Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets 논문 리뷰
Computer Vision
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets

Abstract
최근 Stability에서 text-to-video, image-to-video 모델인 고해상도를 지원하는 latent video diffusion model을 공개했다.
기존의 접근 방법은 2D 생성을 위한 LDM(Latent Diffusion Model)에 대해서 시간축 레이어를 추가 후 작은 비디오 세트에 대해서 파인튜닝하는 방식을 통해 Video Generation Model을 생성했지만, 큐레이션 및 학습 방법에 대한 통일화 된 방법을 얻지 못하는 문제를 가졌다.
이에 따라 이 논문에서는 Video LDM 모델을 생성하기 위해 크게 Text-to-Image, Video Pretraining, High-Quality Video Finetuning 단계로 실험을 진행했다.
실험을 통해 논문의 저자는 다음과 같은 사항들을 주장했다.
- Video Pretraining시에 사용할 Dataset에 대해서 캡션 및 필터링을 포함한 체계적인 큐레이션 프로세스 필요성 및 방안 제시
- high-quality data 학습 및 영향 검토를 통한 text-to-video 모델 생성
- base model의 image-to-video 및 camera motion-specific LoRA module DownStream Task에서의 motion representation 기능 제공
- 제안하는 모델의 3D multi-view prior 제공 및 multi-view diffusion model의 finetuning을 위한 base model로써의 가능성 제시
Introduction
논문의 저자는 기존 video modeling 관련 개선 연구가 주로 공간 혹은 시간 계층에 초점이 맞춰져있고, 데이터 영향에 따른 연구는 이뤄지지 않는다고 문제점을 제시했다.
따라서 저자는 이전 작업과는 달리 model architecture와 train stage를 수정하고, 데이터 큐레이션 효과를 평가할 수 있는 간단한 latent video diffusion을 기반으로 실험을 진행했다.
이를 위해, 먼저 저자는 높은 퍼포먼스를 위해 중요하다고 판단한 다음 세 가지 다른 train stage를 정의했다.
- text-to-image pretraining
- low resolution but large dataset video pretraining
- high resolution but small dataset video finetuning
그리고 video data를 scale 측면에서 큐레이트하기 위한 체계적인 접근법을 소개하고, 이의 효과를 video pretraining 실험을 통해 제시한다. 결과적으로 잘 선별된 데이터 세트에 대해서 pretrain된 모델이 이후 high quality dataset에 대한 finetuning 과정에서 지속적으로 성능 향상을 얻을 수 있었다고 주장한다.
A general motion and multi-view prior
저자는 큐레이션 연구를 바탕으로 약 6억 개의 샘플로 구성된 video dataset에 대해서 큐레이션을 적용하고, strong motion representation을 제공할 수 있는 pretrained text-to-video를 생성했다. 그리고 이 baseline model을 활용하여 high quality dataset으로부터 text-to-video, img-to-video와 같은 downstream task의 모델을 생성했다. 결과적으로 human preference 평가 기반 sota의 image-to-video 모델보다 좋은 성능을 얻었다고 주장했다.
또한, 제안하는 모델은 strong multi-view representation을 제공하고, feed-forward 방식으로 객체의 일관된 여러 뷰를 생성할 수 있으며 기존의 모델을 능가할 수 있는 multi-view diffusion model를 생성할 수 있는 baseline model이 될 수 있음을 주장한다.
마지막으로 제안하는 모델을 기반으로 특정 모션과 유사한 dataset에 대해서 LoRA Module과 함께 학습함으로써 명시적인 모션 제어가 가능함을 입증했다.
요약하면 본 논문의 기여는 다음과 같다.
- 대규모 video dataset에 대해서 양질의 dataset으로 변환할 수 있는 체계적인 data curation workflow 제시한다.
- sota의 text-to-video와 image-to-video 모델들을 학습하여 이전의 모델보다 성능을 높였다.
- domain-specific 실험을 통해 제안하는 모델의 strong motion prior와 3D 이해력에 대한 조사 수행 및 제안하는 모델을 통해 strong multi-view generator로 전환할 수 있는 증거를 제시했다.
Background
Latent Video Diffusion Models
대부분 Video-LDM은 Latent Space에서 주 생성 모델을 훈련시킨다. 그리고 기존 작업에서는 pretrained text-to-image를 사용하고, 여러 형태의 temporal mixing layer를 pretrained architecture에 삽입하는 형태로 사용한다.
