High Quality Segmentation for Ultra High-resolution Images
Abstract
사람이 거친 coarse한 level에서 precise level까지 물체를 지속적으로 구분해야된다는 사실에 동기를 부여받고 본 논문에서는 high resolution segmentation refinement task를 위해 Continuous Refinement Model(CRM)을 제안한다.
CRM은 지속적으로 refinement target에 대해서 feature map을 조정하고 image detail을 재구성하기위해 feature를 모은다. 게다가 CRM은 low resolution training 이미지와 high resolution testing 이미지에 대해서 resolution gap을 채우는 일반화 능력을 보여준다.
1. Introduction
카메라나 디스플레이 장비의 성능 향상은 많은 이점을 가져왔지만, segmentation task에서는 어려움을 가져왔다. 먼저, 많은 input pixel은 비싼 계산 비용을 가지고, GPU memory가 많이 필요하게 된다. 그리고 많이 사용되는 upsample method들은 4배에서 8배정도를 interpolation으로 예측하는데, output mask에 대해서 정제된 detail을 가지지 못하는 문제가 있다.
classic segmentation algorithm에서 생성된 low resolution mask를 기반으로 high resolution refinement를 수행하는 작업들의 경우, decoder에서 cascade scheme를 사용하여 target resolution에 도달하기위해 여러 resolution stage에서 중간 refinement result를 upsample한다. 이러한 방법들은 여전히 decoder의 discrete style로 인해 시간이 소요된다. 대신 본 논문에서는 decoding을 좀 더 효율적이고 upsampling resolution의 학습에 더 우호적이게 만들기 위해 연속성을 고려한다.
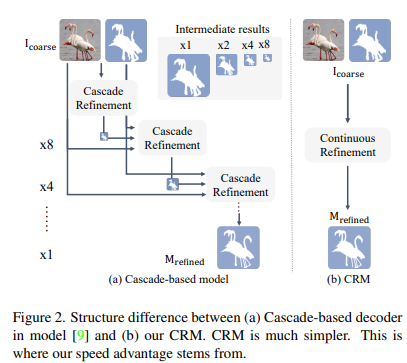
CAM에서는 feature의 좌표와 refinement target을 연속 공간으로 전달한다. 그리고 연속 좌표를 기반으로 좌표와 feature를 정렬한다. implicit function은 segmentation label을 추론하기 위해 위치 정보와 정렬된 잠재 이미지 feature를 결합한다. 결론적으로 이러한 design은 cascade 기반 decoder보다 쉽고 가볍지만, 정확한 refinement mask를 생성한다.
한편, cascade 기반 방법의 경우 convolution을 사용하여 고정된 크기의 patch를 다루게 되어 다른 test resolution에서 일반화가 감소된다. 이와는 반대로 CRM은 이러한 bias없이 feature를 가진다.
또한, multi resolution inference 전략에서 low resolution input에 대해서 먼저 추론하고, refined mask에서 좀 더 detail을 생성하기 위해 input resolution을 증가시키면서 이전 방법들보다 더 강력한 일반화 능력과 inference speed를 보인다.
추가적으로 CRM은 특히 high resolution image에서 좋은 segmentation 결과를 얻었는데, fine tuning 없이 SOTA의 panoptic segmentation model의 성능을 올리는데 도움이 된다.
2. Related Work
2.1 Semantic Semgentation
PSPNet, DeepLab 시리즈 모델과 이외의 모델들은 4배 또는 8배의 output stride를 갖는데 이는 정확도를 감소시킨다. 이와 대조적으로 CRM은 임의의 target resolution에 대해서 연속적으로 feature를 정렬함으로써 시각적으로 자연스럽고 detail을 재구성한다.
2.2 Segmentation Refinement
Cascade 기반 방법은 cascade network 구조와 전역-지역 patch 기반 refining pipeline을 통해 ultra-high resolution 이미지에서 sota refinement 성능을 보였다. 하지만, decoder의 무거운 cascade structure로 인해 down sampling과 cropping patch가 필요하게 되어 추론시에 많은 cost가 필요하게되고 detail과 global context를 잃게 된다.
