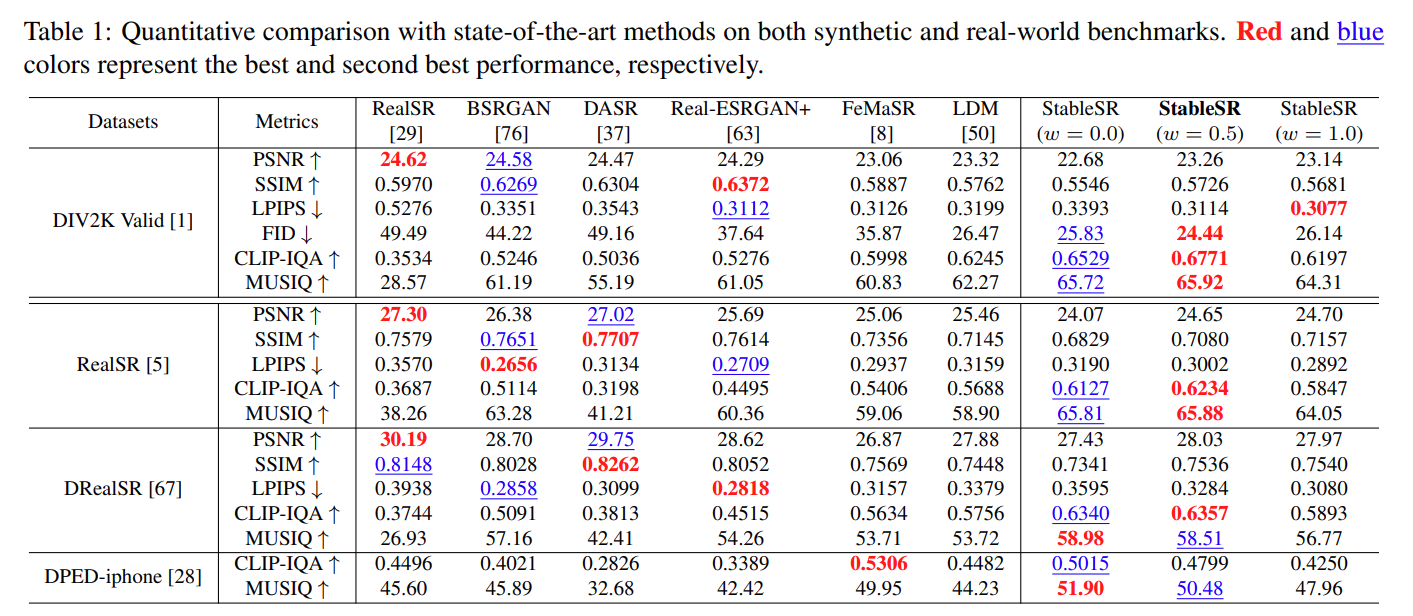 Sota 모델 퍼포먼스 비교
Sota 모델 퍼포먼스 비교
PSNR(Peak Signal-to-Noise Ratio) : 영상 내 신호가 가질 수 있는 최대 신호에 대한 노이즈 비율
SSIM(Structural Similarity Index Map) : 휘도, 대비, 구조 측면에서 품질 평가
LPIPS(Learned Perceptual Image Patch Similarity) : Feature Map 기반 유사도 측정 값
FID (Frechet Inception Distance) : Activation Map 기반 확률 분포 유사도 측정 값
CLIP-IQA : Clip 모델을 활용한 Embedding 방식 기반 이미지 퀄리티 측정 방법
MUSIQ(Multi-Scale Image Quality Transformer) : multi-scale 이미지 품질 평가 모델 기반 평가 방법
 Sota 모델 정성적 비교 결과
Sota 모델 정성적 비교 결과
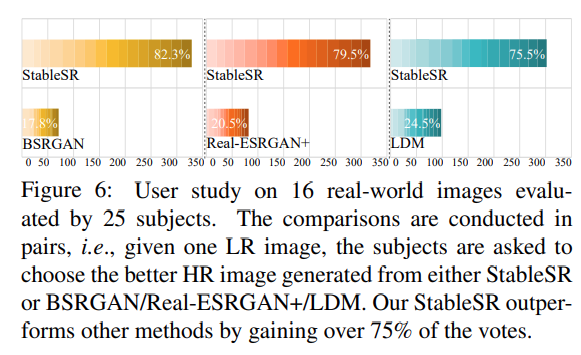 사용자 평가 결과
사용자 평가 결과
 Ablation Study - Time Aware Encoder & Color Normalization
Ablation Study - Time Aware Encoder & Color Normalization
 Ablation Study - CFW Module
Ablation Study - CFW Module
Conclusion
StableSR은 SR에 대해서 높은 성능을 보이지만, time step 200을 기준으로 32G Tesla V100에서 512x512 이미지를 생성했을 때, 약 10초가 걸리는 한계가 있다. 추후 연구에선 빠른 Sampling 전략과 Model Distillation 관점에서 이러한 제한점을 해결하고자 한다.
본 논문에서는 SR에 대해서 Diffusion Prior을 어떻게 적용할 수 있을지에 대한 문제를 집중적으로 다뤘고, Fine Tuning시에 전체적인 모델 학습을 피하면서 real-world SR을 위한 diffusion prior 활용하는 새로운 방법인 StableSR을 제안했다.
그리고 높은 계산 비용과 고정 해상도 문제를 해결할 수 있는 Time-Aware Encoder, CFW, Aggregation Sampling Scheme 등을 소개했다.
