LoRA로 빠르게 나만의 모델을 만들어보자
출처 : https://www.youtube.com/watch?v=66GD0Bj5Whk
강의를 들으면서 인상적인 내용을 정리하고 나중에 다시 볼 때 조금 더 빠르게 찾고자 작성한 글 입니다.
LoRA 등장하게 된 배경
Large-Scale Pretrained Model
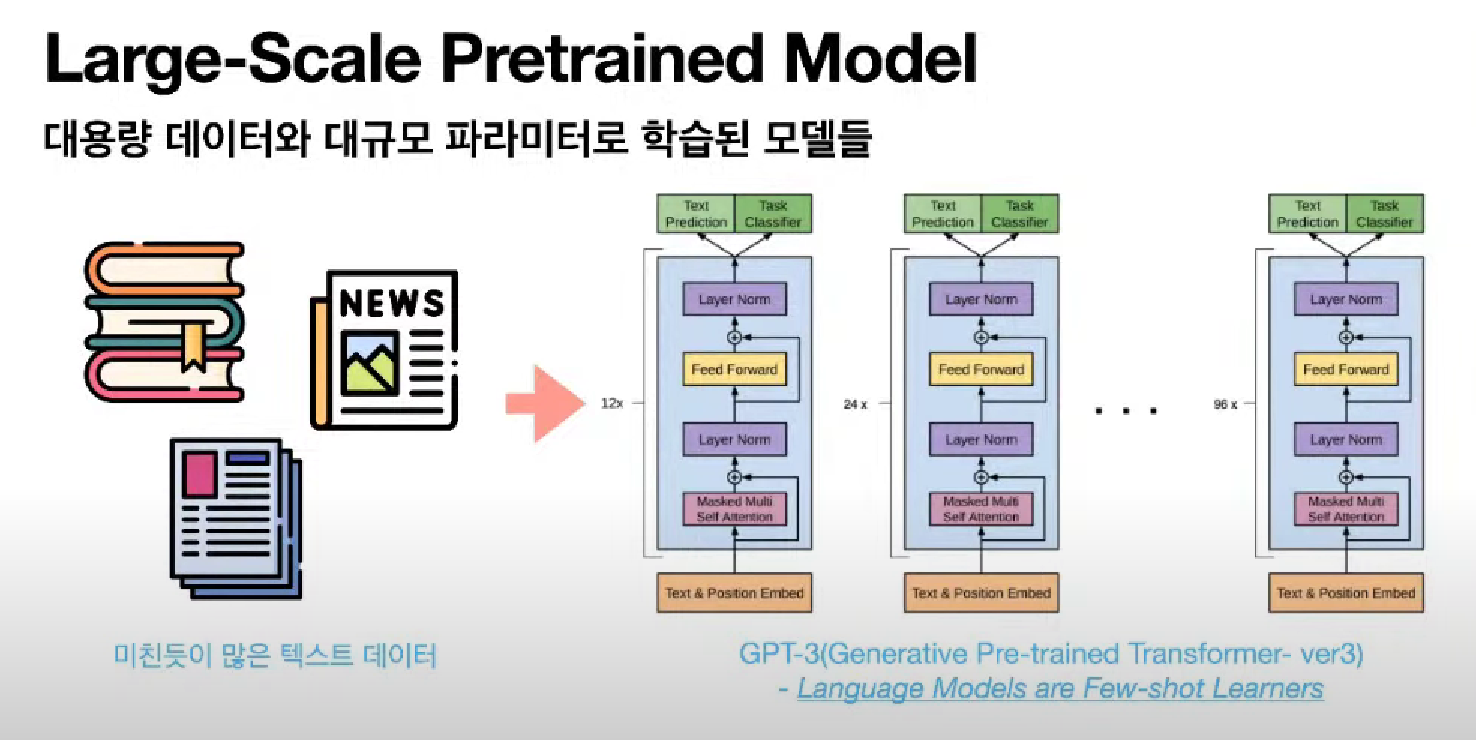
굉장히 거대한 모델을 가볍게 사용할 수 있도록 도와주는 것이라고 생각하면 된다.
GPT3 : 1,750억개의 파라미터로 구성됨.
7B(70억개 파라미터) 이상의 모델을 Large Scale이라고 한다.
Limitation

2018년 부터 AI Model이 점점 커지기 시작하면서 개인은 AI 모델을 사용하기가 점점 어려워졌다.
그러다가 과연 이렇게까지 스케일이 큰 AI 모델이 필요한가에 대한 의문이 생기기 시작함.
그러다가 2021년도에 마이크로소프트에서 LoRA를 개발하게 된다.
Over-parametrized model (파라미터가 굳이 너무 많다)라고 말 함.
(내가 하고싶은 것 대비 너무 많다 라는 의미)
instrinsic dimension에 필요한 정보가 있을것이라고 판단함.
(전체 정보 중에 일부의 정보만 있다면 내가 하고 싶은 서비스를 진행할 수 있을 것이라고 판단함.)
