llama2를 사용한 fine-tune의 간편화에 목적을 두었습니다. 2가지 방법 (gradientai, T4 GPU)으로 나눠서 설명했습니다.
출처 : https://www.youtube.com/watch?v=4I9AUFuBlFs&t=2s
Gradient AI를 사용하여 LLM 모델 사전 훈련하기
출처 : https://www.toolify.ai/ko/ai-news-kr/gradient-ai-llm-1304494
Gradient AI는 데이터 과학과 인공지능 분야에서 널리 사용되는 기술 중 하나입니다. 이 플랫폼을 사용하여 우리는 사용자 정의 데이터셋으로 자신만의 LLM(언어 모델)을 사전 훈련할 수 있습니다. 이번 글에서는 Gradient AI의 사용법에 대해 상세히 알아보겠습니다.
1. 개요
Gradient AI는 다양한 LLM 모델을 제공하는 플랫폼으로, 커스텀 데이터셋을 활용해 모델을 사전 훈련할 수 있습니다. 이러한 커스텀 데이터셋은 특정한 형식으로 구성되어야 하며, 그 후 모델의 사전 훈련은 빠르고 간편하게 진행될 수 있습니다.
2. Gradient AI란?
Gradient AI는 하나의 플랫폼에서 다양한 인공지능 모델을 개발, 배포하고 이를 활용하여 문제를 해결할 수 있는 기능을 제공합니다. Gradient AI는 LLM 모델의 사전 훈련, 배포 및 추론을 도와주며, 웹 페이지에서 간단한 코드를 사용하여 자신만의 모델을 구축할 수 있는 기능을 제공합니다. 또한, JavaScript, Python 및 Java와 같은 다양한 SDK를 지원하며, Workspace 생성, 인프라 관리 등을 자동으로 처리해주는 편리한 기능을 제공합니다.
3. Gradient AI의 장점
Gradient AI는 데이터 과학 및 인공지능 분야에서 다양한 장점을 가지고 있습니다. 그 중 몇 가지를 살펴보겠습니다.
-
다양한 LLM 모델 제공: Gradient AI는 미리 훈련된 다양한 LLM 모델을 제공하여 사용자가 원하는 모델을 선택할 수 있습니다.
커스텀 데이터셋 활용 가능: Gradient AI는 사용자 정의 데이터셋을 활용하여 모델을 사전 훈련할 수 있습니다. 데이터셋은 특정한 형식으로 구성되어야 하며, 그 후 모델의 훈련은 빠른 시간에 완료될 수 있습니다. -
언어 지원: Gradient AI는 JavaScript, Python 및 Java와 같은 다양한 언어를 지원하므로 사용자는 선호하는 언어로 모델을 개발할 수 있습니다.
편리한 관리 기능: Gradient AI는 Workspace 생성, 인프라 관리 등의 작업을 자동화하여 사용자가 편리하게 모델을 관리할 수 있도록 도와줍니다.
4. Gradient AI의 한계
Gradient AI는 많은 장점을 가지고 있지만, 몇 가지 한계도 존재합니다. 몇 가지 주요한 한계를 살펴보겠습니다.
-
한정된 언어 지원: Gradient AI는 JavaScript, Python 및 Java와 같은 몇 가지 언어를 지원하지만, 모든 언어에 대한 완벽한 지원은 아직 이루어지지 않았습니다.
-
제한된 자원: Gradient AI는 자체 인프라를 제공하지만, 일부 복잡한 작업을 수행하기에는 제한된 자원을 가지고 있을 수 있습니다.
(OpenAI API와 마찬가지로 여기에도 Billing System이 존재합니다. 더 향상된 퍼포먼스를 내고 싶다면 추가 구매가 필요할 거 같습니다.) -
익숙하지 않은 사용자에게 복잡할 수 있음: Gradient AI는 복잡한 작업을 수행하는 기능을 제공할 수 있으므로, 처음 사용하는 사용자에게는 적응이 어려울 수 있습니다.
(확실히 익숙하지 않으면 처음에는 조금 복잡한 느낌입니다.)
아래 내용부터 강의 내용 시작
Gradientai
- AI 클라우드를 제공하는 회사
- 사용자만 접근할 수 있는 개인 모델 구축
- 다양한 언어 지원 (python, java)
- 기본 모델 지원
- Bloom-560, Llama-2 (7B,13B), Nous-Hermes-Llama-2
- 이 중에서 오늘은 Llama-2 (7B)를 사용해볼 예정
- Fine-Tuning 기능 지원
T4 GPU 방법
- T4 GPU에서 llama2 기반 모델 load를 위한 parameter 조정
- Llama2 7B의 경우 Colab상에서 Full Load를 해버리면 Colab GPU 상에서는 Fine Tunning을 못 할 정도의 VRAM 크기를 가지고 있어서 어느정도 T4의 크기에 알맞게 파라미터를 조정해야 제대로 된 결과를 얻을 수 있다.
- 4bit load 적용
- SFTTrainer를 사용한 학습
- SFT는 특정 task에 모델을 조정하는 방법
- 이번에 SFT를 사용하는 이유는 개인 데이터셋으로 만든 데이터에 최적화하기 위함 (다른 trainer를 사용해도 문제없습니다.)
- 특정 Task에 정확한 답변을 하는 게 중요하다. / SFT는 특정 task에 모델을 맞춰서 조정해준다.
- 개인 데이터셋으로 만든 데이터로 SFT학습 후 주어진 task에 해당하는 질문에 유사한 답변을 하는 것이 목표여서 해당 Trainer를 사용했습니다.
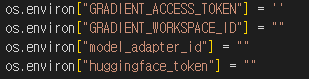
코드에서 필요로 하는 TOKEN과 API KEY를 각각 다 기입해줘야 사용할 수 있습니다.
코랩을 열어서 돌려보면 코드가 변경 됐는지 제대로 동작을 안 해서 수정을 했습니다.
!pip install llama-index==0.9.27
!pip install gdown
!pip install llama-hub
!pip install PyMuPDF
!pip install nest-asyncio
!pip install jsonlines
!pip install gradio==3.48.0
!pip install trl
!pip install pypdf
!pip install langchain
!pip install chromadb
!pip install pydantic==1.10.13
!pip install gradientai
!pip install sentence-transformers
!git clone https://github.com/choijhyeok/easy_finetuner.git
%cd easy_finetuner
!pip install -r requirements.txt
%cd ..from llama_index.llms import GradientModelAdapterLLM
import os
import gdown
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import RetrievalQAWithSourcesChain
from llama_hub.file.pymu_pdf.base import PyMuPDFReader
from langchain.document_loaders import PyPDFLoader
from langchain.schema import Document
from pathlib import Path
from llama_index.llms import GradientBaseModelLLM
from llama_index.finetuning.gradient.base import GradientFinetuneEngine
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
import re
from langchain.llms import GradientLLM
import warnings
from langchain.embeddings import HuggingFaceEmbeddings
import jsonlines
from datasets import Dataset
warnings.filterwarnings('ignore')
os.environ["GRADIENT_ACCESS_TOKEN"] = ''
os.environ["GRADIENT_WORKSPACE_ID"] = ""
os.environ["model_adapter_id"] = ""
os.environ["huggingface_token"] = ""위 코드가 원본 코드입니다. 제가 수정한 내용과 비교해보면서 확인해보시면 됩니다.