이러한 문제를 해결하기위해 CRM은 refinement target에 대해서 연속적으로 feature map을 정렬한다.
2.3 Implicit Function for Representation
초기에 implicit function은 연속적인 좌표와 특징을 좌표에 있는 label에 매핑하는 신경망의 object나 scene을 나타내도록 설계되었다. 예를 들어, NeRF는 3D 좌표 및 2D 시야각을 RGB와 특정한 시야에서 정확한 위치의 투명도에 매핑한다. PixelNerf는 FCN 방식으로 이미지 입력에 NeRF를 조건화하는 구조를 도입하여 장면 인식 모델링을 실현했다. 게다가 그것의 상대적인 카메라 자세 아이디어는 상대적인 위치 정보를 사용하기 위한 연구에 영감을 준다.
본 논문에서는 implicit function을 연속적으로 feature map을 final mask가 될때까지 upsample하기위해 사용했다.
3. Proposed Method
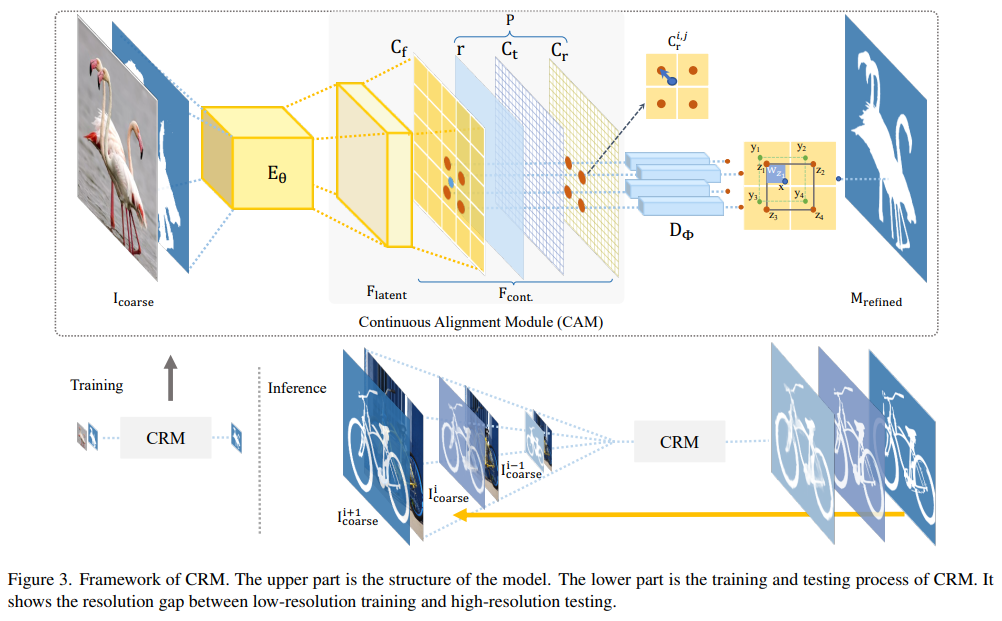
3.1 General Framework
CRM은 3xHxW의 이미지와 1xHxW의 coarse segmentation mask를 input으로 받는다. 먼저, 4xHxW로 concatenate한 다음 Encoder를 통해 Cxhxw 사이즈로 latent embedding을 적용한다.
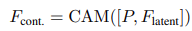
그리고 latent embedding 결과()와 position information(P)에 대해서 계속해서 target size((C+6)xHxW)로 align한다. 여기서, [.,.]는 concatenation을 의미한다.
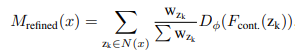
마지막으로 은 implicit function 기반 decoder와 feature aggregation step으로 전달되고, refine Mask인 을 생성한다. 여기서, x는 aligned point이고, N(x)는 x의 supporting points , k ∈ {1, 2, 3, 4}의 집합을 나타낸다. 는 x가 중심이 되는 x와 사이의 상자 면적 값을 대칭으로 바꾸기위한 aggregation weight를 의미한다.
