요구사항 및 데이터 특징
사용된 기술
Java, SpringBatch, MySQL
Book 테이블
id(PK - 자동증가 컬럼)
isbn13varchar(13) NOT NULL (유니크 제약조건)
loan_countint NOT NULL DEFAULT '0'
제목 등등 컬럼 ...
csv에 등장하는 책 데이터는 모두 Book 테이블에는 저장돼 있다.
CSV 데이터
요구사항
- 1521개의 csv 파일에서 대출 건수를 집계한 후 Book 테이블에 loan_count 필드 최신화
- AWS EC2 t3.micro에서 동작하는 Batch 시스템
- Xmx Xms 512M으로 설정할 것.
- CPU 사용량을 16.6% 이하로 낮출 것. (로컬 환경은 6코어 12스레드 CPU)

빠르게 성능 비교를 해보기 위해서 전체 csv파일에서 15%만 사용한다.
접근 1) 임시 테이블 사용하기
처리 과정
- 임시 테이블(temp_loan) 생성 (isbn13, loan_count)
- load infile로 DB에 파일별로 삽입
- temp_loan 테이블에 isbn13 필드에 B트리 인덱스 걸기
- ISBN으로 집계해서 업데이트
sum(loan_count) ... group by isbn13
임시 테이블에 전체 파일인 1521개의 파일을 Insert하고 isbn13 인덱스를 생성하는데 70분이 걸렸다.
15%의 데이터로 진행을 한다면 임시 테이블을 구성하는데만 약 10분이 걸릴 것이다.
group by를 통한 집계를 제외한 시간이긴 하지만 오래 걸리는 건 매한가지니 생략한다.
접근 2) Batch 서버에서 집계하기
Batch 서버에서 직접 대출 수를 직접 종합해서 임시 테이블 구성이 필요없도록 최적화를 진행한다.
Book 테이블에 update 쿼리를 날리는 부분은 공통 부분이기 때문에 성능 비교에서 생략한다.
처리 과정
- Book 테이블에 ISBN13 정보를 읽어와서 Batch 서버내의 Map으로 가져와서
{ ISBN13 - 0 }으로 초기화- 대출 수 집계 Step (파티셔닝 = 멀티 스레딩)
- CSV 파일에서 ISBN13과 대출 수 가져오기
- CSV 파일을 읽어서 대출 수 더하기
- 집계된 Map 정보를 파일 만들기
1,3번 Step은 싱글 스레드로 진행되고 2번 Step은 멀티 스레드로 진행될 것이다.
2-1) HashMap 사용
HashMap의 구조적 수정 작업. 즉 Map에 엔트리를 추가하는 작업은 싱글 스레드로 처리되기 때문에 ConcurrentHashMap을 사용하지 않아도 된다.
HashMap의 조회는 멀티 스레드로 진행해도 괜찮다. 다음 HashMap 문서 내용을 참고하자.

출처) https://docs.oracle.com/javase/8/docs/api/java/util/HashMap.html
다음 코드가 집계 작업을 진행할 서비스이다.
public class MultiMapLoanCountService implements LoanCountService {
private Map<Long, AtomicInteger> map;
@Override
public void init() {
map = new HashMap<>();
}
@Override
public void add(String isbn13) {
map.put(Long.parseLong(isbn13), new AtomicInteger(0));
}
@Override
public boolean contains(String isbn13) {
return map.containsKey(Long.parseLong(isbn13));
}
@Override
public void increase(String isbn, int loanCount) {
if(loanCount == 0)
return;
if(!contains(isbn))
throw new IllegalArgumentException("찾을 수 없는 ISBN");
long key = Long.parseLong(isbn);
map.get(key).getAndAdd(loanCount);
}
...
}최적화 준비
서비스 코드를 보면 implements LoanCountService를 확인할 수 있다.
