시작
Yolov5를 활용하여 Custom dataset을 인식하도록 만들어보겠습니다!!
가장 먼저 준비해야 될 건 역시 자신의 Dataset일겁니다!
저는 Roboflow를 활용하여 Custom dataset을 만들었고, 이를 토대로 Jupyter Notebook에서 실행이 가능하도록 만들어보겠습니다.
출처 : https://github.com/roboflow/notebooks/blob/main/notebooks/train-yolov5-object-detection-on-custom-data.ipynb
위 공식문서를 통해서 알아낸 내용들을 제가 사용할 수 있도록 약간의 각색이 들어갔습니다.
Git clone
!git clone https://github.com/ultralytics/yolov5 # clone repo가장 먼저 yolov5의 repository를 clone합니다.
%cd yolov5그 다음은 Clone한 Yolov5의 폴더로 이동합니다.
!git reset --hard 064365d8683fd002e9ad789c1e91fa3d021b44f0다음은 reset을 해줍니다.
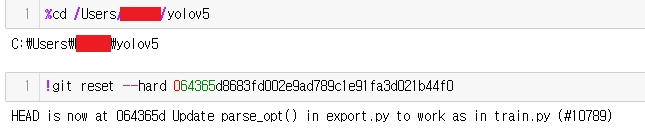
실행하고 나면 이렇게 나올겁니다.
이때 !git reset --hard ~~~를 실행한 결과 아래 메세지는 git 저장소의 기록에서 현재 위치(체크아웃한 커밋)가 설명된 변경 사항을 포함하는 이 특정 커밋(064365d)으로 업데이트되었음을 알려주는 메세지 입니다.
(정확히 제가 이해한게 맞는지 모르겠습니다. 이 부분에 대한 제 설명이 오류가 존재한다면 알려주시면 감사하겠습니다!)
import torch
!pip install -qr requirements.txt
다음으로 requirements에서 필요로 하는 문서들을 install 한 다음,
import torch from IPython.display import Image, clear_output # 이미지를 display하기 위해서 사용 from utils.downloads import attempt_download # models/datasets를 다운로드 하기 위해서 준비다음으로 이렇게 준비해주시면 됩니다.
⭐️⭐️⭐️중요!!! 후회 하지 않으려면!!!!!!!!
print('Setup complete. Using torch %s %s' % (torch.__version__, torch.cuda.get_device_properties(0) if torch.cuda.is_available() else 'CPU'))
이 부분 정말 정말 print결과 확인을 잘 하셔야 됩니다.

저는 이렇게 나왔는데 보시면 CPU로 잡혀있는걸 확인할 수 있습니다.
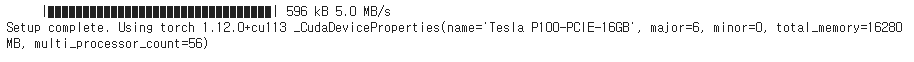
공식 문서에서는 이런 식으로 1.13.1+cu113으로 CUDA가 제대로 잡혀서 GPU를 사용할 준비가 된 것을 확인할 수 있습니다.
하다 보니까 제가 체크를 하지 못 하고 넘어갔는데 CPU를 사용해서 계산이 이뤄져서 굉장히 많은 시간이 소모됐습니다... 반드시 반드시 반드시 이 부분을 체크하고 넘어가시길 바랍니다.
혹여 제대로 잡히지 않는다면 Jupyter notebook GPU 설정하기 와 같은 내용을 참고 하시면 좋을거 같습니다.
