Look Closer to Segment Better : Boundary Patch Refinement for Instance Segmentation
Computer Vision
Look Closer to Segment Better : Boundary Patch Refinement for Instance Segmentation
Abstract
instance segmentation에 대한 연구는 계속되고 있지만, 아직 mask quality에 대한 연구는 부족하다. 특히 추론된 instance mask의 boundary는 low spatial resolution의 feature map과 boundary pixel의 low proportion으로 인한 imbalance 문제로 인해 부정확한 결과를 낳는다.
본 논문에서는 이러한 문제를 해결하기 위해 small boundary를 extract and refine하여 boundary quality를 향상시키는 BPR을 제안한다. 그리고 BPR은 boundary patch refinement network를 higher resolution에서 수행하였다.
최종적으로 Cityscapes benchmark에서 Mask R-CNN에 대해서 좋은 성능을 보였고 특히 boundary aware metric의 성능이 좋아졌다. 또한 BPR framework를 PolyTransform + Segfix에 대해서 적용한 결과 SOTA의 Cityscapes leaderboard에서 1st를 당설했다.
1. Introduction
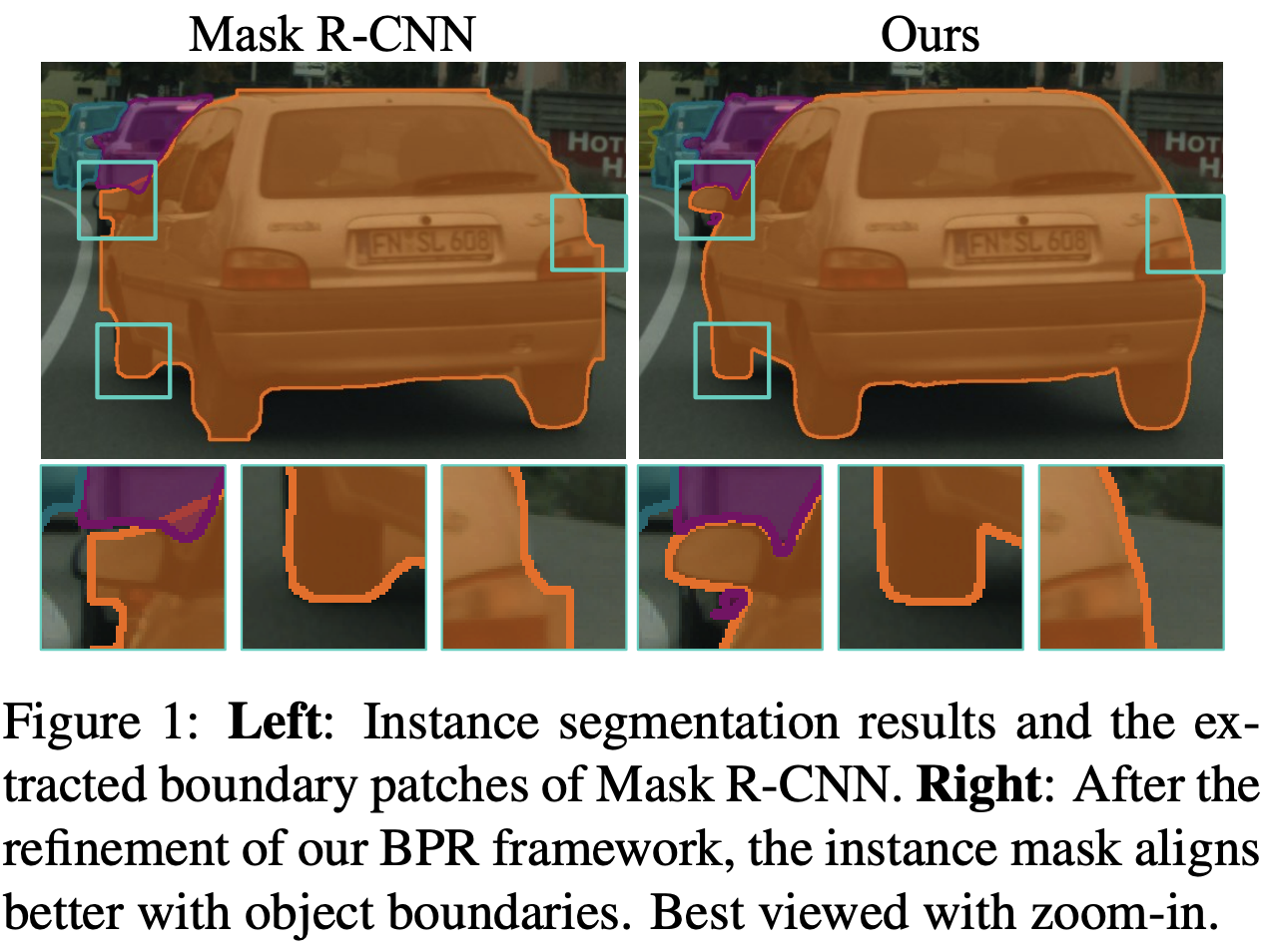
최근 instance segmentation분야에서 Mask R-CNN과 이를 기반으로한 모델들이 좋은 성능을 보이고 있다. 하지만, 추론된 instance mask의 quality는 여전히 부족하다. 그중에서 가장 중요한 문제중 하나는 instance boundary에 대한 부정확한 segmentation이다.
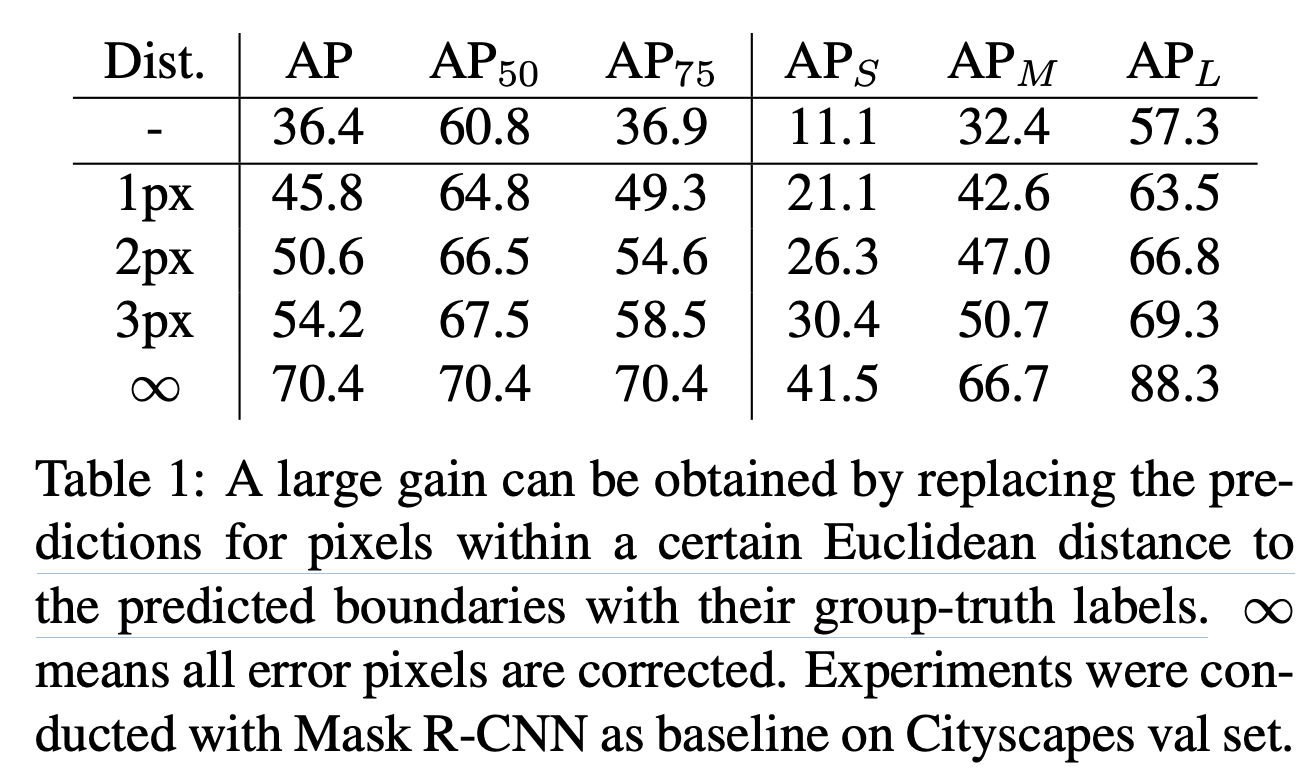
본 논문에서는 Mask R-CNN 기반으로 추론된 instance mask에 대해서 특정 유클리드 거리(1px/2px/3px)의 boundary pixel을 ground truth로 대체함으로써 높은 성능을 얻을 수 있음을 실험을 통해 증명했다.