이 코드는 최적화할 여지가 많다고 생각해서 다음 인터페이스를 구성하고 다른 구현체로 갈아껴놓을 준비를 해놓았다.
public interface LoanCountService {
long EMPTY_SPACE = Long.MAX_VALUE;
int BOOK_TABLE_SIZE = 4_000_000; // 여유분까지 추가
void init();
void add(String isbn13);
boolean contains(String isbn13);
default void beforeCount() {}
void clearAll();
// LongIntPrimitiveConsumer은 내가 만든 long, int를 받는 함수형 인터페이스
void processAll(LongIntPrimitiveConsumer consumer);
void increase(String isbn, int loanCount);
}2-2) 배열 + AtomicIntegerArray
ISBN13 데이터는 처음 삽입된 이후에 처리 과정에서 수정되지 않는다.
그렇다면 굳이 메모리 오버헤드를 감수하며 Map을 사용할 필요가 있을까?
그래서 사용한 방법이 long 배열과 AtomicIntegerArray을 조합한 방식이다
처리 과정
1.long[] isbnArray에 Long.MAX_VALUE를 채워넣기
2.isbnArray의 맨 앞부터 DB에 있는 ISBN13 값을 채워넣기
3. 다 채워넣었다면 ISBN13 값을 정렬하기.
4.Arrays.BinarySearch로 ISBN13 위치 검색
5. 같은 위치의AtomicIntegerArray loanArray요소의 값을 증가시키기
public class MultiArrayLoanCountService implements LoanCountService {
private long[] isbnArray;
private AtomicIntegerArray loanArray;
private int loanIdx = 0;
@Override
public void init() {
isbnArray = new long[BOOK_TABLE_SIZE];
loanArray = new AtomicIntegerArray(BOOK_TABLE_SIZE);
Arrays.fill(isbnArray, EMPTY_SPACE);
loanIdx = 0;
}
@Override
public void add(String isbn13) {
isbnArray[loanIdx++] = Long.parseLong(isbn13);
}
@Override
public void beforeCount() {
Arrays.sort(isbnArray);
}
private int findIdx(String isbn13) {
return Arrays.binarySearch(isbnArray, Long.parseLong(isbn13));
}
@Override
public boolean contains(String isbn13) {
return findIdx(isbn13) >= 0;
}
@Override
public void increase(String isbn, int loanCount) {
if(loanCount == 0)
return;
if(!contains(isbn))
throw new IllegalArgumentException("찾을 수 없는 ISBN");
loanArray.getAndAdd(findIdx(isbn), loanCount);
}
...
}성능 비교 및 결론
| Data Structure | Threads | Chunk Size | 처리시간 | Old 영역 | CPU 사용량 |
|---|---|---|---|---|---|
long[], AtomicIntegerArray | 멀티(2) | 1000 | 2m 28s 749ms | 211 MiB | 14.1% |
Map<Long, AtomicInteger> | 멀티(2) | 1000 | 2m 42s 407ms | 324 MiB | 36% |
long[], int[] | 싱글(1) | 2000 | 3m 33s 498ms | 154 MiB | 10.1% |
기본 배열과 싱글 스레드를 사용하는 방식도 성능을 체크해봤다.
결과적으로 long[]와 AtomicIntegerArray를 사용하는 방식을 선택했다.
10m => 2m 28s 749ms으로 감소했다.
만약 전체 데이터를 다룬다면 처리 시간이 70분에서 약 17분으로 감소한 것이다.
처리 시간 75.21%로 감소 = 4.03배 향상
다음 그래프들이 long[]과 AtomicIntegerArray를 사용할 때의 서버 상태 그래프이다.
