Hybrid Task Cascade for Instance Segmentation
Abstract
논문에서는 Hybird Task Cascade(HTC)라는 새로운 Framework를 제안하며, 다음 두가지 측면에서 다른 점을 제시했다.
(1) cascaded refinement를 detection과 segmentation의 두 task에 대해서 함께 상호 적용하도록 설계
(2) fully convolutional branch를 사용하여 spatial context를 제공
MSCOCO dataset에서 single HTC를 적용하여 38.4%를 기록했으며, Cascade Mask R-CNN baseline보다 1.5%의 성능 향상을 얻었다. 그리고 test-challenge split에서 48.6 mask AP를 기록하여 COCO 2018 Object Detection Task Challenge에서 1st를 달성했다.
1. Introduction
Cascade 구조는 다양한 task에 대해서 multi-stage refinement를 적용함으로써 성능을 향상시켰다. 특히, Cascade R-CNN은 object detection을 위한 multi-stage 구조를 제시함으로써 좋은 성과를 보였고, 성공에 대한 원인은 다음 두가지 주요 측면에 기인한다.
(1) prediction의 점진적인 refinement
(2) training distributions에 대한 적응적인 처리
기존 Cascade 구조의 문제
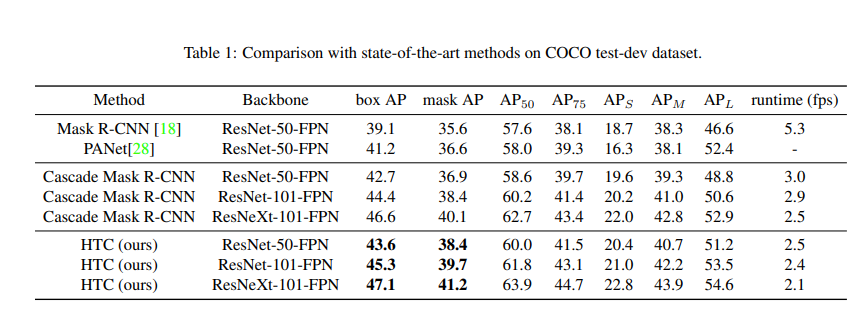
- detection task에서는 효과적이지만, Cascade의 아이디어를 instance segmentation에 통합하는 것은 쉽지 않다. Cascade R-CNN과 Mask R-CNN을 직접적으로 조합했을 때 bbox AP에 비해 mask AP는 제한적인 성능을 야기했다. (Table 1 참조)
주요 원인
- 서로 다른 stage의 mask branch간의 정보 흐름이 최적이 아니기 때문이다. later stage의 mask branch들은 직접적인 연결 없이 오직 더 나은 localized bounding box의 이점만 있게 된다.
HTC의 주요 아이디어
논문에서는 이런 차이를 해결하기 위해 Hybrid Task Cascade(HTC)라는 instance segmentation을 위한 새로운 cascade architecture를 제안했다.
(1) 각 stage에서 cascade와 multi-tasking을 통합하여 정보 흐름의 향상
- 논문 저자는 점진적인 refinement를 위한 cascaded pipeline을 설계했다. 각 stage에서는 bounding box regression과 mask prediction이 multi-tasking 방법으로 결합된다.
(2) spatial context를 활용한 정확도 향상
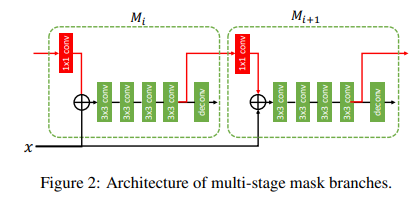
- 서로 다른 stage에서 mask branch간의 직접적인 연결을 도입했다. (Figure 2 참조)
(3) context 정보 활용을 위한 stuff segmentation
- context 정보을 활용하기 위해 픽셀 수준의 stuff segmentation을 수행하는 fully convolutional branch를 포함함으로써 foreground와 background의 contextual information을 encode하여 보완할 수 있게 했다.
HTC 성과
- coco dataset 기준 Mask R-CNN과 Cascade Mask R-CNN보다 각 2.6%와 1.4% 높은 mask AP를 기록
- deformable convolution, multi scale training 및 testing, model ensembling을 적용하여 coco 2017 challenge의 기록보다 약 2.3% 높은 49.0 mask AP 기록
HTC 기여
- 공통 multi-stage processing을 위해 detection과 segmentation feature를 연결함으로써 효과적으로 instance segmentation에 cascade를 통합
- foreground object를 background clutter와 구별함으로써 spatial context가 instance segmentation에 이점이 있음을 보여줌
2. Related Work
Instance Segmentation
현재 Instance Segmentation 방법은 크게 detection-based와 segmentation-based 방법으로 구분된다.
detection-based 방법은 기존 detector를 통해 bounding box 또는 region proposal를 생성하고, bounding box내에 object mask를 추론한다. 관련 연구는 하기와 같다.