3.2 Continuous Alignment Module
Position Informtion
Coordinates of refinement target()는 feature map coordinates()에 투영된다. 이 operation은 다른 resolution feature map과 다양한 inference resolution을 위해 지속적인 좌표를 생성한다.
absolute coordinate는 이미지 및 feature map size에 따라 달라질 수 있기 때문에, CRM을 임의의 크기에 보편적으로 만들기 위해 와 는 [-1, 1]의 범위로 normalize한다.
투영한 뒤에 와 사이의 offset을 로 나타낸다. relative target 좌표 offset , feature와 target사이의 ratio인 r 그리고 refinement target position 는 position information P를 형성한다. continous position information은 CRM에 있는 continuity의 bais이다.
Continuous Feature Alignment
refinement target position 는 global feature로 생각할 수 있고, 위치 정보와 마찬가지로 refinement target의 각 픽셀을 로 정렬할 수 있다. 그리고 는 위치 정보 P와 정렬된 를 연결해서 얻을 수 있다. 따라서, CRM은 upsampling process를 제한하지않으면서 larger space에서 더 높은 성능을 보이고 최적화할 수 있다.
3.3 Implicit Function in CRM
CAM을 적용하고 나서 는 를 input으로 받는다. Figure 3에서 target refinement mask에 있는 queried point(blue point)는 x(i, j)로 표현할 수 있다. 이를 처리하기 위해 먼저, Figure 3에서 green point로 표현된 이웃하는 point 를 찾는다. 그 다음, 에 가장 가까운 point인 Figure 3에서 redpoint로 표현된 는 aligned feature map에서 선택된다.
그리고나서 ()를 implicit function 에 입력한다. 여기서, 는 5-layer MLP로 6+256 channel coordinates와 feature를 1 channel mask로 매핑한다.
마지막으로 implicit function의 output을 모은다. aggregation weights()는 relative coordinate offsets 에 의해 계산된다. aggregated output은 (i, j)의 마지막 추론 결과이다.
Analysis
CRM과 Cascade의 주요 차이점은 decoder 부분이다. CRM은 2x2 convolution 대신 MLP와 area 기반 average를 사용했기때문에 CRM은 더 큰 feature space를 가지게 되고, 4 point가 서로 다른 class에 속했을때 더 큰 feature space를 가진 CRM이 Cascade보다 분석에 유리하게 된다.
3.4 Training and Inference Strategy
Training without Cascade
큰 이미지에 대해서 annotation된 train dataset은 적기때문에 본 논문에서는 CascadePSP의 방법에 따라 초기에 low resolution image를 사용한다. 는 제공된 에 대해서 morphological pertubation을 적용하여 생성한다.
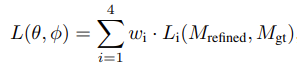
본 논문에서 사용된 Loss는 위와 같다. 여기서, 는 각각 cross entropy, L1, L2, gradient loss를 뜻한다. 그리고 는 이에 대응하는 weight들이다. (θ, ϕ)는 각각 encoder와 decoder의 파라미터를 의미한다.
Inference Strategy
training resolution과 test resolution의 격차를 메우기 위해 본 논문에서는 CRM의 continuous P와 aligned 에 대해서 multi resolution inference를 제안한다.