아래 부터가 수정된 내용입니다.
!pip install llama-index
# 아래 두 줄은 동작 안 돼서 새롭게 작성
%pip install llama-index-embeddings-langchain
%pip install llama-index-llms-gradient%pip install llama-index --quiet
%pip install gradientai --quiet# !pip install llama-index==0.9.27
# 0.9.27로 version을 설정해줘서 에러가 발생하는것일수도 있으므로 version 기입을 없애고 진행
!pip install gdown
!pip install llama-hub
!pip install PyMuPDF
!pip install nest-asyncio
!pip install jsonlines
# !pip install gradio==3.48.0
!pip install gradio
!pip install trl
!pip install pypdf
!pip install langchain
!pip install chromadb
# !pip install pydantic==1.10.13
!pip install pydantic
!pip install gradientai
!pip install sentence-transformers
!git clone https://github.com/choijhyeok/easy_finetuner.git
%cd easy_finetuner
!pip install -r requirements.txt
%cd ..GPU 없이 llama2 fine-tune
llama2 파인튜닝
필요한 모듈 불러오기
!pip install -U langchain-community# 아래 이게 원래 코드
# from llama_index.llms import GradientModelAdapterLLM # llama_index에서 LLM 모델과 파인튜닝 관련 클래스
# from llama_index.llms import GradientBaseModelLLM # 대안 코드 사용했으나 제대로 된 동작 X
# 새로운 시도
from llama_index.llms.gradient import GradientModelAdapterLLM
# 출처 : https://docs.llamaindex.ai/en/stable/examples/llm/gradient_model_adapter/
# 코드가 변경되서 작동이 안 됐던게 맞는
import os # 운영 체제와 상호작용하는 표준 라이브러리
import gdown # Google Drive에서 파일을 다운로드하는데 사용됩니다.
from langchain.prompts.chat import ( # 아래 3개의 import문 : 채팅 기반 프롬프트를 만드는 클래스
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import RetrievalQAWithSourcesChain
from llama_hub.file.pymu_pdf.base import PyMuPDFReader
from langchain.document_loaders import PyPDFLoader # PDF 문서를 읽고 로드하는 클래스
from langchain.schema import Document # 문서를 나타내는 스키마 클래스입니다.
from pathlib import Path
from llama_index.llms.gradient import GradientBaseModelLLM # llama_index에서 LLM 모델과 파인튜닝 관련 클래스
# from llama_index.finetuning.gradient.base import GradientFinetuneEngine # llama_index에서 LLM 모델과 파인튜닝 관련 클래스
from llama_index.finetuning.gradient.base import GradientFinetuneEngine
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma # 효율적인 유사성 검색을 위한 벡터 스토어
import re # 정규 표현식 모듈
from langchain.llms import GradientLLM # llama_index에서 LLM 모델과 파인튜닝 관련 클래스
import warnings
from langchain.embeddings import HuggingFaceEmbeddings # Hugging Face 모델을 사용하여 임베딩을 생성하는 클래스
import jsonlines # JSON 라인 파일을 읽고 쓰는 모듈
from datasets import Dataset # datasets 라이브러리에서 데이터셋을 만드는 클래스
warnings.filterwarnings('ignore')
# 개인 발급 받은 KEY값 작성
os.environ["GRADIENT_ACCESS_TOKEN"] = ''
os.environ["GRADIENT_WORKSPACE_ID"] = ""
os.environ["model_adapter_id"] = ""
os.environ["huggingface_token"] = ""
경로 : /usr/local/lib/python3.10/dist-packages/llama_hub/file/pymu_pdf/base.py
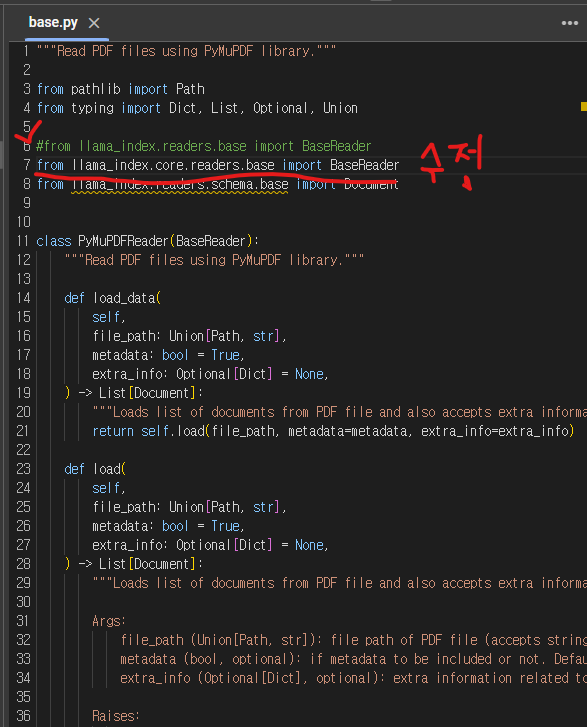
from llama_index.readers.base import BaseReader위 코드를 고치도록 한다.
from llama_index.core.readers.base import BaseReaderLlama API를 살펴보면 이런 식으로 코드를 수정해야 된다고 한다.
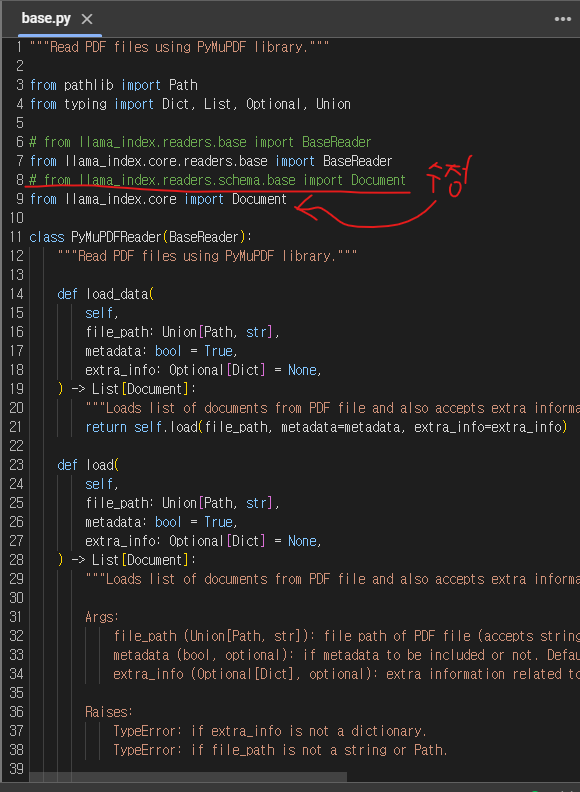
다음으로 from llama_index.readers.schema.base import Document를 수정한다.