-
DeepMask, SharpMask, Instance-FCN을 포함한 대부분 방법들은 CNN을 기반으로한다.
-
MNC의 경우, 3가지 sub task로 구성된 pipeline으로 instance segmentation을 정의한다. (instance localization, mask prediction과 object categorization, cascaded 방법으로 end-to-end 학습)
-
FCIS의 경우는 Instance-FCN을 확장하고, fully convolutional 접근으로 instance segmentation을 연구
-
Mask R-CNN은 Faster R-CNN을 기반으로 branch 추가 및 pixel-level mask prediction 수행
-
PANet은 정보의 흐름을 유용하게 하기위해 FPN의 top-down 경로에서 bottom-up 경로를 추가
segmentation-based 방법은 이와 반대로 pixel-level segmentation map을 얻고, object instance를 식별한다.
Multi-stage Object Detection
object detection frame의 기존 주요 연구 방향은 single-stage detector와 two-stage detector로 구분될 수 있다. 최근에는 multiple stage를 적용한 detection framework가 등장했다.
- Multi-region CNN은 box scoring과 location refinement 사이에서 반복적으로 대체하는 연구 진행
- AttractionNet은 box location을 반복적으로 업데이트하기 위한 Attend & Refine module을 소개
- CRAFT는 cascade 구조를 RPN과 Fast R-CNN에 통합
- Cascade R-CNN은 multiple stage를 포함하며, 각 stage의 출력은 다음 stage에 입력되어 higher quality refinement를 얻을 수 있도록 한다. 또한, stage를 거칠수록 iou threshold가 증가하는 방향으로 sample되고 이는 다른 학습 분포를 처리한다는 것을 의미한다.
제안하는 HTC와 기존 cascade 기반 모델의 차이점은 다음과 같다.
- detection, mask prediction, semantic segmentation의 결과가 각 stage에서 합쳐진다. (joint multi-stage processing pipeline으로 명칭)
- stuff segmentation을 위한 추가적인 branch를 통해 contextual information이 활용된다.
3. Hybrid Task Cascade

Overview
HTC와 기존 framework간의 차이
- box regression과 mask prediction을 병렬적으로 실행하는 대신 interleave 방식 사용
- 정보 흐름을 강화하기 위해 stage를 거치면서 mask feature를 직접 연결하는 방식으로 통합
- semantic segmentation branch를 추가하여 더 많은 contextual information을 얻도록 했고, box와 mask branch에 결합
3.1 Multi-task Cascade
Cascade Mask R-CNN
Cascade Mask R-CNN 구조는 Figure 1 (a)와 같고, pipeline은 다음과 같이 표현된다.
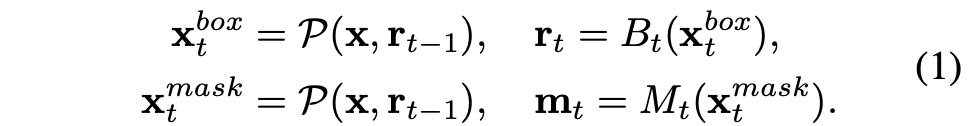
여기서, 각 파라미터의 의미는 다음과 같다.
- : backbone으로 추출된 CNN Feature
- , : 와 입력 ROI로부터 추출된 box, mask feature
- : pooling operator (e.g.ROI Align or ROI pooling)
- , : t-th stage에서의 box와 mask head
- , : box와 mask prediction 결과
cascaded refinement의 이점과 bounding box와 mask prediction의 상호 이점을 결합하여 Mask R-CNN보다 box AP 성능을 향상시켰지만, 여전히 mask prediction 성능은 안정적이지 않다.
Interleaved Execution
위 설계의 한 가지 단점은 각 단계의 두 가지 분기가 훈련 중에 병렬로 실행된다는 것입니다. 둘 다 이전 단계의 bounding box 예측을 입력으로 받아들인다. 결론적으로 한 단계에서 두 분기가 서로 상호작용하지 못하게 된다. 이 문제를 해결하기 위해 box와 mask branch를 interleave하여 개선된 design을 제시했고, Figure 1 (b)와 같다.