본 논문은 low quality boundary segmentation을 야기하는 두가지 심각한 issue에 대해서 언급한다.
-
low spatial resolution of the output(e.g. Mask R-CNN : 28 x 28, One Stage Framework : 적어도 input resolution의 1/4)
-
object boundary에 존재하는 pixel은 오직 전체 이미지에서 작은 부분을 차지해서 분류하기 어렵다. (1% 미만)
dense prediction task의 오랜 challenge로써 많은 연구가 있었다. PolyTransform은 polygon 좌표의 offset을 예측하기위해 instance patch를 crop하는 변형된 network를 사용했지만, 큰 계산비용이 소요되었다. 그리고 SegFix는 coarse prediction의 boundary pixel을 내부 추론 결과로 대체했지만, 정확한 boundary 추론 결과에 의지하는 경향이 있다.
본 논문은 annotation하는 사람 행위에 기반하여 이와 유사하게 crop and refine 전략을 사용했다. 먼저, 추론된 small boundary patch를 crop한 뒤, concatenate하여 refinement network에 입력하여 high quality를 가지도록 refine된 binary segmentation mask를 얻는다. 제안된 framework를 BPR로 명시했다.
제안한 방법은 mask quality를 높이기 위해 어떠한 수정이나 모델에 대한 fine tuning이 필요없다. (model-agnostic) 또한, object의 boundary를 crop해서 사용하기 때문에 다른 모델들에 비해서 더 높은 resolution으로 처리할 수 있어 low detail을 더 잘 얻을 수 있다.
2. Related Work
Instance Segmentation
Instance Segmentation은 one-stage와 two-stage로 나눌 수 있다.
two-stage는 대표적으로 Mask R-CNN이 있는데, 먼저 이미지내에 존재하는 object를 검출한다음 bounding box에 대해서 binary segmentation을 수행하는 방식을 사용하고 특히 Mask R-CNN, PANet은 bottom-up path augmentation을 통해 feature를 강화시켰다. Mask Scoring R-CNN은 추가적인 mask-IoU head를 통해 mask prediction을 re-score했다.
one-stage는 detect then segmentation 전략을 사용했는데, 여기서 detector 부분을 one-stage로 대체했다. YOLACT는 prototype의 집합을 학습함으로써 real-time을 달성했는데, 여기서 prototype은 학습된 선형 계수로 조합된다. BlendMask는 attention map을 조합하여 이러한 아이디어를 더 발전시켰다. 또 다른 연구로는 detection의 필요성을 없애고 segmenting object를 직접적으로 하는 것들이 있다. 이와 관련해서 CondInst와 SOLOv2가 있다. 또한 semantic segmentation 결과에 대해서 픽셀 별 embedding을 학습한 뒤, cluster를 적용하여 instance segmentation을 구현한 연구도 있다. 이외에도 pixel-wise instance representation을 contour-based representation으로 대체한 연구도 있다.
Semantic Segmentation
semantic segmentation 분야는 대부분 FCN(Fully Connected Network)으로 구현되며, dilated/atrous convolution을 통한 feature map의 resolution 증가나 풍부한 context information, encoder-decoder 구조 사용 또는 refinement schemes를 통해 segmentation result를 향상시키는 많은 연구가 진행되었다. 본 논문에서는 HRNet을 사용하여 high-resolution representation을 유지할 수 있도록 하였다.
