Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation
Computer Vision
Abstract
본 논문은 이미지에 랜덤하게 object를 paste하는 instance segmentation을 위한 Copy Paste 연구에 관한 내용이다.
기존에는 visual context를 파악하고 copy paste를 적용했지만, 본 논문에서는 간단하게 object를 무작위로 copy paste하는 것만으로 충분히 성능을 향상 시킬 수 있음을 확인했다.
추가적으로 semi-supervised learning에 있어서 도움이 된다는 것을 확인했다.
본 논문에서 제안하는 방법론으로 기존 COCO 이외에도 LVIS 데이터 셋에서 성능 향상을 얻을 수 있었다.
1. Introduction
기존에는 scale jittering이나 random resizing augmentation 방법들이 있지만, 이는 instance segmentation을 위해 design된 방법은 아니다.
category 및 shape 측면에서 객체를 더 잘 인식하는 augmentation 절차는 instance segmentation에 유용할 수 있습니다. 그리고 copy paste augmentation은 다양한 object를 여러 스케일로 배경에 붙이면서 이를 만족할 수 있다.
copy paste는 다음을 어떻게 선택하느냐에 따라서 다양한 학습 데이터를 생성할 수 있다.
(1) source, target image 선택
(2) source 이미지에 존재하는 object 선택
(3) target 이미지에 어느 위치에 붙일지 선택
본 논문에서는 대상 이미지의 랜덤 위치에 객체를 무작위로 copy paste하는 간단한 전략이 backbone 구조의 다양성, scale jittering의 확장성, 학습 schedule과 이미지 사이즈와 같은 여러 설정에 걸쳐 성능 향상시킬 수 있다고 주장한다.
또한, copy paste augmentation을 적용했을 때, self-training 효과를 얻을 수 있다고 주장한다. 여기서 본 논문의 저자는 gt data로부터 instance를 추출하고, unlabeled data에 대해서 유사 label로 annotation 했다.
2. Related Work
Data Augmentations
Data Augmentation은 backbone architecture나 detection/segmentation frameworks에 비해 상대적으로 적은 관심을 받고 있다.
기존에는 random crop, color jittering, Auto/RandAugment와 같은 Data Augmentation들이 ImageNet Benchmark에서 image classification, self-supervised learning, semi-supervised learning task에 sota 달성에 큰 역할을 했다.
이러한 증강들은 주로 image classification에 적합한 원칙인 데이터 변환에 불변성을 인코딩하는데 사용된다.
Mixing Image Augmentation
데이터 변환에 불변성을 인코딩하는 augmentation과는 다르게, 서로 다른 이미지에 포함된 정보를 gt label로 적절하게 변환하는 augmentation class가 있다.
대표적인 예로 mixup data augmentation이 있고, 전체 픽셀을 사용하지 않고 일부를 crop하여 mixup augmentation을 적용한 CutMix라는 방법도 사용되고 있다. 추가적으로 yolov4에서 사용된 mosaic data augmentation 방법도 있는데, 여러 개별 이미지들과 해당 gt들을 함께 사용하여 혼합된 하나의 이미지를 만든다는 점에서 CutMix와 관련이 있다.
그러나 여전히 object-aware한 instance segmentation에 특화된 augmentation 방법은 없었다.
Copy-Paste Augmentation
Copy Paste는 mixup이나 CutMix 방법과 매우 유사하지만, bounding box내에 존재하는 모든 픽셀이 아닌 object에 해당하는 정확한 픽셀 영역만 복사하는 부분에 있어서 차이가 있다.
기존의 Contextual Copy-Paste나 InstaBoost와는 달리 본 논문에서 제안하는 방법은 복사한 instance 객체를 배치하기 위해 visual context를 모델링할 필요가 없다.
본 연구의 차이점은 다음과 같다.
-
geometric transformation(e.g. rotation)을 사용하지 않고, Gaussian blurring을 instance에 적용하는 것은 효과적이지 않으므로 사용하지 않는다.
