
동기
1편의 카테고리별 리뷰 조회를 시작으로 500ms가 넘어가는 요청들을 위주로 Cardinality/Selectivity를 고려하여 인덱스를 생성했다. 하지만 1편까지는 진짜 대용량 데이터베이스는 아니였다. 2편부터 여기어때컴퍼니 벤처 프로젝트인만큼 여기어때 홍보자료에 있는 데이터 규모에서 성능을 측정해보고 필요하다면 개선까지 진행해보자.
기존 테스트 데이터 스케일
- 여행상품: 30 (각 카테고리 10개씩, 숙소, 식당, 렌터카)
- 예약: 540,000 (카테고리 별 180,000)
- 여행상품 마다 18,000개의 예약- 리뷰: 540,000 (카테고리 별 180,000)
- 모든 예약에 리뷰 작성- 리뷰 태그: 2,700,000 (카테고리 별 900,000)
- 각 리뷰당 5개의 리뷰 태그
성능 테스트
테스트 데이터 구축
여기어때 사이트에 의하면 600만 개 이상의 리뷰를 제공하고 있다고 한다. 이에 맞게 더미 데이터를 추가해보자. 600만 건의 예약과 리뷰 데이터를 추가하고 각 리뷰당 3개의 리뷰 분석 값이 있다고 가정하자. 여기어때의 인기 숙소들은 5000개 정도의 리뷰가 달리므로, 한 상품 당 5000개가 등록될 수 있도록 상품의 개수와 연관관계를 설정했다.
- 여행상품: 1200
- 예약: 6,000,000
- 여행상품 마다 5,000개의 예약 - 리뷰: 6,000,000
- 모든 예약에 리뷰 작성 - 리뷰 태그: 18,000,000
- 각 리뷰당 3개의 리뷰 태그

여기어때 공식 사이트 (https://gccompany.co.kr/)
성능 측정
| 요청 | 요청 처리 시간 |
|---|---|
| 리뷰 단일 조회 | 30 ms |
| 리뷰 목록 조회 (LIMIT 10) | 37 ms |
| 카테고리 별 리뷰 목록 조회 (LIMIT 10) | 7504 ms |
| 카테고리+키워드 별 리뷰 목록 조회 (LIMIT 10) | 4550 ms |
| 별점순 리뷰 목록 조회 (LIMIT 10) | 41 ms |
| 긍정적인순 리뷰 목록 조회 (LIMIT 10) | 35 ms |
| 상품의 리뷰 통계 조회 | 71 ms |
| 상품의 리뷰태그 통계 조회 | 107 ms |
정상적으로 인덱스를 타서 준수한 성능을 보이지만, 일부 비정상적인 요청이 있다. 1편에서 집중적으로 다룬 리뷰 속성과 키워드 필터링 조회 요청이다. 특정 태그를 가진 리뷰를 정렬 및 페이징해야 하므로, 인덱스가 적용되어도 full scan해야 한다. 아래 시행 계획을 보면 Full Index Scan이 실행되었고 17802236 rows가 조회된 것을 확인할 수 있다.
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | review1_ | null | index | PRIMARY | review_created_at_index | 9 | null | 10 | 100 | null |
| 1 | SIMPLE | <subquery2> | null | eq_ref | <auto_distinct_key> | <auto_distinct_key> | 8 | Reviewmate.review1_.review_id | 1 | 100 | null |
| 2 | MATERIALIZED | reviewtag4_ | null | index | review_tag_review_id_property_keyword_index,review_tag_review_id_property_polarity_index | review_tag_review_id_property_polarity_index | 2052 | null | 17902236 | 10 | Using where; Using index |
개선
문제 파악
select
review1_.review_id as review_i1_8_,
review1_.created_at as created_2_8_,
review1_.updated_at as updated_3_8_,
review1_.content as content4_8_,
review1_.negative_tags_count as negative5_8_,
review1_.polarity as polarity6_8_,
review1_.positive_tags_count as positive7_8_,
review1_.rating as rating8_8_,
review1_.reservation_id as reserva10_8_,
review1_.title as title9_8_
from
review review1_
where
exists (
select
1
from
review_tag reviewtag4_
where
reviewtag4_.review_id=review1_.review_id
and reviewtag4_.property="ROOM"
)
order by
review1_.created_at desc limit 10;현재 적용되어 있는 인덱스는 2가지 이다.
reviewtag index (review_id, property)review index (created_at DESC)
where 절에서 사용되는 테이블들에 인덱스를 적용하였고 SQL explain을 통해 정상적으로 인덱스를 타고 있음에도 긴 시간이 소모된다. 도저히 모르겠어서 동아리 선배님들이 모여있는 슬랙에서 조언을 구해봤다.

