요구사항 및 데이터 특징
사용된 기술
Java, SpringBatch, MySQL
Book 테이블 컬럼
id(PK - 자동증가 컬럼)
isbn13varchar(13) NOT NULL (유니크 제약조건)
제목 등등 컬럼 ...
요구사항
- 1521개의 csv 파일에서 유니크한 ISBN13의 책 데이터를 Book 테이블에 저장하기.
- AWS EC2 t3.micro에서 동작하는 Batch 시스템
- Xmx Xms 512M으로 설정할 것.
- CPU 사용량을 16.6% 이하로 낮출 것. (로컬 환경은 6코어 12스레드 CPU)
데이터 특징
- Book 테이블에는 약 280만개의 데이터가 이미 저장돼 있다.
- csv 파일의 데이터는 이미 DB에 저장돼 있는 책 데이터가 대부분이다.
- 매월 약 1만건의 새로운 책이 Insert 된다.
이 글은 1.3억건의 데이터의 15% 정도의 데이터인 약 2000만건의 데이터로 진행된다.
(1521개의 파일 중 일부 파일)
최적화한 방법들의 처리시간은 성능 비교 섹션에 표를 만들어놨다.
❌ DB를 exist 쿼리로 조회하기
DB에 ISBN13이 있는지 processor에서 exist 쿼리를 보내서 필터링한 후 Insert하기.
정말 단순한 방식이지만 1.3억 번의 exist 쿼리 필요하다.
청크단위로 처리해도 N만 번의 추가적인 쿼리가 발생하므로 쿼리를 최소화 시킬 방법이 필요했다.
✅ ISBN13을 서버에서 캐싱하기
DB에 있는 ISBN13의 정보를 모두 가져와서 Batch 서버에 Set에 캐싱한다.
그리고 캐싱한 정보로 csv 데이터를 필터링하는 방식을 사용하면, exist 쿼리를 반복할 필요가 없을 것이다.
Step 구성
BeforeStep: DB에 있는 ISBN13을
HashSet에 넣기
Reader: csv 파일 읽기
Processor:HashSet에 존재하는지 확인하기
Writer: 새로운 책 데이터Insert Ignore로 삽입
AfterStep:HashSetclear()
중복 데이터에 Insert Ignore만 사용?
굳이 Processor에서 중복 데이터를 필터링하지 않고, MySQL에서 제공해주는 Insert Ignore로 전부 처리하면 어떻게 될까?
MySQL에서 제공해주는 Insert Ignore의 경우 키 충돌이 발생했을 때 해당 Insert를 무시하고 처리를 진행하지만 키의 충돌이 많아질수록 삽입 성능이 느려진다.
지금 문제는 1.3억개의 데이터에서 1만개의 새로운 데이터를 삽입하는 것이다.
즉, 대부분이 중복 데이터이기 때문에 Insert Ignore는 최악의 속도로 처리된다.
최적화 1) 멀티 스레딩처리
HashSet의 요소 삽입 부분은 싱글스레드로 처리되고, 조회는 멀티스레드로 진행되기 때문에 딱히 문제될 건 없어 보인다.
최적화 1 방법을 그대로 두고 SpringBatch 파티셔닝을 통해서 여러 스레드에서 처리할 파일을 나눠서 처리하는 방식으로 전환하면 데드락이 발생한다.
Insert Ignore 데드락 발생
멀티 스레딩으로 중복된 유니크 키(ISBN13)를 집어넣으면서 넥스트 키 락이 발생하며 데드락이 발생했다.
자세한 내용은 Insert Ignore 키 충돌과 데드락 발생 글에 정리해놨다.
❌ 방법 1) 중복 데이터를 완벽하게 걸러서 Insert하기
Batch서버에서 DB 데이터와 완벽히 동기화를 해서 Insert를 진행해야 락을 없앨 수 있다.
동기화를 위해 ConcurrentHashMap.newKeySet()을 사용할 수도 있겠다.
Step의 구성을 다음과 같이 바꾸는 것이다.