-
이미지에 포함된 instance를 이미 instance와 배경이 존재하는 다른 이미지에 Copy Paste를 적용함으로써 성능 향상시키는 연구를 한다.
-
semi-supervised learning 환경에서 self-training과 함께 사용하여 Copy Paste의 효과를 연구한다.
-
COCO, LVIS dataset을 대상으로 benchmark한다.
Long-Tail Visual Recognition
최근, computer vision 분야에서는 자연 이미지에 존재하는 object category의 long-tail 특성에 집중하고 있다.
deep network를 학습할 때 long-tail data를 다루는 현대적인 접근 방식은 주로 data re-sampling, loss re-weighting이 있다. 그리고 다른 관련 learning method들(e.g. meta-learning, causal inference, Bayesian methods, etc.)도 있다.
최근 연구에서는 end-to-end 학습에서 re-balancing 전략은 feature learning에 해로울 수 있기 때문에 feature learning과 re-balancing stage를 나누어서 진행하는 two-stage 전략을 주장한다.
본 논문에서는 Simple Copy-Paste data augmentation이 LVIS benchmark에서 특히 희귀한 object category에 대해서 single-stage와 two-stage 학습에 상당한 이득을 줄 수 있다고 주장한다.
3. Method
Copy Paste는 먼저, 2개의 이미지를 랜덤하게 선택하고, 각각에 대해서 random scale jittering과 random horizontal flipping을 적용한다. 그러고 나서 하나의 이미지로부터 객체들의 부분 집합을 선택하고 다른 이미지에 붙여넣는다. 마지막으로 gt annotation들을 조절한다. 여기서, 완전히 occlude된 객체를 제거하고, occlude된 mask와 bbox를 업데이트한다.

Blending Pasted Objects
본 논문에서는 새로운 object를 이미지에 구성할 때 binary mask(a)로 gt annotation과 이미지를 계산했다. 식은 다음과 같다.
본 논문에서는 pasted object의 경계를 smooth하기위해 Gaussian Filter를 a에 적용했는데 실험 결과, blending을 적용하지 않은것과 큰 차이가 없음을 알 수 있었다.
Large Scale Jittering
본 논문에서는 Copy Paste 이외에 SSJ(Standard Scale Jittering)과 LSJ(Large Scale Jittering)을 사용한다.

본 논문 저자는 이전 연구들을 실험했을 때, SSJ에 비해 LSJ를 사용했을 때 훨씬 성능이 좋았다고한다.
Self-training Copy-Paste
본 논문에서는 supervised data에 대해서 Copy-Paste를 적용하는것 이외에도 unlabeled image를 통합하는것에 대해서 실험을 진행했다. 실험은 다음과 같이 진행했다.
(1) label된 supervised data에 대해서 Copy-Paste와 함께 학습한다.
(2) unlabeled data에 대해서 유사 label을 생성한다.
(3) gt instance를 유사 label와 supervised label된 이미지에 대해서 새로 모델을 학습한다.
