0. 들어가며
카페 주문 플랫폼 프로젝트를 리팩토링하던 중
장바구니 조회 페이지에서 예상보다 많은 쿼리가 실행되고 있는 것을 로그를 통해 발견했다.
특히 장바구니에 음료를 하나씩 추가할수록
조회 시 실행되는 쿼리 수가 함께 증가하는 현상이 나타났다.
이러한 패턴을 보며 성능 병목이 발생할 수 있는 API라고 생각했고,
문제의 원인을 명확히 확인해보기로 했다.
이번 포스팅에서는
N+1 문제를 분석하고 개선한 과정까지 작성해보려 한다.
1. 문제 상황 및 분석
1.1 문제 상황 확인
장바구니 조회 API를 기준으로
랜덤으로 각 상품에 3개의 옵션을 선택한 뒤
상품을 하나씩 장바구니에 담아가며 API를 호출해보았다.
그 결과 상품을 하나 추가할 때마다
쿼리 로그가 상품 수가 증가함에 따라 쿼리 수 역시 함께 증가하는 것을 발견했다.
이를 통해서 연관 관계 조회 과정에서 불필요한 쿼리가 반복적으로 발생하고 있을 가능성을 의심하게 되었다.
먼저 대시보드를 통해 전반적인 흐름을 파악한 뒤,
테이블 구조를 정리하고 테스트 코드를 통해 쿼리 수를 정확히 확인해보겠다.
1.2 장바구니 도메인 구조
현재 ERD 구조
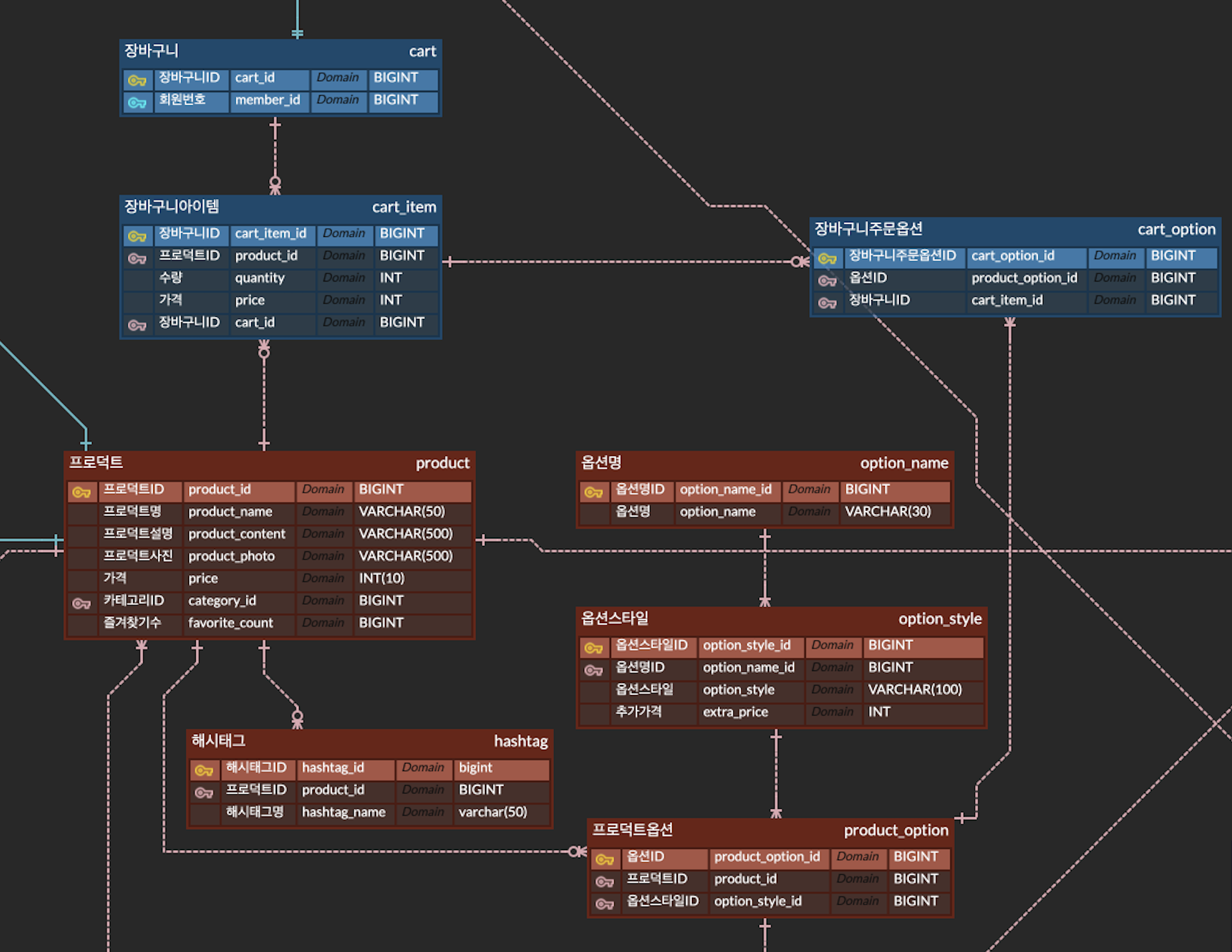
Cart
└─ CartItem
├─ Product
└─ CartOption
└─ ProductOption
└─ OptionStyle-
Cart / CartItem