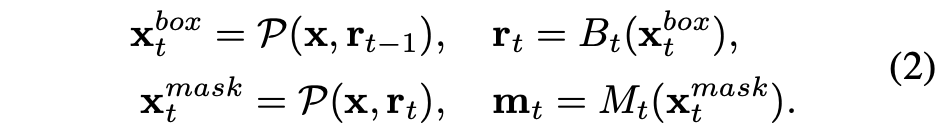
이 design을 적용했을 때, mask branch는 업데이트된 bounding box 예측을 얻을 수 있는 이점이 있다.
Mask Information Flow
Interleaved Execution의 경우, ROI Feature인 와 box prediction인 에만 기반하기 때문에 서로 다른 mask branch간의 직접적인 정보 연결이 없어서 mask prediction 정확도에 대한 성능 향상을 막게 된다.
Interleaved Execution과 비슷한 전략으로 이전 stage의 mask feature를 현재 mask branch에 입력으로 전달하는 정보 흐름 전략을 사용했고, Figure 1 (c)와 같다.

여기서, 각 파라미터의 의미는 다음과 같다.
- : 의 intermediate feature
- : 현재 stage의 feature와 이전 stage의 feature를 결합하는 function
Implementation
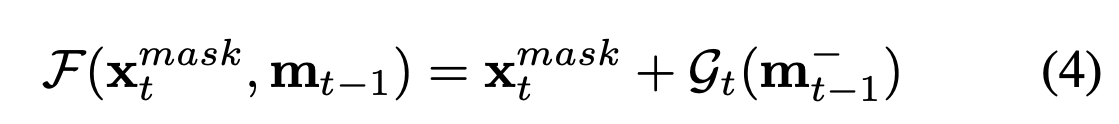
앞에서 설명한 접근 방식들을 종합하면 위와 같다. deconvolution layer 이전의 RoI feature를 mask representation 으로 사용하고, spatial size는 14x14를 가진다. Stage t에서, 를 계산하기 위해 모든 이전의 mask head부터 현재 stage의 ROI를 거쳐야된다.
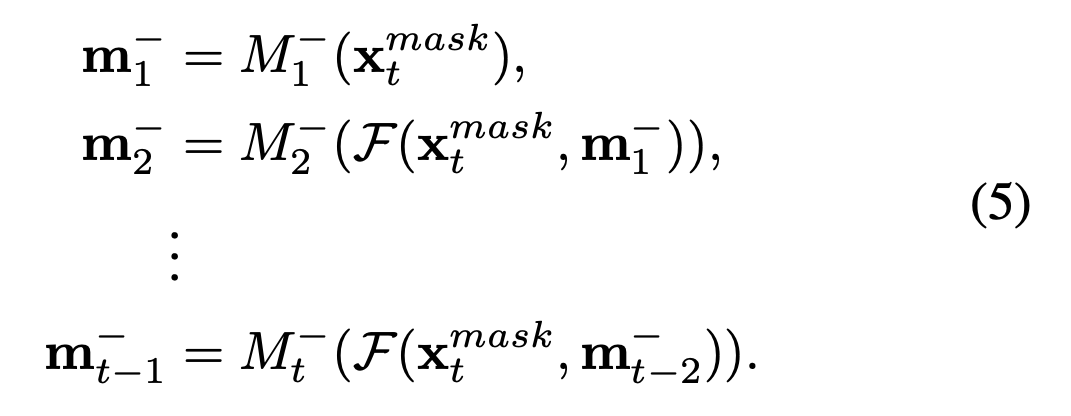
위의 과정은 다음과 같다.
- : mask head 의 feature transformation component, 4개의 연속적인 3x3 convolutional layer로 구성(Figure 2 참조)
- 변환된 feature 는 1x1 convolution layer 와 함께 embed되어 pooled backbone feature 에 맞게 align된다.
- 마지막으로 )은 에 element-wise sum이 수행된다.
이러한 구조를 통해 Mask Feature는 더 이상 독립적이지 않고 인접한 mask branch 간의 상호작용이 가능해졌다.
3.2 Spatial Contexts from Segmentation
논문에서는 background로부터 fore ground를 이해하기 위해 spatial context 정보를 사용했다. Figure 1 (d)와 같이 전체 이미지에 대해서 픽셀 별 semantic segmentation 추론 결과를 얻기 위해 fully convolutional architecture를 사용하고 다른 branch와 상호 훈련되는 branch를 추가했다.