Boundary Refinement for Segmentation
최근 boundary refinement 관련 연구는 boundary를 처리하기 위한 특출하고 전문적인 module을 통합함으로써 boundary-aware segmentation을 디자인하는 것을 목표로한다.
예를들어, BMask R-CNN과 Gated-SCNN은 boundary를 직접적으로 예측함으로써 mask feature의 boundary awareness를 향상시키는 extra branch를 사용했다. PointRend는 신뢰할 수 없는 prediction 결과를 공유된 MLP로 refine하여 반복적으로 feature point를 sample한다.
또 다른 연구로는 segmentation model의 결과에 대해서 후처리 작업을 하는 연구가 있다. 대표적으로 Segfix가 있는데, 이 모델은 신뢰할 수 없는 boundary pixel을 내부 픽셀의 prediction으로 대체하는 대표적인 refinement mechanism이다. 하지만, Segfix는 디테일한 boundary prediction에 의존하는 경향이 있는 문제가 있다.
3. Framework

제안하는 framework는 위와 같다. post processing mechanism으로 일반 인스턴스 모델에 대해서 어떠한 수정이나 fine-tuning없이 추론 결과를 refine할 수 있다.
3.1 Boundary Patch Extraction
먼저, instance mask가 주어지면 mask의 어떤 부분을 refine해야할지 결정해야된다. 이를 위해 본 논문은 예측된 instance boundary를 따라 일련의 patch들을 추출하는 효과적인 sliding-window style algorithm을 제안한다.
구체적으로 bounding box의 중앙 영역이 boundary pixel을 덮는 squared bounding box의 집합으로 조밀하게 할당한다. 그리고 추출된 box들은 많은 겹침이나 중복이 발생하기 때문에 NMS(Non-Maximum Suppression)을 적용한다.
3.2 Boundary Patch Refinement
Mask Patch
binary mask patch를 사용함으로써 instance에 대해서 location guidance와 훈련 가속 효과를 얻을 수 있다. 이는 곧 refinement network가 instance-level semantic을 학습할 필요가 없어지고, 오직 어떻게 hard pixel들을 위치하는지와 올바르게 정제하는지에 대해서만 학습할 수 있게된다. 더 중요한 점은 인접한 instance들은 동일한 boundary patch를 공유하지만, 학습 목표는 서로 완전히 다르게 할 수 있다.
Boundary Patch Refinement Network
refinement network의 역할은 각 추출된 boundary patch에 대해서 binary segmentation을 하는 것이다. 어떠한 segmentation 모델도 사용이 가능하며, input channel은 4이고(3 for the RGB, 1 for the binary mask patch) output channel은 2이다. 그리고 편의상 HRNetV2 모델을 사용하여 input 사이즈가 커져도 효과적으로 high resolution representation을 유지하고 처리할 수 있도록 했다.
Reassembling
refined boundary patch들은 이전 예측 mask를 대체하여 축약된 instance-level mask로 재구성된다. 인접 패치의 겹쳐진 영역의 경우는 출력 logit에 대해서 평균을 취하고, 0.5의 threshold를 적용해서 결과를 합친다.
3.3 Learning and Inference
본 논문에서는 instance segmentation model에 대해서 직접적으로 훈련하거나 fine tuning하지 않았고, BPR을 훈련하는 동안 오직 IOU가 ground truth에 대해서 0.5보다 큰 instance로부터 boundary patch를 추출했다. 그리고 model output에 대해서 이에 상응하는 ground truth mask patch와 pixel-wise binary cross-entropy loss를 적용한다. 학습시에는 NMS eliminating threshold를 0.25로 할당했고, 빠른 처리가 필요한 inference의 경우에는 다른 threshold 값을 적용했다.
