이 글에서 사용하는 인덱스의 analyzer는 다음과 같다.
"analysis": {
"tokenizer": {
"my_tokenizer": {
"type": "nori_tokenizer",
"decompound_mode": "mixed"
}
},
"analyzer": {
"my_nori_analyzer": {
"type": "custom",
"tokenizer": "my_tokenizer",
"filter": ["nori_readingform", "nori_part_of_speech", "lowercase"]
}
}
}문제) 한글 문자열 검색 실패
이토록 뜻밖의 뇌과학 이라는 단어을 검색할 때 결과가 존재하지 않는다.
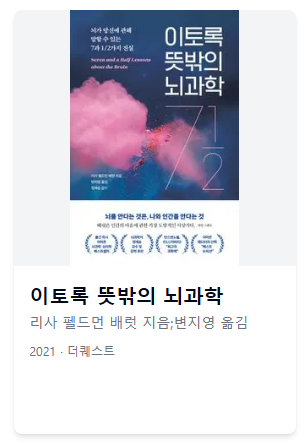
하지만 뇌과학을 키워드로 검색했을 때 여러 검색 결과 중 하나로 확인할 수 있다.
완전히 동일한 제목을 키워드로 검색하는데 왜 검색이 되지 않는지 이해할 수 없다.
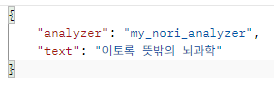
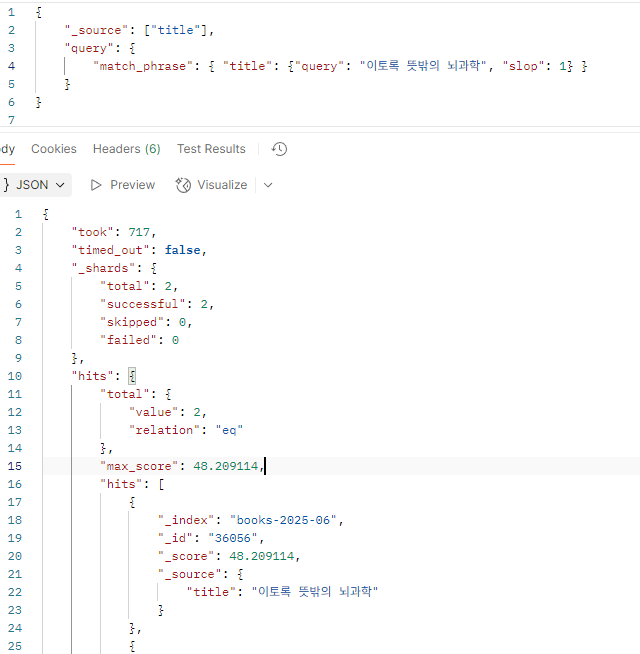
검색은 다음 요청으로 진행된다고 보면 되겠다.
{
"_source": ["title"],
"query": {
"match_phrase": { "title": {"query": "이토록 뜻밖의 뇌과학"} }
}
}원인 - match_phrase 토큰 간격
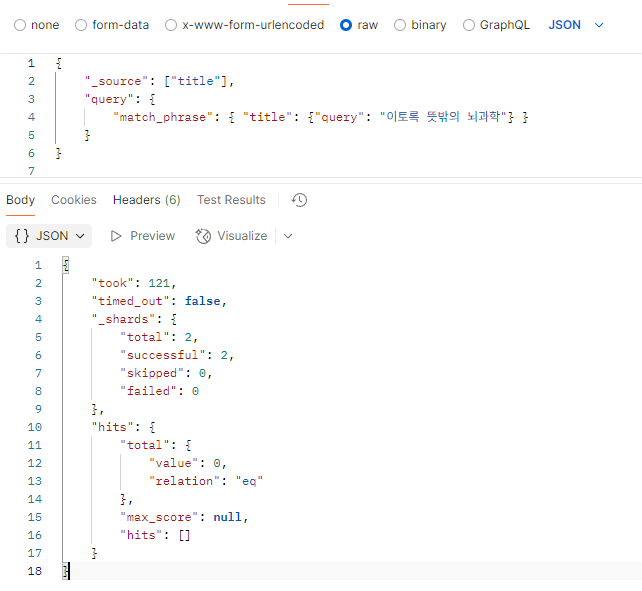
이토록 뜻밖의 뇌과학이라는 단어를 GET books/_analyze로 요청을 보내 분석해보겠다.
결과는 다음과 같다.

간단하게 살펴보자
| 번호 | 토큰 | 포지션 |
|---|---|---|
| 1 | 뜻밖 | 1–2 |
| 2 | 뜻 | 1 |
| 3 | 밖 | 2 |
| 4 | 뇌 | 4 |
| 5 | 과학 | 5 |
이 토큰들이 인덱싱되고, 검색할 때도 사용되게 될 것이다.
여기서 주목해야 할 부분은 분석기의 nori_part_of_speech 거치면서 뜻밖의에서 의가 필터링 됐다는 점이다.
그래서 밖과 뇌사이의 포지션 간격이 생겼다.
밖은 포지션이 2, 뇌는 포지션이 4이다.
match_phrase 쿼리는 입력된 검색어를 순서까지 고려하여 검색을 수행한다.
여기서 일치하는 토큰 사이에 허용되는 최대 간격을 slop으로 설정할 수 있는데
slop은 기본적으로 0으로 설정된다.
이 상황에서는 밖과 뇌사이에 포지션 3이 비었고, 1개의 포지션 만큼의 간격이 발생했다.
그래서 검색이 되지 않은 것이다.
해결 - slop 변경
간단하다. slop을 변경해주면 된다.
한글을 사용하는 경우에는 이렇게 토큰이 필터링되는 경우가 있으니
그래도 slop을 1 이상으로 사용해야 할 것 같다.
matchPhrase 요청을 생성하는 부분에 slop 조건을 추가했고 1로 설정했다.
private Query matchPhrase(String fieldName, String keyword, int slopCnt) {
return new Query.Builder()
.matchPhrase(mp -> mp.field(fieldName).query(keyword).slop(slopCnt))
.build();
}slop이 없을 때
slop이 있을 때
공부한 내용을 적지 말고 이해한 내용을 설명하자