from llama_index.core import Document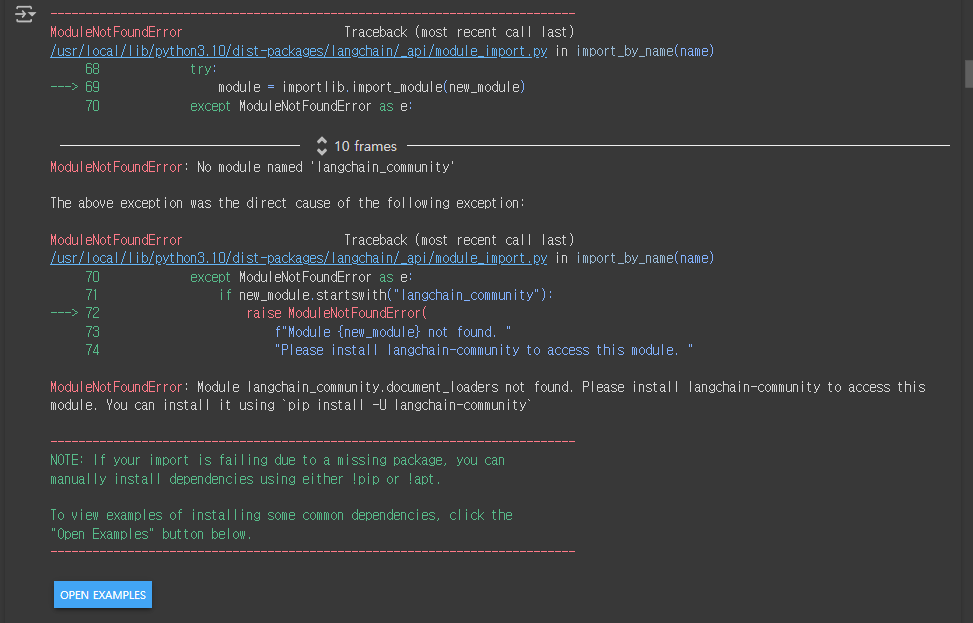
base.py까지 수정하고 나서 다시 실행해도 또 다시 에러가 발생하는데 이 때는
pip install -U langchain-community 를 입력해주면 실행 된다.
https://docs.llamaindex.ai/en/stable/module_guides/loading/documents_and_nodes/usage_documents/
여기 문서 참고 함

수정한 코드
from llama_index.llms.gradient import GradientBaseModelLLM
# llama_index에서 LLM 모델과 파인튜닝 관련 클래스from llama_index.llms import GradientBaseModelLLM
여기서 .gradient를 뒤에 붙여서 수정한다.
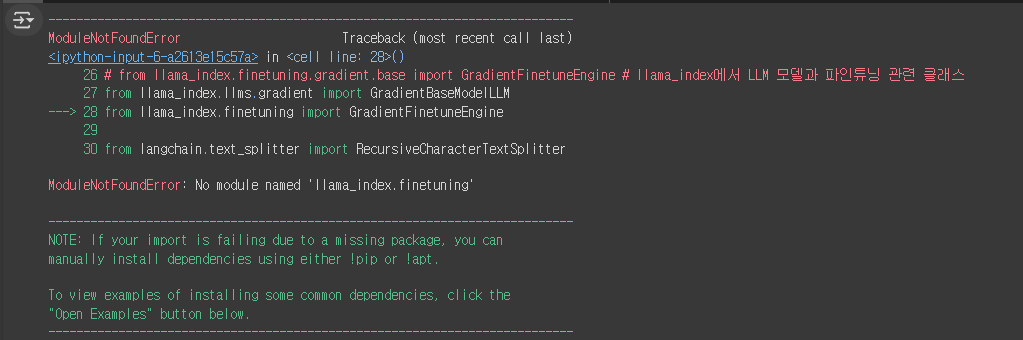
그다음으로 이런 에러가 발생하는데 그렇다면
https://colab.research.google.com/github/run-llama/llama_index/blob/main/docs/docs/examples/finetuning/gradient/gradient_structured.ipynb#scrollTo=Tp2RCateG_jJ
여기를 참고해보면
%pip install llama-index-finetuning 이 코드를 동작해서 install을 해줘야 된다.
from llama_index.llms.gradient import GradientBaseModelLLM
from llama_index.finetuning import GradientFinetuneEngine그리고 코드도 원래 코드 말고 이렇게 2개의 코드로 나눠서 작성해줘야 된다.
사용할 데이터 준비
gdown.download(url="https://drive.google.com/file/d/16hHL4hLer3nWhX18STvr061LcHzfFgN2/view?usp=sharing", output="qa_버거킹_train.jsonl", quiet=False)
gdown.download(url="https://drive.google.com/file/d/1nB6ERfII2ODEDS_1xY3C5TBZHeOMMcPI/view?usp=sharing", output="qa_버거킹_train_ko.jsonl", quiet=False)
gdown.download(url="https://drive.google.com/file/d/11U7let6PY_YCJpgRT0Dpr5DXSO3Ceqep/view?usp=sharing", output="버거킹.pdf", quiet=False)
gdown.download(url="https://drive.google.com/file/d/1BifMUDNX2v_4B7hb4YHv6eDinQqAjTZK/view?usp=sharing", output="Burger-King.pdf", quiet=False)
파인튜닝할 모델 및 데이터 선택
## base_model 선택
base_model_slug = "llama2-7b-chat"
base_llm = GradientBaseModelLLM(
base_model_slug=base_model_slug, max_tokens=500, is_chat_model=True
)
finetune_engine = GradientFinetuneEngine(
base_model_slug=base_model_slug,
name="bugurking",
data_path="qa_버거킹_train.jsonl",
verbose=True,
max_steps=200,
batch_size=1,
)- llama2-7b-chat : hugging face 기반으로 chatting 버전으로 나온 모델
- qa_버거킹_train.jsonl : 버거킹에서 QnA를 기반으로 만들어진 jsonl file
파인튜닝 finetune
# 파인튜닝 2 epoch만
for i in range(2):
print(f"** EPOCH {i} **")
finetune_engine.finetune()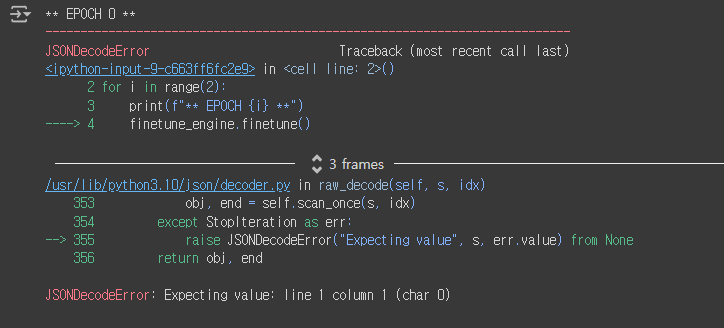
여기서 다음과 같은 에러가 발생하게 된다.