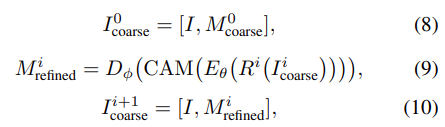
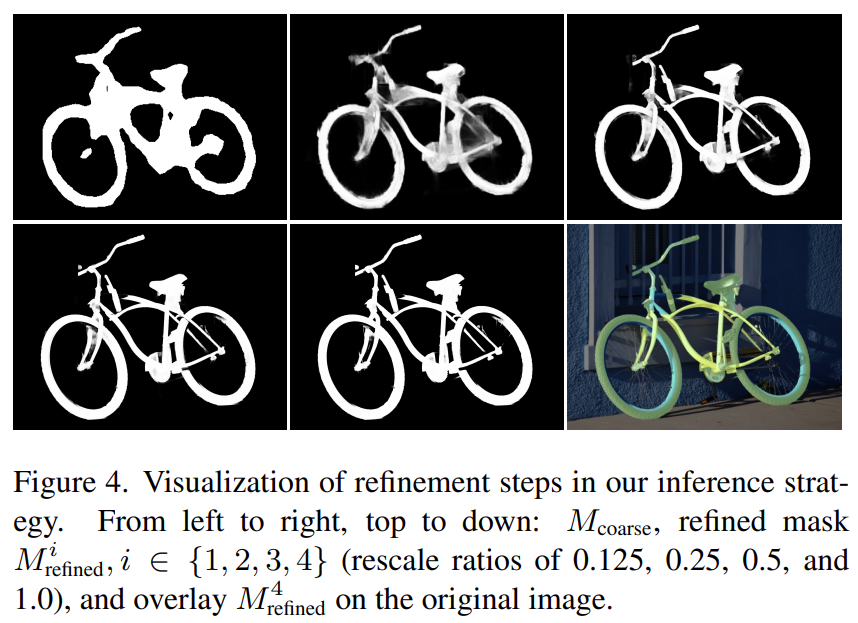
inference는 먼저 훈련 이미지의 resolution을 중심으로 하고, continuous ratio 축인 를 따라 점진적으로 input resolution을 증가시킨다. 특히, original ultra high resolution image I와 coarse mask (초기 stage)나 이전 stage의 refined mask 을 concatenate한다. 