Roboflow using in jupyter notebook
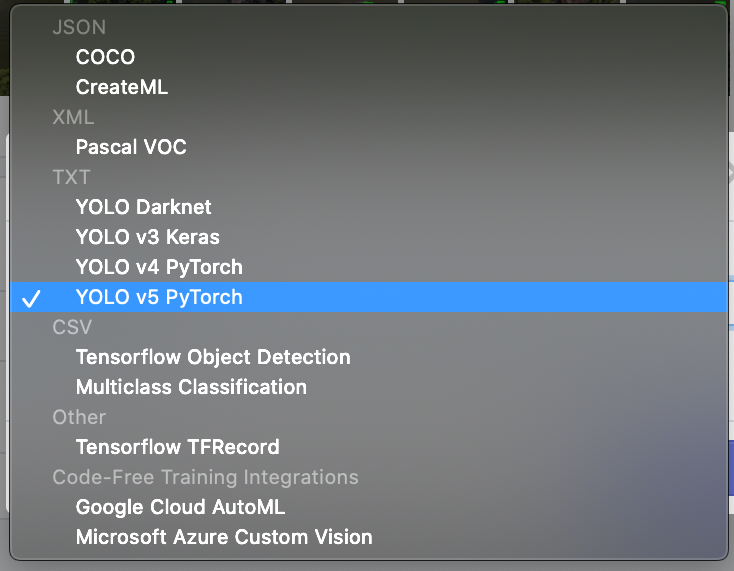
만들어 놓은 dataset을 roboflow에서 export할 때 반드시 YOLO v5 PyTorch를 해주시길 바랍니다.
저는 저걸 하지 않고 이상하게 해서 시간을 많이 날렸습니다 ㅠㅠ
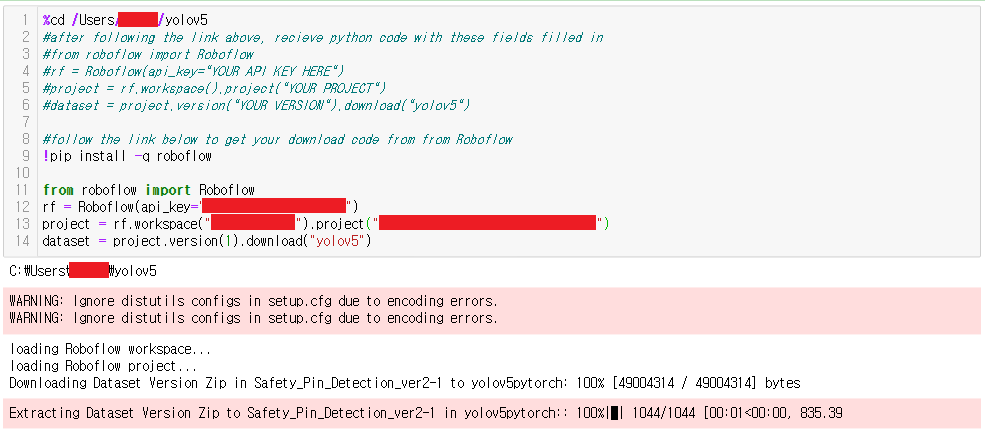
%cd /Users/kimdu/yolov5 #follow the link below to get your download code from from Roboflow !pip install -q roboflow from roboflow import Roboflow rf = Roboflow(api_key="Your_API_Key") project = rf.workspace("Your_workspace_name").project("Your_project_name") dataset = project.version(1).download("yolov5")
Roboflow에서 dataset을 export까지 했다면 이제 위와 같이 roboflow를 설치하고 export한 내용을 붙여넣기 해주시면 됩니다.
(Export할 때 파일이 다운로드 되는게 아니라 아래 진행 결과와 같이 코드를 복사할 수 있도록 코드가 나올 겁니다. 그 코드를 복사하고 Jupyter notebook에 붙여넣기 하시면 됩니다.)
yaml
%cd /yolov5 %pycat {dataset.location}/data.yaml
자 이번에는 yaml파일에 따라 데이터를 나눕니다.
곤혹스러웠던 내용중 하나인데, 공식문서의 설명에서는 %cat을 사용하여 자꾸 에러메시지가 출력됐습니다.
혹여나 OS가 윈도우라면 %cat 말고 %pycat을 사용하시면 됩니다!!!
# define number of classes based on YAML import yaml with open(dataset.location + "/data.yaml", 'r') as stream: num_classes = str(yaml.safe_load(stream)['nc'])

nc는 앞서 적힌 설명과 같이 num_classes로서 여러분들이 지정하신 라벨링 이름입니다.
