SimpleClick : Interactive Image Segmentation with Simple Vision Transformers
Computer Vision
Abstract
최근 dense prediction task에서 경쟁력 있는 backbone으로 ViT(Vision Transformer)가 등장했다. ViT design은 쉽고, 효과적이지만 아직 interactive segmentation에서는 연구가 부족하다. 그래서 본 논문에서는 SimpleClick이라 부르는 plain backbone method를 제안한다.
1. Introduction
최근 click-based approach는 보다 효과적인 backbone architecture에 대해서 연구하거나 backbone에 대해서 보다 정교한 refinement module를 연구하는 방향으로 진행되고 있다. 전자와 관련해서는 ConvNets나 ViTs와 같은 hierarchical backbone들이 개발되고 있고, 후자와 관련해서는 local refinement나 click imitation와 같은 refinement module들이 개발되고 있다. 본 논문에서는 전자의 경우에 해당되며, interactive segmentation을 위한 plain backbone에 대한 실험에 집중한다.
기존 hierarchical backbone은 receptive field를 넓히기 위해 hierarchical 구조를 사용한다. 특히, ConvNets의 경우 점진적으로 downsample하여 global contextual information을 구할 수 있도록한다. 이 과정에서 FPN이 사용되는데, ViT는 self-attention block에서 각 feature map이 동일한 resolution을 가지면서도 global information을 얻을 수 있으므로 FPN을 사용하지 않는다.
이러한 ViT의 장점에도 불구하고 기존 Interactive Segmentation에선 충분한 연구가 이뤄지지않고 있었다. 그래서 본 논문에서 ViT 구조 기반 SimpleClick 모델을 제안했다. SimpleClick은 ViT으로부터 얻은 last feature map에 대해서 segmentation을 위한 simple feature pyramid를 구성한다. 그리고 SimpleClick을 보다 효과적으로 만들기 위해 MLP Decoder를 light-weight하게 수정했다.
2. Related Work
Interactive Image Segmentation
최근 Interactive Image Segmentation 분야는 주로 이미지 픽셀에 대해서 정의된 graph를 사용해서 문제를 해결하려했지만, 이 방법들은 주로 low-level image feature에 집중하는 경향이 있고, 복잡한 object에 대해서 어려움을 겪는다.
한편 ConvNets는 large dataset들에 대해서 high quality interactive segmentation을 얻을 수 있는 지배적인 architecture로 발전해왔고, bounding box, polygon, click, scribbles 등의 다양한 interaction type에 대해서 연구되어왔다. 그중에서 click 기반 접근 방법이 사용하기 쉽고, 학습 및 훈련 프로토콜이 잘 확립되어 일반적으로 사용된다.
그리고 최근에는 ViT 기반 방법들이 interactive segmentation에서 연구되고 있는데, 그중에서 FocalClick은 SegFormer를 backbone으로 사용하여 높은 computational 효율성을 가지고 sota를 달성했다.
backbone의 기여에 이어서 정교한 refinement module에 대한 연구도 함께 진행되고 있는데, FocalClick과 FocusCut은 high quality segmentation을 제공하는 비슷한 local refinement module을 제안한다. PseudoClick은 다음 클릭을 예측하여 human annotation cost를 줄이는 메커니즘을 제안하기도 했다.
본 논문에서 제안하는 method는 기존 방법들과는 달리 보다 일반적이고 non-hierarchical ViT backbone을 사용하여 pretrained ViT 모델을 쉽게 사용할 수 있는 이점을 누릴 수 있다.
Vision Transformers for Non-Interactive Segmentation
Vit based model들은 Segmentation Task에서 기존 ConvNets에 비해 경쟁력 있는 성능을 보였다. original ViT는 single-scale feature map을 유지하는 non-hierarchical 구조를 가지고 있다.
SETR과 Segmenter는 Semantic Segmentation에서 ViT를 encoder로 사용했다. 그리고 Swin Transformer에서는 좀 더 정확한 segmentation을 위해 shifted window attention을 사용하면서 computational hierarchy를 ViT 구조에 재도입했다. SegFormer는 중복 patch 병합을 사용하여 ViT를 기반으로 hierarchical feature representations을 design했고, 효율적인 segmentation을 위해 경량 MLP decoder를 결합했다. HRViT는 high-resolution multi-branch 구조를 통합하여 ViT가 multi-scale representation을 학습할 수 있도록 했다.
최근 ViT는 MAE, pretraining, window attention을 목표로 semantic segmentation, object detection에서 경쟁력이 있는 backbone으로 재도입 되고 있으며, 본 논문에서는 interactive segmentation에 적용하기 위해 plain ViT를 실험했다.