내부에 침투해 있는 즉, 전체 정보 중에 일부의 정보만 있으면 내가 하려는 다운스트림 테스트를 할 수 있을거다. 그래서 만약에 이걸 내가 찾으면 좀 더 효율적으로 학습을 시킬 수 있을 거야 이게 LoRA의 메인 아이디어이다.
RANK : 어떤 메트릭스가 있는데 메트릭스의 기준이 되는 차원을 얘기한다.
(컬럼 벡터가 이 때 RANK가 된다.)
Low Rank : 적은 양이지만 핵심 정보를 가지고 있는 데이터
Propose
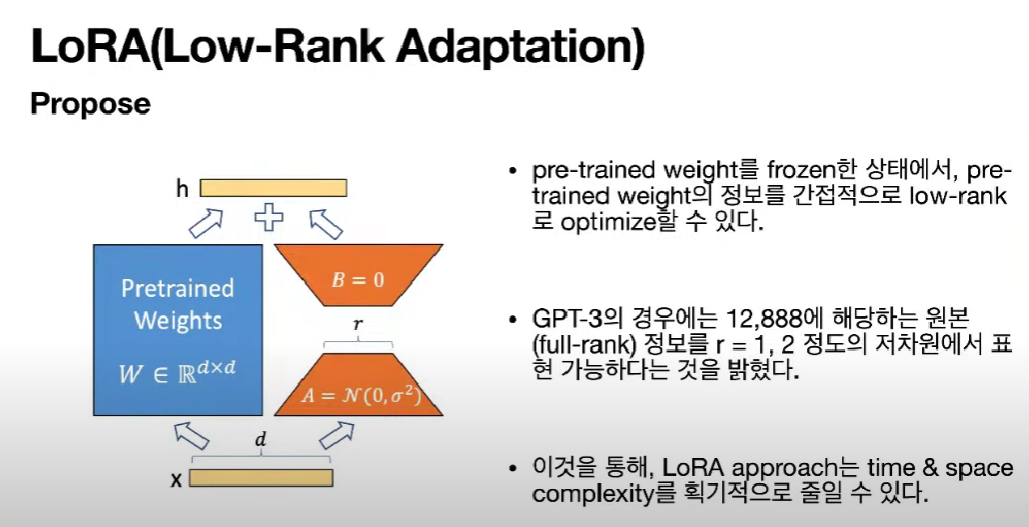
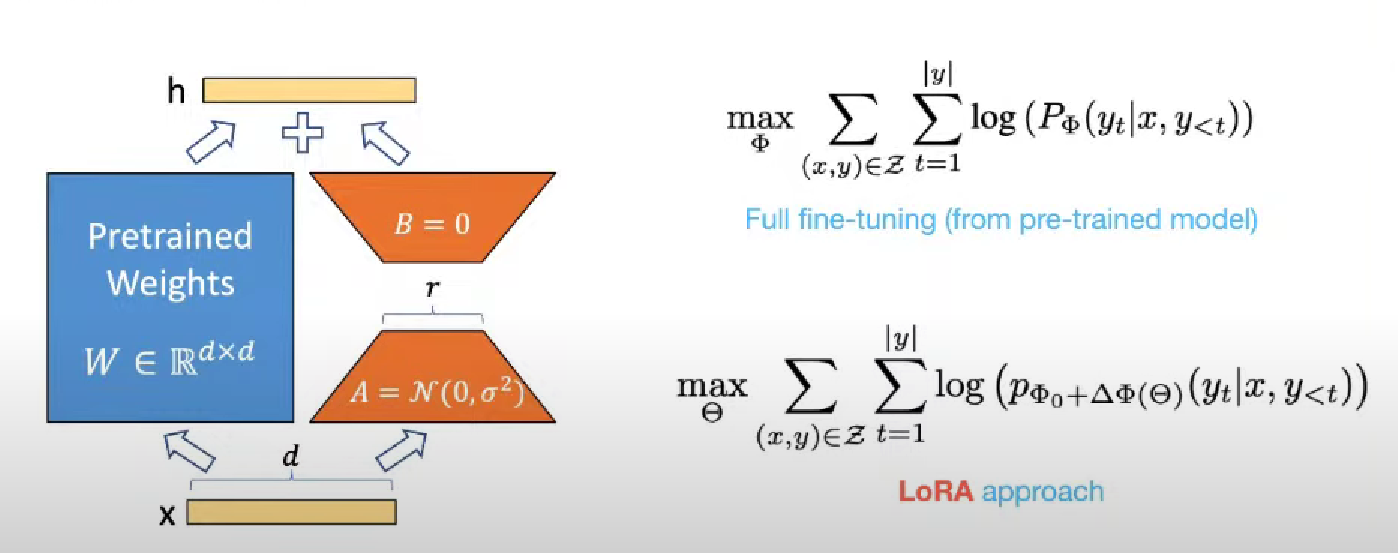
LoRA의 컨셉
이미 학습되어 있는 건 똑같이 가져다가 사용하겠다. 근데 여기서 중요한 정보만 뽑아서 학습이 가능하다.
