문제
Limit와 Offset을 쓰는 페이징 쿼리는 앞에서 부터 읽기 때문에 IO가 굉장히 많다.
@Repository
public interface BookRepository extends JpaRepository<Book, Long> {
}다음 로그는 bookRepository.findAll(pageable)의 쿼리문이다.
Hibernate:
select
c1_0.id,
c1_0.author,
c1_0.created_at,
c1_0.isbn13,
c1_0.loan_count,
c1_0.publication_year,
c1_0.publisher,
c1_0.subject_code,
c1_0.title
from
book c1_0
limit
?,?
Hibernate:
select
count(c1_0.id)
from
book c1_0limit와 offset을 쓰고, 마지막에 count 쿼리까지 나간다.
이 쿼리가 한 번만 사용되는게 아니라 300만 / 청크 사이즈 만큼 발생하기 때문에 RDS에서는 IO가 굉장히 많이 발생한다.
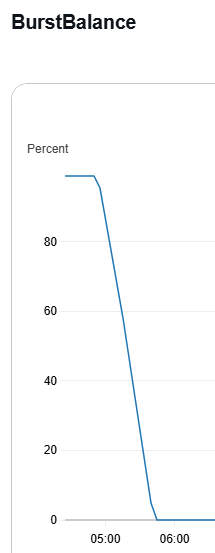
내 RDS에서는 gp2 RDS를 사용하기 때문에 버스트 크레딧이 사진과 같이 급격하게 소모된다.
그리고 결과적으로 분당 1개의 청크만 인덱싱되는 상황이 발생하게 된 것이다.
더 자세한 내용은 바로 앞에 글을 참고하자.
해결 방법
2가지 방법이 있다.
- 페이징 쿼리를 바꿔서 IO를 최소화 하기
- RDS의 ssd를 gp3로 변경하기
프리티어를 유지하기 위해선 gp2를 사용해야 하므로 gp3로 변경하긴 싫다.
페이징 쿼리를 바꿔서 IO를 최소화해 봐야겠다.
IO 최소화 - findAll(pageable) 대체하기
limit와 offset을 쓰고, 마지막에 count 쿼리까지 나간다.
화면에 무엇인가를 출력하는게 아니라 DB에 있는 내용을 OpenSearch로 옮기는 과정이기 때문에 count 쿼리는 필요없다.
findAll()을 마지막으로 가져온 id보다 큰 데이터를 가져오고, 청크 사이즈로 limit를 거는 방식으로 바꿨다.
lastId는 재시작을 위해서 ExecutionContext에 저장하는 것을 잊으면 안된다.
entityManager.createQuery("""
SELECT b
FROM Book b
WHERE b.id > :lastId
ORDER BY b.id ASC
""", Book.class)
.setParameter("lastId", lastId)
.setMaxResults(pageSize)
.getResultList();변경 결과
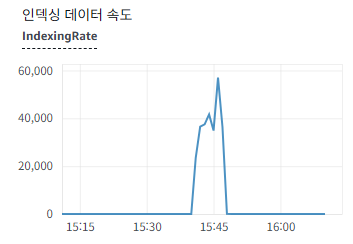
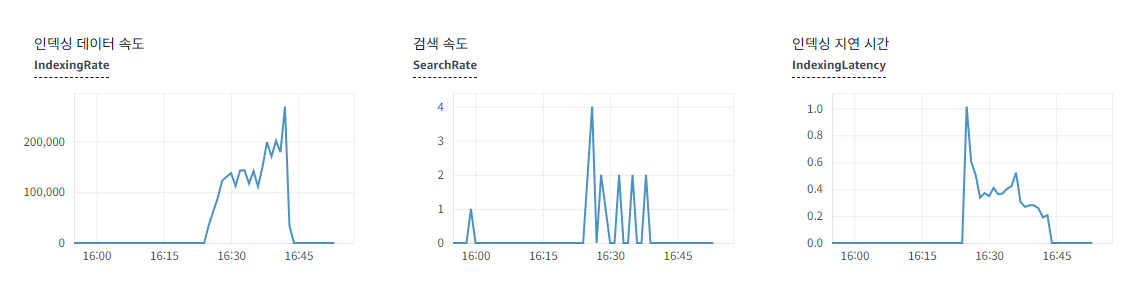
첫 번째 사진이 findAll(pageable)을 사용할 때 OpenSearch에 인덱싱 데이터 속도이다.
두 번째 사진이 where 필터링과 limit를 사용할 때 OpenSearch에 인덱싱 데이터 속도이다.
드디어 OpenSearch에서 인덱싱 지연이 생긴다
많은 데이터가 빠르게 OpenSearch에 들어가면서 소켓 타임아웃 오류가 발생했다.