4. Experiments
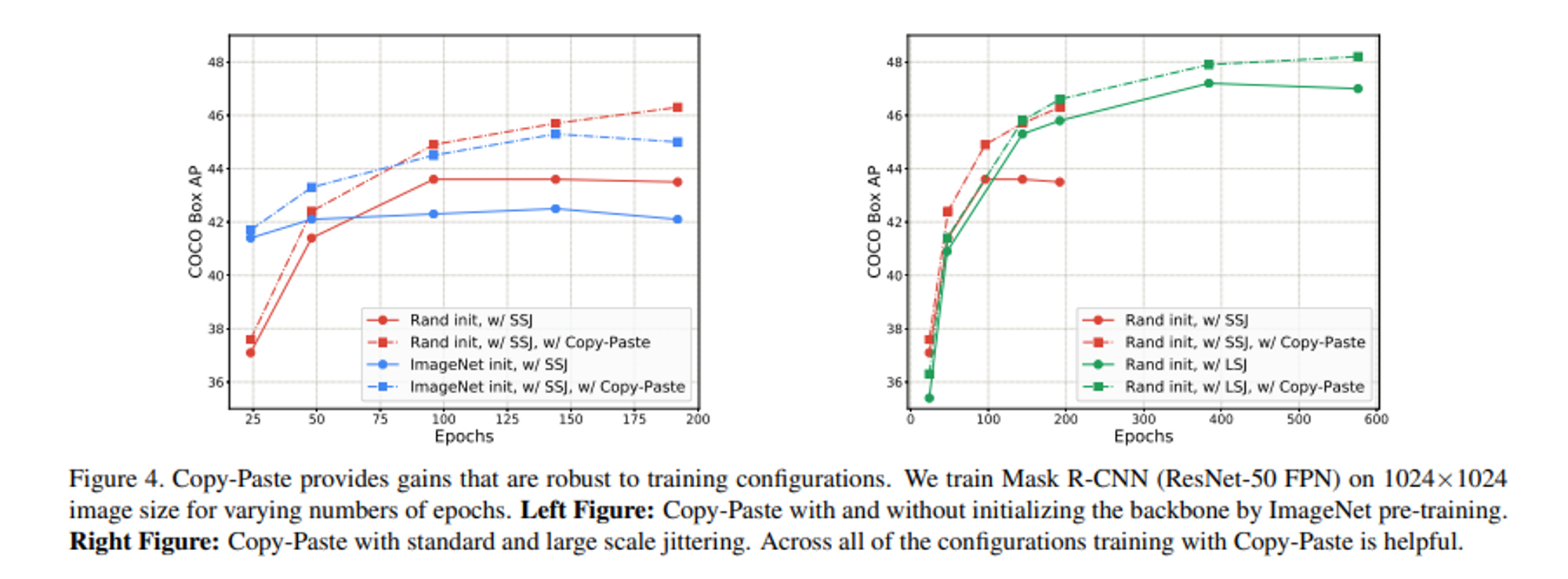
- ImageNet Pretrained Model을 사용한 것보다 장기적으로 Random Initialization Model을 사용했을 때 장기적으로 학습시에 더 효과적이다. 그리고 Copy Paste를 함께 적용했을 때 최적 결과를 도출했다.
- SSJ과 LSJ를 비교한 결과, LSJ를 적용했을 때 더 장기적인 학습 측면에서 유리하고, 성능이 더 높다. 