3. Method
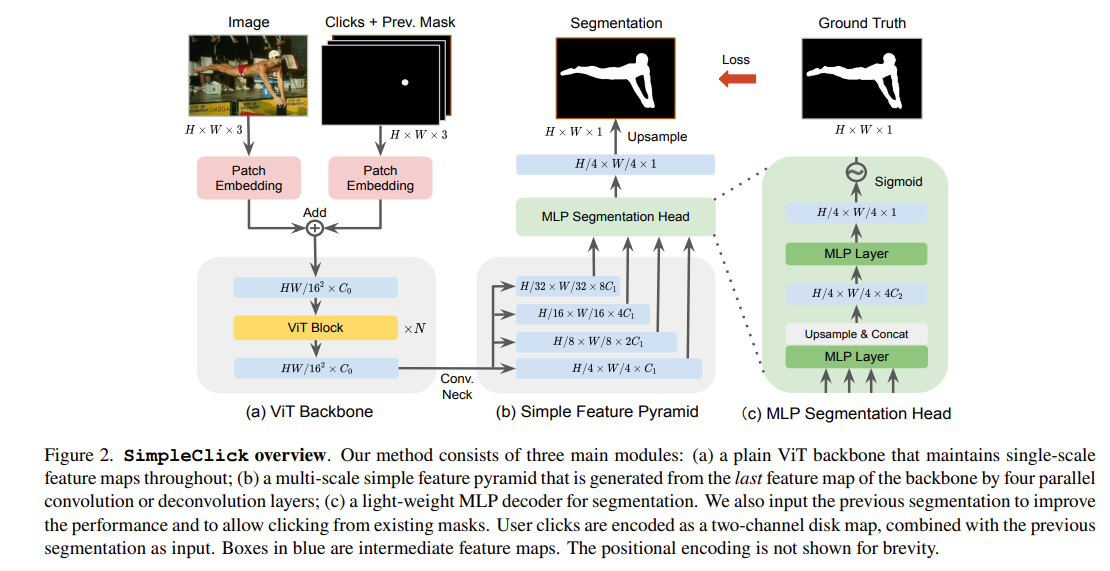
3.1 Network Architecture
Adaptation of Plain-ViT Backbone
SimpleClick에서는 plain ViT를 backbone으로 사용했고, single-scale feature map을 유지한다. patch embedding 부분은 기존 ViT와 동일하다. 본 논문에서는 ViT-B, ViT-L, ViT-H backbone을 소개했다. 이 backbone들은 MAEs로써 ImageNet-1k에서 사전학습되었다. 마지막 feature map은 전체 attention block의 영향을 받기 때문에 가장 강력한 representation을 가져야한다. 따라서 본 논문에서는 last feature map를 simple multi-scale feature pyramid를 구축하는데 사용했다.
Simple Feature Pyramid
hierarchical backbone에서는 다른 stage들의 feature들을 결합하기 위해 FPN을 통해 feature pyramid를 얻는다. plain-backbone에서는 parallel convolutional이나 deconvolutional layer를 last feature map에 적용하여 쉽게 feature pyramid를 얻을 수 있다.
All-MLP Segmentation Head
본 논문에서는 오직 MLP layer만 사용하여 경량화된 segmentation head를 구현했다. head에서는 simple feature pyramid를 입력받아 1/4 스케일의 segmentation probability map을 생성하고 이어서 upsampling이 적용된다.
MLP head는 3가지 step을 거치는데, 위의 Figure 2 그림과 같이 동작한다.
Other Modules
사용자 click은 positive click과 negative click의 2-channel disk map으로 encode된다. positive click은 전경에 위치해야하고, negative click은 배경에 위치해야된다. 이전의 segmentation과 2-channel click map은 patch embedding을 위한 3-channel map으로 연결된다. 두개의 분리된 patch embedding layer들은 각각 이미지와 연결된 3-channel map에서 동작한다. 두 입력은 패치화, 평탄화 및 동일한 차원의 두 벡터 시퀀스에 투영된 다음 self-attention block에 입력하기 전에 element-wise로 더해진다.
3.2 Training and Inference Settings
Backbone Pretraining
본 논문에서 사용한 모델은 ImageNet-1K에서 MAE로 학습된 pretrained 모델이다. MAE pretraining시에는 ViT 모델이 이미지에 random하게 mask된 픽셀을 재구성한다. 이러한 쉬운 self-supervised 접근은 ViT 모델을 효과적이고 확장가능하도록 pretrain한다. 단, 본 논문에서는 직접 pretrain하지않고, 사전 학습된 모델을 사용했다.