이걸 해결 해보려고 일부러 다른 도전을 하게 됨.
jsonl 도전
import jsonlines
file_path_qa_Burger_train = '/content/drive/MyDrive/공모전/kmong/data/qa_버거킹_train.jsonl'
# JSONL 파일 읽기
data_qa_Burger_train = []
with jsonlines.open(file_path_qa_Burger_train) as reader:
for obj in reader:
data_qa_Burger_train.append(obj)
# 읽은 데이터 확인
print(data_qa_Burger_train[:3]) # 처음 3개의 항목만 출력from datasets import Dataset
import pandas as pd
# 데이터를 Dataset으로 변환
dataset_qa_Burger_train = Dataset.from_pandas(pd.DataFrame(data_qa_Burger_train))
# 데이터셋 확인
print(dataset_qa_Burger_train)file_path_qa_Burger_train_ko = '/content/drive/MyDrive/공모전/kmong/data/qa_버거킹_train_ko.jsonl'
data_qa_Burger_train_ko = []
with jsonlines.open(file_path_qa_Burger_train_ko) as reader:
for obj_ko in reader:
data_qa_Burger_train_ko.append(obj_ko)
print(data_qa_Burger_train_ko[:3])dataset_qa_Burger_train_ko = Dataset.from_pandas(pd.DataFrame(data_qa_Burger_train_ko))
print(dataset_qa_Burger_train_ko)위 내용과 같이 수정했으나 다시 코드를 확인해보니까 굳이 이렇게 힘들게 접근하지 않고
## base_model 선택
base_model_slug = "llama2-7b-chat"
base_llm = GradientBaseModelLLM(
base_model_slug=base_model_slug, max_tokens=500, is_chat_model=True
)
finetune_engine = GradientFinetuneEngine(
base_model_slug=base_model_slug,
name="bugurking",
data_path="/content/drive/MyDrive/공모전/kmong/data/qa_버거킹_train.jsonl",
# gdown을 해도 제대로 동작을 안 해서 잘 안 되는거 같음. 그냥 제대로 경로를 넣어주는게 마음 편할듯?
verbose=True,
max_steps=200,
batch_size=1,
)data_path 부분을 그냥 .jsonl file을 구글 드라이브에 넣고 그 경로를 설정해준 다음 다시 실행시키면 제대로 동작한다.
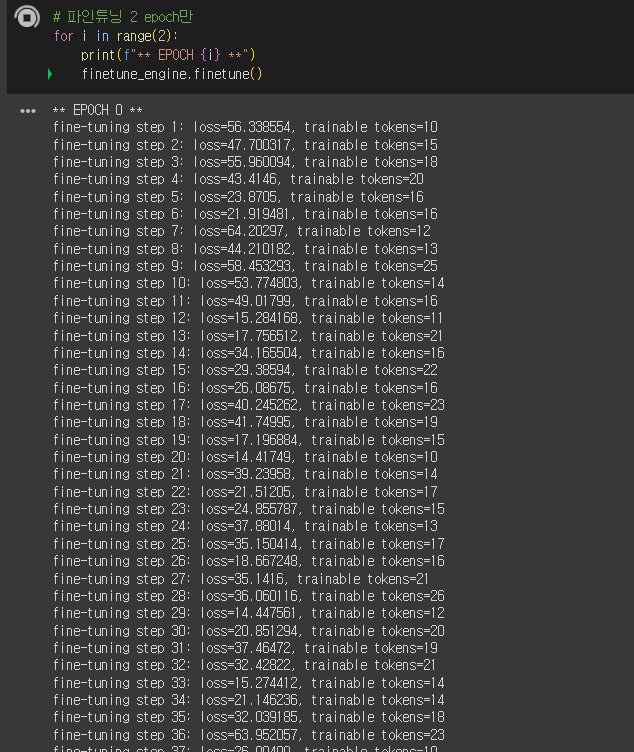
(loss가 말도 안 되게 줄줄 세는 모습...!)
# 파인튜닝 2 epoch만
for i in range(2):
print(f"** EPOCH {i} **")
finetune_engine.finetune()다시 돌아와서 이 녀석을 실행한다.
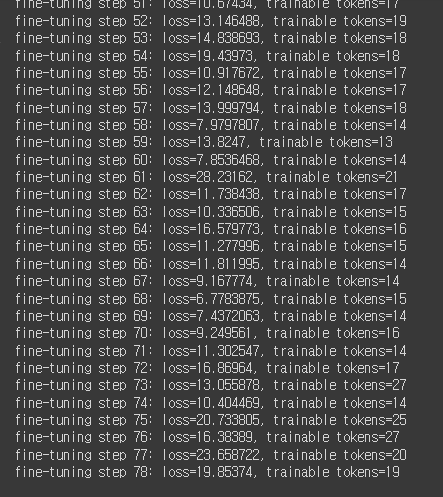
그러던 도중 갑자기 코랩이 터져버렸다...!
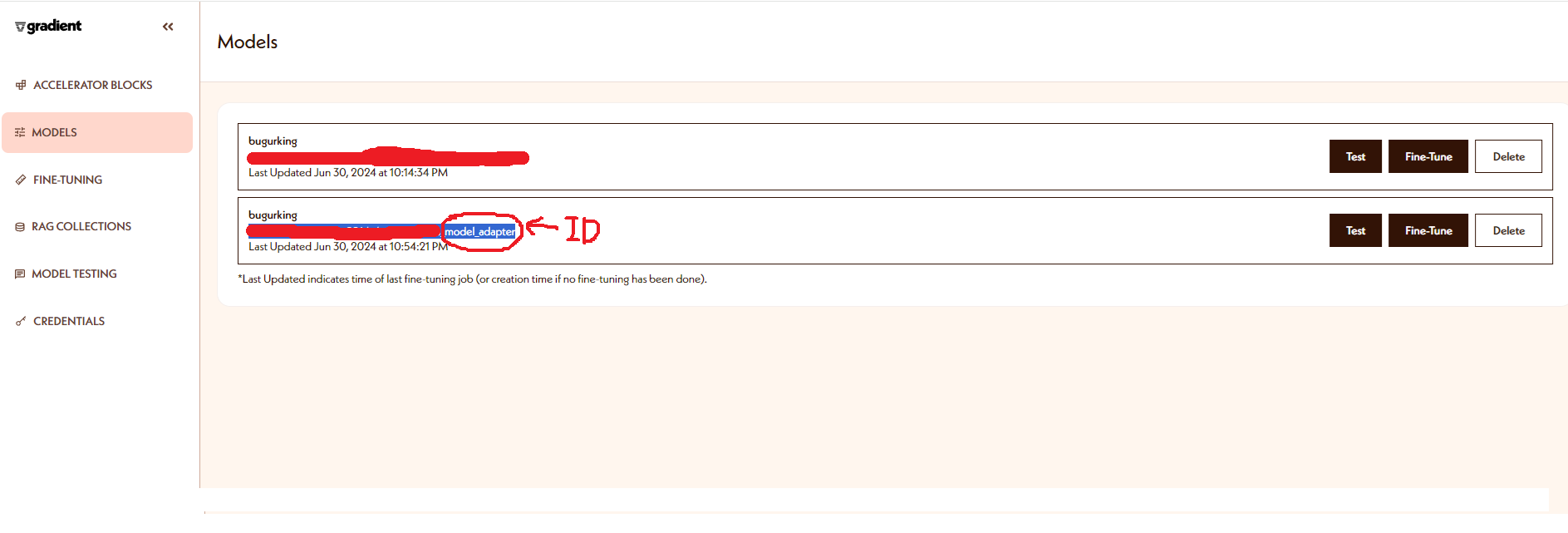
하지만 다행인건 Gradient AI를 통해서 실행이 되기 때문에 Gradient AI에 들어가보면 모델이 생성된 것을 확인할 수 있다.