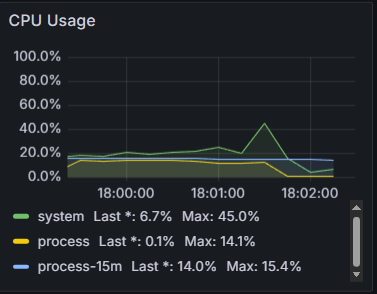
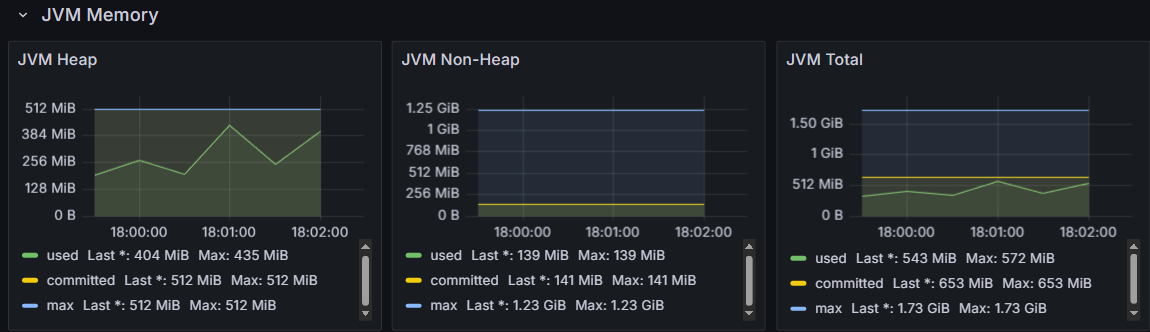
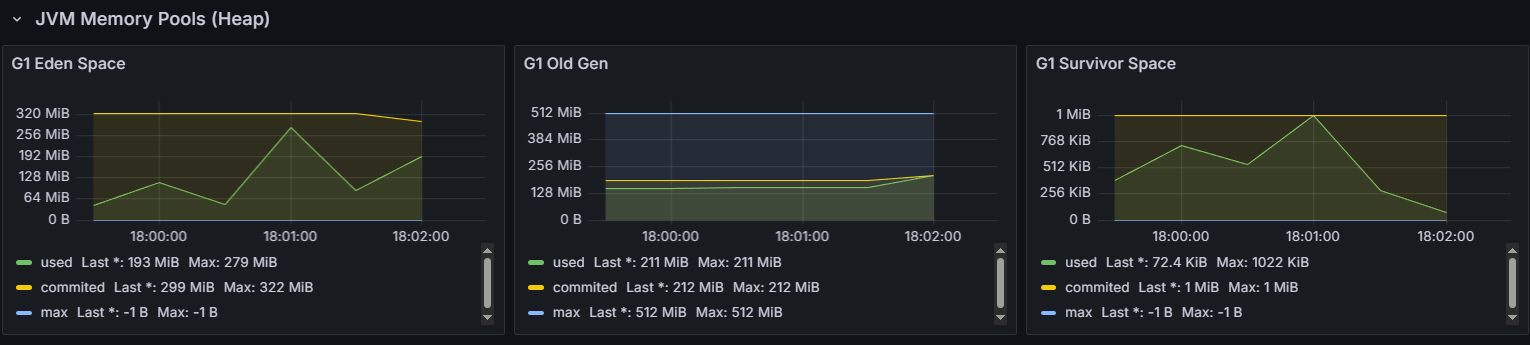
왜 CPU 사용량이 감소했을까?
이론적으로 contains를 할 때 시간복잡도는 Map은 O(1), BinarySearch를 사용하는 long 배열은 O(logN)이다.
하지만 CPU 사용량은 36%, 14.1%이다.
왜 시간복잡도가 안좋은 방식을 사용했는데 CPU 사용량이 감소했을까?
개인적인 생각을 적은 부분이다.
작아진 Old 메모리 사용량으로 인한 GC 부하 감소
jvm_gc_pause_seconds_count를 모니터링한 결과이다.
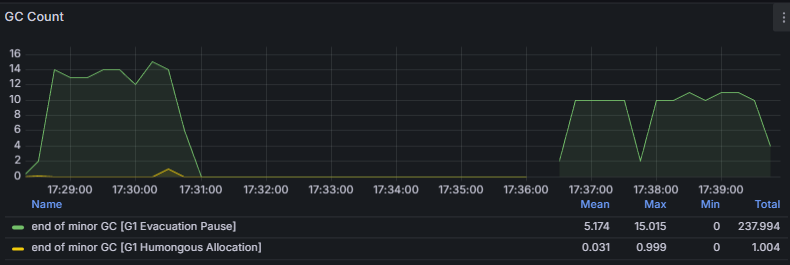
전자가 Map<Long,AtomicInteger> 방식이고, 후자가 long[], AtomicIntegerArray 방식이다.
확실히 Map을 사용하는 방식이 Old영역을 많이 잡다보니 GC가 더 일어나는 것을 확인할 수 있다.
힙 영역을 512M에서 1G로 바꿨을 때 CPU의 최대 사용량이 26.3%로 감소한 것을 확인했다.