Semantic Segmentation Branch
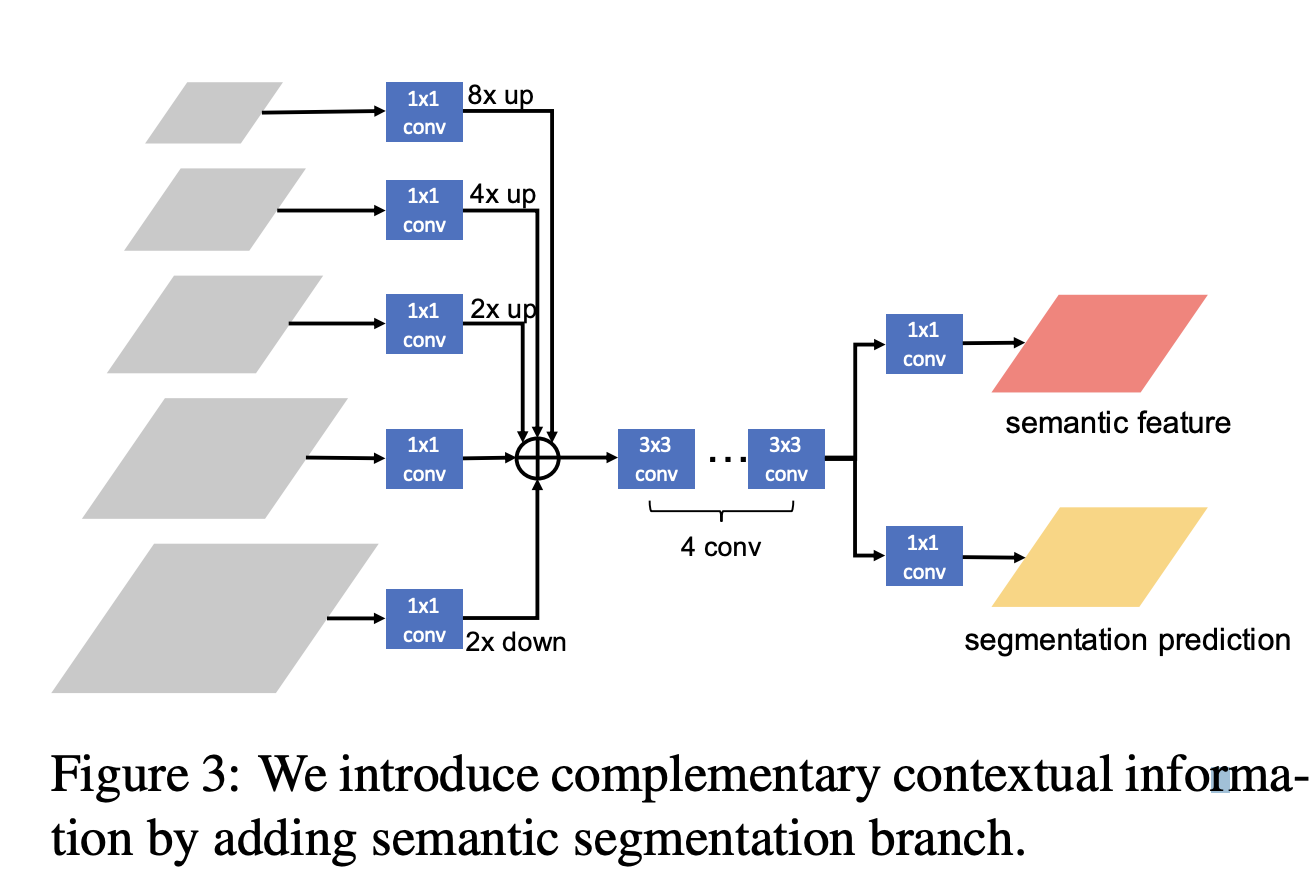
Semantic segmentation branch 는 Feature Pyramid의 출력으로부터 얻어진다. 여기서 주의할 점은, single level로 얻어진 feature는 discriminative power가 약할 수 있다는 부분이다. 따라서 논문에서는 mid-level에서 higher-level과 lower-level의 feature를 통합함으로써 higher-level의 global feature와 lower-level의 local feature를 얻을 수 있도록 multi-level feature를 통합했다.