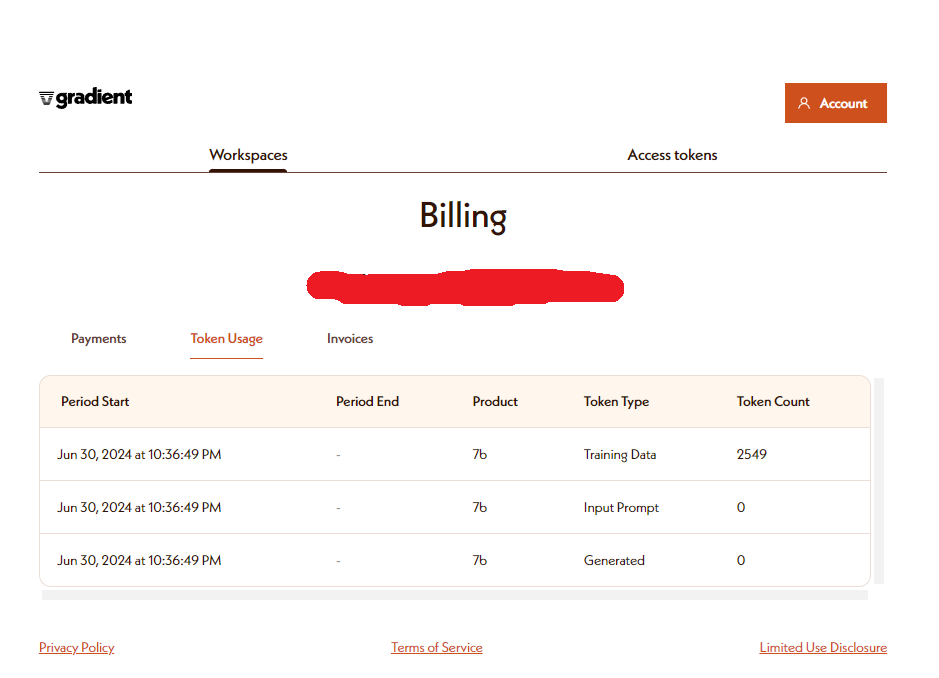
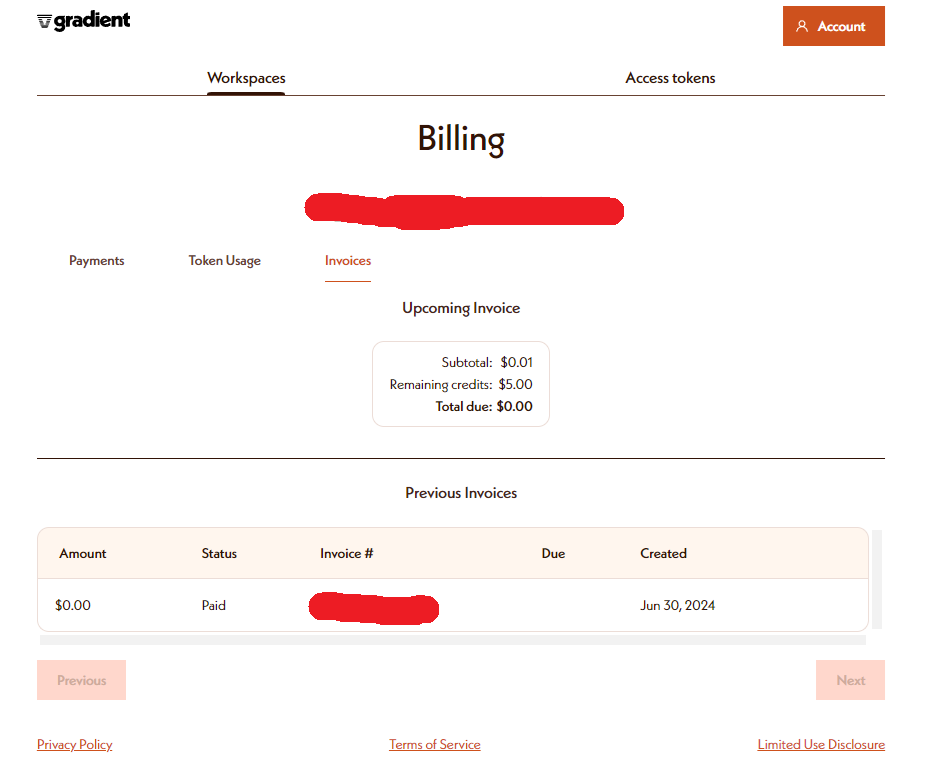
가입하면 기본적으로 5$가 이미 들어간 상태인데 이 정도 학습으로는 크게 지불할 금액이 늘지 않았다.(사실상 변동이 없다고 봐도 무방할지도?)
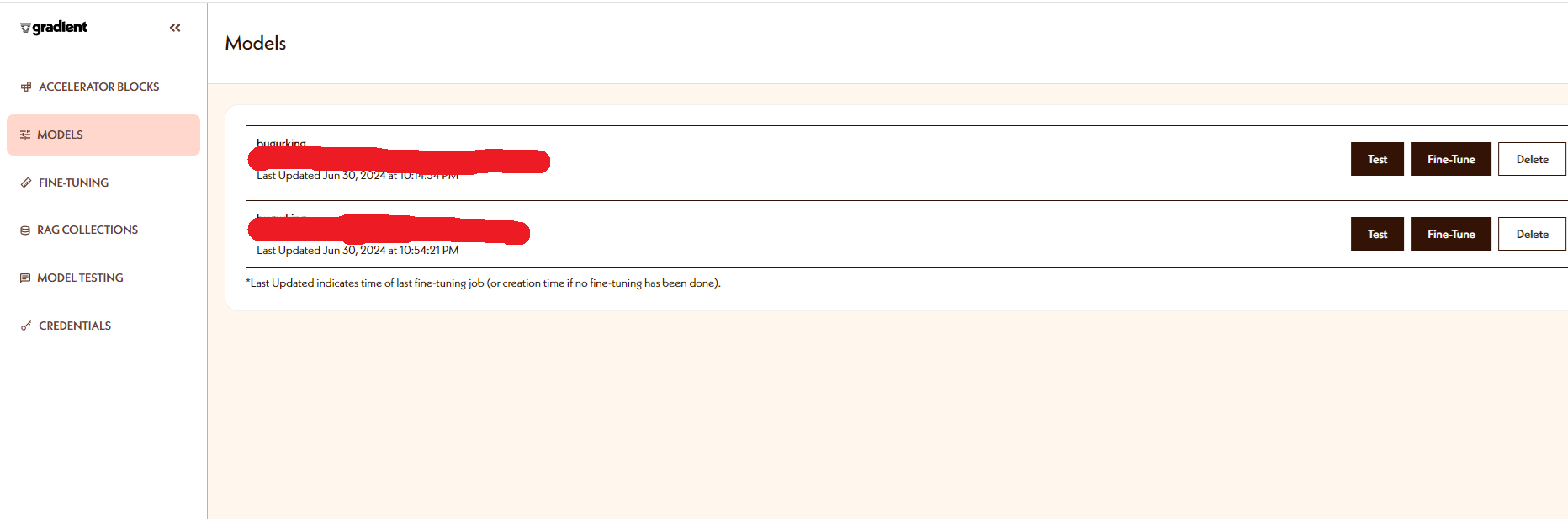
따로 이렇게 모델이 생성되어 있는것을 확인할 수 있다!