4. Experiments

- Ablation Study : Mask Patch(1)

- Ablation Study : Mask Patch(2)

- Ablation Study : Patch Extraction Scheme

- Ablation Study : Patch Size

- Ablation Study : Input Size
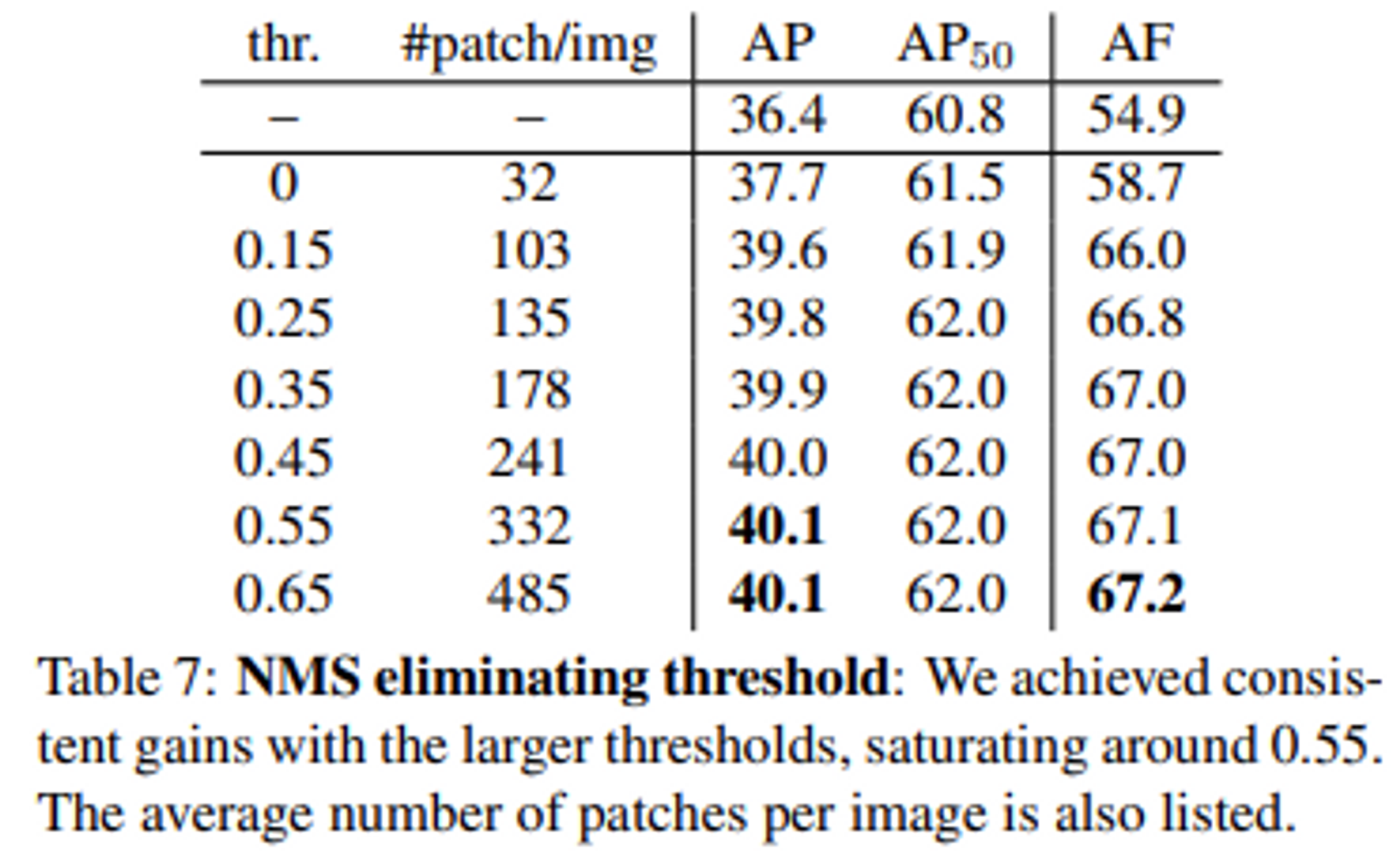
- Ablation Study : NMS threshold