3.3 Learning
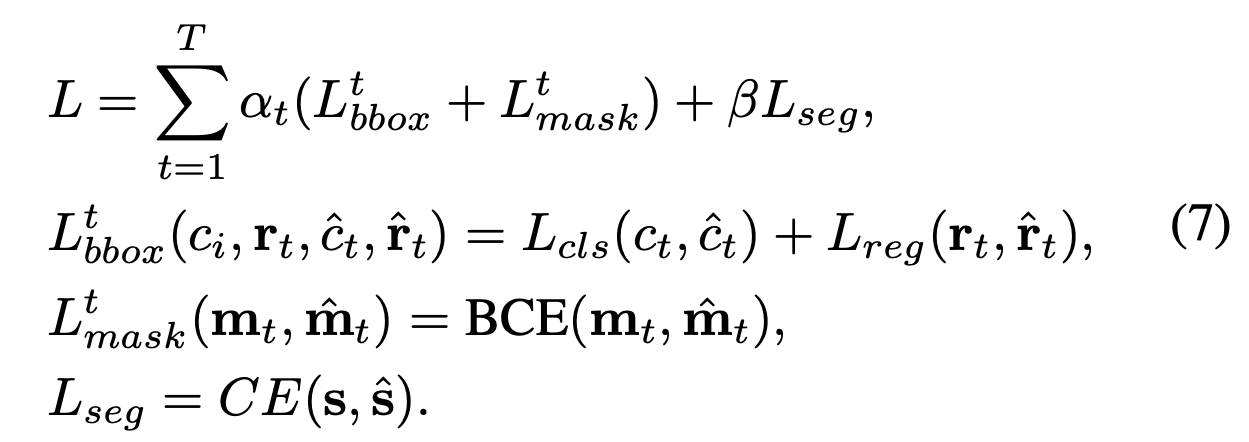
multi-task learning에서의 전체적인 loss function은 상기와 같고 각 파라미터에 대한 의미는 다음과 같다.
- : t stage에서의 bounding box prediction에 대한 loss (Cascade Mask R-CNN과 동일)
- , : classification과 bounding box regression
- : t stage에서의 mask prediction에 대한 loss (Mask R-CNN과 동일)
- : semantic segmentation loss (Cross Entropy)