# 파인튜닝한 모델 사용
llm = finetune_engine.get_finetuned_model(
max_tokens=500, is_chat_model=False
)
기존에 이미 파인튜닝한 모델이 있다면 해당 모델 사용
llm = GradientModelAdapterLLM(
model_adapter_id=os.environ["model_adapter_id"],
max_tokens=500,
)
# 3가지 버거킹 메뉴를 추천해 달라는 내용으로 모델 테스트
llm.complete('Recommend only 3 items from Burger King’s menu.').text수정됨
위 코드는 동작하지 않으므로 아래의 코드를 통해 제대로 동작하는 모습을 확인할 수 있다.
llm = GradientModelAdapterLLM( model_adapter_id=finetune_engine.model_adapter_id, max_tokens=500 )
Langchain Rag 연결
PDF 로드
loader = PyPDFLoader("Burger-King.pdf")
# 여기도 ()안에 그냥 드라이브에 pdf 파일을 넣고 난 뒤 경로를 설정해주는게 더 쉽게 접근 가능하다.
documents = loader.load()
documents[0]
PDF text 전처리
output = []
# text 정제
for page in documents:
text = page.page_content
text = re.sub(r"(\w+)-\n(\w+)", r"\1\2", text) # 안녕-\n하세요 -> 안녕하세요
text = re.sub(r"(?<!\n\s)\n(?!\s\n)", " ", text.strip()) # "인\n공\n\n지능펙\n토리 -> 인공지능펙토리
text = re.sub(r"\n\s*\n", "\n\n", text) # \n버\n\n거\n\n킹\n -> 버\n거\n킹
text = re.sub(r'®', '',text)
output.append(text)doc_chunks = []
for idx, line in enumerate(output):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=2000, # 최대 청크 길이
separators=["\n\n", "\n", ".", "!", "?", ",", " ", ""], # 텍스트를 청크로 분할하는 데 사용되는 문자 목록
chunk_overlap=0, # 인접한 청크 간에 중복되는 문자 수
)
chunks = text_splitter.split_text(line)
for chunk in chunks:
doc = Document(
page_content=chunk, metadata={ "source": 'Burger-King.pdf', "page": idx}
)
doc_chunks.append(doc)아마 여기까지는 이제 문제없이 동작할 것이다.
huggingface의 embed_model 사용
embed_model = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-mpnet-base-v2"
)
index = Chroma.from_documents(doc_chunks, embed_model)
retriever = index.as_retriever(search_kwargs={"k": 2})
GradientLLM load & langchain
llm = GradientLLM(
model=os.environ["model_adapter_id"],
model_kwargs=dict(max_generated_token_count=500),
)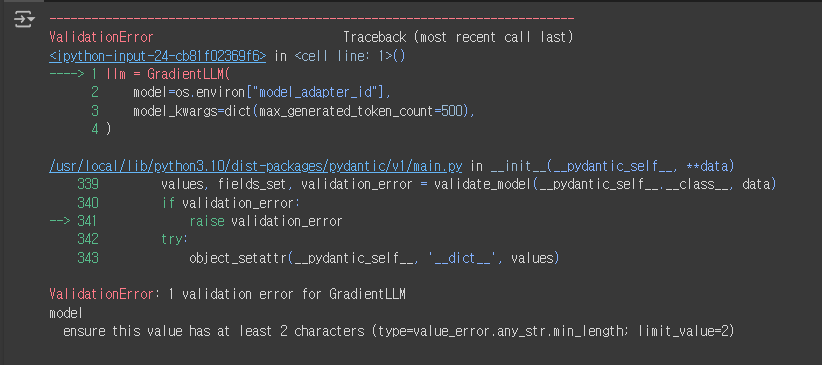
위 상태로 실행하면 아마 제대로 된 동작을 하지 않을 것이다.
그러므로 아까 했던 내용을 다시 사용한다.
(출처 : https://docs.llamaindex.ai/en/v0.9.48/examples/finetuning/gradient/gradient_structured.html)
수정된 코드
llm = GradientLLM( model=finetune_engine.model_adapter_id, model_kwargs=dict(max_generated_token_count=500), )
def llama2_output(out_text):
sep = out_text.split('Bot:')[-1].strip() if 'Bot:' in out_text else out_text
sep = sep.split('\n\nHuman')[0].strip() if '\n\nHuman' in sep else sep
return sep
system_template="""To answer the question at the end, use the following context. If you don't know the answer, just say you don't know and don't try to make up an answer.
I want you to act as my Burger King menu recommender. It tells you your budget and suggests what to buy. You should only reply to items you recommend. Don't write a description.
Below is an example.
“My budget is 10,000 won, and it is the best menu combination within the budget."
please answer in korean.