본 연구에서는 Blattmann et al.에서 제안된 아키텍처를 따르고, 모든 spatial convolution과 attention layer뒤에 temporal convolution and attention layer를 삽입한다. 이전 연구인 temporal layer만 학습하거나 training-free 방식과는 달리 전체 모델을 학습한다. 특히, text-to-video의 경우, 대부분의 작업은 text prompt에서 model에 대해서 conditioning하거나 추가적인 text-to-image prior을 사용한다.
그리고 fps에 대한 micro conditioning을 도입했으며, EDM framework를 사용하고 noise schedule을 high resolution finetuning에 필수적이라 생각되는 더 높은 noise 값으로 크게 변환한다.
Data Curation
Large Dataset에 대한 Pretrain은 성능이 높은 모델을 만들기 위한 필수 전략이다. 기존에는 CLIP과 같이 language-image representation을 활용하여 data curation에 적용했지만, video generation과 관련해서 이러한 data curation 전략은 일반적으로 논의되지 않았다.
한편, Video 모델을 학습하기 위해 일반적으로 WebVid-10M 데이터 셋을 활용한다. 논문의 저자는 WebVid-10M의 경우 종종 이미지 데이터와 함께 사용되어 image-video 학습에 이용되는데 이는 이미지와 비디오 각각의 영향에 대한 분석이 어렵게 된다고 주장했다.
이러한 문제를 해결하기위해 Video Data Curation 방법에 대한 체계적인 연구를 제시하고, 최종적으로 제안하는 모델로 SOTA를 달성했다.
Curating Data for HQ Video Synthesis
논문의 저자는 Large Video Dataset에 대한 SOTA 모델을 학습하기 위한 다음 전략을 소개한다.
. Data Processing과 Curation Method
. Data Processing과 Curation Method에 따른 모델 품질에 대한 영향 분석
. Generative Video Modeling을 위한 3가지 학습 체제 : Image Pretraining, Video Pretraining, Video FineTuning
Data Processing and Annotation
먼저, 저자들은 Pretrain을 위한 long video의 초기 데이터 셋을 수집했다. 그리고 cut과 fade가 synthetic video에서 발생되지 않게 cut detection pipeline1을 세 가지 FPS Level에서 수행했다.
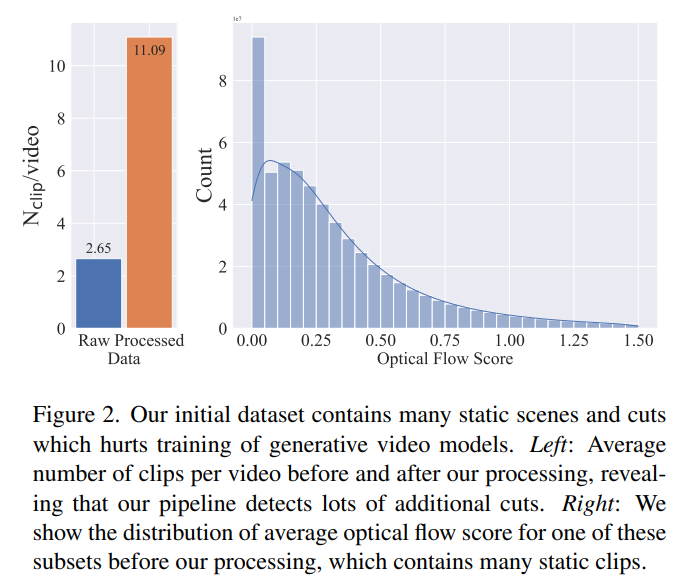
위의 그림을 보면, cut detection을 적용하기 전보다 대략 4배의 clip을 얻을 수 있었고 이를 통해 cut detection의 필요성을 알 수 있다.
그리고 다음의 방법으로 클립에 대한 캡션을 생성했다.
1. CoCA 기반 클립 중간 프레임 캡션 생성
2. V-BLIP 기반 비디오 캡션 생성
3. LLM 기반 1과 2에서 얻은 캡션 종합
최종적으로 초기 데이터 셋인 LVD(Large Video Dataset)는 212년 분량의 580M 주석을 가진 video clip쌍으로 구성된다.
한편, 저자는 데이터 셋에는 움직임이 적거나 텍스트가 과도하게 존재하여 video generation model의 성능을 저하 시킬 수 있는 요소들이 존재하는 것을 확인했다. 이에 따라 dense optical flow 기반 주석을 추가 생성했으며, 2fps를 기준으로 average optical flow가 특정 threshold 미만인 비디오를 제거했다.