- Cart는 회원당 하나의 장바구니를 가지며, CartItem은 장바구니에 담긴 상품 단위이다.
-
CartOption
- CartOption은 CartItem에 대해 사용자가 실제로 선택한 옵션을 저장하는 테이블이다.
- 하나의 상품에는 여러 옵션이 선택될 수 있으며, 이로 인해 CartItem ↔ CartOption은 1:N 관계를 가진다.
-
ProductOption / OptionStyle
- 옵션 정보는 ProductOption과 OptionStyle로 분리되어 있다.
- ProductOption : 상품에 어떤 옵션이 존재하는지
- OptionStyle : 옵션명과 추가 가격 등 실제 표시/계산에 필요한 정
이러한 구조에서는 CartItem 하나를 조회하더라도
선택된 옵션 수에 따라 연관 엔티티 조회가 반복적으로 발생할 가능성이 있다.
1.3 문제가 발생하는 Service 코드
N+1 문제가 발생하는 API의 서비스 코드를 살펴보자.
우선 멤버 아이디를 기준으로 장바구니 엔티티를 조회하면서
Fetch Join을 통해 장바구니 상품과 상품 엔티티까지 함께 조인하고 있다.

하지만 상품 조회 페이지에서는 상품 정보뿐만 아니라,
해당 상품에 대한 옵션 정보도 필요함에도 불구하고
상품 옵션 엔티티에 대해서는 Fetch Join을 사용하지 않고 있었다.
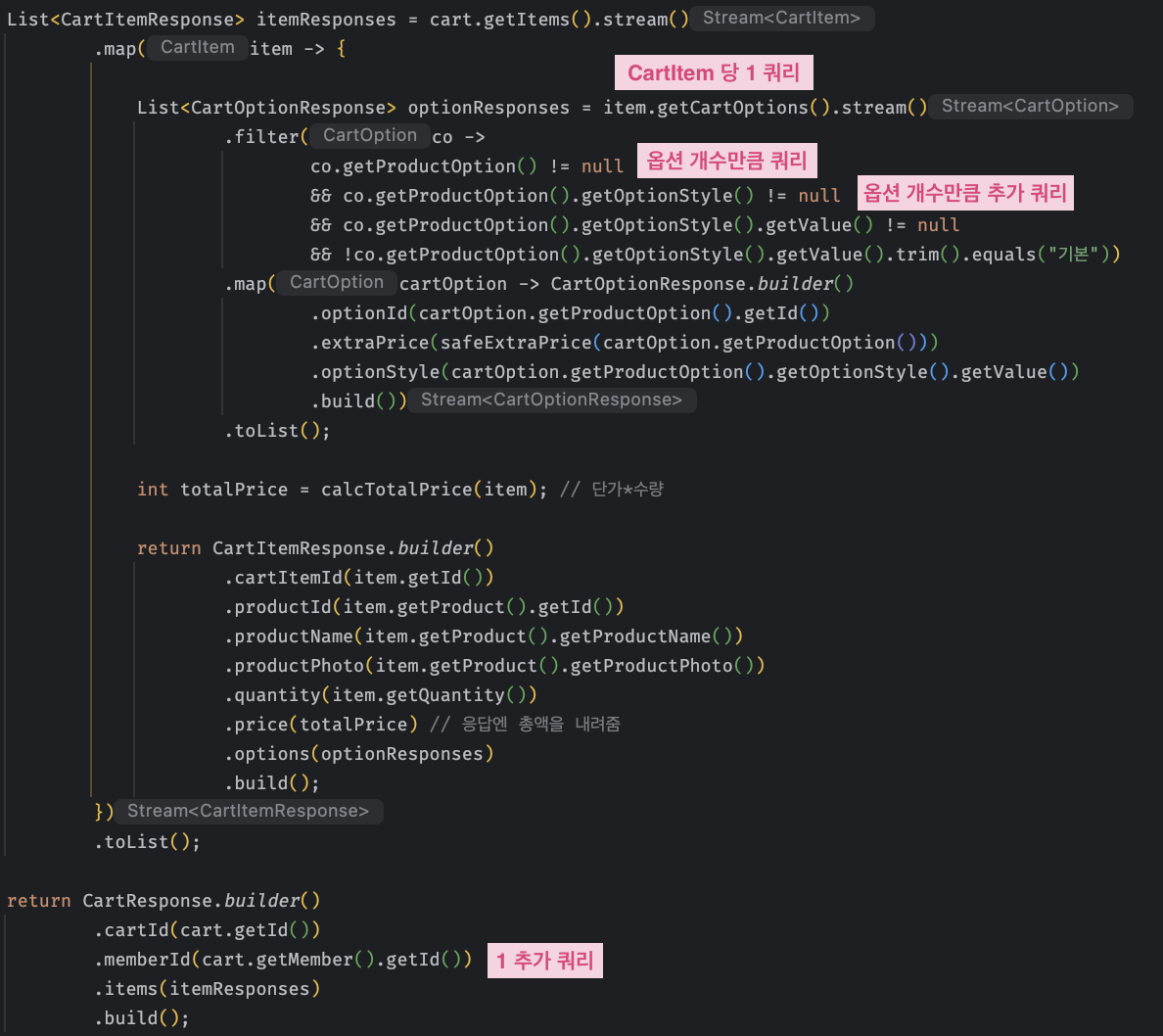
