
역전파 과정에서 각 가중치들의 Gradient가 입력층으로 갈수록 0에 가까워지거나 매우 큰 값으로 발산되는 현상이 발생하는데, 이를 각각 Gradient Vanishing / Exploding이라고 한다. 이번 포스팅에서 이 현상들을 제어하는 방법에 대해서 알아보고자 한다.
1. Activation Function
이전에 포스팅했던 Activation Function(1), Activation Function(2)에서 언급했던 것과 같이 Sigmoid Function을 사용하게 되면, Gradient Vanishing 현상이 발생하게 된다. 이에 대해서 기존에는 ReLU와 ReLU의 변형 함수들이 나오게 되었다. 보다 자세한 내용은 위의 링크를 통해 복습하는 것을 추천한다.
2. Gradient Clipping
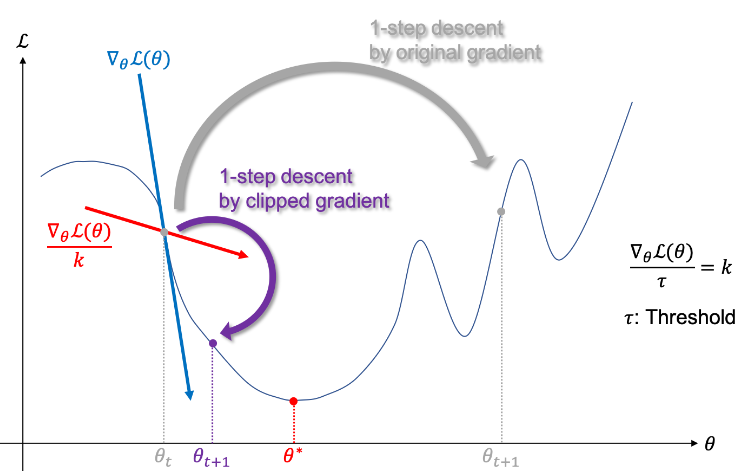
Gradient Cliping은 말 그대로 가중치의 Gradient에 대해서 Threshold를 기준으로 자르는 방법을 의미한다. 위의 그림에서 Gradient Cliping을 적용하지 않은 경우, 가중치 업데이트가 과하게 수행되어 Global Minimum을 찾지 못하게 된다.
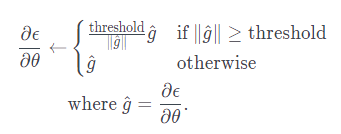
Gradient Cliping 수식은 위와 같고, 여기서 는 가중치 Gradient의 L2 Norm을 의미한다. 의 최댓값을 하이퍼 파라미터인 threshold로 지정해줘야 되는 문제점이 있지만, 를 적용함으로써 Gradient의 방향을 유지하면서 일정 크기이상의 Gradient를 제어할 수 있으므로 효과적이다.
3. Weight Initialization
Activation Function(1)에서 Sigmoid 함수를 사용함에도 Gradient Exploding 현상이 발생할 수 있는 이유에 대해서 설명했다. 이와 같이 가중치 초기화(Weight Initialization)는 모델 학습에 많은 영향을 준다.
3.1 세이비어 초기화(Xavier Initialization)
세이비어 글로럿과 요슈아 벤지오가 2010년에 제안한 새로운 가중치 초기화 방법이다.
세이비어 초기화(Xavier Initialization)는 균등 분포(Uniform Distribution)와 정규 분포(Normal Distribution)로 초기화하는 경우로 나눌 수 있으며, 이전 층의 뉴런 수와 현재 층의 뉴런 수를 가지고 식을 만들었다.
이전 층의 뉴런 수를 , 현재 층의 뉴런 수를 라고 가정하고, 균등분포의 경우는 다음과 같다.
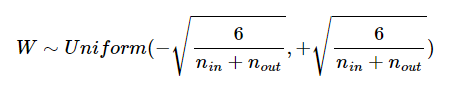
정규 분포로 초기화할 경우에는 평균은 0이고, 표준편차 는 다음을 따른다.

세이비어 초기화는 Layer간의 노드 수를 파악하여 가중치를 초기화 하기 때문에 특정 Layer에 가중치가 집중되는 현상을 막을 수 있다.
세이비어 초기화는 Sigmoid 나 Tanh Function와 같이 S 형태의 Function에 적용할 때 좋은 성능을 보인다고 한다. 하지만, ReLU나 ReLU의 변형 함수에 대해서는 성능이 좋지 않다고 한다.
3.2 He 초기화(He Initialization)
He 초기화(He Initialization) 또한 균등분포와 정규분포로 나눌 수 있다. 단, He 초기화는 세이비어 초기화는 달리 현재 층의 뉴런 수()를 반영하지 않는다.
균등 분포의 경우는 다음과 같다.