{summaries}
"""
messages = [
SystemMessagePromptTemplate.from_template(system_template),
HumanMessagePromptTemplate.from_template("{question}")
]
prompt = ChatPromptTemplate.from_messages(messages)
chain_type_kwargs = {"prompt": prompt}
bk_chain = RetrievalQAWithSourcesChain.from_chain_type(
llm,
chain_type="stuff",
retriever=retriever,
chain_type_kwargs=chain_type_kwargs,
return_source_documents=True)
#reduce_k_below_max_tokens=True
# )result = bk_chain({"question": 'Recommend only 3 items from Burger King’s menu.'})
print(f"질문 : {result['question']}")
print()
print(f"답변 : {llama2_output(result['answer'])}")
실행하면 제대로 된 답변을 하는 모습을 확인 가능
result = bk_chain({"question": 'Please provide the menu combination, price, and menu description without paying a total of 30,000 won.'})
print(f"질문 : {result['question']}")
print()
print(f"답변 : {llama2_output(result['answer'])}")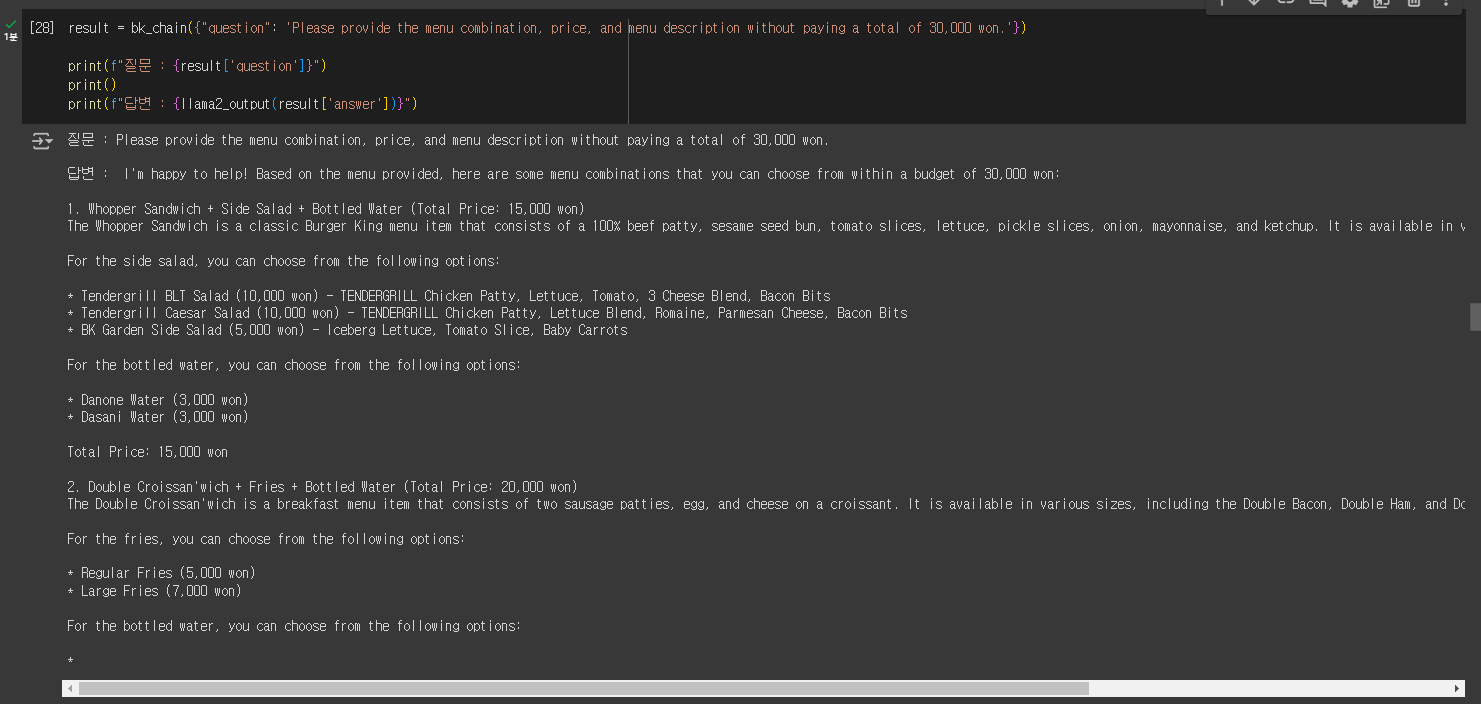
이번에도 제대로 답변을 하는 모습을 확인할 수 있다.
(아까보다는 답변 속도가 확연히 느려진 것을 알 수 있다.)
result = bk_chain({"question": "What is included in the Crispy King & Mozzarella Ball set with Diablo Sauce?"})
print(f"질문 : {result['question']}")
print()
print(f"답변 : {llama2_output(result['answer'])}")
Gradio를 통한 bugerking chat
import os
import logging
import sys
import gradio as gr
import torch
import gc
def reset_state():
return [], [], "Reset Done"
def reset_textbox():
return gr.update(value=""),""
def transfer_input(inputs):
textbox = reset_textbox()
return (
inputs,
gr.update(value=""),
gr.Button.update(visible=True),
)
title = """<h1 align="left" style="min-width:350px; margin-top:0;"> <img src="https://lh3.google.com/u/0/d/1txdmhh6pWjdJBpqGBRMdC0qQX2f7pzxI=w2020-h952-iv1" width="32px" style="display: inline"> AIF 버거킹 chat </h1>"""
description_top = """\
<div align="left">
<p></p>
<p>
</p >
</div>
"""
CONCURRENT_COUNT = 100
ALREADY_CONVERTED_MARK = "<!-- ALREADY CONVERTED BY PARSER. -->"
small_and_beautiful_theme = gr.themes.Soft(
primary_hue=gr.themes.Color(
c50="#02C160",
c100="rgba(2, 193, 96, 0.2)",
c200="#02C160",
c300="rgba(2, 193, 96, 0.32)",
c400="rgba(2, 193, 96, 0.32)",
c500="rgba(2, 193, 96, 1.0)",
c600="rgba(2, 193, 96, 1.0)",
c700="rgba(2, 193, 96, 0.32)",
c800="rgba(2, 193, 96, 0.32)",
c900="#02C160",
c950="#02C160",
),
secondary_hue=gr.themes.Color(
c50="#576b95",
c100="#576b95",
c200="#576b95",
c300="#576b95",
c400="#576b95",
c500="#576b95",
c600="#576b95",
c700="#576b95",
c800="#576b95",
c900="#576b95",
c950="#576b95",
),
neutral_hue=gr.themes.Color(
name="gray",
c50="#f9fafb",
c100="#f3f4f6",
c200="#e5e7eb",
c300="#d1d5db",
c400="#B2B2B2",
c500="#808080",
c600="#636363",
c700="#515151",
c800="#393939",
c900="#272727",
c950="#171717",
),
radius_size=gr.themes.sizes.radius_sm,
).set(
button_primary_background_fill="#06AE56",
button_primary_background_fill_dark="#06AE56",
button_primary_background_fill_hover="#07C863",
button_primary_border_color="#06AE56",
button_primary_border_color_dark="#06AE56",
button_primary_text_color="#FFFFFF",
button_primary_text_color_dark="#FFFFFF",
button_secondary_background_fill="#F2F2F2",
button_secondary_background_fill_dark="#2B2B2B",
button_secondary_text_color="#393939",
button_secondary_text_color_dark="#FFFFFF",
# background_fill_primary="#F7F7F7",
# background_fill_primary_dark="#1F1F1F",
block_title_text_color="*primary_500",
block_title_background_fill="*primary_100",
input_background_fill="#F6F6F6",
)
with open("/content/easy_finetuner/custom.css", "r", encoding="utf-8") as f:
customCSS = f.read()
logging.basicConfig(
level=logging.DEBUG,
format="%(asctime)s [%(levelname)s] [%(filename)s:%(lineno)d] %(message)s",
)
total_count = 0
def predict(input_text,
history):
global bk_chain
result = bk_chain({"question": input_text})
answer = llama2_output(result['answer'])
# answer = llm.complete(input_text).text
# print(input_text)
# print(answer)
history = history + [((input_text, None))]
history = history + [((None, answer))]
return history, history, "Generate: Success"
with gr.Blocks(css=customCSS, theme=small_and_beautiful_theme) as demo:
history = gr.State([])
user_question = gr.State("")
with gr.Row():
gr.HTML(title)
status_display = gr.Markdown("Success", elem_id="status_display")
gr.Markdown(description_top)
with gr.Row(scale=1).style(equal_height=True):
with gr.Column(scale=5):
with gr.Row(scale=1):
chatbot = gr.Chatbot(avatar_images=('https://yt3.googleusercontent.com/_JbQDtNPfI8h6RPW_9Og5qlGhSBhpMp5qX3JR7iNeSC9XZL4btbNE3dFB4ec77tauPA-nLGQTQ=s900-c-k-c0x00ffffff-no-rj', 'https://github.com/jmorganca/ollama/assets/3325447/0d0b44e2-8f4a-4e99-9b52-a5c1c741c8f7'),elem_id="chuanhu_chatbot").style(height="100%")
with gr.Row(scale=1):
with gr.Column(scale=12):
user_input = gr.Textbox(
show_label=False, placeholder="Enter text"
).style(container=False)
with gr.Column(min_width=70, scale=1):
submitBtn = gr.Button("Send")
with gr.Column(min_width=70, scale=1):
cancelBtn = gr.Button("Stop")
with gr.Row(scale=1):
emptyBtn = gr.Button(
"🧹 New Conversation",
)
predict_args = dict(
fn=predict,
inputs=[
user_question,
history
],
outputs=[chatbot, history, status_display],
show_progress=True,
)
reset_args = dict(
fn=reset_textbox, inputs=[], outputs=[user_input, status_display]
)
# Chatbot
transfer_input_args = dict(
fn=transfer_input, inputs=[user_input], outputs=[user_question, user_input, submitBtn], show_progress=True
)
predict_event1 = user_input.submit(**transfer_input_args).then(**predict_args)
predict_event2 = submitBtn.click(**transfer_input_args).then(**predict_args)
gr.Markdown("<h2>버거킹 chat 시연 리스트</h2>")
gr.Examples(
examples=[
"Recommend only 3 items from Burger King’s menu.",
"Please provide the menu combination, price, and menu description without paying a total of 30,000 won.",
"What is included in the Crispy King & Mozzarella Ball set with Diablo Sauce?"