Fetch join으로 가져오지 않은 cartOption, optionStyle, member 엔티티의 데이터를 메서드를 통해 연관관계를 따라 체이닝 방식으로 접근하면서,
각 상품마다 그에 해당하는 데이터를 가져오기 위해서 추가 쿼리가 발생하고 있었다.
결과적으로 상품과 선택한 옵션 수만큼 추가 쿼리가 실행되면서 N+1 문제가 발생하고 있음을 확인할 수 있었다.
1.4 N+1 문제 탐지 결과
테스트 코드 기반으로 정확한 수치를 확인해보겠다.
테스트 환경
- 데이터베이스 : MySQL (HikariCP 커넥션 풀)
- 테스트 데이터 : 옵션 3개 이상인 상품 10개 선택, 각 상품당 3개 옵션 선택 (총 30개)
- JPA 1차 캐시 : 매 측정마다
EntityManager.clear()로 초기화하여 캐시 영향 제거
측정 방법:
- 워밍업 : 3회 실행 (JVM 최적화 및 DB 준비)
- 실제 측정 : 10회 반복 후 평균값 산출
- 수집 지표 : 쿼리 실행 횟수, 응답 시간(평균/최대/P95), 테이블별 쿼리 분포
테스트 데이터로 옵션이 3개 이상 등록된 상품 10개를 조회하여 사용하였다.
내부적으로는 실행 시간, 쿼리 수을 수집하였고
응답시간은 평균, 최대, P95 기준으로 비교하였다.
P95 기준 응답 시간은 약 475ms 정도였고,
동일 조건에서 더 다양한 옵션을 선택할 경우
option_style에 대한 쿼리 수가 증가하면서 응답 시간 또한 함께 증가할 것으로 예상된다.