그렇다. 실제로 SQL explain에 따르면 reviewtag scanning rows는 17,902,236나 된다. 쿼리로 짐작하건데, exists를 통해 리뷰에 달린 리뷰태그 중에서 ROOM property가 있는 리뷰를 10개 찾을 때까지 선형적으로 풀 스캔을 하고 있는 것이라고 짐작이 된다. 메인 쿼리의 스캔 범위를 줄여야하는데 1800만개를 스캔하고 있으면 오래 걸릴 수 밖에 없을 것이다.
옵티마이저는 SQL을 최대한 효율적으로 동작하기 위해 다양한 최적화를 자동으로 적용한다고 알고 있는데, 정말 방법이 없는 것일까? 쿼리의 실행 계획을 더 자세히 알았는데, 순서가 예상과는 조금 달랐다. 하나하나 조사해보자.
explain analysis graph

1. property filter
우선 전체 리뷰태그 중에서 property 컬럼이 ROOM인 것만 필터링한다.

2. deduplication
리뷰에는 3개의 리뷰태그가 연관되므로, 중복되는 태그들을 제거하는 deduplication 과정을 거친다. 다이어그램에 적혀있는 rows는 통계를 통한 추청치이고, 실제로 propert가 ROOM 태그만 골랐다면 800,000 정도 된다.
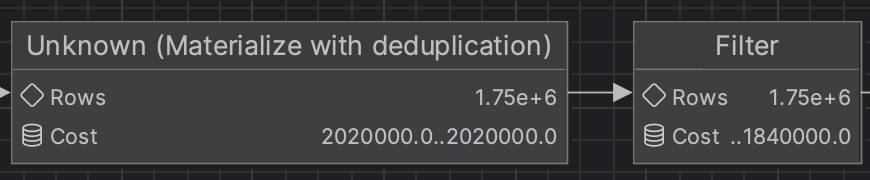
Materialize는 MySQL이 서브쿼리나 복잡한 조인을 처리할 때, 중간 결과를 임시 테이블에 저장하는 과정을 말한다. 더욱 효율적으로 쿼리를 처리할 수 있고 반복적인 계산을 줄일 수 있다.
3. FK를 통한 Nested loop inner join
필터링과 중복이 제거된 리뷰 태그를 review와 join을 통해 데이터를 조회한다.
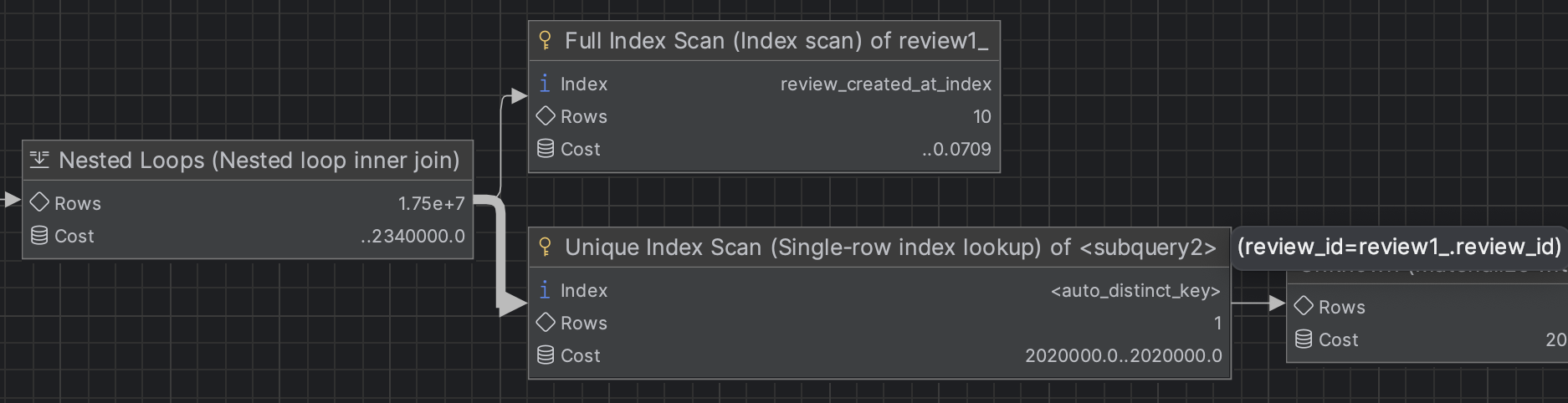
4. LIMIT, SELECT
물론 MySQL 내부적으로 잘 최적화되어 800000개 전부 Join하지는 않고 필요한 10개만 Join 후 결과를 반환했을 것이다.