End-to-end Finetuning
위에서 언급한 pretrain모델을 가지고 interactive segmentation task로 SimpleClick 모델을 finetune했다. finetuning pipeline은 다음과 같다.
- 클릭을 제공하는 사람없이 현재 segmentation과 gold standard segmentation을 기반으로 자동으로 클릭을 시뮬레이션한다.(RITM 참조) 여기서, 반복 클릭 시뮬레이션은 반복적으로 클릭을 생성하고, 다음 클릭은 이전 클릭을 사용하여 얻은 예측의 잘못된 영역에 배치되어야 한다.
- 더 나은 segmentation 결과를 위해 backbone에 대한 추가 입력으로 이전 insteraction으로부터 얻은 segmentation을 통합한다.
본 논문에서는 NFL(Normalized Focal Loss)를 사용했다.
Inference
inference mode는 automatic evaluation과 human evaluation 두가지가 있다. automatic evaluation은 현재 segmentation과 gold standard를 기반으로 자동으로 클릭이 시뮬레이션되고, human evaluation은 사람이 현재 segmentation 결과에 대해서 주관적인 평가를 기반으로 모든 클릭을 제공한다.
4. Experiments
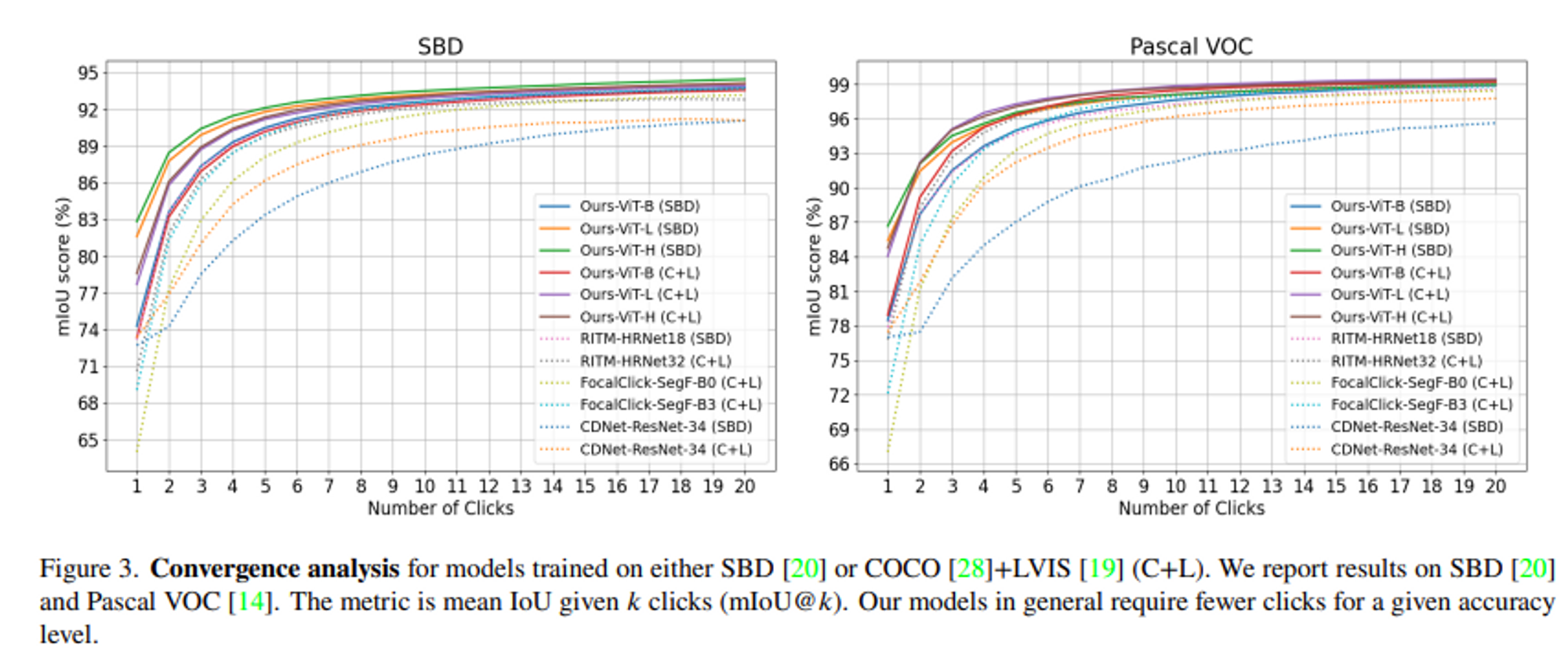
- Convergence analysis 결과 : Simple Click 모델의 클릭에 따른 성능이 가장 높았다.