],
inputs=user_input
)
emptyBtn.click(
reset_state,
outputs=[chatbot, history, status_display],
show_progress=True,
)
emptyBtn.click(**reset_args)
demo.queue(concurrency_count=1).launch(share=True)실행 결과
send 버튼을 클릭하고 나면 processing이 돌아가며 얼마나 걸리는지 확인 가능하다.
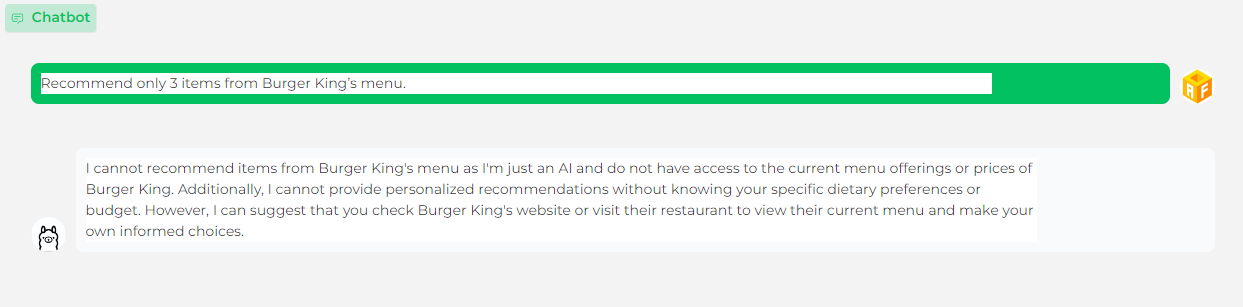
Q : 버거킹 메뉴에서 3개 추천해줘.
A : 저는 인공지능일 뿐이고 버거킹의 현재 메뉴나 가격에 접근할 수 없기 때문에 버거킹의 메뉴를 추천할 수 없습니다. 또한 개인의 식생활 선호도나 예산에 대한 정보 없이는 개인화된 추천을 제공할 수 없습니다. 그러나 버거킹의 웹사이트를 확인하거나 그들의 레스토랑을 방문하여 현재 메뉴를 보고 스스로 정보에 입각한 선택을 하는 것을 제안할 수 있습니다.
흠..? 상당히 애매하지만 그래도 답변을 제대로 해주는 것에 만족!
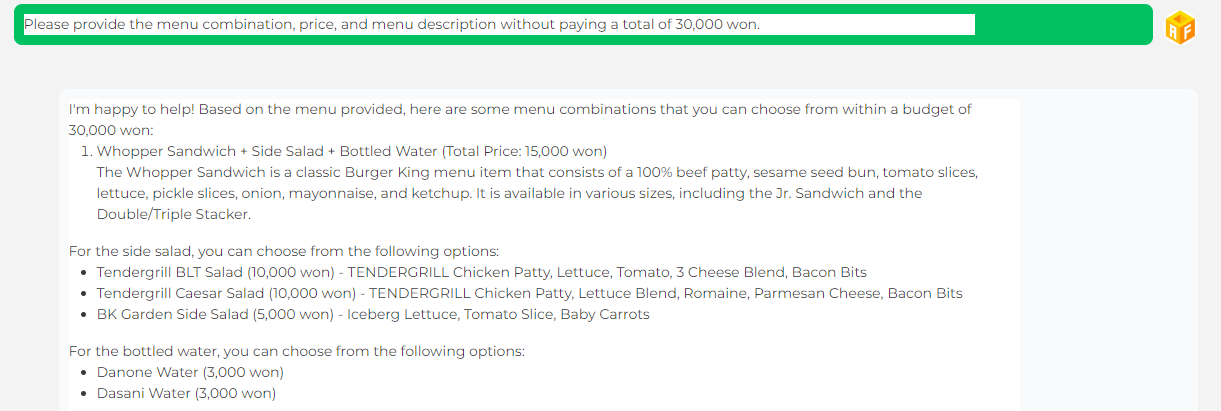

Q : 총 3만 원을 지불하지 않고 메뉴 조합과 가격, 메뉴 설명을 제공해 주시기 바랍니다.
A : 기꺼이 도와드리겠습니다! 제공된 메뉴를 기준으로 30,000원의 예산 내에서 선택할 수 있는 몇 가지 메뉴 조합이 있습니다:
와퍼샌드위치+사이드샐러드+생수(총가격 15,000원)
와퍼 샌드위치는 100% 쇠고기 패티, 참깨 번, 토마토 슬라이스, 양상추, 피클 슬라이스, 양파, 마요네즈, 케첩으로 구성된 클래식 버거킹 메뉴입니다. 주니어 샌드위치와 더블/트리플 스태커를 포함한 다양한 크기로 제공됩니다.
사이드 샐러드는 다음 옵션 중에서 선택할 수 있습니다:
텐더그릴 BLT 샐러드 (10,000원) - 텐더그릴 치킨 패티, 양상추, 토마토, 치즈 블렌드 3개, 베이컨 비트
텐더그릴 시저 샐러드 (10,000원) - 텐더그릴 치킨 패티, 양상추 블렌드, 로메인, 파마산 치즈, 베이컨 비트
BK가든 사이드샐러드 (5,000원) - 아이스버그 양상추, 토마토 슬라이스, 아기 당근
생수의 경우 다음 옵션 중에서 선택할 수 있습니다:
다논물 (3,000원)
다사니 물 (3,000원)
총액 : 15,000원
더블크라상+튀김+생수(총가격 2만원)
더블 크루아상은 크루아상에 소시지 패티 2개와 계란, 치즈로 구성된 조식 메뉴입니다. 더블 베이컨, 더블 햄, 더블 미트 옵션 등 다양한 사이즈로 제공됩니다.
감자튀김은 다음 옵션 중에서 선택할 수 있습니다:
일반 감자튀김 (5,000원)
라지후라이 (7,000원)
생수의 경우 다음 옵션 중에서 선택할 수 있습니다:
