opensearch
1.OpenSearch Multimodal 번역

2.11에서 도입됨멀티모달 임베딩 모델을 사용하여 텍스트와 이미지 데이터를 검색하는 멀티모달 검색을 사용하십시오.텍스트 검색을 사용하기 전에 멀티모달 임베딩 모델을 설정해야 합니다. 자세한 내용은 모델 선택을 참조하십시오.멀티모달 검색을 구성하는 방법에는 두 가지가 있
2.Custom local models - OpenSearch 번역
2.9에서 도입됨사용자 정의 모델을 로컬에서 사용하려면 OpenSearch 클러스터에 업로드할 수 있습니다.OpenSearch 2.6부터 OpenSearch는 로컬 텍스트 임베딩 모델을 지원합니다.OpenSearch 2.11부터 OpenSearch는 로컬 스파스 인코딩
3.Concurrent segment search
https://docs.opensearch.org/latest/search-plugins/concurrent-segment-search/쿼리 단계 중에 세그먼트를 병렬로 검색하려면 동시 세그먼트 검색을 사용하세요.
4.Collapsing hybrid query results
https://docs.opensearch.org/latest/vector-search/ai-search/hybrid-search/collapse/3.1 버전에서 도입됨collapse 매개변수를 사용하면 필드별로 결과를 그룹화하여 각 고유 필드 값에 대해 가장
5.사후 필터링을 사용한 하이브리드 검색
https://docs.opensearch.org/latest/vector-search/ai-search/hybrid-search/inner-hits/2.13 버전에서 도입됨쿼리에 post_filter 매개변수를 제공하여 하이브리드 검색 결과에 사후 필터링을
6.Availability and recovery settings
https://docs.opensearch.org/latest/install-and-configure/configuring-opensearch/availability-recovery/가용성 및 복구 설정에는 다음과 같은 설정이 포함됩니다:스냅샷클러스터 관리자
7.Search settings
https://docs.opensearch.org/latest/install-and-configure/configuring-opensearch/search-settings/OpenSearch는 다음과 같은 검색 설정을 지원합니다:search.max_bucket
8.Discovery and gateway settings
https://docs.opensearch.org/latest/install-and-configure/configuring-opensearch/discovery-gateway-settings/다음은 디스커버리 및 로컬 게이트웨이와 관련된 설정입니다.정적 및 동
9.Configuration and system settings
https://docs.opensearch.org/latest/install-and-configure/configuring-opensearch/configuration-system/
10.Semantic search using the OpenAI embedding model
https://docs.opensearch.org/latest/tutorials/vector-search/semantic-search/semantic-search-openai/이 튜토리얼에서는 OpenAI 임베딩 모델을 사용하여 Amazon OpenSearch
11.Optimizing vector search using Cohere compressed embeddings
https://docs.opensearch.org/latest/tutorials/vector-search/vector-operations/optimize-compression/이 튜토리얼에서는 Cohere 압축 임베딩을 사용하여 벡터 검색을 최적화하는 방법을
12.Getting started with semantic and hybrid search
기본적으로 OpenSearch는 Okapi BM25 알고리즘을 사용하여 문서 점수를 계산합니다. BM25는 키워드를 포함하는 쿼리에서는 좋은 성능을 보이지만 쿼리 용어의 의미론적 의미를 포착하지 못하는 키워드 기반 알고리즘입니다. 의미론적 검색은 키워드 기반 검색과 달
13.Search your data
https://docs.opensearch.org/latest/getting-started/search-data/OpenSearch에서는 데이터를 검색하는 여러 가지 방법이 있습니다:쿼리 도메인 특화 언어(DSL): 복잡하고 완전히 사용자 정의 가능한 쿼리를
14.Concepts
https://docs.opensearch.org/latest/getting-started/concepts/이 페이지는 OpenSearch와 관련된 주요 용어와 개념을 정의합니다.문서(Document): OpenSearch에서 JSON 형식으로 저장되는 정보의
15.Semantic search using byte-quantized vectors
https://docs.opensearch.org/latest/tutorials/vector-search/vector-operations/semantic-search-byte-vectors/이 튜토리얼은 Cohere Embed 모델과 바이트 양자화 벡터를 사용
16.Generating embeddings from arrays of objects
이 튜토리얼은 객체 배열에 대한 임베딩을 생성하는 방법을 보여줍니다. 자세한 정보는 "임베딩 자동 생성"을 참조하세요.your\_로 시작하는 접두사가 있는 자리 표시자를 자신의 값으로 바꾸세요.이 튜토리얼에서는 Amazon Bedrock에서 호스팅되는 Amazon Ti
17.Getting started with OpenSearch security
https://docs.opensearch.org/latest/getting-started/security/데모 구성은 OpenSearch 보안을 시작하는 가장 간단한 방법입니다. OpenSearch에는 install_demo_configuration.sh(W
18.Ingest your data into OpenSearch
https://docs.opensearch.org/latest/getting-started/ingest-data/OpenSearch로 데이터를 수집하는 방법에는 여러 가지가 있습니다:개별 문서 수집: 자세한 정보는 "문서 인덱싱"을 참조하세요.여러 문서 일괄
19.Communicate with OpenSearch
https://docs.opensearch.org/latest/getting-started/communicate/REST API 또는 OpenSearch 언어 클라이언트 중 하나를 사용하여 OpenSearch와 통신할 수 있습니다. 이 페이지에서는 OpenSe
20.Installation quickstart
https://docs.opensearch.org/latest/getting-started/quickstart/OpenSearch는 여러 설치 방법을 지원합니다: Docker, Debian, Helm, RPM, tarball, Windows. 이 가이드는 빠른
21.Introduction to OpenSearch
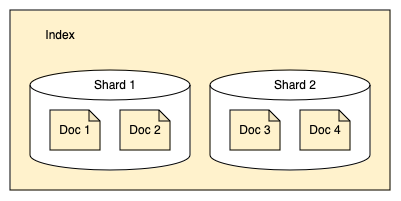
OpenSearch는 웹사이트의 검색창 구현부터 위협 탐지를 위한 보안 데이터 분석까지 다양한 사용 사례를 지원하는 분산 검색 및 분석 엔진입니다. 분산이라는 용어는 OpenSearch를 여러 컴퓨터에서 실행할 수 있다는 의미입니다. 검색 및 분석은 데이터를 OpenS
22.Version history
하이브리드 검색: 2.10.0 (2023년 9월)신경 검색: 2.9.0에서 GA (2023년 7월)벡터 검색 GPU 가속: 3.1.0에서 GA (2025년 6월)의미론적 검색: 3.1.0 (2025년 6월)에이전트와 도구: 2.13.0에서 GA (2024년 4월)Ope
23.Keyword search
기본적으로 OpenSearch는 Okapi BM25 알고리즘을 사용하여 문서 점수를 계산합니다. BM25는 쿼리에 나타나는 단어들에 대해 어휘적 검색을 수행하는 키워드 기반 알고리즘입니다.문서의 관련성을 결정할 때, BM25는 단어 빈도/역문서 빈도(TF/IDF)를 고