- , : 상관 계수
- 논문에서는 = [1, 0.5, 0.25], T=3, =1 사용
4. Experiments
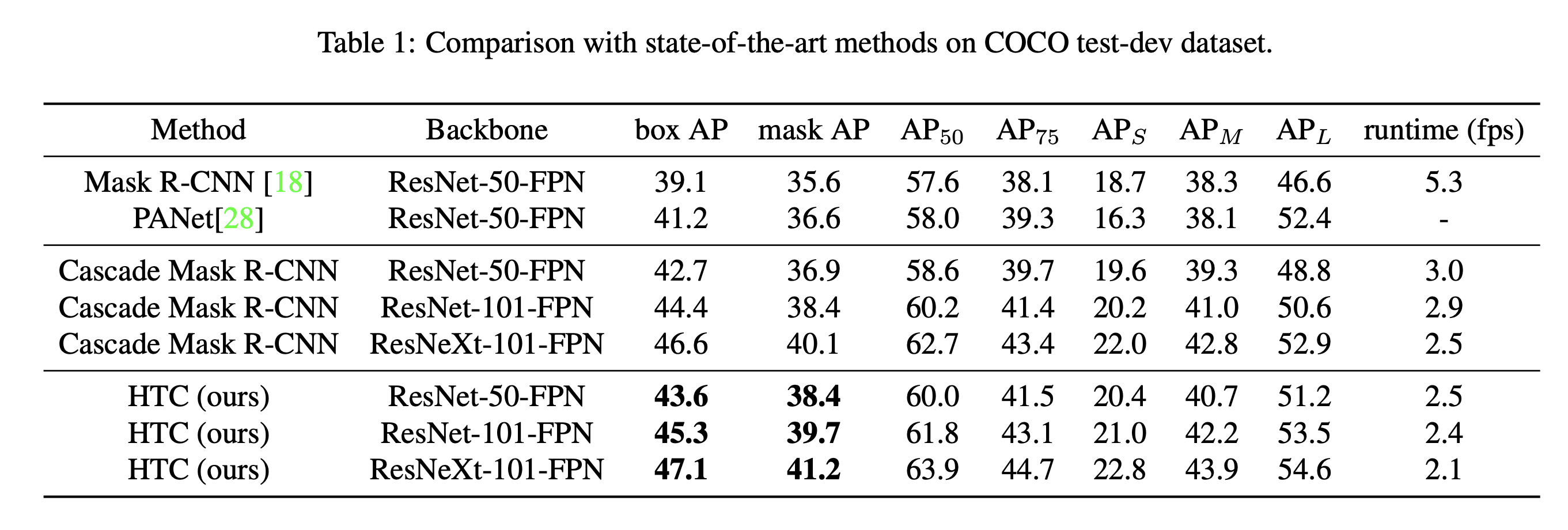
- Benchmarking Results : bounding box, mask AP 모두 일관성 있게 상승한 것을 확인

- Ablation Study : Component-wise Analysis

- Ablation Study : Effectiveness of Interleaved Branch Execution
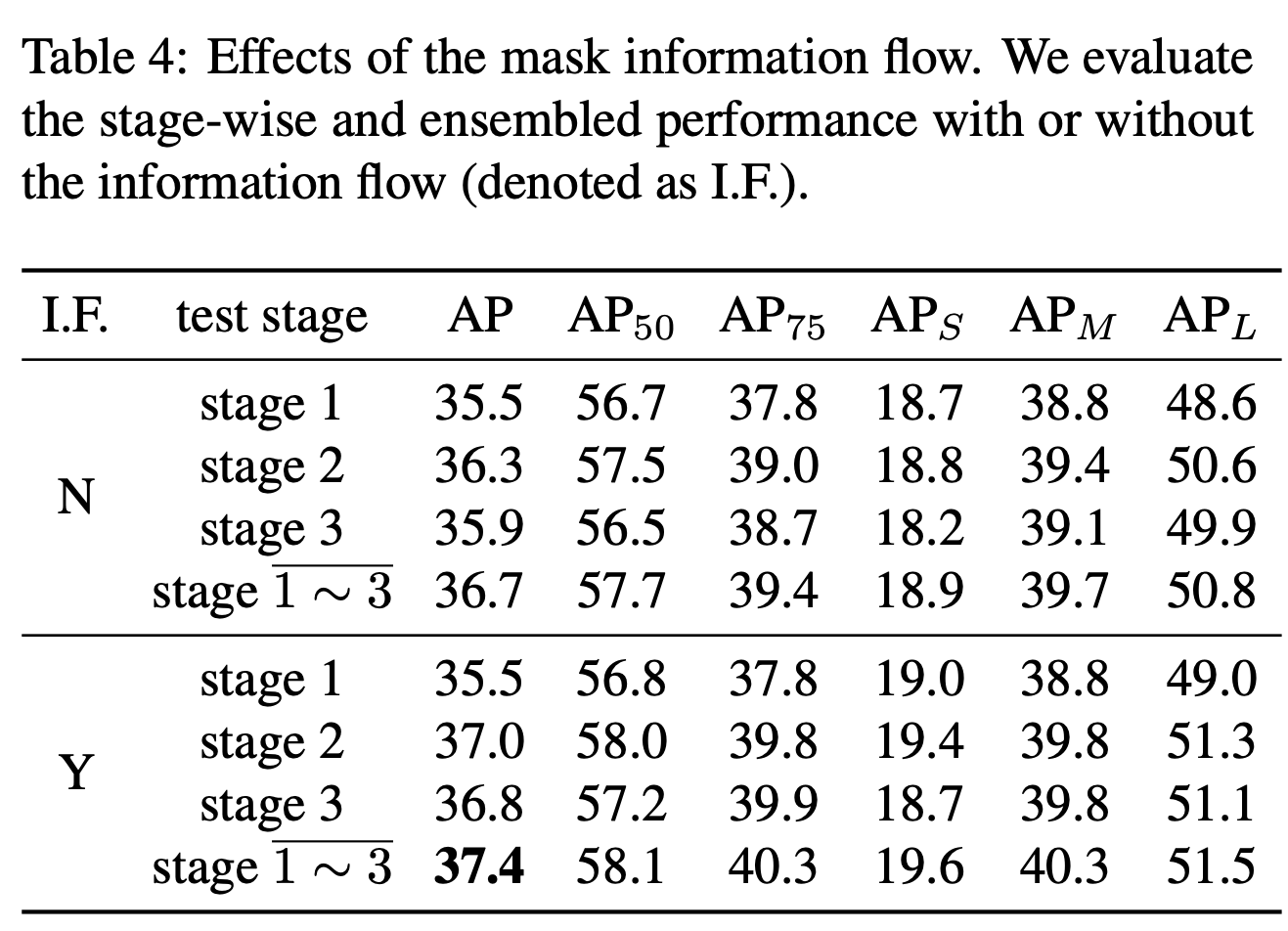