그리고 Copy Paste를 함께 적용했을 때 더 성능 향상되었다.
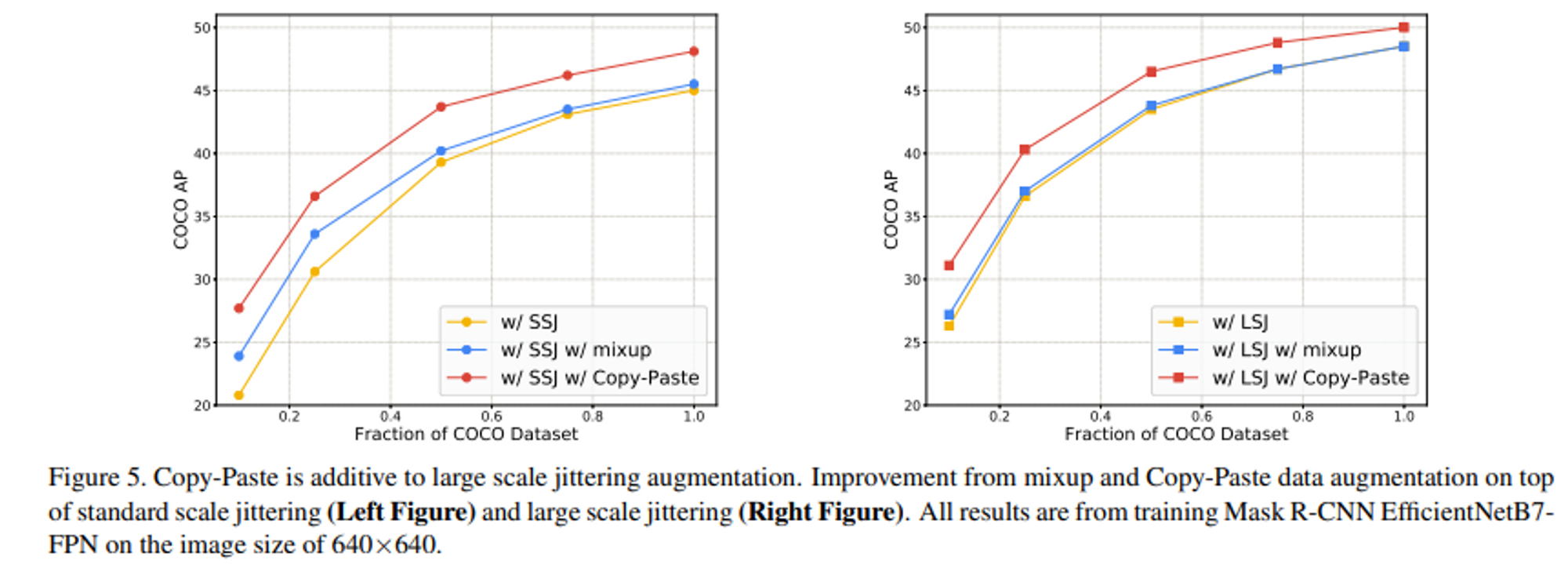
- SSJ와 LSJ에 대해서 각각 mixup과 Copy-Paste를 적용한 결과, mixup은 성능향상에 도움이 되지 않았고, Copy Paste는 모두 성능 향상 시켰다.
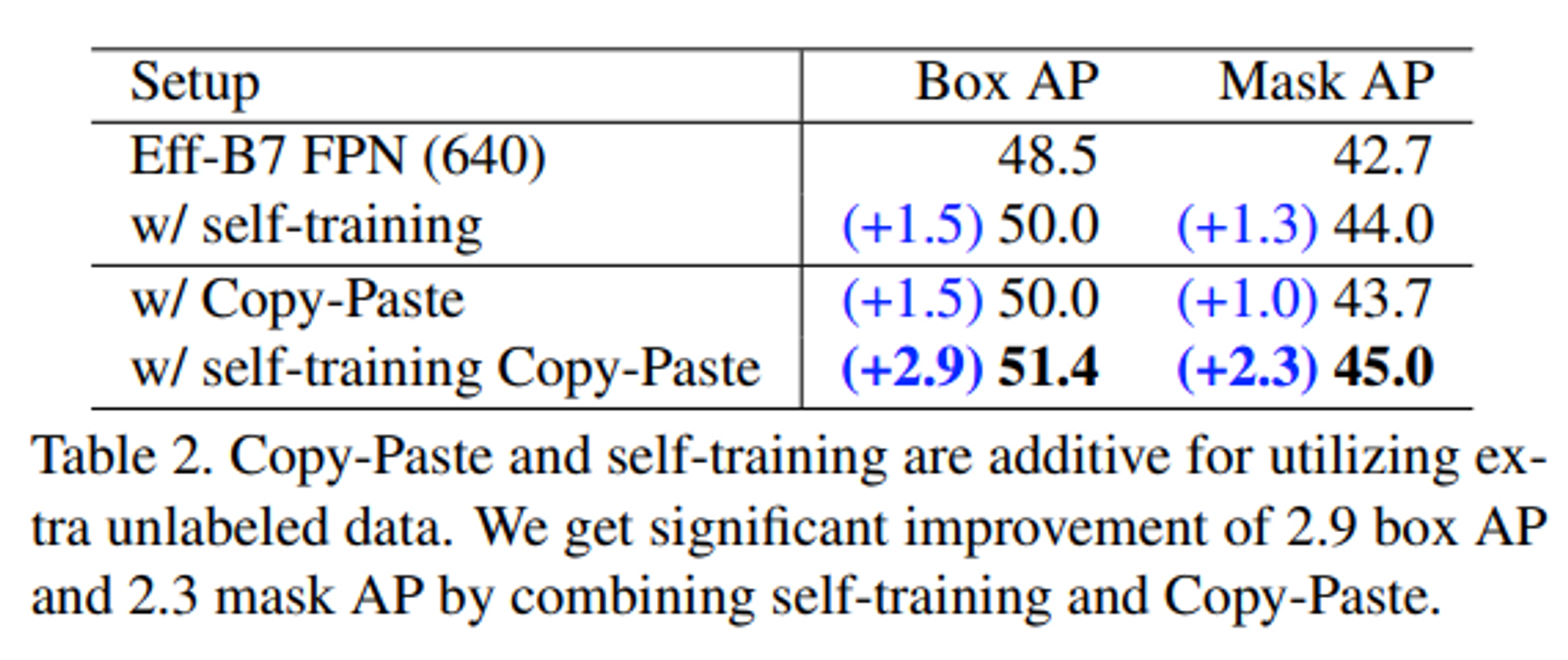