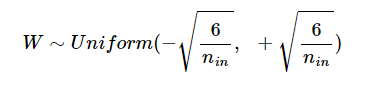
정규 분포의 경우, 평균은 0을 가지고 표준편차 는 다음과 같다.
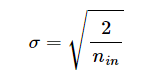
He 초기화는 ReLU나 ReLU의 변형 함수에 대해서 좋은 성능을 보인다고 한다.
4. 배치 정규화(Batch Normalization)
이전 포스팅에서 언급한 것과 같이 기존에는 GD(Gradient Descent)의 학습 시간 문제를 해결하기 위해 SGD(Stochastic Gradient Descent)를 사용하게 되었다. 이와 관련하여 Batch 개념이 도입되었다. 배치 정규화는 각 Layer의 Batch 단위 Input에 대해서 정규화를 적용하는 방법이다.
내부 공변량 변화(Internal Covariate Shift)
내부 공변량 변화(Internal Covariate Shift)는 학습 과정에서 Layer를 거치면서 각 Input 데이터의 분포들이 달라지는 현상을 의미한다.
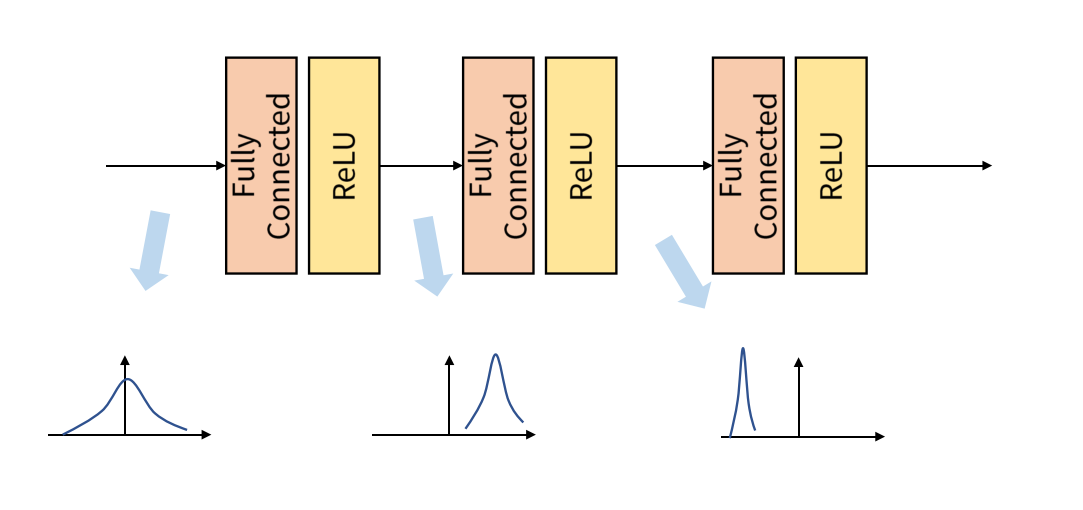
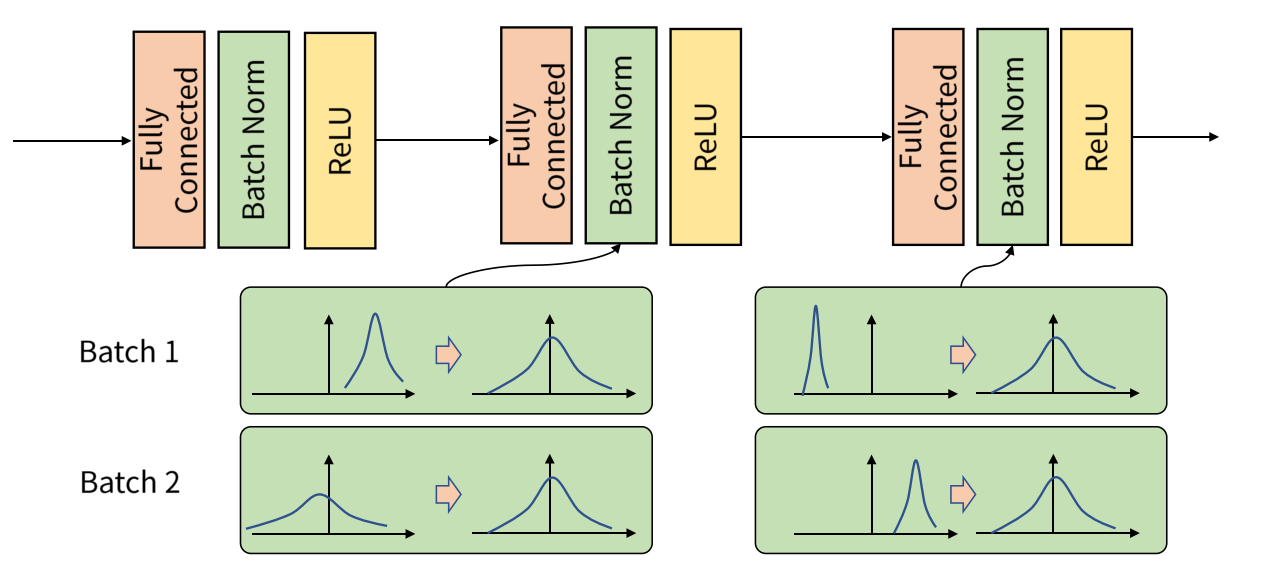
한편, Batch 단위의 데이터들은 내부 공변량 변화 현상으로 인해 Batch 및 Layer별 서로 다른 데이터 분포가 발생하게 된다. 여기서, Batch 단위의 Input 데이터의 분포를 정규화하여 Batch 및 Layer별로 같은 분포를 가질 수 있도록 하는 연산을 배치 정규화(Batch Normalization)라고 한다.