- Ablation Study : Effectiveness of Mask Information Flow

- Ablation Study : Effectiveness of Semantic Feature Fusion
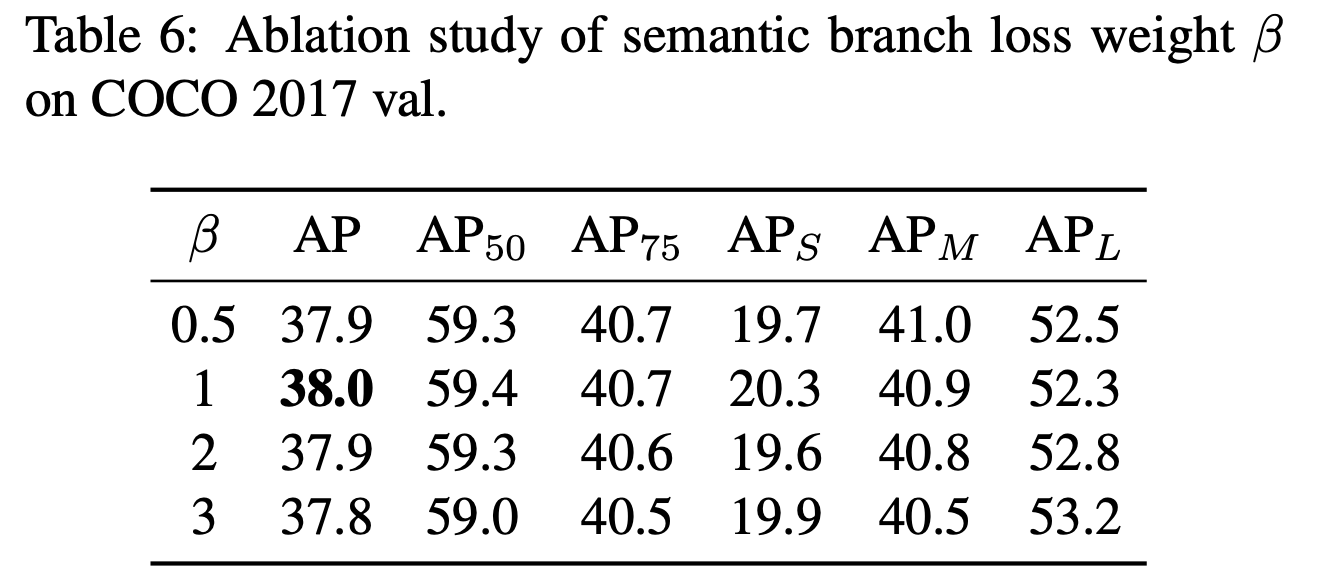
- Ablation Study : Influence of Loss Weight
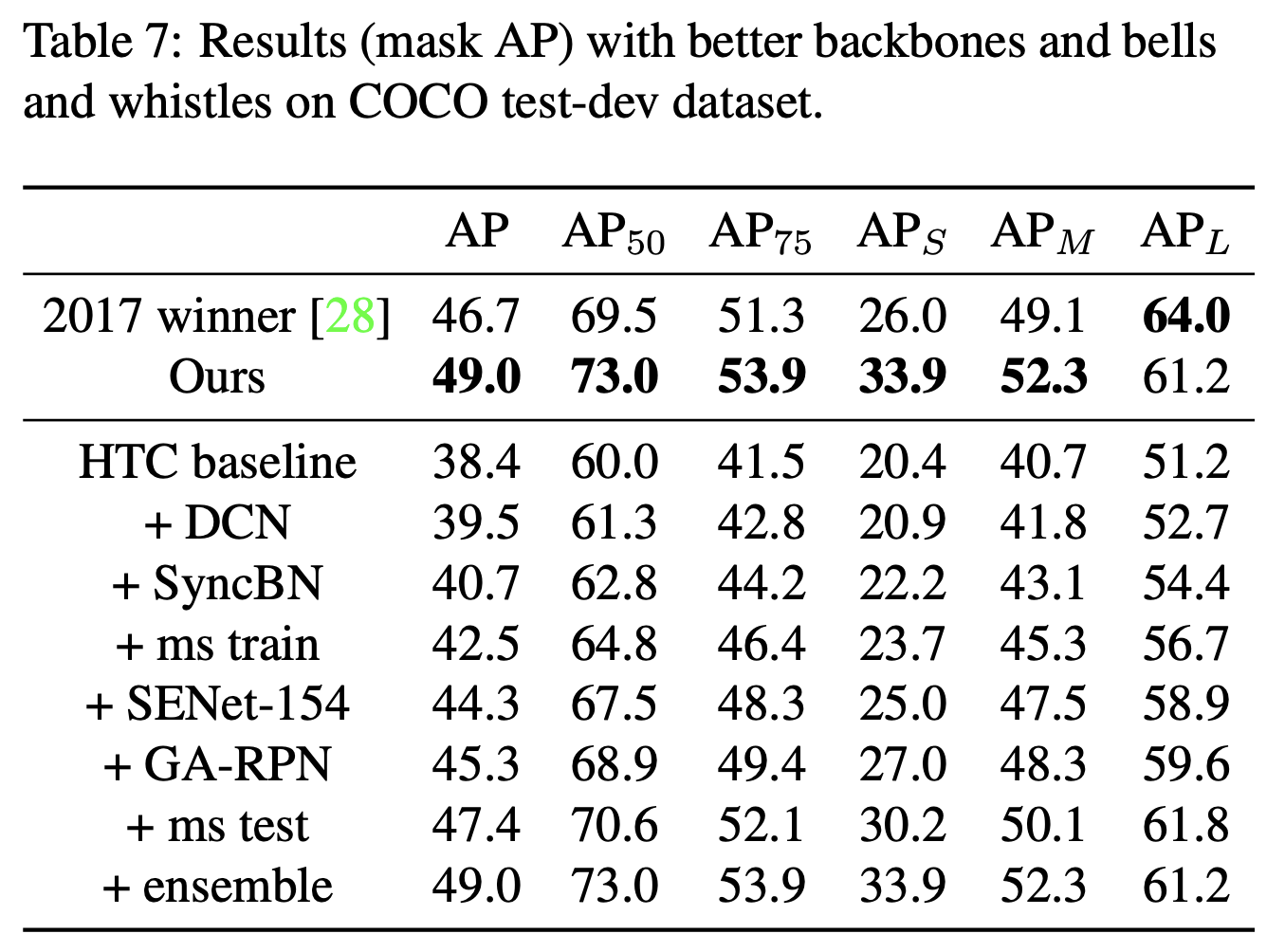
- Extensions on HTC
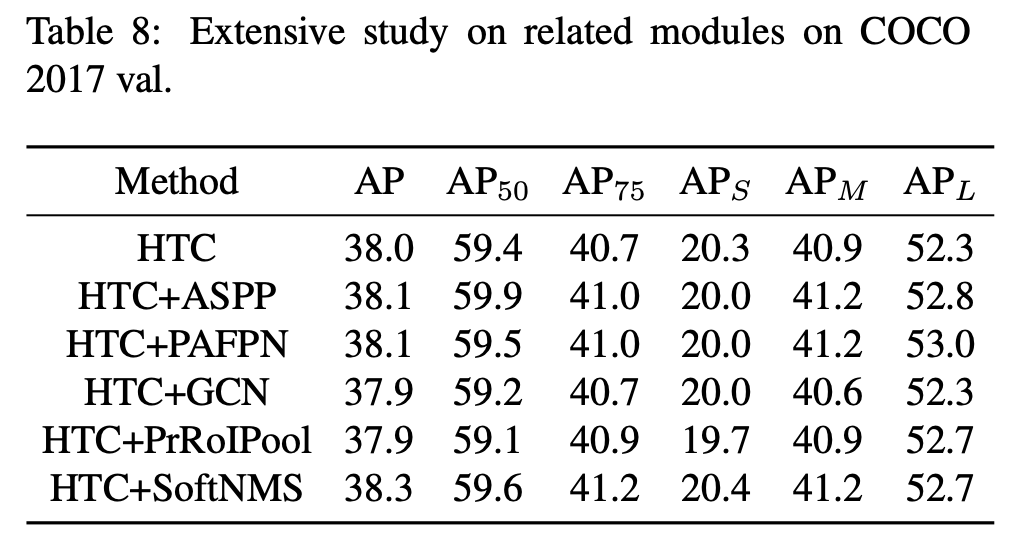
- Extensive Study on Common Modules
5. Conclusion
- 논문에서는 instance segmentation을 위한 새로운 cascade architecture인 Hybrid Task Cascade(HTC)를 제안했다.
- joint multi-stage processing을 위해 box와 mask branch를 서로 엮었고, spatial context를 제공하기 위해 semantic segmentation branch를 추가했다.
- MSCOCO dataset에서 Cascade Mask R-CNN보다 약 1.5% 높은 성능을 얻었고, 제안한 전반적인 시스템은 test-challenge와 test-dev에서 각각 48.6%와 49.0 mask AP를 기록했다.