여기서, 은 의 rescale function이고, i는 refinement stage를 의미한다. multi-resolution inference를 사용했을 때 CRM의 전체 refinement process는 CascadePSP보다 적어도 2배는 빠르다.
4. Experiments
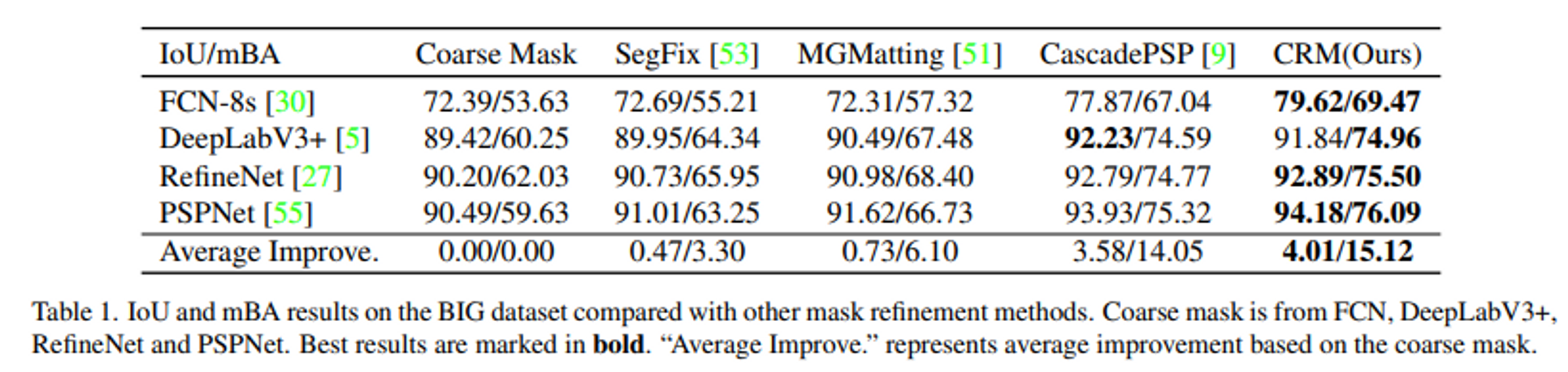
- BIG dataset 기반 refinement 성능 비교 결과