한편, 배치 정규화의 원인이 내부 공변량 변화 때문이 아니라고 주장하는 의견도 있다. 이에 관해서 지속적인 연구가 필요할 것으로 보인다.
배치 정규화는 각 배치별 데이터 분포를 평균이 0인 표준정규분포를 따르도록 정규화하는 연산이다. 배치 정규화는 와 를 사용하는데, 그 이유는 정규화만 적용했을 때 활성화 함수를 통한 비선형성이 감소될 수 있기 때문에 이를 방지하기 위함이다.

모델 추론 과정에서는 학습 시에 저장해놓은 배치 정규화 연산에 필요한 평균과 분산을 통해 정규화를 수행한다. 이때, 평균과 분산은 단순 이동 평균(Moving Average)나 지수 이동 평균(Exponential Moving Average)를 통해 구한 값이다.
4.1 배치 정규화 장점
- Gradient Vanishing 문제를 개선할 수 있다.
- 가중치 초기화에 대한 Dependency가 감소한다.
각 Layer의 출력은 활성화 함수를 거친 다음 Batch Normalization이 적용되기 때문에 정규화된 데이터를 가질 수 있으므로 안전성이 보장된다.
- 큰 학습률(Learning Rate) 적용이 가능해짐에 따라 학습 시간을 단축한다.
Batch Normalization을 적용하지 않고, Learning Rate를 크게 잡는 경우에는 주로 가중치의 Scale의 영향으로 인해 Gradient Vanishing / Exploding이나 Local Minimum에 빠지게 된다. 하지만, Batch Normalization을 적용하게 되면 이러한 가중치 Scale의 영향을 줄일 수 있으므로 큰 학습률 사용이 가능해지고, 학습 시간이 단축된다.
- 과적합을 방지할 수 있다.
타 블로그를 참고했을 때, 각 Batch 마다 평균과 분산을 구해서 정규화를 적용하는 작업은 전체 데이터에 대해서 평균과 분산을 구하는 경우와 다르기 때문에 결국 각 Batch별로 노이즈를 주는것과 같은 효과를 줌으로써 과적합을 방지할 수 있다고 한다.
하지만, 개인적인 생각으로는 Batch마다 평균과 분산을 구해서 표준정규분포 형태로 정규화를 함으로써 특정 데이터에 적합한 분포로 국한되는 과적합 문제를 개선 할 수 있다고 생각한다.
4.2 배치 정규화 단점
- 배치 정규화를 적용하면, 추가적인 계산이 필요하게 되어 추론 시간에 모델의 추가적인 실행 시간이 소요된다.
- Batch Size에 의존적이다.
단적인 예로 Batch Size가 1인 경우, 분산은 0을 가진다. 이처럼 배치 정규화는 Batch Size에 영향을 받기 때문에 배치 정규화를 사용할때는 적당한 크기의 Batch Size를 선택해야 된다.
- RNN 구조에 적합하지 않다.
RNN은 각 시점(Time Step)마다 다른 통계치(분포)를 갖는다. 즉, 배치 정규화를 적용하기 힘들다는 것이다. 예를 들어, 하나의 Batch에 (, , )가 있을 때, 이 데이터 각각은 서로 다른 시점에서의 입력이고, 서로 독립적으로 존재해야 되기 때문에 배치 정규화를 적용하면 안된다.
5. 층 정규화(Layer Normalization)
층 정규화는 각 Layer 별로 정규화하는 것을 의미한다. 배치 정규화와 달리 Batch Size에 의존적이지 않다.
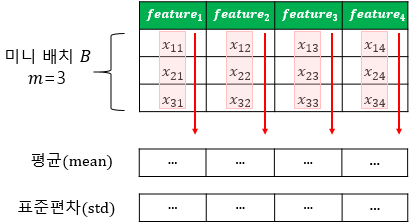
배치 정규화는 다음과 같이 각 Layer에 입력되는 Batch 데이터들의 평균과 분산을 통해 정규화하는 작업이다.

이에 반해 층 정규화는 위와 같이 Batch의 각 데이터 별 평균과 분산을 통해 정규화한다.