- Self-Training & Copy Paste 적용으로 인한 성능 향상 결과
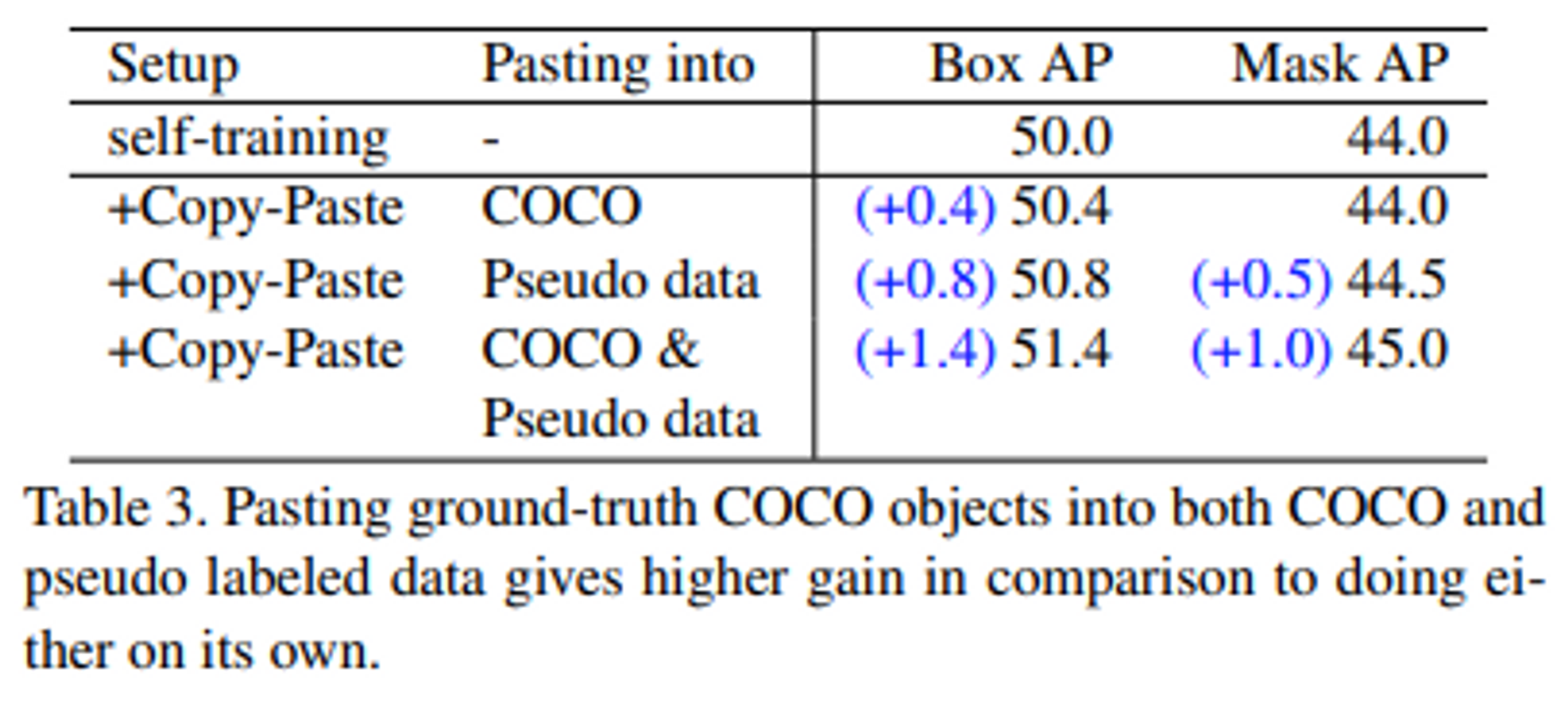
- Self-Training & Copy Paste 적용으로 인한 성능 향상 결과
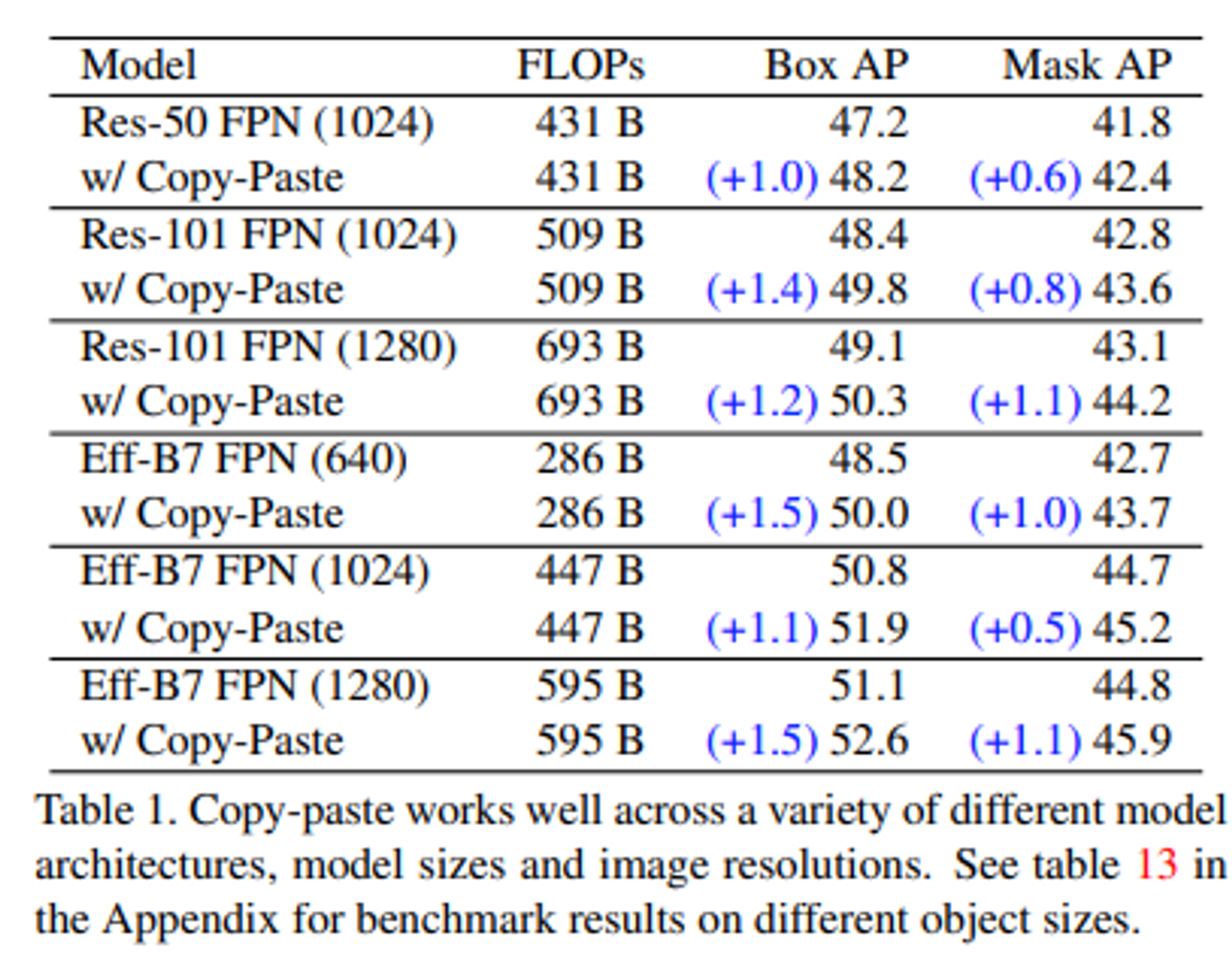
- Copy Paste 적용으로 인한 성능 향상 결과
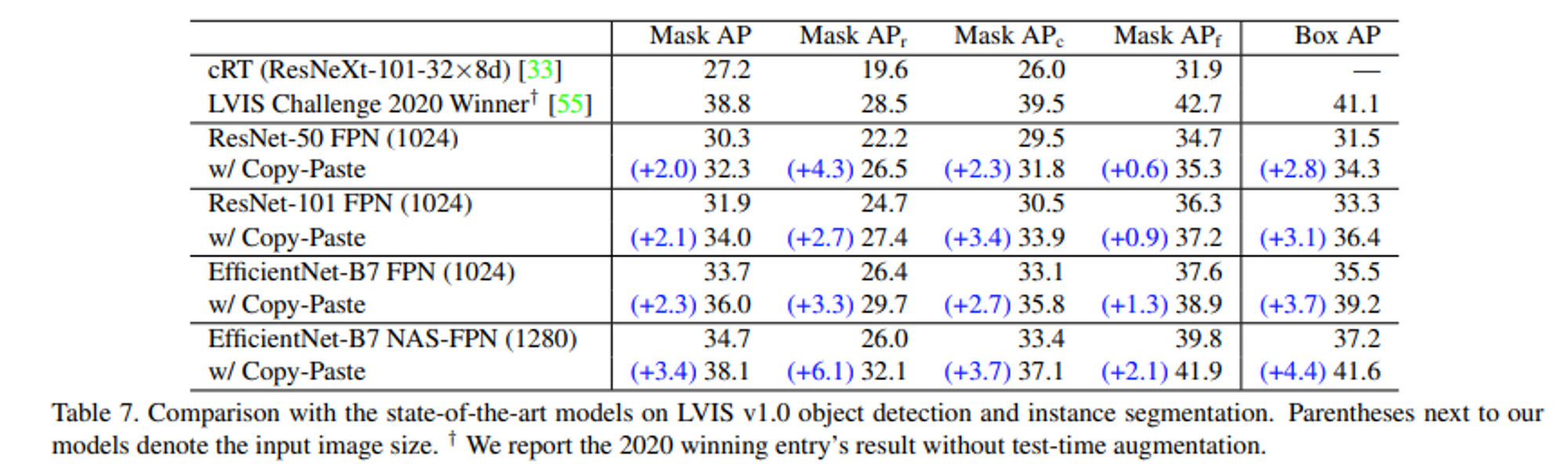
- SOTA의 LVIS 데이터 셋 모델에 대해서 Copy Paste 적용에 의한 성능 향상 결과

- Single-stage와 Two-stage 학습 전략에서 RFS와 Copy Paste를 통한 성능 향상 결과
Two Stage 학습 전략
- Single-Stage 학습과 동일하게 모델 학습
- Class Balanced Loss로 Fine Tuning
- 모델에 대해서 3xschedule 적용 및 classification loss를 통해 마지막 classification layer만 학습
5. Conclusion
- Copy Paste는 다양한 실험적 세팅과 COCO나 LVIS와 같은 baseline에 대해서 잘 수행된다.
- training cost와 inference time을 증가시키지 않고 쉽고 간단하게 적용할 수 있다.
- self-training에서도 효과적임을 알 수 있다.