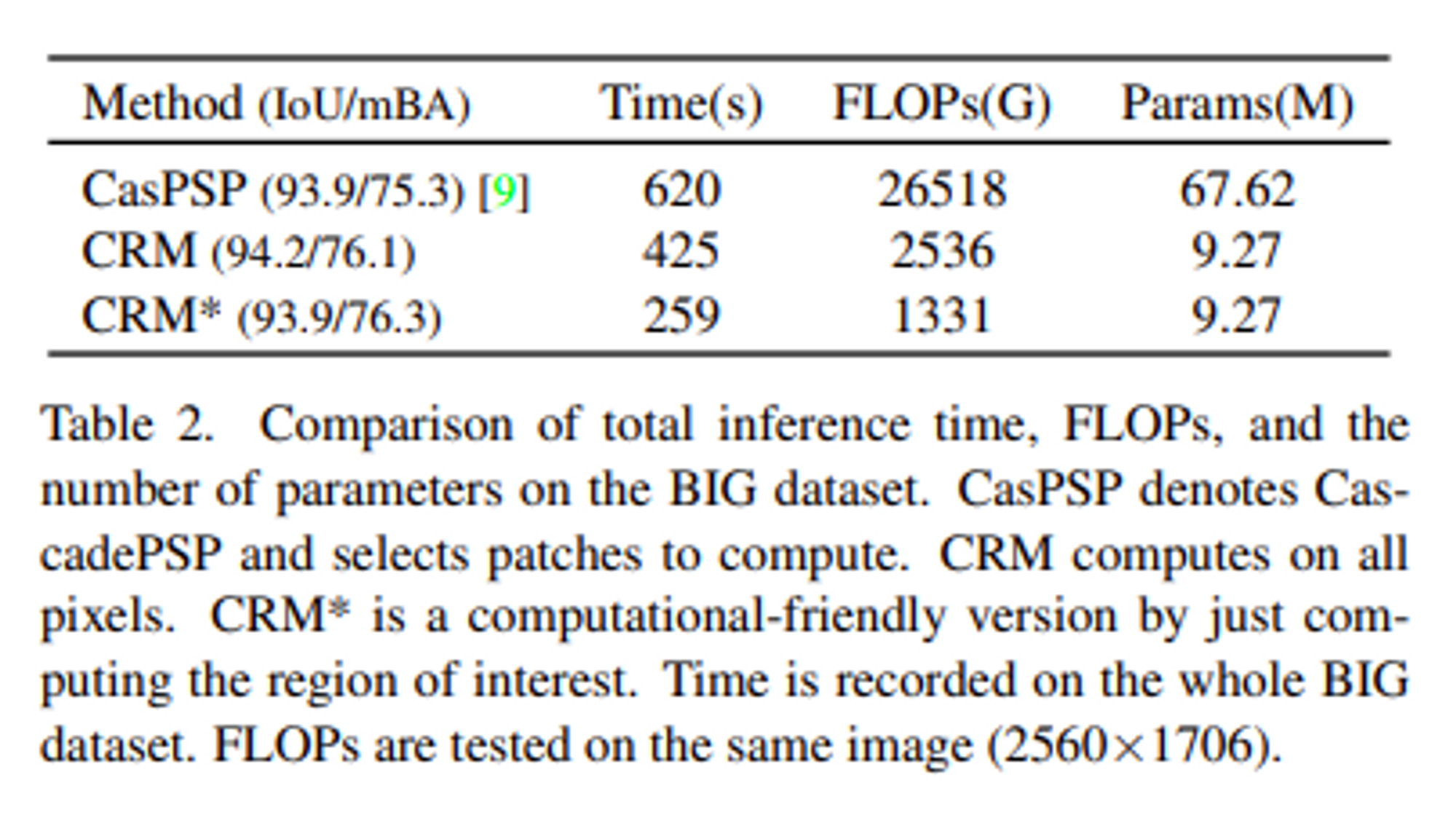
- CascadePSP, CRM 성능 비교 결과
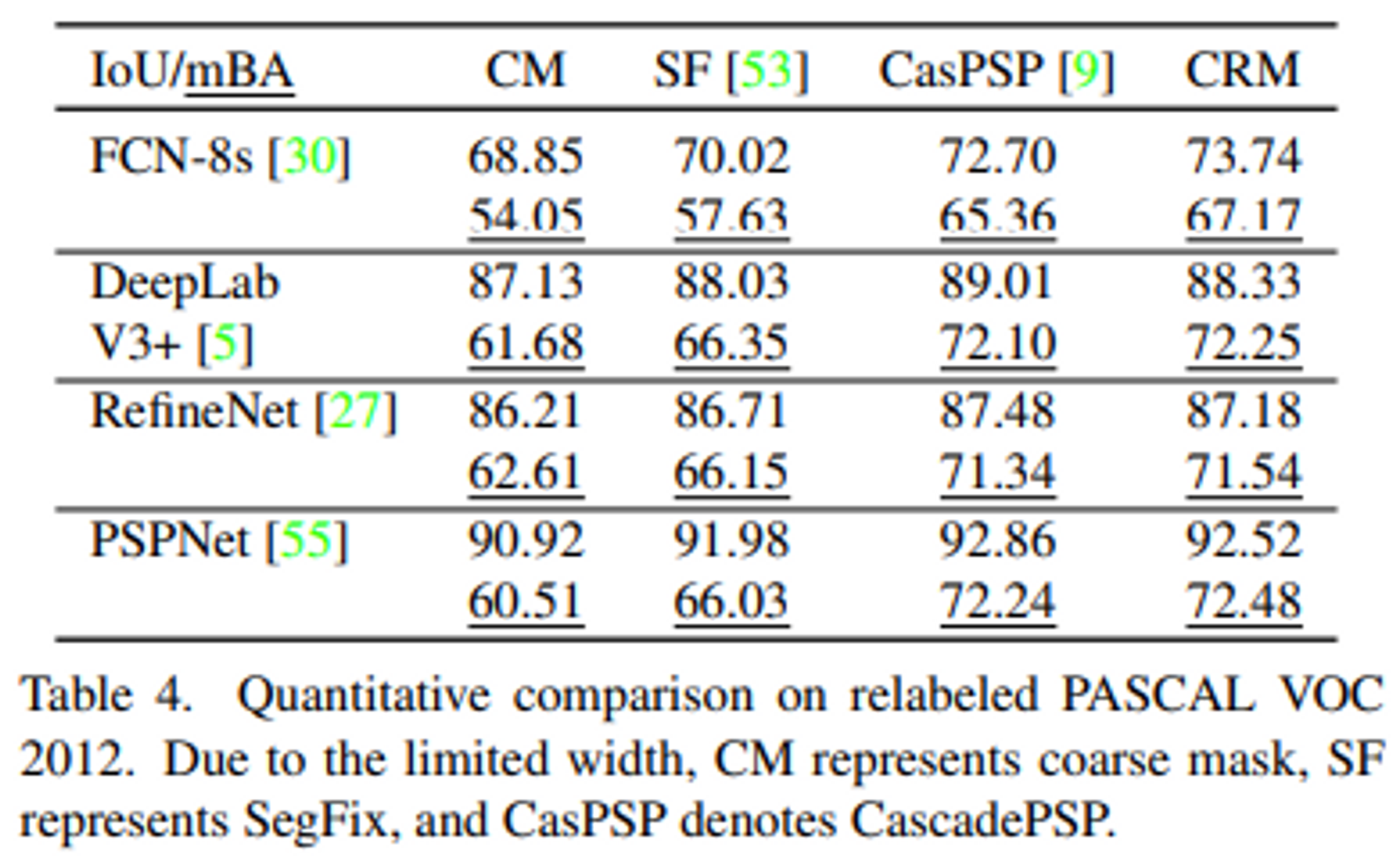
- Refinement Method 성능 비교 결과

- 정성적 평가 결과(1)

- 정성적 평가 결과(2)

- Ablation Study 결과
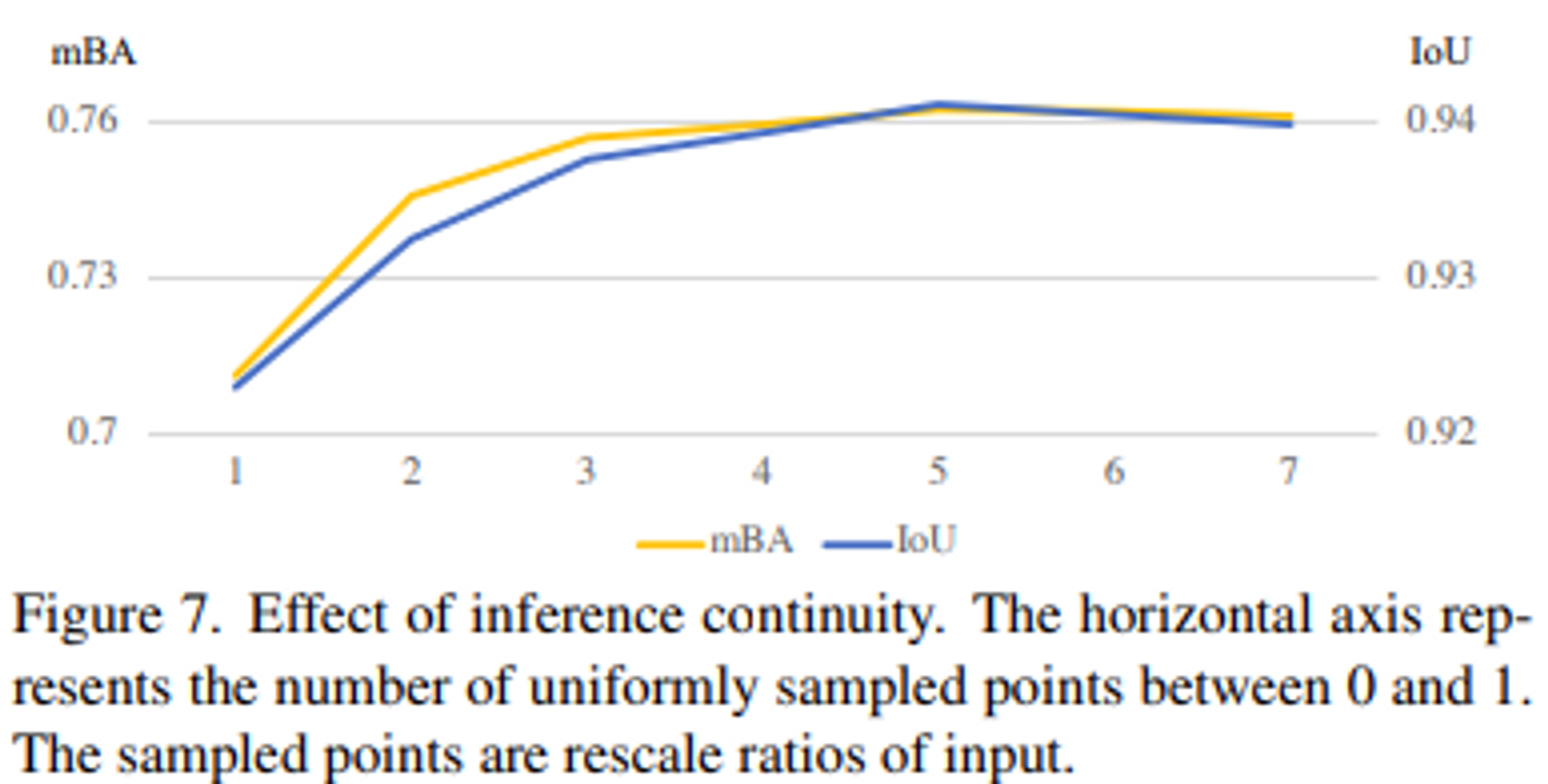
- Inference’s continuity의 효과
5. Conclusion
CRM은 연속적으로 feature map을 정렬하고, high resolution mask에서 detail을 재구성하기 위한 aggregate feature를 돕는다. 게다가 CRM은 low resolution에도 일반화 잠재력을 보인다.
Limitations
현재는 low resolution에서 학습하고, high resolution에서 test하는 형태로 사용했는데, 아직 ultra high resolution image에서 학습에는 resource에 한계가 있다.