이 부분에서는 따로 출력이 나오지 않습니당
#this is the model configuration we will use for our tutorial %pycat /yolov5/models/yolov5s.yaml
마찬가지로 여기서도 따로 출력이 나오지 않습니다.
단, 마찬가지로 여기서도 %cat이 아닌 %pycat을 사용해주셔야 됩니다.

globs
#customize iPython writefile so we can write variables from IPython.core.magic import register_line_cell_magic @register_line_cell_magic def writetemplate(line, cell): with open(line, 'w') as f: f.write(cell.format(**globals()))
이 다음으로
%%writetemplate /yolov5/models/custom_yolov5s.yaml
# parameters
nc: {num_classes} # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, BottleneckCSP, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]새롭게 다시 작성을 해줍니다.
nc를 저희가 만든 dataset에 맞게 변경을 해줘야 하기 때문입니다.

Start Train
%%time %cd /yolov5/ !python train.py --img 416 --batch 16 --epochs 100 --data {dataset.location}/data.yaml --cfg /yolov5/models/custom_yolov5s.yaml --weights '' --name yolov5s_results --cache
이제 train을 시작하시면 됩니다.
이때 아까 말씀드렸던 GPU로 연결이 되어있지 않다면, 끔찍한 고통과 인내의 시간이 필요해집니다.
저는 훈련을 마치는데 4시간 가까이 소모됐습니다....
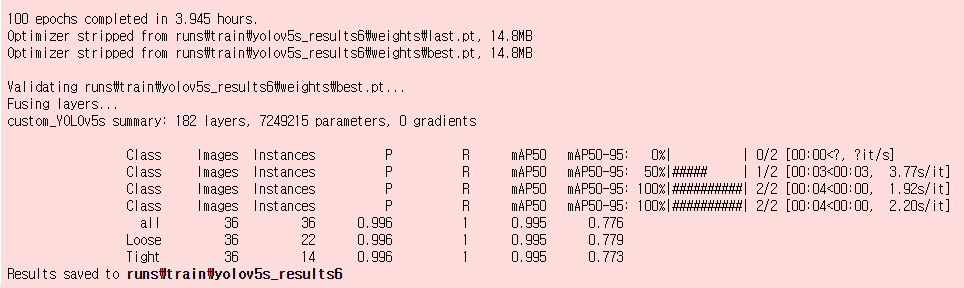
(끔찍한 인내의 시간을 보여주는 3.945 hours...
사실 원래 이 보다 덜 걸려도 되는걸 이만큼 걸려서 더 화가 나는 기분입니다...)
실행결과 화면을 확인해보시면 yolov5s_results6에 save된걸 확인할 수 있습니다.
반드시 saved된 위치를 잘 확인하시길 바랍니다.
best.pt가 상기된 위치에 저장되어 있기 때문입니다.
results check
# Start tensorboard # Launch after you have started training # logs save in the folder "runs" %load_ext tensorboard %tensorboard --logdir runstensorboard를 통해서 결과를 확인하도록 하겠습니다.
# we can also output some older school graphs if the tensor board isn't working for whatever reason... from utils.plots import plot_results # plot results.txt as results.png Image(filename='/yolov5/runs/train/yolov5s_results6/results.png', width=1000) # view results.png
Image(filename='/yolov5/runs/train/yolov5s_results6/results.png', width=1000) 에서 확인할 수 있듯이 yolov5s_results6 folder에 제가 원하는 best.pt가 있으므로 results.png를 가져올 때도 best.pt가 저장된 폴더에서 가져오시는게 최고의 퍼포먼스를 확인할 수 있습니다.