Caused by: java.net.SocketTimeoutException: 30,000 milliseconds timeout on connection http-outgoing-0 [ACTIVE]
at org.apache.http.nio.protocol.HttpAsyncRequestExecutor.timeout(HttpAsyncRequestExecutor.java:387) ~[httpcore-nio-4.4.16.jar!/:4.4.16]
at org.apache.http.impl.nio.client.InternalIODispatch.onTimeout(InternalIODispatch.java:98) ~[httpasyncclient-4.1.5.jar!/:4.1.5]
at org.apache.http.impl.nio.client.InternalIODispatch.onTimeout(InternalIODispatch.java:40) ~[httpasyncclient-4.1.5.jar!/:4.1.5]
at org.apache.http.impl.nio.reactor.AbstractIODispatch.timeout(AbstractIODispatch.java:175) ~[httpcore-nio-4.4.16.jar!/:4.4.16]
at org.apache.http.impl.nio.reactor.BaseIOReactor.sessionTimedOut(BaseIOReactor.java:261) ~[httpcore-nio-4.4.16.jar!/:4.4.16]
at org.apache.http.impl.nio.reactor.AbstractIOReactor.timeoutCheck(AbstractIOReactor.java:506) ~[httpcore-nio-4.4.16.jar!/:4.4.16]
at org.apache.http.impl.nio.reactor.BaseIOReactor.validate(BaseIOReactor.java:211) ~[httpcore-nio-4.4.16.jar!/:4.4.16]
at org.apache.http.impl.nio.reactor.AbstractIOReactor.execute(AbstractIOReactor.java:280) ~[httpcore-nio-4.4.16.jar!/:4.4.16]
at org.apache.http.impl.nio.reactor.BaseIOReactor.execute(BaseIOReactor.java:104) ~[httpcore-nio-4.4.16.jar!/:4.4.16]
at org.apache.http.impl.nio.reactor.AbstractMultiworkerIOReactor$Worker.run(AbstractMultiworkerIOReactor.java:591) ~[httpcore-nio-4.4.16.jar!/:4.4.16]
at java.base/java.lang.Thread.run(Thread.java:1583) ~[na:na]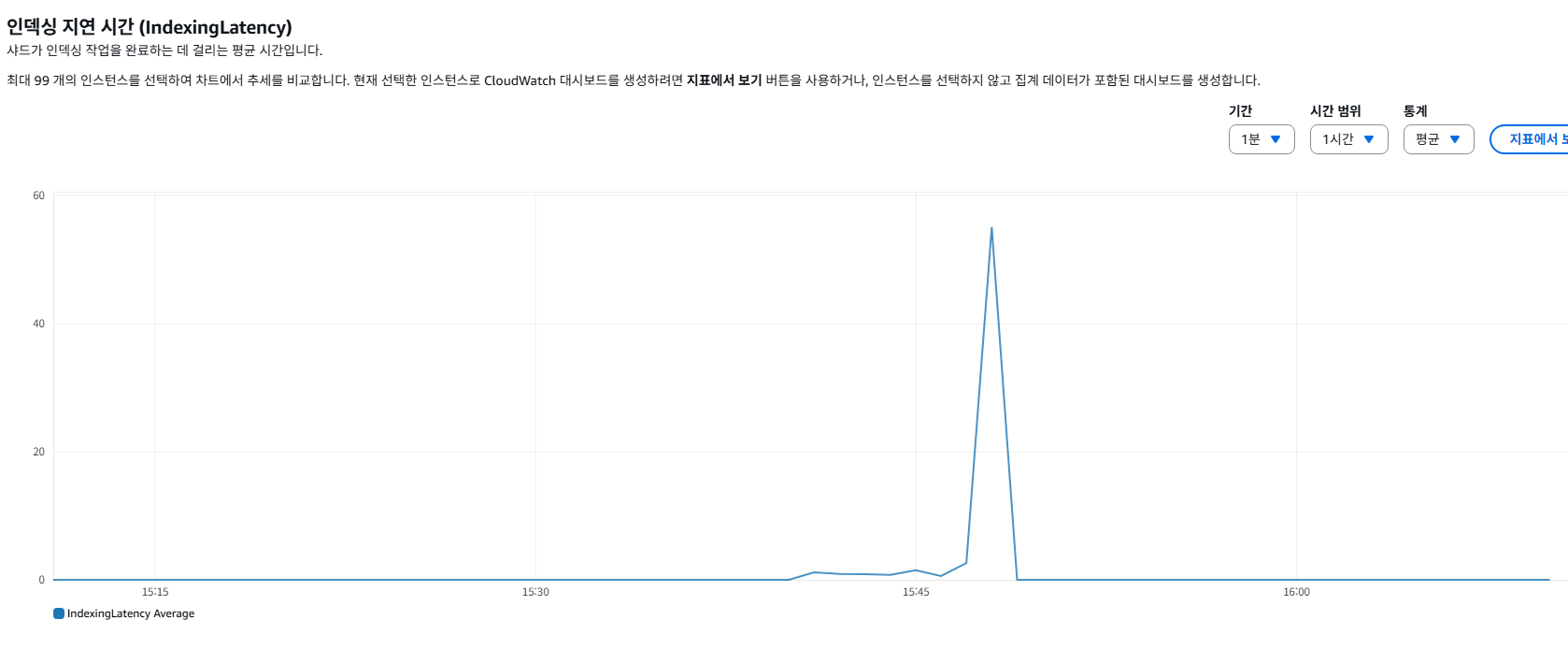
이 문제는 청크 사이즈를 줄이는식으로 해결하면 되겠다.
청크 사이즈 500 -> 250
청크 사이즈를 줄이면서 정상적으로 모든 데이터가 올라갔다.
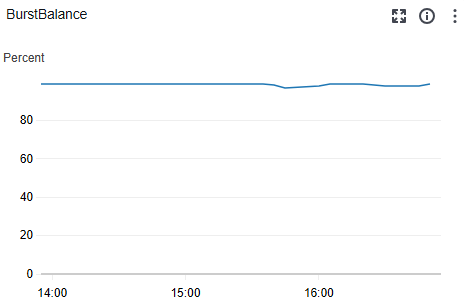
정말 단순한 id 기반의 범위 + Limit 청크사이즈 필터링이다 보니 RDS 버스트 크레딧도 크게 사용하진 않는 것으로 보인다.
약 300만개의 데이터를 넣는데 17m58s378ms 정도의 시간이 소요됐다.