추가적으로 OCR(Optical Character Recognition)을 적용하여 텍스트가 많은 클립을 제거했고, CLIP 임베딩을 기반으로 각 클립의 처음, 중간, 마지막 프레임에 주석을 생성하여 aesthetics score와 text-image 유사성을 계산했다.
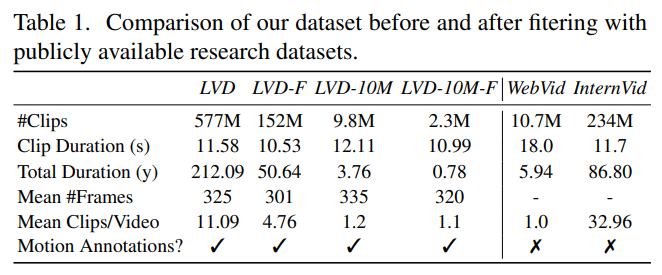
클립 전체 크기 및 평균 지속 시간을 포함한 통계 수치는 위와 같다.
Stage I: Image Pretraining
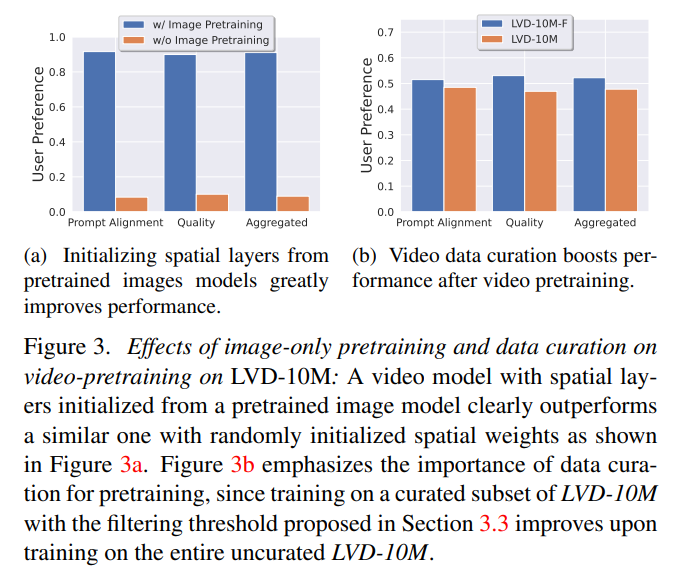
논문의 저자는 Image Pretraining 과정에서 Stable Diffusion v2.1 모델을 베이스라인으로 선택했다.
Fig 3(a)을 보면 Image-Pretrained Model이 quality와 prompt-following 측면에서 모두 월등한 결과를 얻을수 있다는 걸 확인할 수 있다.
Stage II: Curating a Video Pretraining Dataset
A systematic approach to video data curation
비디오 도메인의 경우 원하지 않는 데이터를 필터링할 수 있는 기성 방법이 미흡하기 때문에 human preference에 의존했다. 특히, LVD의 subset에서 학습된 latent video diffusion model의 human preference 기반 순위를 고려했다.
구체적으로, 각 유형의 주석(CLIP score, aesthetic score, optical flow score)에 대해서 LVD, LVD-10M에서 필터링되지 않고 랜덤 샘플링된 9.8M 크기의 subset에서 시작해서 하위 12.5, 25, 50%의 예제를 체계적으로 제거했고, 이러한 이유로 synthetic caption은 필터링 할 수 없다.
앞서 필터링된 각 subset에 대해서 학습한 모델로 얻은 결과를 human preference 투표에 대한 Elo 순위와 비교했다.
이 투표 결과를 기반으로 각 유형의 주석에 대한 filtering threshold를 선택했다. 이 필터링 접근 방식을 LVD에 적용하여 152M 학습 예제에 대한 최종 pretrain dataset이 생성되고 이는 Tab 1.에서 언급된 LVD-F를 의미한다.
Curated training data improves performance.
이 섹션에서는 위에서 설명한 데이터 큐레이션 접근 방식으로 생성된 데이터 셋에서 학습된 video diffusion model과 큐레이션이 적용되지 않은 데이터 셋으로 학습된 모델을 비교한다.
Fig 3b를 보면, LVD-F의 경우 LVD보다 약 4배 적은 데이터를 사용하지만 일괄적으로 성능이 높은 것을 확인할 수 있다. 그리고 Fig 4b를 보면 WebVid-10M, InterVid10M 데이터 셋에 대해서 추가적인 비교를 진행했느데 spatial and temporal quality와 prompt alignment 모두 약 4배 적은 데이터 셋인 LVD-F에서 학습된 모델의 성능이 높음을 알 수 있다.
Data curation helps at scale.
