Query-Centric Trajectory Prediction
Abstract
논문에서는 주변 차량의 미래 궤적을 예측하는 모델링 프레임워크인 QCNet을 소개한다.
먼저, 기존 접근 방식에서 사용된 에이전트 중심 모델링 스키마의 경우 에이전트가 이동할 때마다 정규화 및 인코등을 수행하므로 중복된 계산이 발생한다는 것을 명시했다. 여기선 이러한 제한 사항을 극복하기 위해 장면 인코딩을 위한 쿼리 중심 패러다임을 소개한다. 쿼리 중심 패러다임은 전역 시공간 좌표계의 독립된 표현을 학습함으로써 과거의 계산을 재사용할 수 있다. 또한, 모든 target agent 사이에서 invariant scene feature를 공유함으로써, multi-agent trajectory decoding이 가능하도록 한다.
두 번째로, scene에서 풍부한 encoding이 주어진 상황에도 기존 디코딩 전략은 특히, prediction horizon이 긴 경우에 에이전트의 미래 행동에 내재된 다중성(multimodality)을 포착하기 어렵다. 이 문제를 해결하기 위해, 여기선 경로 후보를 재귀적 형태로 생성하기 위해 anchor-free query를 도입했다. 이를 통해 모델이 다른 scene context를 활용하여 서로 다른 horizon에서 waypoint를 디코딩할 수 있다. refinement module은 trajectory proposal을 anchor로 사용하여 trajecotory를 더욱 세분화한다. 적응적이며 high quality anchor를 refinement module에 적용함으로써 논문에서 제안한 query-based decoder는 경로 예측의 출력이 가지는 다중성을 잘 처리할 수 있다.
논문에서 제안한 모델은 각각 Argoverse 1, Argoverse 2 motion forecasting benchmark에서 sota를 기록했으며, 동시에 query-centric design으로 streaming scene encoding과 multi-agent decoding을 달성할 수 있었다.
Introduction
먼저, 자율주행 분야에서 활용되어온 궤적 예측 알고리즘의 성능을 고도화 시키기 어려운 이유와 기존 접근법의 한계에 대해서 소개한다.
(i) 최근 제안된 기법들은 이질적은 traffic scene을 효율적으로 처리하지 못한다. 실제 자율주행 시스템에서는 데이터 프레임이 예측 모듈을 통해 순차적으로 도착하여 high resolution vector map과 주변 agent의 kinematic state를 포함한 희소한 scene context의 stream으로 구성된다. 이에 따라 희소한 scene context encoding 기술에 대한 연구가 진행되었고 특히, factorized attention-based Transformer가 높은 성능을 보였다. 그러나 이 방법의 경우 각 시공간 scene 요소에 대한 attention-based representation 학습을 필요로 하고, dense traffic scene을 처리할 때 매우 많은 계산 비용이 소요되는 문제가 있다.
(ii) 궤적 예측의 불확실성은 horizon이 증가함에 따라 기하급수적으로 증가하게 되어 궤적 예측의 어려움을 겪게 한다. 예를 들어, 교차로에서의 차량은 운전자의 장기적 목표에 따라 회전하거나 직진할 수 있는데, 이러한 상황에서 잠재적 행동을 놓치지 않기 위해서 모델은 단순히 가장 빈도가 높은 모드를 예측하는 것이 아닌 multimodal distribution을 포착할 수 있어야 한다. 하지만, 이러한 학습 과제는 일반적으로 각 학습 샘플에는 하나의 가능성만 기록되기 때문에 어렵다. 이와 관련하여 일부 연구에서는 학습 난이도를 줄이기 위해 multimodal prediction을 위한 가이드로 수동으로 만든 앵커를 활용한다. 그러나 이 방법의 경우 앵커의 품질에 크게 영향을 받는다. 특히, 몇 개의 앵커로 GT를 포괄할 수 있는 경우에 성능이 낮아진다. 이외에도 mode collapse나 훈련 불안정성에도 직접적으로 궤적을 예측하는 방법도 있지만, 이러한 경우 spatial prior이 없으므로 long-term forecast가 힘들다.
