OpenSearch 소개
https://docs.opensearch.org/latest/getting-started/intro/
OpenSearch는 웹사이트의 검색창 구현부터 위협 탐지를 위한 보안 데이터 분석까지 다양한 사용 사례를 지원하는 분산 검색 및 분석 엔진입니다. 분산이라는 용어는 OpenSearch를 여러 컴퓨터에서 실행할 수 있다는 의미입니다. 검색 및 분석은 데이터를 OpenSearch에 수집한 후 검색하고 분석할 수 있다는 의미입니다. 데이터 유형에 관계없이 OpenSearch를 사용하여 저장하고 분석할 수 있습니다.
문서 (Document)
문서는 정보(텍스트 또는 구조화된 데이터)를 저장하는 단위입니다. OpenSearch에서 문서는 JSON 형식으로 저장됩니다.
문서는 여러 가지 방식으로 생각할 수 있습니다:
- 학생 데이터베이스에서 문서는 한 명의 학생을 나타낼 수 있습니다
- 정보를 검색할 때, OpenSearch는 검색과 관련된 문서를 반환합니다
- 문서는 기존 데이터베이스의 행을 나타냅니다
예를 들어, 학교 데이터베이스에서 문서는 한 명의 학생을 나타내며 다음과 같은 데이터를 포함할 수 있습니다:
| ID | 이름 | 평점 | 졸업년도 |
|---|---|---|---|
| 1 | 홍길동 | 3.89 | 2022 |
이 문서를 JSON 형식으로 나타내면 다음과 같습니다:
{
"name": "홍길동",
"gpa": 3.89,
"grad_year": 2022
}문서 ID가 어떻게 할당되는지는 "문서 인덱싱"에서 배우게 됩니다.
인덱스 (Index)
인덱스는 문서의 모음입니다.
인덱스는 여러 가지 방식으로 생각할 수 있습니다:
- 학생 데이터베이스에서 인덱스는 데이터베이스의 모든 학생을 나타냅니다
- 정보를 검색할 때, 인덱스에 포함된 데이터를 쿼리합니다
- 인덱스는 기존 데이터베이스의 테이블을 나타냅니다
예를 들어, 학교 데이터베이스에서 인덱스는 학교의 모든 학생을 포함할 수 있습니다:
| ID | 이름 | 평점 | 졸업년도 |
|---|---|---|---|
| 1 | 홍길동 | 3.89 | 2022 |
| 2 | 김철수 | 3.85 | 2025 |
| 3 | 이영희 | 3.52 | 2024 |
| … | … | … | … |
클러스터와 노드
OpenSearch는 분산 검색 엔진으로 설계되었으며, 이는 데이터를 저장하고 검색 요청을 처리하는 서버인 하나 이상의 노드에서 실행할 수 있다는 의미입니다. OpenSearch 클러스터는 노드의 모음입니다.
OpenSearch를 랩톱에서 로컬로 실행할 수 있습니다(시스템 요구사항이 최소한임). 하지만 단일 클러스터를 데이터 센터의 수백 대의 강력한 머신으로 확장할 수도 있습니다.
랩톱에 배포된 것과 같은 단일 노드 클러스터에서는 한 대의 머신이 모든 작업을 수행해야 합니다: 클러스터 상태 관리, 데이터 인덱싱 및 검색, 인덱싱 전 데이터의 전처리. 그러나 클러스터가 커지면 책임을 세분화할 수 있습니다. 빠른 디스크와 충분한 RAM을 가진 노드는 데이터 인덱싱 및 검색에서 좋은 성능을 발휘할 수 있는 반면, 충분한 CPU 성능과 작은 디스크를 가진 노드는 클러스터 상태를 관리할 수 있습니다.
각 클러스터에는 인덱스 생성과 같은 클러스터 수준 작업을 조율하는 선출된 클러스터 매니저 노드가 있습니다. 노드들은 서로 통신하므로, 요청이 한 노드로 라우팅되면 해당 노드가 다른 노드들에 요청을 보내고, 노드들의 응답을 수집하여 최종 응답을 반환합니다.