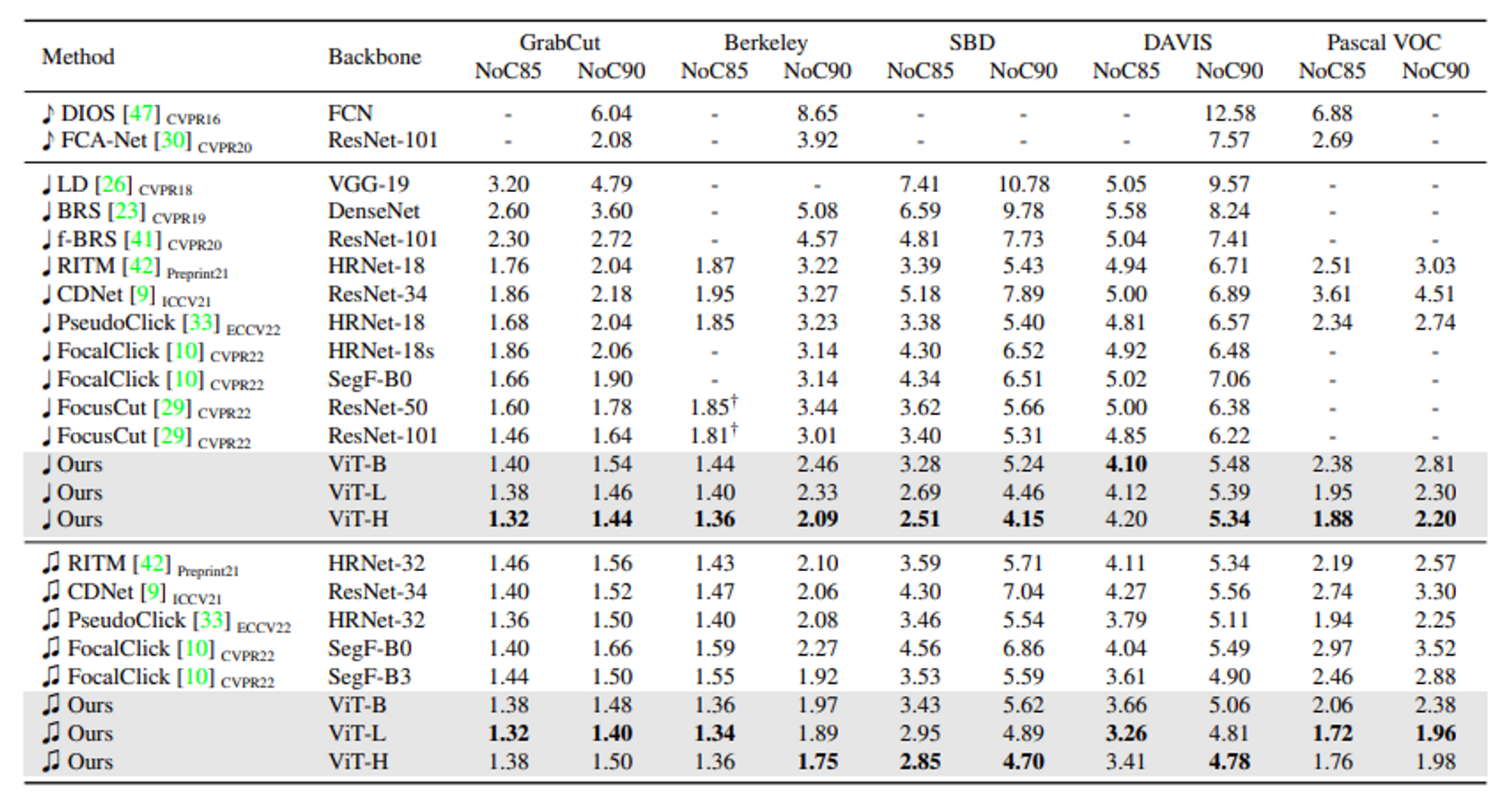
- NoC기반 성능 평가 결과
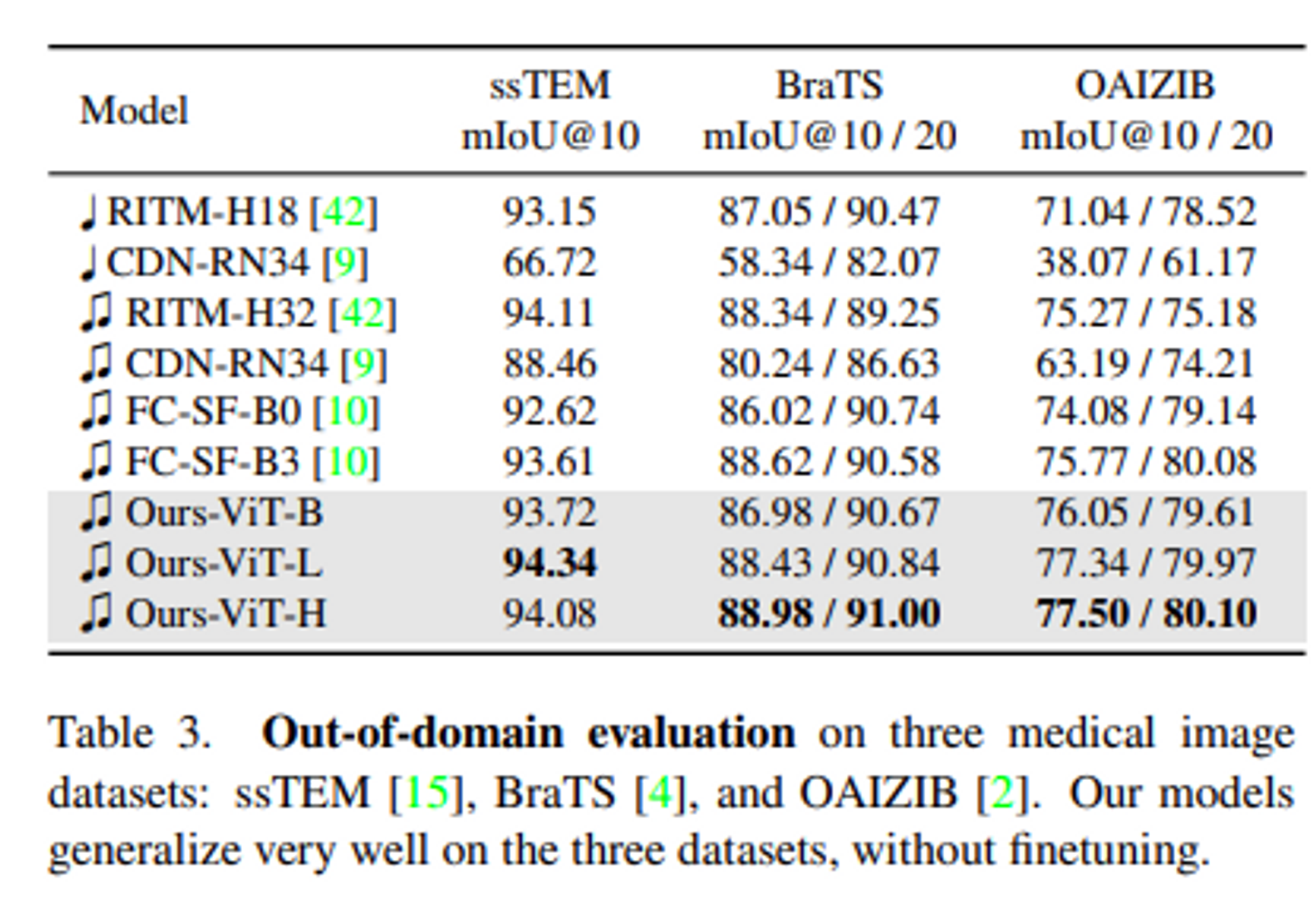
- medical dataset 기반 성능 평가 결과
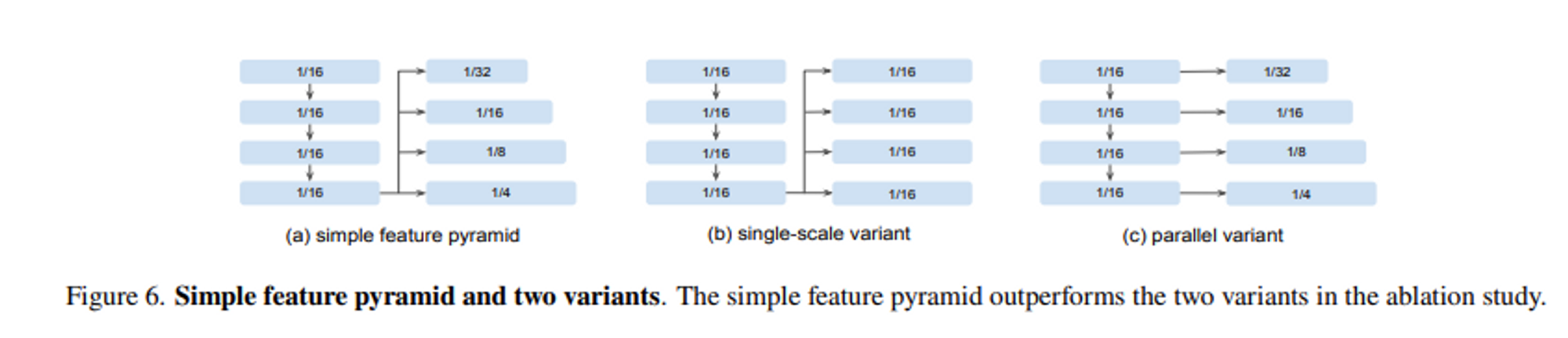
- Simple Feature Pyramid(Proposed), Single-Scale variant, Parallel variant
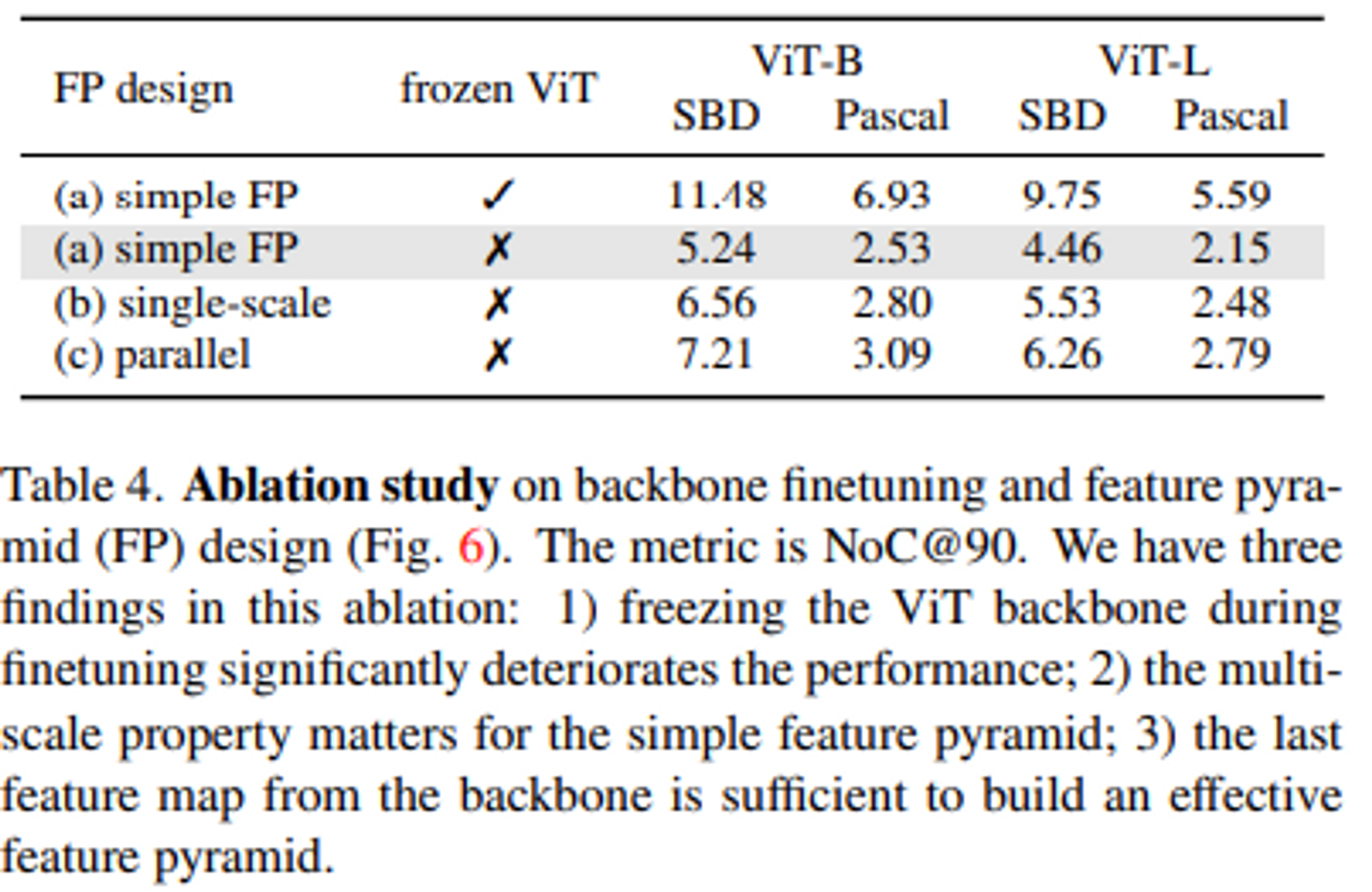
- Ablation Study 결과(Freeze Backbone, Feature Pyramid, Last Feature Map)
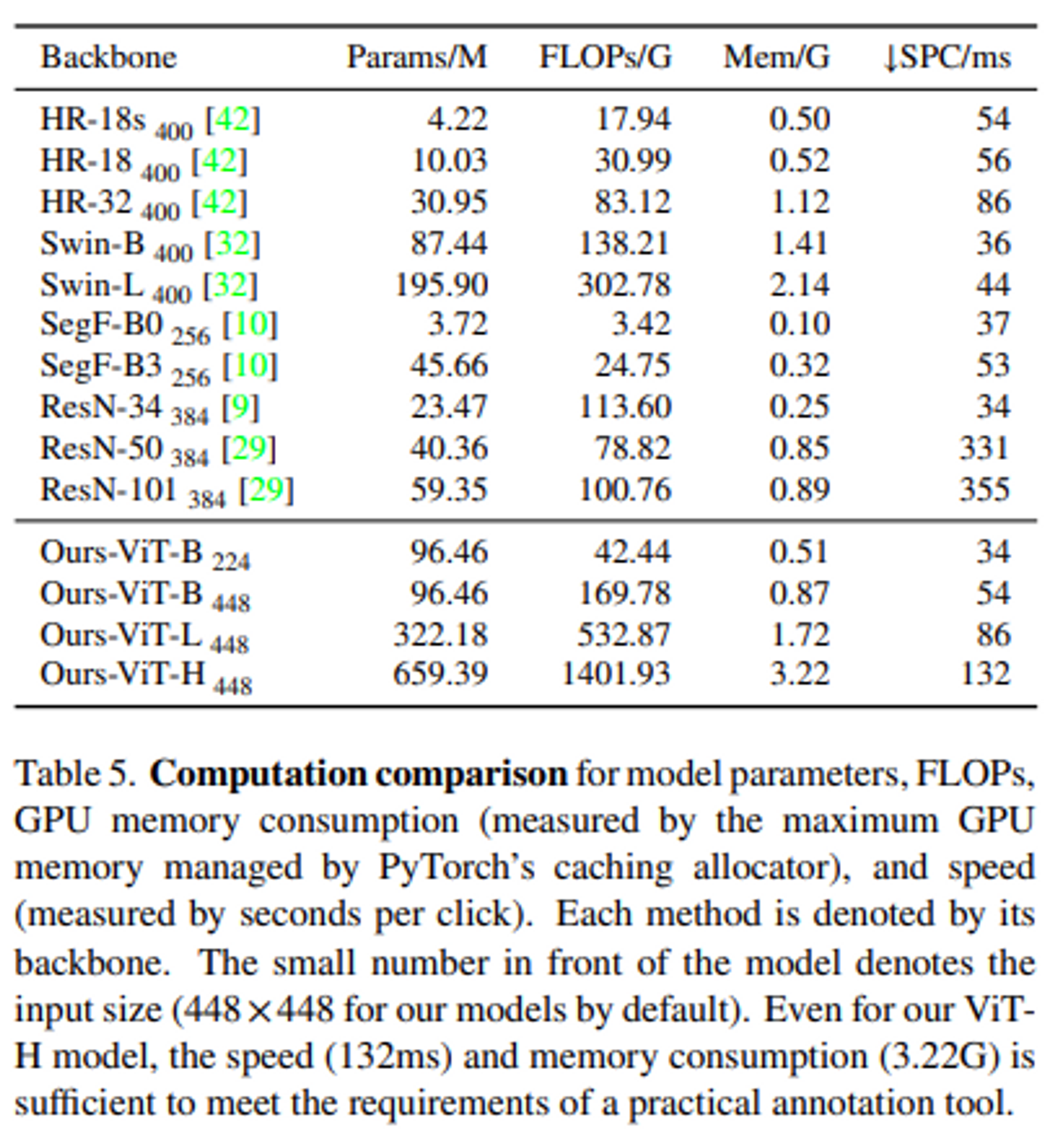
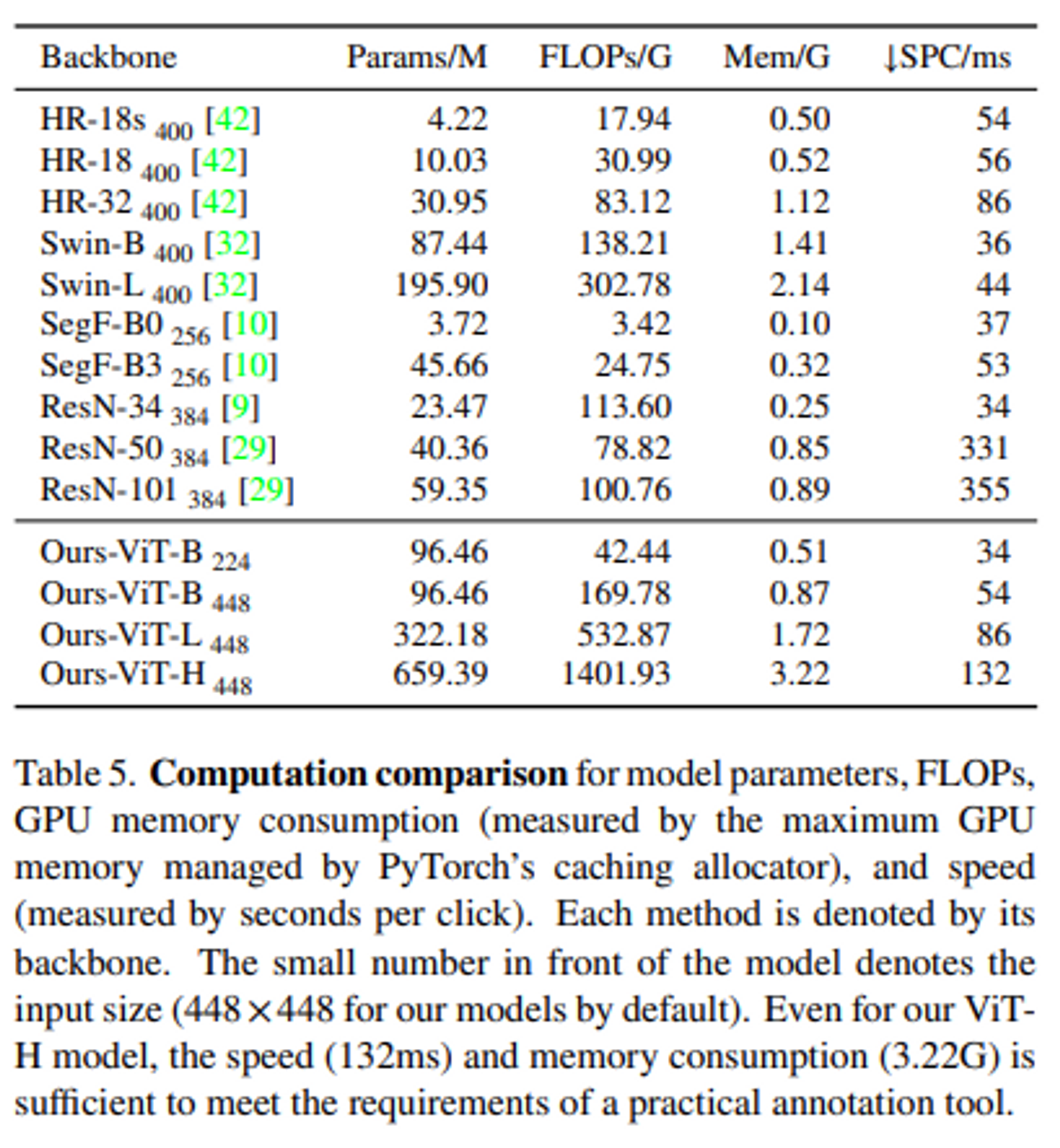
- Computational Analysis
5. Limitations

많은 Flops가 필요하기 때문에 low-power device에 사용하기 어렵다. 그리고 매우 얇고 긴 instance나 cluttered occlusion에 대해서 종종 실패하는 경향을 보인다. 이 경우는 local refinement 모듈을 적용해서 해결할 필요가 있다.
6. Conclusions
본 논문에서 제안한 SimpleClick 모델은 범용적인 ViT를 backbone으로 사용함으로써 pretrain된 ViT 모델의 이점을 즉시 얻을 수 있는 동시에 fine tuning시에 pretrain 모델을 분리할 수 있었다. 그리고 MAE로 pretrain된 plain backbone을 사용하여 sota를 기록했고, 의료 이미지에 대한 강력한 일반화 가능성을 증명했다.