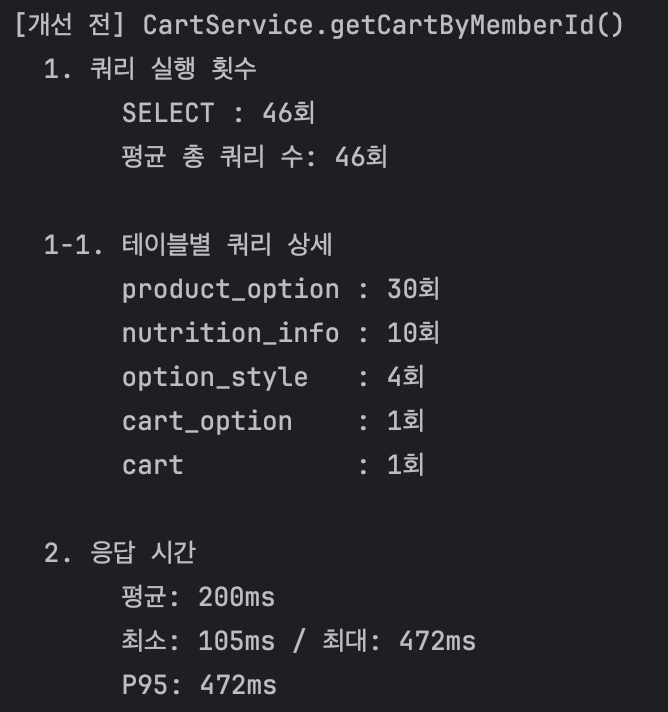
옵션 3개씩 적용된 상품 10개가 담긴 장바구니를 조회한 결과
총 46개의 쿼리가 발생한 것을 확인할 수 있었다.
- product_option : 3 × 10 = 30회
- nutrition_info : 10회
- option_style : 4회
- cart_option, cart : 각각 1회
그런데 여기서 추가로 발견한 문제점이 있다.
product와 1:1 연관관계를 맺고 있는 nutrition_info(영양 정보) 엔티티에서 10개의 추가 쿼리가 발생하고 있었다.
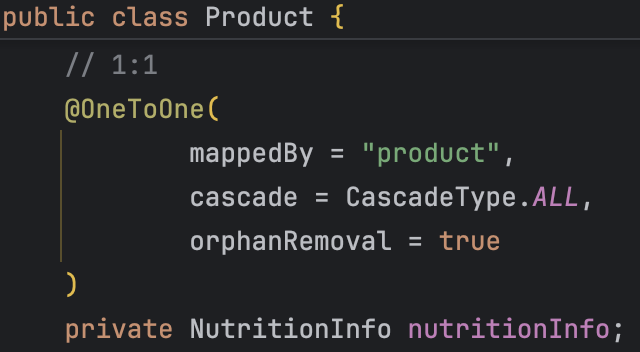
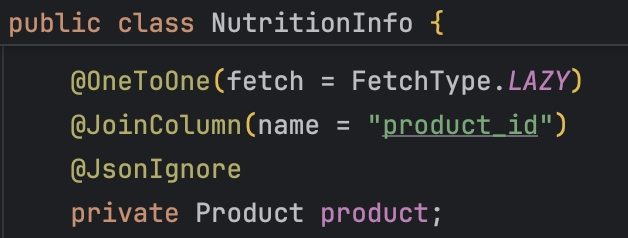
처음에는 단순한 로딩 전략 문제라고 생각했다.
하지만 원인을 찾아보니 @OneToOne 연관관계에서 FK의 위치로 인해 발생한 문제였다.
nutrition_info는 product를 참조하고 있으며,
FK는 nutrition_info 테이블에 존재한다.
장바구니 조회에서는 nutrition_info 데이터를 전혀 사용하지 않음에도 불구하고,
product 엔티티를 로딩하는 과정에서
nutrition_info에 대한 추가 조회 쿼리가 발생하고 있었다.
이는 FK가 존재하지 않는 쪽(product)에서
@OneToOne(fetch = LAZY) 연관관계를 사용할 경우 발생하는 JPA의 특성 때문이다.