- Ablation Study : Refinement network
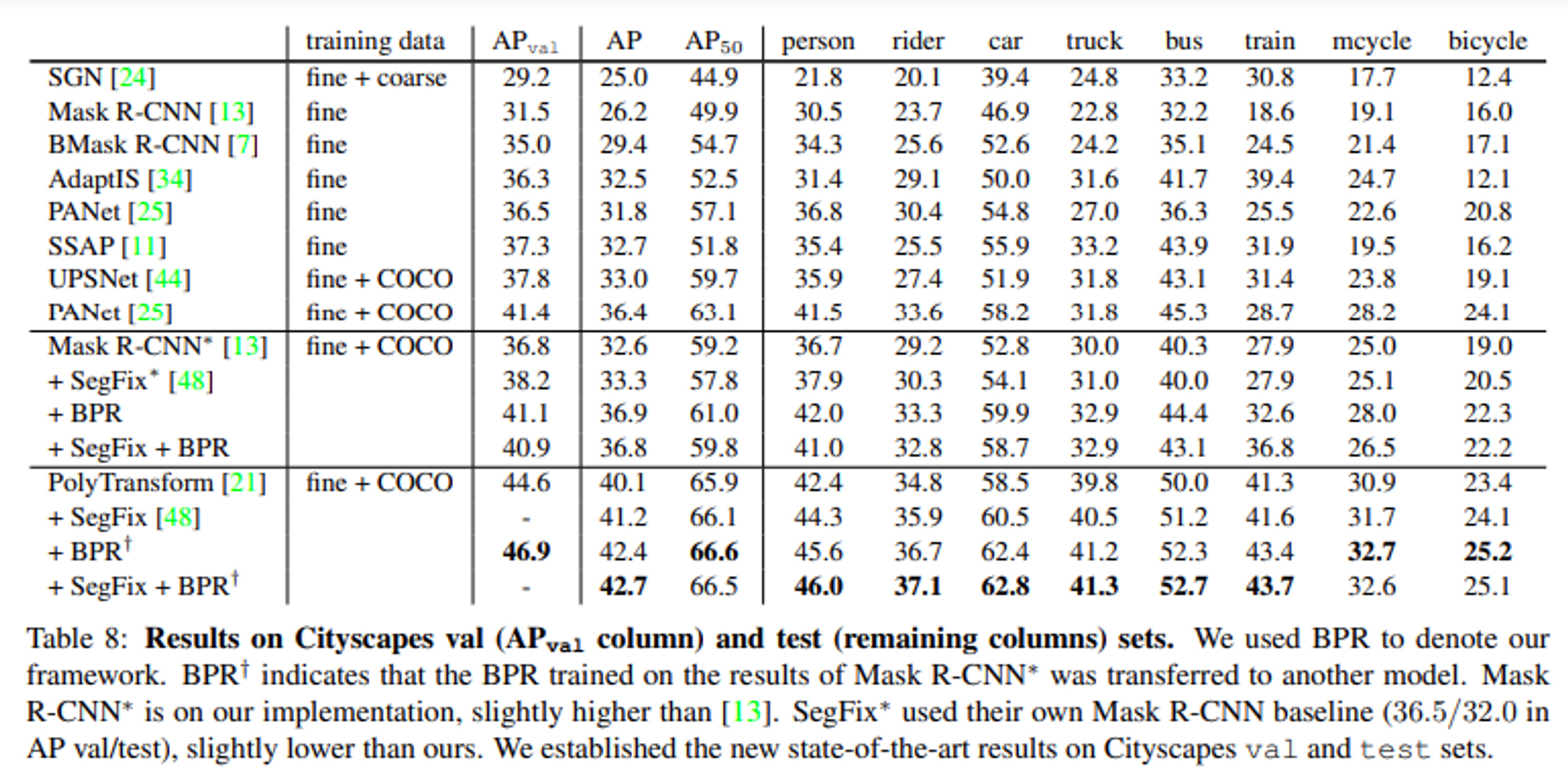
- Refinement model 적용에 따른 성능 평가 결과

- Cityscapes val set 기준 정성적 평가 결과
5. Conclusion
제안된 framework는 서로 다른 baseline에 대해서 일관되고 인상적인 성능 향상을 보였다. 정석적 평가의 결과는 제안하는 방식이 정확하고 뚜렷한 경계를 가진 고품질 마스크를 생산했음을 보여준다.