다른 노드 유형에 대한 자세한 정보는 "클러스터 형성"을 참조하세요.
샤드 (Shards)
OpenSearch는 인덱스를 샤드로 분할합니다. 각 샤드는 다음 이미지에 표시된 것처럼 인덱스의 모든 문서 중 일부를 저장합니다.
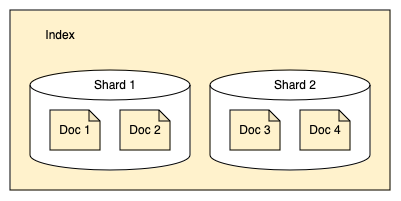
인덱스가 샤드로 분할됨
샤드는 클러스터의 노드 간 균등 분배에 사용됩니다. 예를 들어, 400GB 인덱스는 클러스터의 단일 노드가 처리하기에는 너무 클 수 있지만, 각각 40GB인 10개의 샤드로 분할하면 OpenSearch가 10개 노드에 샤드를 분산하고 각 샤드를 개별적으로 관리할 수 있습니다. 2개의 인덱스(인덱스 1과 인덱스 2)가 있는 클러스터를 고려해보세요. 인덱스 1은 2개의 샤드로 분할되고, 인덱스 2는 4개의 샤드로 분할됩니다. 다음 이미지에 표시된 것처럼 샤드들은 노드 1과 노드 2에 분산됩니다.
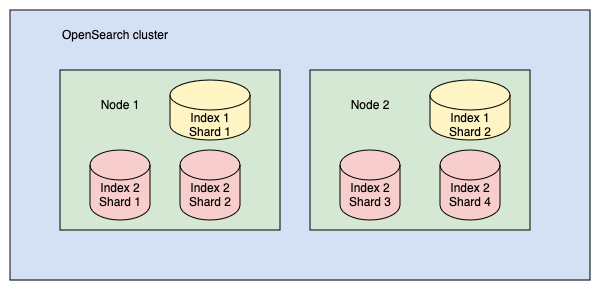
두 개의 인덱스와 두 개의 노드를 포함하는 클러스터
OpenSearch 인덱스의 한 부분이지만, 각 샤드는 실제로는 완전한 Lucene 인덱스입니다. 이 세부사항은 Lucene의 각 인스턴스가 CPU와 메모리를 소비하는 실행 프로세스이기 때문에 중요합니다. 샤드가 많다고 해서 반드시 좋은 것은 아닙니다. 예를 들어, 400GB 인덱스를 1,000개의 샤드로 분할하면 클러스터에 불필요한 부담을 줄 수 있습니다. 샤드 크기를 10-50GB로 제한하는 것이 좋은 경험 법칙입니다.
프라이머리 샤드와 레플리카 샤드
OpenSearch에서 샤드는 프라이머리(원본) 샤드 또는 레플리카(복사본) 샤드일 수 있습니다. 기본적으로 OpenSearch는 각 프라이머리 샤드에 대해 레플리카 샤드를 생성합니다. 따라서 인덱스를 10개의 샤드로 분할하면 OpenSearch는 10개의 레플리카 샤드를 생성합니다. 예를 들어, 이전 섹션에서 설명한 클러스터를 고려해보세요. 클러스터의 각 인덱스의 각 샤드에 대해 1개의 레플리카를 추가하면, 다음 이미지에 표시된 것처럼 클러스터는 인덱스 1에 대해 총 2개의 샤드와 2개의 레플리카, 인덱스 2에 대해 4개의 샤드와 4개의 레플리카를 포함하게 됩니다.