위 그림에서 a와 b로 이뤄진 Dense Layer가 있다.
(다른 말로는 Fully Connected Layer)
a, b는 Auto Encoder처럼 a라는 weight matrix를 거치면 d가 r 크기로 줄어들게 된다.
(r : hidden layer의 node 개수)
그러고 나서 r이 다시 d 크기로 커지게 된다.
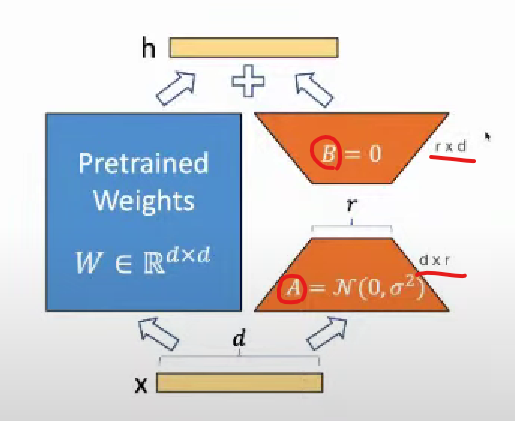
A : dr
B : rd
(행렬의 곱 : (ab)(bc) = ac)
A, B라는 2개의 matrix로 원본 데이터를 충분히 optimize가 가능하다.
r : low Rank의 r
12,888 차원에 해당하는 것을 로우 랭크로 내리면 1이나 2만 있어도 해당 정보를 충분히 optimizer 할 수 있더라
(원래라면 12,888개의 숫자가 필요하던게 1개에서 2개의 숫자로 줄일 수 있다.)
12,888 12,888의 행렬에서 12,888 2로 줄어들게 된다.
굉장히 많은 수를 줄일 수 있게 된다.
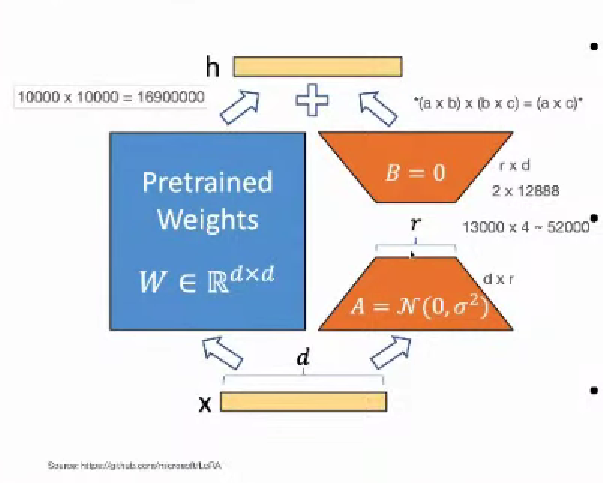
~16,900,000개의 파라미터에서 ~52,000개의 파라미터로 굉장히 많이 줄일 수 있다.
auto regressive way한 language model : GPT
Full fine-tunning 에서 x, y는 전체 데이터
max : 전체 확률 값
학습한 문장들로 다음 단어를 맞추는, 다음 단어가 등장할 확률을 최대로 해서 단어를 잘 맞추는 문제를 기존 pre-trained 모델로 정의를 한다.
LoRA approach
fine tunning을 하면은 내가 기존에 있는 weight에다가 세타만큼의 정보를 추가 한다라는 컨셉으로 이제 파인 튜닝을 재정의 한다.
로라라는 모델이 정의 : 기존 Pretrained fine tunning 할 때는 기존 웨이트가 가지고 있는 정보에다가 내가 fine-tunning 할 때 정보를 더해준다고 가정한다. 여기서 말하는 더해준다는 거는 진짜 플러스 마이너스이 개념이 아니고이 델타 즉, 뭔가 정보가 추가된다라는 개념에서 추가된다는 말이 쓰인것이다.
fine 튜닝을 하는 정보 : 세타에서 결정이 되니까 세타가 파인 튜닝할 때 우리가 업데이트하는 파라미터를 세타라고 정의 한다.
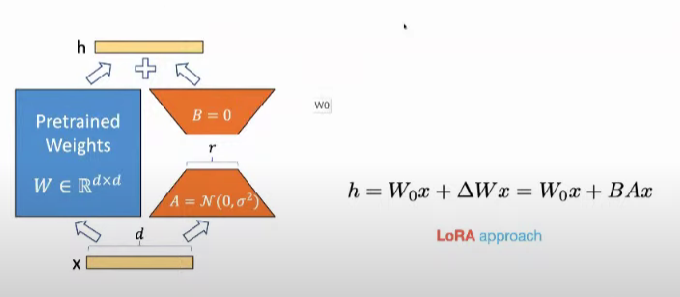
기존에 있던 pretrained weight를 w0라고 표시를 합니다
feed-forward 하면 여기에는 x와 w0는 곱해진다. > 그게 원래 h이다.
42분 정도?