Step 구성
BeforeStep: DB에 있는 ISBN13을
ConcurrnetHashSet에 넣기
Reader: csv 파일 읽기
Processor:ConcurrnetHashSet에 존재하는지 확인하기
Writer:ConcurrnetHashSet.add로 캐시 동기화 + 새로운 책 데이터Insert Ignore로 삽입
AfterStep:ConcurrnetHashSetclear()
하지만 ConcurrentHashMap을 사용해도 충돌이 발생할 수 있다.
ConcurrentHashMap도 충돌이 발생할 수 있다.
다음 설명은
ConcurrentHashMap에 읽기 일관성에 관한 내용이다. 자세한 내용은 링크를 참고하자.
참고) https://www.baeldung.com/concurrenthashmap-reading-and-writing
ConcurrentHashMap에서는 다중 스레드 환경에서 쓰기 작업의 높은 처리량과 일관성을 확보하기 위해 쓰기 작업에서는 버킷에 락을 걸지만 조회 작업에서는 락을 걸지 않기 때문에 위 설명과 같은 현상이 발생한다.

정말 단순하게 가면 HashSet을 사용하고 HashSet 요소에 접근할 때 synchronized를 사용해서 동기화하는 방식이 있을 것이다. 하지만 이 방식은 멀티 스레드를 무의미하게 만든다.
✅ 방법 2) 데드락 재시도하기.
전체 데이터를 Insert Ignore로 시도하는 방식이 아니라 전월의 ISBN13을 거른 후에 삽입하기 때문에 Insert 자체가 그렇게 많지는 않다.
물론 새로운 책이 여러 도서관에 추가될 수 있기 때문에 정확히 1만 건보다 많은 Insert가 발생한다.
readCount와 writeCount를 통해 대략적으로 계산해보면 전체 데이터 중 0.001%정도를 Insert 시도하기 때문에 데드락이 빈번하게 발생하진 않을 것이다.
그래서 Step을 가끔 발생하는 데드락을 재시도하도록 만들었다.
return new StepBuilder("bookSyncStep", jobRepository)
.<StockCsvData, Book>chunk(CHUNK_SIZE, transactionManager)
.reader(stockCsvFileReader)
.processor(bookSyncProcessor)
.writer(bookSyncItemWriter)
.faultTolerant()
.retry(CannotAcquireLockException.class) // 데드락 재처리
.retryLimit(5)
.build();Bulk Insert가 데드락이 발생해도 청크단위로 5번 정도는 재시도하도록 만들었다.
최적화 2) CPU 사용량 최소화하기
멀티 스레딩으로 처리를 했을 때 HashSet을 사용했을 때 CPU 사용량이 36.5%가 나왔다. (성능 비교 섹션 확인)
로컬 PC는 6코어의 CPU이기 때문에 1코어에서 동작할 수 있도록 적어도 16.6%로 내려야 한다.
단순하게 생각해보면 2개의 스레드가 2개의 코어를 최대한 사용했을 때 33.2%까지 나올 것이다.
CPU 처리가 많은 Procssor 영역보다 파일을 읽는 Reader나, DB에 삽입 요청을 보내는 Writer로 대기하는 시간이 있기 때문에 CPU 사용량이 33.2%까지 도달하기도 힘들 것이라 생각했다.
하지만 33.2%보다 큰 36.5%가 나왔다.
이 수치는 2코어를 최대한 사용했을 때보다 큰 수치기 때문에,
GC를 진행하는 스레드가 CPU 사용량에 영향을 미치는 것이라고 생각을 했다.
그래서 Long 대신 원시 자료형인 long을 사용하는 원시 자료형 컬렉션을 지원하는 Eclipse 컬렉션을 사용하기로 했다.
다음 의존성을 추가하고 LongHashSet을 사용한다.
implementation("org.eclipse.collections:eclipse-collections:11.1.0")
성능 비교
| 자료구조 | 청크 사이즈 | 스레드 | 최대 CPU 사용량 | 처리 시간 |
|---|---|---|---|---|
| Primitive LongHashSet | 3000 | 멀티(2) | 19.7% | 1m51s100ms |
| Primitive LongHashSet | 2000 | 멀티(2) | 16% | 1m59s397ms |
| long 배열 | 3000 | 멀티(2) | 19.5% | 1m58s726ms |
| HashSet | 3000 | 멀티(2) | 36.5% | 2m39s109ms |
| HashSet | 7000 | 싱글 | 24.3% | 4m20s652ms |
결과적으로 Primitive HashSet에 청크사이즈를 조절해서 사용하도록 결정했다.
다음 그래프가 표에 나온 자료구조들을 위에서부터 차례대로 실행하고 모니터링한 그래프이다. (두 번째 빨간줄 좌우는 무시)
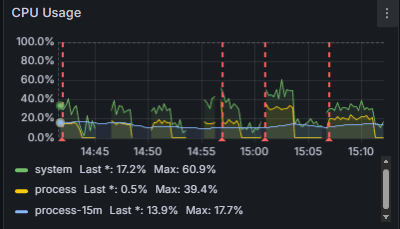
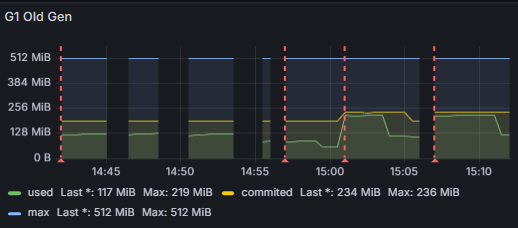
최대 CPU 사용량이 왜 적어졌을까? (불확실)
원시 자료형을 사용하면서 Old 영역 메모리 사용량이 219MiB에서 121MiB로 줄었다.
결과적으로 GC 빈도가 줄며 CPU 사용량이 감소한다.
이건 확실하긴 한데... 이게 36.5%를 19.7%로 줄일 정도로의 개선일까?
청크 사이즈를 2000으로 줄였을 때 CPU 사용량이 19.7%에서 16%로 감소한 것을 보니 유의미한 영향을 준 것은 확실하다.
참고) 대출 수 동기화 - 작아진 Old 메모리 사용량으로 인한 GC 부하 감소
정리
- 반복되는 exist 쿼리 수를 줄이기 위해서 메모리에 DB 정보를 캐싱하는 방법을 선택했다.
- 데드락을 해결하는 방식으로 재시도를 선택했고, 멀티 스레드 처리가 가능해졌다.
- CPU 사용량을 줄이기 위해 JDK 컬렉션 대신 이클립스 컬렉션을 사용했다.
싱글 스레드 + HashSet을 사용했을 때 처리시간인 4m20s652ms을
멀티 스레드 + LongHashSet을 사용하는 방식으로 바꿔 1m59s397ms로 줄였다.
15%의 데이터가 아닌 전체 데이터라면 29분 58초를 13분 16초로 줄인것이다.
(번외) 실패) Bloom Filter 사용하기
아래 링크의 영상으로 BloomFilter 개념을 확인하자. (이 영상을 보면 왜 실패했는지 알 수 있다.)
Youtube - 블룸필터 개념 정리 | CDN, DB 성능개선 | 자료구조
블룸 필터를 다음과 같이 생성하고 사용했다.
private BloomFilter<String> bloomFilter = BloomFilter.create(
Funnels.stringFunnel(Charset.forName("UTF-8")),
3_000_000, 0.0001
);guava - BloomFilter 사용 + 멀티 스레딩
청크사이즈: 3000
스레드: 멀티(2)
처리 시간: 1m48s227ms
실패 원인
블룸필터는 데이터 누락이 발생할 수 있다.
블룸필터를 사용할 때 주의할 점은 mightContains()호출 시에 2가지 답을 준다는 것이다.
1. 블룸필터 안에 이 데이터는 확실하게 존재하지 않는다! (확실)
2. 블룸필터 안에 이 데이터가 존재할 수도 있다... (불확실)
그래서 DB에 존재하지 않는 데이터여도 mightContains를 호출했을 때 true를 반환할 수 있다.
이런 블룸필터의 특징은 데이터 누락으로 이어진다.
성능이 빨라지고, 메모리 사용량도 낮지만
낮은 확률로 데이터 누락이 발생할 수 있기 때문에 적절한 해결책은 아니였다.