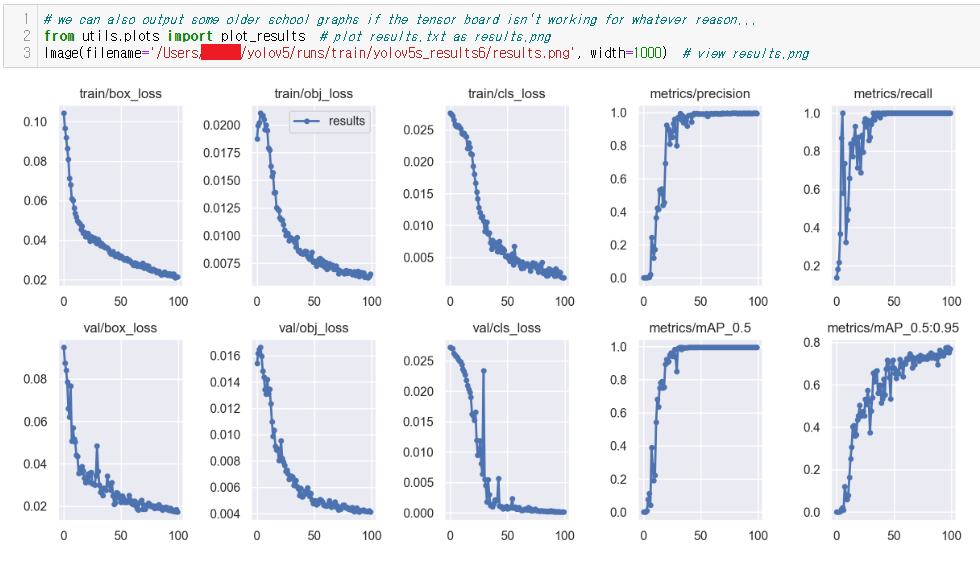
위와 같은 결과 화면을 확인할 수 있습니다.
확실히 반복될 때 마다 loss가 떨어지는 모습을 확인할 수 있습니다.
제대로 학습이 이뤄졌음을 짐작할 수 있습니다.
# first, display our ground truth data print("GROUND TRUTH TRAINING DATA:") Image(filename='/yolov5/runs/train/yolov5s_results/test_batch0_labels.jpg', width=900)이유는 모르겠지만, 저는 위 jpg가 나오지 않았습니다...
이 부분은 조금 더 제가 알아보도록 하겠습니다.
# print out an augmented training example print("GROUND TRUTH AUGMENTED TRAINING DATA:") Image(filename='/yolov5/runs/train/yolov5s_results/train_batch0.jpg', width=900)
Find Weights and Here We Go!!
# trained weights are saved by default in our weights folder %ls runs\
이때도 공식 문서에서는 %ls runs/ 라고 되어있지만, 이렇게 하면 동작을 하지 않습니다.
따라서 반드시 %ls runs\라고 해주시면 동작 하는것을 확인할 수 있습니다.
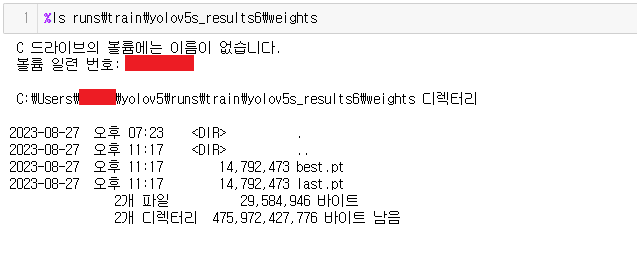
%ls runs\train\yolov5s_results6\weights
여기서도 반드시 saved된 results folder로 이동하여 Weights를 확인하시길 바랍니다.
결과에서 보이시듯 best.pt를 찾은것을 확인할 수 있습니다.
Custom Dataset 사용하기!!
# when we ran this, we saw .007 second inference time. That is 140 FPS on a TESLA P100!
# use the best weights!
%cd /yolov5/
!python detect.py --weights runs/train/yolov5s_results6/weights/best.pt --img 416 --conf 0.4 --source /yolov5/Movie_check/Movie_Data.mp4위와 같이 detect.py와 weights 폴더의 best.pt를 사용하여 이제 detection을 원하는 영상을 통해서 제대로 검출이 이뤄지는 것을 확인할 수 있습니다!!!

검출이 이뤄지는 영상은 exp12에 저장된것을 확인할 수 있었습니다.