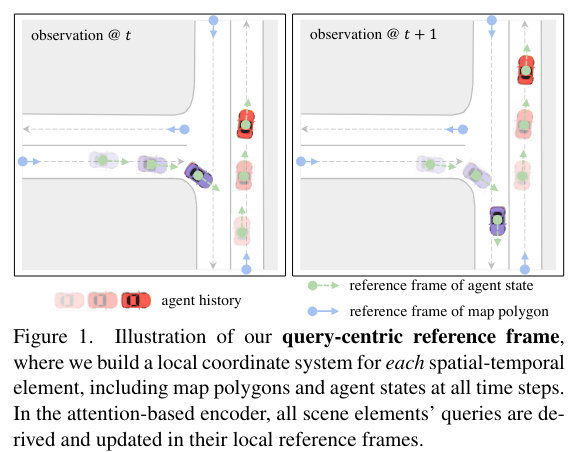
위의 분석을 기반으로 논문에서는 이전 솔루션의 제한을 극복하기 위해 QCNet을 제안했다. 먼저, QCNet은 factorized ateention의 이점을 가지면서도 더 빠른 online inference가 가능함을 언급했다. 여기서, 기존의 agent-centric enconding scheme는 계산 중복성 문제가 존재하여 scene encoding을 위한 query-centric 패러다임을 도입했다. query-centric의 핵심은 모든 scene element를 local space-time reference frame에서 처리하고, global coordinate system의 독립적인 representation을 학습하는 것이다. 이 방법은 이전에 계산된 encoding을 캐싱 및 재사용하고, 모든 observation window애 계산을 분산시켜 추론 지연 시간을 줄일 수 있다. 또한, 불변적인 scene feature는 scene 내의 모든 target agent사이에서 공유되어 multi agent decoding의 병렬 연산이 가능하게 한다.
그리고 scene encoding을 multi-modal 및 long term prediction에 더 잘 활용하기 위해 anchor-free query를 사용하여 scene context를 재귀적으로 검색하고 각 반복에서 future waypoint의 short segment를 디코딩하게 한다. 이러한 재귀 매커니즘은 query에게 다른 scene context에 집중할 수 있도록 함으로써 query의 모델링 부담을 줄일 수 있다. 재귀 decoder에 의해 예측된 고품질의 궤적은 refinement module에서 동적 앵커로 작용한다. 여기서, 논문에서는 scene-context를 기반으로 궤적 제안을 refine하기 위해 anchore-based query를 사용한다. 결론적으로 제안하는 query-based decoding pipeline은 anchor-free 방법의 유연성을 anchor-based solution에 통합하여 multimodal 및 long term prediction에 용이하게 한다.
Related Work
Scene context fusion
이전 연구에서는 world state를 multi-channel image로 rasterize하고, 고전적인 cnn을 사용하는 방식으로 풍부한 정보를 encoding했다. 그러나 raster-based method의 손실 압축, 제한된 receptive field 및 높은 비용으로 인해 vector-based encoding scheme로 전환되었다. permutation-invariant set operator(e.g. pooling, GCN)를 사용함으로써, vector-based method는 효과적으로 traffic scene의 희소한 정보를 집계할 수 있었다.
최근 경로 예측 모델은 encoder로 factorized attention을 사용하는 transformer를 채택했다. 이러한 모델은 계층적으로 agent-centric feature를 학습하거나 전체 장면을 shared coordinate system으로 인코딩함으로써 효율성을 향상시켰지만, 여전히 factorized attention의 계산 복잡성에 의해 확장 가능성이 제한되었다.
Multimodal future distribution
multimodal future distribution은 world state가 부분적으로 관측 가능하고 agent의 의도가 매우 불확실한 상황에서 궤적 예측시에 널리 사용된다. 생성 모델은 multi modal prediction에 자연스럽게 부합하지만 잠재 변수에서 샘플링하면 test-time의 확률적 요소가 도입되어 자율 주행과 같은 안전에 중요한 응용 분야에 적용하기에는 위험하다. 또 다른 연구 방향으로 인코딩된 scene context에서 이산적인 궤적 집합을 디코딩하여 multimodal을 처리하는 것이 있는데, 학습 데이터에는 하나의 모드만 관측되기 때문에 여러 가지 다양한 미래를 예측하는 것은 어렵다. anchor-based 방법은 사전 정의된 maneuvers, 후보 궤적 또는 map-adaptive goal를 활용하여 multimodal prediction이 가능하도록 한다. 그러나, 추론 성능은 anchor의 품질에 크게 영향을 받는 문제가 있다. 반면, anchor-free 방법은 mode collapse와 훈련 불안정성을 가지면서 여러 가설을 얻을 수 있다. 본 논문에서는 anchor-based method와 anchor-free method의 장점을 모두 활용한다.
Approach
Input and Output Formulation
자율 주행 차량을 둘러싼 A개의 에이전트가 있는 시나리오를 고려했을 때, 온라인 실행중에는 perception module은 prediction module에게 agent의 상태 스트림을 제공한다. 여기서, 각 에이전트 상태는 시공간 포지션과 기하학 속성과 관련되어 있다.
예를 들어, time step t에서의 i번째 agent는 공간 위치 , 각도 위치 (yaw angle), 시간 위치 t, 속도 로 구성된다. 그리고 motion vector 를 기하학 속성에 추가한다. 또한, prediction module은 고해상도 맵에서 M개의 polygon(e.g. lanes, crosswalks)에 엑세스할 수 있다. 여기서, 각 맵 polygon은 샘플링된 포인트와 semantic attribute(e.g. 차선의 사용자 유형)으로 주석이 달려있다.
T time steps의 observation window 내에서 맵 정보와 agent state가 주어졌을 때, prediction module은 T time steps의 지표를 통해 각 target agent의 K개의 미래 궤적을 예측하고 각 예측에 대한 확률 점수를 할당하는 것을 목표로 한다.
Query-Centric Scene Context Encoding
궤적 예측의 첫 단계는 scene input에 대한 encoding이다.
최근 연구에 따르면 factorized attention은 scene encoding에 효과적임을 발견했다. 이러한 접근 방식은 한 번에 하나의 축을 따라 쿼리 요소가 키 / 값 요소에 주의를 기울일 수 있도록 한다. 이는 temporal attention, agent-map attention, social attention(i.e. agent-agent attention)을 얻을 수 있고, 각각 의 시간 복잡도를 가진다.
이는 temporal network를 적용하여 time dimension을 압축한 다음 현재 시간 단계에서만 agent-map, agent-agent fusion을 수행하는 전형적인 인코딩 전략과는 달리, factorized attention은 observation window내의 모든 과거 time step에서 융합을 수행한다. 그러나, 각 fusion operation의 계산 복잡성으로 인해 확장성이 제한된다.
여기서, 논문의 저자의 주 관심은 factorized attention의 표현력은 유지하면서 inference latency time을 줄이는 것이다.
먼저, 논문 저자는 궤적 예측이 스트리밍 작업임을 명시했고, 이와 관련하여 observation window를 이동시킬 때 이전에 계산된 time step의 enconding을 재사용할 수 있는지 여부에 대한 내용을 언급했다. 결론적으로 current time step에서는 agent의 위치를 기반으로 다시 정규화를 해야되어 이 방법은 불가능함을 언급했다.
위의 분석을 토대로, 논문에서는 scene element의 전역 좌표와 독립적인 표현을 학습하기 위한 쿼리 중심 인코딩 패러다임을 도입했다. 구체적으로는, 쿼리 벡터가 유래하는 각 장면 요소에 대한 로컬 시공간 좌표 시스템을 설정하고 쿼리 요소의 feature를 해당 로컬 참조 프레임에서 처리한다. 그런 다음 attention-based context fusion을 수행할 때 상대적인 spatial-temporal position을 키와 값 요소에 주입한다.
Local Spacetime Coordinate System
Fig 1은 scene element의 local coordinate system 예시를 보여준다. time step t에서의 i번째 에이전트의 상태는 reference spatial-temporal position 와 reference direction 로 정의된다. 그리고 차선과 횡단보도의 경우, 중앙선의 입구 지점의 위치와 방향을 참조로 선택한다.
Scene Element Embedding
agent state 또는 lane과 같은 각 spatial-temporal scene element에 대해 해당 요소의 로컬 프레임에 의해 참조된 sptial point와 direction와의 상대적인 위치에 대한 모든 기하학적 속성(e.g. agent state의 속도 및 운동 벡터, 차선의 모든 샘플링된 지점의 위치)의 극좌표를 계산한다.
그리고나서 각 극좌표를 푸리에 특징으로 변환하여 고주파 신호 학습에 용이하도록 유도한다. 각 agent state와 map의 sampled point에 대해, 푸리에 특징은 semantic attribute(e.g. agent의 범주)와 MLP를 통해 임베딩을 얻는다. 차선과 횡단보도에 대한 polygon-level representation을 더 생산하기 위해, 각 맵 polygon 내의 샘플링된 지점의 임베딩에 attention-based pooling을 적용한다.
위의 작업을 통해 [A,T,D]의 agent embedding와 [M, D] 형태의 map embedding을 얻게 된다. 여기서 D는 숨겨진 특징 차원을 나타낸다. local reference frame에서 모델링하는 이점을 통해, 각 agent state/map polygon의 임베딩은 하나의 인스턴스만 가지고 있으며 후속 observation window에서 재사용할 수 있다.
Relative Spatial-Temporal Positional Embedding
scene element에 대한 relative position embedding을 준비한다. 이 임베딩은 attention-based operation에 통합되어 모델이 두 element의 로컬 좌표 프레임 간의 차이를 인식할 수 있도록 돕는다.
절대 sptial-temporal position 와 에 대해 상대적인 위치를 요약하기 위한 4차원 descriptor를 사용한다. 이 descriptor는 상대적 거리 , 상대적 방향 , 상대적 방향 , 시간 차 로 구성된다.
그런 다음, 4차원 설명자를 푸리에 특징으로 변환하고 이를 MLP를 통해 상대적인 위치 임베딩 로 표시할 수 있다. 만약, 두 scene 요소중에서 하나라도 정적인 경우(e.g. static map polygons), 위 첨자를 생략하고 임베딩을 로 표시할 수 있다.
Self-Attention for Map Encoding
맵 요소들 간의 관계를 모델링하기 위해 self-attention을 적용한다. 이후에 업데이트 된 맵 인코딩은 agent feature를 제공하고, trajectory decoding을 지원한다.
i번째 map polygon에 대해, 임베딩 결과 에서 쿼리 벡터를 도출하고 이를 이웃한 차선과 횡단보도 와 연산을 수행한다. 여기서, 은 polygon 이웃 집합을 나타낸다. 맵 인코딩에 대한 공간적 인식을 통합하기 위해, 와 와 같은 $$relative position embedding의 연결으로부터 j-th key/value vector를 생성한다.
각각의 attention layer에 입력되는 쌍은 global sptial-temporal 좌표 시스템의 변환에 독립적이므로 output map encoding인 또한 global reference frame의 변환에 불변성을 가진다. 따라서, 이들은 모든 agent 및 모든 time step에 걸쳐 공유 될 수 있으며, 오프라인으로 사전에 계산이 가능하다.
Factorized Attention for Agent Encoding
agent embedding에 더 많은 정보를 포함할 수 있도록 agent의 time step과 agent들 간의 관계 그리고 agent와 map 간의 factorized attention을 고려한다.
i번째 에이전트의 time step t를 예를 들면, 쿼리는 agent state의 embedding 로부터 파생되고, 키와 값 벡터는 다음 수식으로부터 계산된다.
- agent의 time step :
- agent-map :
- agent social attention :
여기서, neighbor set 는 50 meter threshold를 의미한다.
쿼리 중심 모델링을 통해 모든 에이전트 및 맵 인코딩은 어떤 시공간 좌표 시스템에서든 고유하고 고정되어 있다. 즉, 모델은 과거 계산을 재사용할 수 있고 스트리밍 방식으로 동작할 수 있게 된다.

Query-Based Trajectory Decoding
궤적 예측의 두 번째 단계는 인코더에 의해 출력된 scene encoding을 활용하여 각 대상 agent에 대한 K개의 미래 궤적을 디코딩하는 것이다.
논문에서는 최근 Object Detection Task에서 one-to-many 문제에 좋은 성능을 보인 DETR 구조의 Decoder를 채택했다. 하지만, 이러한 구조의 문제점으로 다른 anchor-free 접근법과 유사하게 학습 불안정성과 mode collapse이 발생한다. 또한, long term prediction에서 잘 동작하지 않는 문제도 포함한다.
논문에서는 recurrent, anchor-free proposal module을 사용하여 적응적인 궤적 앵커를 생성하고, 초기 제안을 더욱 정제하는 앵커 기반 모듈을 사용하여 이러한 제한을 극복한다.
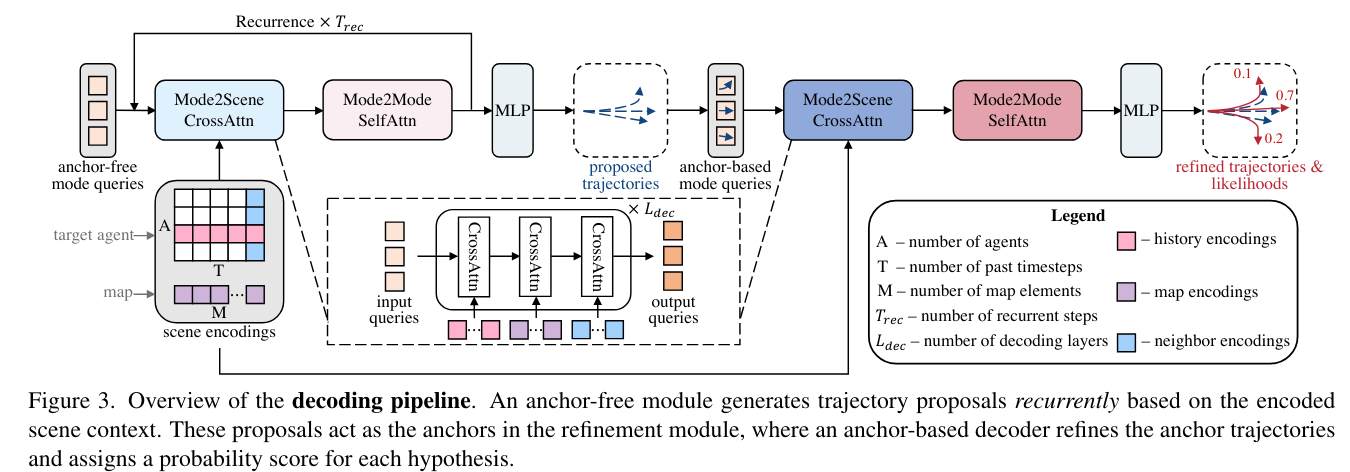
Mode2Scene and Mode2Mode Attention
DETR의 객체 쿼리 개념과 유사하게 각 쿼리는 K 궤적 모드 중 하나의 디코딩을 담당한다. Mode2Scene Attention에서는 cross attention layer를 사용하여 대상 agent의 history encoding, map encoding 및 social agent encoding을 포함한 여러 컨텍스트로 모드 쿼리를 업데이트한다. Mode2Scene Attention에 이어 K 개의 모드 쿼리는 Mode2Mode Self Attention을 통해 서로 소통하여 여러 모드의 다양성을 향상시킨다.
Reference Frames of Mode Queries
다중 에이전트의 궤적을 병렬로 예측하기 위해, 장면 내의 모든 대상 에이전트에게 동일한 장면 인코딩 세트를 공유한다. 이러한 인코딩은 그들의 로컬 시공간 좌표 시스템에서 유도되므로, 에이전트 중심적 모델링과 동일한 효과를 얻기 위해 이를 각 대상 에이전트의 현재 시점으로 투영해야 한다. 이를 위해, 각 모드 쿼리에 대해 해당 대상 에이전트의 현재 위치와 yaw 각도를 기반으로 가상의 좌표 프레임을 만든다. Mode2Scene 어텐션을 통해 쿼리 임베딩을 업데이트할 때, 장면 요소의 위치는 쿼리에 상대적으로 키와 값에 통합되며, 이는 인코더에서 수행한 것과 유사하다.
Anchor-Free Trajectory Proposal
논문에서는 학습 가능한 anchor-free query를 사용하여 초기 궤적을 제안한다. 이러한 제안은 refinement module에서 anchor 역할을 수행한다. 밀도가 높게 샘플링된 수작업 anchor로 ground truth를 cover하려는 anchor 기반 방법과 비교하여 제안하는 방식은 데이터 기반으로 K개의 적응형 앵커를 생성한다. 여기서, cross attention layer의 이점으로 mode query는 scene context를 검색하고 anchor의 검색 공간을 빠르게 좁힐 수 있다. 그리고 self-attention layer는 궤적 proposal을 생성할 때, query가 서로 협력할 수 있도록 한다.
한편, 논문에서는 long term sequence를 디코딩할 때 필요한 모든 정보를 단일 쿼리 임베딩으로 요약하는 것은 어렵기 때문에 쿼리의 컨텍스트 추출의 부담을 줄이고 앵커 품질을 향상시키기 위해 DETR과 비슷한 반복적인 방식으로 디코딩을 수행한다. 다음 recurrent step에서는 디코딩된 query를 다시 입력으로 사용하고, 몇 개의 waypoint에 관련된 scene context를 추출한다.
Anchor-Based Trajectory Refinement
Anchor Free Decoding은 유연성을 가지지만, 불안정한 학습 과정은 때로는 모드 붕괴로 이어질 수 있다. 반면, 무작위로 초기화된 모드 쿼리는 모든 장면에서 모든 대상 에이전트에 적응해야 하며, 시나리오별 편향이 없을 수 있습니다. 이는 운동 법칙을 위반하거나 고화질 지도에서 전달된 교통 규칙을 어긴 궤적과 같은 준수하지 않은 예측으로 이어질 수 있습니다.
따라서 논문에서는 제안을 더욱 정제하기 위해 앵커 기반 모듈을 사용했다. 제안 모듈의 출력을 앵커로 삼아, 정제 모듈은 제안된 궤적에 대한 오프셋을 예측하고 각 가설의 가능성을 추정한다. 이 모듈도 DETR과 유사한 아키텍처를 채택하지만, 그 모드 쿼리는 무작위로 초기화된 것이 아니라 제안된 궤적 앵커에서 유도된다. 구체적으로, 각 궤적 앵커를 임베딩하기 위해 작은 GRU가 사용되고, 그 최종 은닉 상태를 모드 쿼리로 취한다. 이러한 Anchor-based query는 모델에 명시적인 공간 우선순위를 제공하여 attention layer가 관심 영역의 context를 더 쉽게 localization할 수 있도록 한다.
Training Objectives
논문에서는 HiVT 이론을 바탕으로 i-th agent의 future trajectory를 라플라스 분포의 혼합으로 파라미터화시켰다.
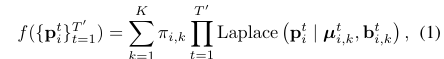
여기서, 각 파라미터는 다음을 뜻한다.
- : 혼합 상관 계수
- : k번째 t time step에서의 라플라스 밀도의 혼합 구성 요소
- : scale
그런 다음, 논문에서는 분류 손실 Lcls를 사용하여 위치와 스케일의 그래디언트를 중지하고 정제 모듈이 예측한 혼합 계수를 최적화한다. 반면에, 제안 및 정제 모듈에서는 출력된 위치와 스케일을 최적화하기 위해 winnertake-all strateg을 채택한다. 이 전략은 가장 잘 예측된 제안 및 해당 정제에 대해서만 역전파를 수행한다. 안정화를 위해 정제 모듈은 제안된 궤적 앵커의 그래디언트를 중지합니다.
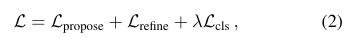
Conclusion
이 논문은 경로 예측에서 기존 연구의 문제를 극복할 수 있는 QCNet 구조를 소개한다. QCNet은 쿼리 중심 모델링의 디자인을 기반으로 Factorized Attention의 representational capability를 표현 능력을 유지하면서 더 빠른 추론 속도를 보인다. 또한, recurrent 및 anchor-free trajectory proposal module을 사용하여 long-term prediction에 좋은 성능을 보였다.
용어 설명
agent : 주어진 환경에서 행동할 수 있는 독립적인 개체나 시스템
horizon : 예측하는 시간 또는 거리 범위
waypoint : 경로나 이동 경로 상에서 특정한 지점이나 목표 지점
kinematic state : 물체의 운동에 대한 기본적인 정보. 물체의 위치, 속도, 가속도 등과 같은 운동 관련 변수 포함
anchor : 특정 상황에서 가능한 궤적의 시작점 또는 특정 속도 범위
rasterize : 벡터 형식의 그래픽이나 이미지를 픽셀 형식의 레스터 이미지로 변환하는 프로세스
