[논문 리뷰]Continual Learning for Task-oriented Dialogue System with Iterative Network Pruning, Expanding and Masking

서론
선행연구
선행연구는 task-oriented dialogue system(TDS)을 다룰 때, 특정 목적을 위해 주어진 데이터셋에서 Seq2Seq 모델을 학습하는 isolation learning을 수행하였다.
isolated learning은 이전에 학습한 것을 다룰 때 forgetting 문제가 발생한다. 따라서 human-like한 dialogue system을 만들기에는 문제가 있었다. 또한, continual learning을 수행한 연구들은 성과가 좋지 않았다.
선행연구의 한계를 해결하는 방법
Network pruning, Network Expaning, Network Masking을 통하여 이전의 성능을 보존하고 이후의 학습 진행을 가속화하는 방법을 제안하였다.
반복 가지치기를 통하여 이전 작업의 성능을 보존하는 동시에 향후 작업에 대한 학습 진행을 가속화하고자 하였다. 오래된 task 가중치를 masking하기 위하여 task별 binary matrix를 제안하였다.
제안한 방법
Global-to-Local Memory Pointer Networks (GLMP) 모델을 기반으로 새로운 것을 추가하였다.
Global-to-Local Memory Pointer Networks (GLMP)
GLMP 모델의 특징은 다음과 같다.
1. External Knowledge: 각 개체 단어는 메모리 위치를 가리킬 때 직접 복사된다.
2. Global Memory Encoder: 원본 메모리 표현과 해당 암묵적 표현이 요약되어 맥락화된 표현이 대화 메모리에 기록된다. 보조 다중 레이블 분류 작업이 존재한다.
3. Local Memory Decoder: GPU가 sketch tag를 만든다. Global memory pointer가 External Knowledge로 전달되고, 검색된 개체 단어가 local memory pointer에 의해서 픽업된다. 그렇지 않으면 sketch GRU에서 출력 단어가 직접 생성된다.
Task-oriented dialogue system with iterative network pruning, expanding and masking (TPEM)
이 논문에서는 GLMP 모델에 아래의 것들을 추가하여 TPEM이라는 모델을 구축하였다.
1. Network Pruning: 이전 작업 가중치를 유지하면서 새로운 학습을 위한 가중치를 추가한다. 네트워크를 확장하는 것이 목표다. Network pruning + re-training 과정을 거친다. 이 방법을 거쳤을 때 성능 저하가 최소화되었다고 주장한다.
2. Network Expanding: 새로운 것을 학습할 때 모델 크기를 확장하는 방법이다.
3. Network Masking: 새로운 것을 잘 학습하기 위하여 이전의 것을 masking한다. 경사하강법을 사용해서 계산된다.
선행연구와 관련하여
Network pruning, Network expanding, Network masking을 추가해서 GLMP 모델을 더 효과적으로 만들 수 있었다고 주장한다. 그 결과는 아래의 실험 결과에 나와있다.
실험
GLMP와 TPEM을 비교하였다.
다음 단어를 예측하는 TDS를 task로 하였다. TDS 평가 데이터셋이 존재하지 않기 때문에 3개의 벤치마크에서 7개의 task를 가져와서 평가하였다. Score는 BLEU와 F1을 이용하였다.
결과
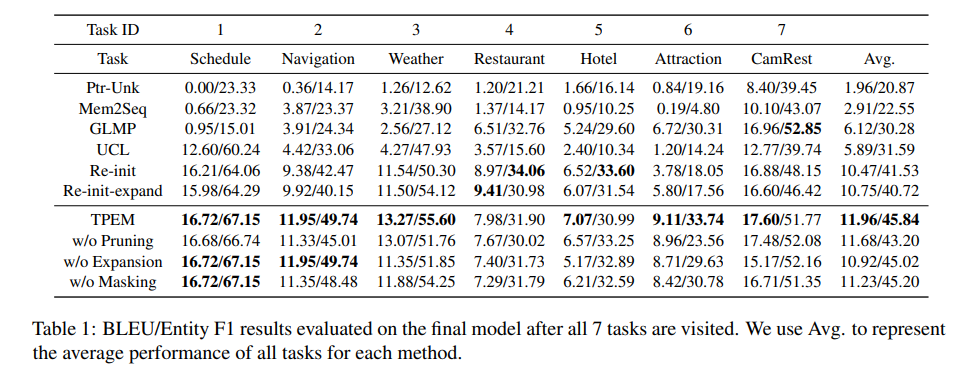
BLEU와 F1 score 모두 TPEM이 GLMP보다 훨씬 높았다. 또한 ablation experiment에서도 하나의 F1 score 빼고 모두 TPEM의 결과가 더 좋았다.