최적화
이상하다.. 나는 분명 reviewtag4_.review_id=review1_.review_id and reviewtag4_.property="ROOM" 로 where 절을 작성했으므로 인덱스도 이 순서로 적용하였다. 하지만 실제 실행 순서를 반대였다. 아마도, 1:N 관계인 리뷰와 리뷰태그 관계 상, 리뷰와 관계된 리뷰태그를 불러와서 property를 확인하는 것보다 property를 충족하는 리뷰태그의 중복을 제거하고 리뷰와 연관시키는게 효율적이라고 판단한 것 같다.
그렇다면 이 순서에 맞게 인덱스를 적용해보면 어떨까? 결과는 성공적이다!
reviewtag index (property, review_id)
explain analysis graph

property filter와 deduplication이 한 단계로 합쳐졌다. 이전에는 순서가 맞지 않아 property filter 이후 review_id를 통한 deduplicationdl 불가능했지만, 이제는 covering index로 한 번에 가능하여 두 단계가 통합된 것 같다. 단적으로 수치만 비교하자면 100만 건 이상의 스캔이 생략된 것이다. 그 결과 쿼리 실행시간도 7.5초에서 1.5초로 단축되었다.

explain analysis
-> Limit: 10 row(s) (cost=2.05e+6 rows=10) (actual time=1552..1552 rows=10 loops=1)
-> Nested loop inner join (cost=2.05e+6 rows=14.5e+6) (actual time=1552..1552 rows=10 loops=1)
-> Index scan on review1_ using review_created_at_index (cost=0.0707 rows=10) (actual time=0.0462..0.0762 rows=14 loops=1)
-> Single-row index lookup on <subquery2> using <auto_distinct_key> (review_id=review1_.review_id) (cost=466650..466650 rows=1) (actual time=111..111 rows=0.714 loops=14)
-> Materialize with deduplication (cost=466649..466649 rows=1.45e+6) (actual time=1552..1552 rows=800000 loops=1)
-> Covering index lookup on reviewtag4_ using review_tag_property_review_id_index (property='ROOM') (cost=321768 rows=1.45e+6) (actual time=0.0266..323 rows=800000 loops=1)실제 스케일 적용
아직 빠드린 것이 있다. 성능 저하가 발생하는 리뷰 태그 부분이 추가된 쿼리만 다뤘는데, 이제는 상품이 소속된 여행사와 리뷰가 소속된 상품을 비교하는 조건절도 추가되어야 한다. 이에 맞게 인덱스도 정돈하면 다음과 같다.