JPA는 프록시를 생성하기 위해 연관 엔티티의 식별자(ID)를 알아야 하지만,
이 경우 product 엔티티만으로는 nutrition_info의 ID를 알 수 없다.
따라서 nutrition_info가 실제로 존재하는지,
혹은 null인지 판단하기 위해 즉시 조회 쿼리를 실행할 수밖에 없다.
그 결과, fetch = LAZY로 설정했음에도
실제로는 즉시 로딩처럼 동작하게 되며,
이 조회가 상품 수만큼 반복되면서 N+1 문제가 발생하게 된다.
이는 단순한 Fetch 전략 변경으로 해결할 수 있는 문제가 아니라
연관관계 매핑 설계 자체에서 발생한 문제라고 볼 수 있다.
2. N+1 문제 해결 전략
2.1 대표적인 세 가지 전략
N+1 문제를 해결하는 대표적인 세 가지 전략을 간단하게 살펴보자.
Fetch Join
패치 조인을 사용할 경우,
연관관계에 해당하는 엔티티를 하나의 쿼리로 한 번에 조회할 수 있다.
이렇게 조회된 엔티티는 이후 접근 시에도 추가 쿼리가 발생하지 않는다.
목록 조회에서 항상 함께 사용하는 연관 엔티티가 명확하고,
데이터 양이 많지 않을 때 가장 확실한 해결 방법이다.
@BatchSize
하나의 쿼리 수행 시,
IN 절을 사용해 여러 연관 엔티티를 묶어서 조회하도록 설정하는 어노테이션이다.
지정한 배치 사이즈만큼 데이터를 한 번에 가져오며,
이를 초과할 경우 다음 쿼리를 통해 동일한 방식으로 조회한다.
Fetch Join을 사용하기 어렵거나,
여러 연관 엔티티가 선택적으로 사용되는 경우에 유용하다.
@EntityGraph
조회 시 함께 가져올 연관 엔티티를 어노테이션으로 명시하여
필요한 연관 데이터만 즉시 로딩하도록 설정할 수 있다.
JPQL을 수정하지 않고,
메서드 단위로 Fetch 전략을 제어하고 싶을 때 사용한다.
2.2 나의 해결 방안
우선 하나의 쿼리로 가져오던 데이터를 두 개의 쿼리로 나눠서 가져오기로 했다.
장바구니 조회에서 실제로 필요한 데이터는 Cart가 아니라 CartItem이었고,
Cart를 기준으로 fetch join 을 해서
DISTINCT를 통해 이를 다시 하나의 Cart 엔티티로 합치는 과정이 불필요하다고 생각했다.
그래서 Cart는 식별자 조회로 분리하고,
CartItem을 루트로 필요한 연관 데이터만 fetch join 하는 두 단계 조회 방식을 선택했다.
1. 조회 방식 선택 : Fetch join vs Projection
장바구니 조회 API에서 N+1 문제를 해결하기 위해
Fetch Join과 Projection 중 어떤 방식을 사용할지 고민했다.
먼저 두 방식의 특징을 간단히 정리해보았다.
Projection
- 필요한 컬럼만 조회하므로 가져오는 데이터 양이 줄어든다.
- 엔티티를 생성하거나 영속성 컨텍스트에 등록하지 않기 때문에
엔티티 로딩 및 관리 비용이 발생하지 않는다. - 이러한 특성으로 인해 대량 조회 시 메모리 및 CPU 사용량을 줄이는 데 효과적이다.
Fetch Join
- 연관된 엔티티를 한 번의 쿼리로 함께 조회할 수 있어 N+1 문제를 방지할 수 있다.
- 엔티티를 그대로 조회하므로
연관 관계 탐색, 옵션 조합, 금액 계산 등 도메인 로직을 자연스럽게 처리할 수 있다. - 컬렉션 구조가 유지된 상태로 로딩되기 때문에
Projection처럼 결과를 다시 그룹핑하거나 가공할 필요가 없다.
두 방식을 비교해보았을 때,
장바구니 조회는 한 사용자 기준의 데이터로 규모가 크지 않고,
옵션과 같은 중첩된 연관 구조를 그대로 활용해야 하는 특성을 가지고 있었다.