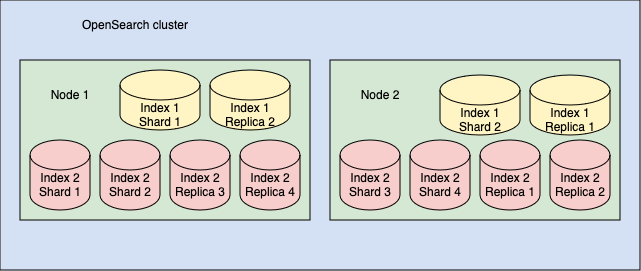
각 인덱스의 각 샤드에 대해 하나의 레플리카 샤드를 가진 두 개의 인덱스를 포함하는 클러스터
이러한 레플리카 샤드는 노드 장애 시 백업 역할을 합니다. OpenSearch는 레플리카 샤드를 해당 프라이머리 샤드와 다른 노드에 배포합니다. 또한 클러스터가 검색 요청을 처리하는 속도도 향상시킵니다. 검색 집약적인 워크로드의 경우 인덱스당 둘 이상의 레플리카를 지정할 수 있습니다.
역인덱스 (Inverted Index)
OpenSearch 인덱스는 역인덱스라는 데이터 구조를 사용합니다. 역인덱스는 단어를 해당 단어가 나타나는 문서에 매핑합니다. 예를 들어, 다음 두 문서를 포함하는 인덱스를 고려해보세요:
- 문서 1: "아름다움은 보는 이의 눈에 있다"
- 문서 2: "미녀와 야수"
이러한 인덱스에 대한 역인덱스는 단어를 해당 단어가 나타나는 문서에 매핑합니다:
| 단어 | 문서 |
|---|---|
| 아름다움 | 1 |
| 은 | 1 |
| 보는 | 1 |
| 이의 | 1 |
| 눈에 | 1 |
| 있다 | 1 |
| 미녀와 | 2 |
| 야수 | 2 |
문서 ID 외에도 OpenSearch는 단어들이 서로 인접하게 나타나야 하는 구문 쿼리 실행을 위해 문서 내에서 단어의 위치를 저장합니다.
관련성 (Relevance)
문서를 검색할 때, OpenSearch는 쿼리의 단어를 문서의 단어와 일치시킵니다. 예를 들어, 이전 섹션에서 설명한 인덱스에서 "아름다움"이라는 단어를 검색하면, OpenSearch는 문서 1과 2를 반환합니다. 각 문서는 해당 문서가 쿼리와 얼마나 잘 일치하는지를 알려주는 관련성 점수를 할당받습니다.
검색 쿼리의 개별 단어를 검색어라고 합니다. 각 검색어는 다음 규칙에 따라 점수가 매겨집니다:
-
문서에서 더 자주 나타나는 검색어는 더 높은 점수를 받는 경향이 있습니다. 개라는 단어를 여러 번 사용하는 개에 관한 문서는 개라는 단어를 적게 포함하는 문서보다 더 관련성이 높을 가능성이 있습니다. 이것이 점수의 단어 빈도 구성 요소입니다.
-
더 많은 문서에서 나타나는 검색어는 더 낮은 점수를 받는 경향이 있습니다. "파란색"과 "아홀로틀"이라는 용어에 대한 쿼리는 더 일반적인 단어인 "파란색"보다 "아홀로틀"을 포함하는 문서를 선호해야 합니다. 이것이 점수의 역문서 빈도 구성 요소입니다.
-
긴 문서의 일치는 짧은 문서의 일치보다 낮은 점수를 받는 경향이 있습니다. 전체 사전을 포함하는 문서는 모든 단어와 일치하지만 특정 단어에 대해서는 그다지 관련성이 없습니다. 이것이 점수의 길이 정규화 구성 요소에 해당합니다.
OpenSearch는 BM25 순위 알고리즘을 사용하여 문서 관련성 점수를 계산한 다음 관련성에 따라 정렬된 결과를 반환합니다. 자세한 내용은 "Okapi BM25"를 참조하세요.
다음 단계
- "설치 빠른 시작"에서 몇 분 안에 OpenSearch를 설치하는 방법을 배우세요.
- 문서 인덱싱에 대해 학습하세요.
- 검색 기능에 대해 알아보세요.