저자는 또한 Scale에 따른 실험을 진행했다. 위와 동일한 실험을 50M의 데이터 셋에 대해서 진행했는데 결과적으로 동일하게 성능이 향상된 것을 확인할 수 있었고, LVD-10M-F보다 우수한 성능을 얻을 수 있음을 확인했다.
Stage III: High Quality Finetuning
Stage III에서는 기존의 Latent Diffusion Modeling(EMU, SDXL)을 활용하고, 250k의 caption-video clip으로 구성된 적지만 높은 해상도를 가진 학습 데이터에 대해서 finetuning 작업을 진행한다.
이번 섹션에서는 video pretrain의 영향을 분석하기 위해, 구조는 같고 초기화 방식이 다른 방법을 사용한다.
1. Pretrained Image Model 기반 가중치 초기화 (단, Video Pretrain 생략)
2. 50M Video Dataset에 대해서 Curation을 적용한 Video Pretrained 모델로 가중치 초기화
3. 50M Video Dataset에 대해서 Curation을 적용하지 않은 Video Pretrained 모델로 가중치 초기화
위 각 모델에 대한 human preference 기반 평가 결과, 일관적으로 curate된 데이터 셋의 성능이 높은 것을 확인할 수 있다.
이 결과를 통해 다음과 같은 사실을 알 수 있다고 저자는 주장한다.
1. video model train 과정에서 video pretrain과 video fintuning 과정을 분리하는 것이 최종 모델 성능 향상에 도움이 된다.
2. video finetuning시에 pretrain의 영향을 받기 때문에 video pretrain은 large scale & curated dataset에서 이뤄줘야 한다.
Training Video Models at Scale
Pretrained Base Model
논문에서는 Stable Diffusion v2.1 모델을 베이스라인으로 다음 Pretrain 과정을 진행했다.
1. 256x384 크기의 이미지에 대해서 Karras et al.에서 제안한 network preconditioning을 사용하여 image model의 고정된 discrete noise schedule에서 continuous noise noise schedule로 finetuning 과정 수행
2. temporal layer를 삽입 후 EDM noise scheduler를 사용하여 256x384 해상도의 14개 프레임을 가지는 LVDF에서 모델 학습
3. 14개의 320x576 프레임을 생성할 수 있도록 768 batch size에서 100k iteration 학습 수행. 단, 이 과정동안 Hoogeboom et al.에서 주장한 고해상도 이미지 학습시에 noise schedule을 더 많은 noise로 전환하는 것이 중요함을 확인
High-Resolution Text-to-Video Model
baseline 모델로부터 1M의 high-quality video dataset에 대해서 finetuning 과정을 수행한다. 이 과정에서는 576x1024의 해상도에서 768 batch size로 50k iteration 학습을 진행한다. (단, 여기서도 동일하게 더 많은 노이즈로 변경)
생성 결과는 Fig 5와 같다.
High Resolution Image-to-Video Model
image-to-video의 경우는 text embedding이 아닌 clip image embedding conditioning으로 변경하고 추가적으로 UNet의 입력인 noise-augmentaed conditioning을 채널별로 연결했다.
여기서, 어떠한 마스킹 기법도 사용하지 않고 단순하게 temporal layer에 걸쳐 프레임을 복사했고 각각 14, 25개의 프레임을 예측하는 모델을 구현했다.
한편, standard vanilla classifier-free guidance에서 guidance가 적으면 conditioning frame 불일치가 생기고, guidance scale이 큰 경우 oversaturation이 생기는 현상이 발생했는데, 논문에서는 이러한 현상을 완화하기 위해 프레임별로 guidance scale을 선형적으로 증가시켰다.
Camera Motion LoRA
temporal attention block에서 camera motion LoRA 학습 및 결과
Frame Interpolation
Blattmann et al.를 따르고 Masking을 통해 왼쪽과 오른쪽 프레임을 UNet 입력과 연결하여 3개의 프레임을 예측하도록 학습했고, 매우 적은 수의 반복(~10k) 학습임에도 높은 성능을 얻었다.
Conclusion
i. 체계적인 data selection과 scaling 연구 그리고 large dataset에 대한 curation method를 통해 generative video model에 적합한 pretrain dataset 생성
ii. 개별적인 3단계의 학습을 통해 높은 성능의 최종 모델 생성
iii. SVD을 통해 camera control을 위한 LoRA Module를 비롯한 다양한 Application에서 strong video representation 제공
iiii. SVD의 강력한 3D prior를 통한 multi-view diffusion model에서의 활용 가능성