실행시간도 1500 ms -> 120 ms로 대폭 감소되었는데, 이전까지는 2400만 개(리뷰 600만 + 리뷰태그 1200만)를 대상으로 조회했다면 현재는 2만 개(리뷰 5000 + 리뷰태그 10000)를 대상으로 조회하고 있다. 따라서 성능 저하가 발생하는 리뷰와 리뷰태그의 개수가 줄어들어 scanning rows 자체가 줄어들어서이다.
마무리
긴 시간 동안 수 많은 시도와 착오의 끝에 2400만 개의 데이터(리뷰 600만 + 리뷰태그 1200만)를 대상으로 94%의 성능 개선을 이뤄내 매우 만족스러운 결과로 마무리되었다. 가장 크게 배운 것은 쿼리 실행 계획 분석법과 인덱스 생성 전략인 것 같다. 처음 인덱스를 배우면서 불완전하게 배운 이론만을 바탕으로 최적화하다보니 많은 시행착오를 겪었지만, 그 과정에서 실제 동작하는 DB 엔진과 옵티마이저의 동작에 맞게 인덱스를 튜닝해나가는 법을 배울 수 있었다. 특히, "인덱스의 순서가 맞지 않으면 제대로 인덱스를 제대로 타지 않는 것"과 "인덱스를 제대로 타지 않는 것"의 진정한 의미를 경험할 수 있었다. 가볍게 이론을 배우고 인덱스를 통한 데이터베이스 튜닝을 직접 부딪혀보며 많은 것을 배웠으니, 이 경험을 바탕으로 더 깊은 이론도 배워볼까 한다.
성능 개선 결과
| 요청 | 기존 조회 시간 | 전체 리뷰 대상 조회 시간 | 상품 리뷰 대상 조회 시간 |
|---|---|---|---|
| 리뷰 단일 조회 | 30 ms | 33 ms | 32 ms |
| 리뷰 목록 조회 (LIMIT 10) | 37 ms | 35 ms | 113 ms |
| 카테고리 별 리뷰 목록 조회 (LIMIT 10) | 7504 ms | 1555 ms | 132 ms |
| 카테고리+키워드 별 리뷰 목록 조회 (LIMIT 10) | 4550 ms | 10 ms | 11 ms |
| 별점순 리뷰 목록 조회 (LIMIT 10) | 41 ms | 36 ms | 89 ms |
| 긍정적인순 리뷰 목록 조회 (LIMIT 10) | 35 ms | 33 ms | 76 ms |
| 상품의 리뷰 통계 조회 | 71 ms | 70 ms | 40 ms |
| 상품의 리뷰태그 통계 조회 | 107 ms | 188 ms | 176 ms |
| 기존 대비 개선율 | 84 % | 94 % |
다양한 시행착오들
Join으로 Exists 서브 쿼리 대체
QueryDSL any() 가 자동 생성한 where(exist(select 1 ~))) 를 사용하고 있지만, reviewtag scan rows가 굉장히 큰 것으로 보아 인덱스를 제대로 타지 않는 것으로 보인다. 서브쿼리 구조의 한계일 수 있다고 생각되어, 서브쿼리 대신 join을 이용해보자.
select
distinct review0_.review_id as review_i1_8_,
review0_.created_at as created_2_8_,
review0_.updated_at as updated_3_8_,
review0_.content as content4_8_,
review0_.negative_tags_count as negative5_8_,
review0_.polarity as polarity6_8_,
review0_.positive_tags_count as positive7_8_,
review0_.rating as rating8_8_,
review0_.reservation_id as reserva10_8_,
review0_.title as title9_8_
from
review review0_
inner join
review_tag reviewtags1_
on review0_.review_id=reviewtags1_.review_id
where
reviewtags1_.property="ROOM"
order by
review0_.created_at desc limit 10;14초 정도로 오히려 성능이 저하되었다. 특히 리뷰태그 비교가 들어가지 않아 굉장히 빠르던 간단한 조회들이 40초 넘게 걸리는 등의 모습을 보였다.
인덱스 주의
기존의 Exists 방식의 where 절 내부에서 reviewtag의 review_id와 property를 사용하므로 인덱스도 reviewtag index(review_id, property, keyword)를 쓰고 있었다. 하지만 Join 방식 쿼리의 where절에서 더이상 review_id를 사용하지 않음에도 인덱스는 정상적으로 타지는데, 쿼리 실행시간은 매우 길어졌다.
하지만 인덱스를 reviewtag index(property, keyword)로 정상적으로 변경하면, 마찬가지로 변경된 인덱스로 타지며 실행시간도 굉장히 짧아진다. 실행계획으로 비교하면 reviewtag의 scan 단계에서 actual rows: 18e+6 -> 800,000로 대폭 감소했으며 Filter 단계가 생략됐다. 기존의 인덱스는 review_id 처음에 있던 탓에 풀스캔처럼 동작하였고, 이후 인덱스는 정상적으로 커버링 인덱스로 동작하였다.
아마, 옵티마이저가 비효율적인 인덱스 VS 풀스캔을 비교했을 때, 그래도 비효율적인 인덱스가 더 효율적이라 인덱스를 탄 것 같다. 인덱스의 시작점이 다르면 인덱스가 타지지 않는다는 이론적인 배움에만 의존해서 key 부분만 비교했는데, 더욱 면밀히 살펴보며 주의해야할 것 같다.
Distinct VS Group by
Review 1 : Reviewtag N 관계이므로, 중복되는 리뷰 데이터를 방지하기 위해 deduplication 과정이 필요하다. 문법적으로 가장 목적에도 맞고 일반적으로 더 빠른 distinct를 쓰고 있었는데, Join 방식의 쿼리에서는 직접 시도해보니 달랐다.
distinct 실행계획
-> Temporary table with deduplication (cost=2.4e+6..2.4e+6 rows=1.62e+6) (actual time=13088..13088 rows=800000 loops=1)group by 실행계획
-> Temporary table with deduplication (cost=2.4e+6..2.4e+6 rows=1.62e+6) (actual time=8587..8587 rows=800000 loops=1)관련된 자료를 아무리 조사해도 일반적으로는 distinct가 빠르다는 자료 밖에 찾을 수 없었다. 실행 계획 상 cost는 같음에도 actual time이 차이가 난다. 일단은 더 빠른 group by를 채용하였다. 실행 시간은 8초 정도였다.