이러한 구조를 Projection으로 조회할 경우
서비스 계층에서 결과를 다시 그룹핑하고 가공하는 추가 로직이 필요해져
오히려 코드 복잡도가 증가할 수 있다고 생각했다.
그리고 성능적 측면에서도 대량 데이터 조회에 효과 큰 Projection의 이점을 장바구니 조회 에선 효과가 크지 않을 것 같았다.
반면 Fetch Join을 사용하면
연관 데이터를 한 번에 조회하면서도 엔티티 구조를 그대로 활용할 수 있어
도메인 로직을 단순하게 유지하고, 유지보수성 측면에서도 유리하다고 생각했다.
따라서 이번 장바구니 조회 API에서는
Projection 이 아닌 Fetch Join 방식을 선택했다.
2. Fetch join 전략 활용
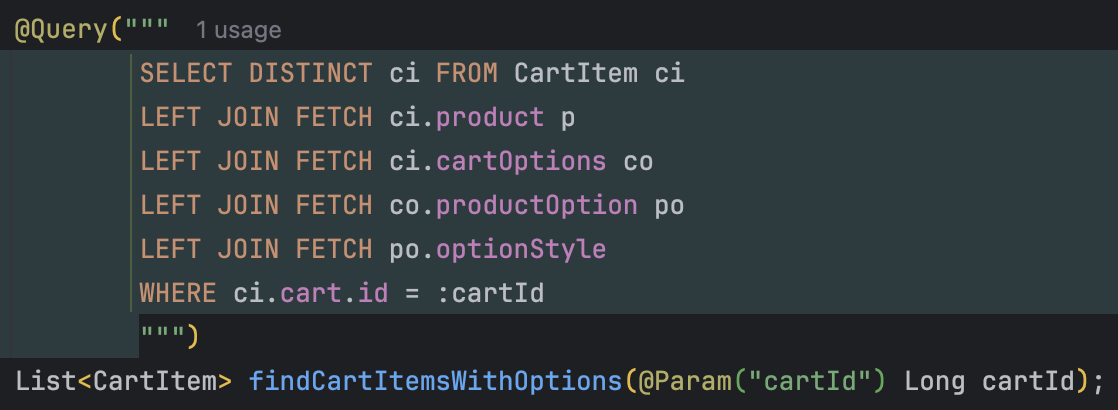
Fetch Join 을 활용하여 장바구니 조회에 필요한 연관 데이터를 한 번의 쿼리로 가져오도록 수정하였다.
장바구니 도메인에는 다음과 같은 다양한 상태가 존재한다.
- 장바구니는 존재하지만 상품이 없는 경우
- 상품은 존재하지만 옵션이 선택되지 않은 경우
- 옵션 조합이 부분적으로만 선택된 상태
이러한 특성상 INNER JOIN FETCH를 사용할 경우,
연관 데이터가 존재하지 않는 시점에서는
장바구니 또는 장바구니 아이템 자체가 조회되지 않는 문제가 발생할 수 있다고 생각했다.
그래서 연관 데이터의 존재 여부와 관계없이
장바구니 정보를 안정적으로 조회하기 위해
모든 연관 관계를 LEFT JOIN FETCH로 조회하는 방식을 선택하였다.
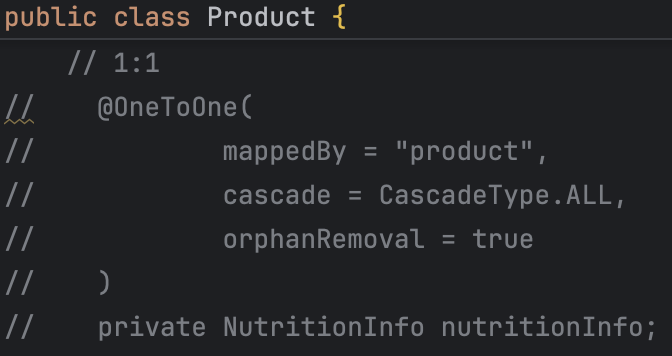
3. 비효율적인 OneToOne 연관 관계 설계 개선
두 번째로 문제였던 부분은
실제로는 필요하지 않은 nutritionInfo 데이터가 조회되고 있다는 점이었다.
일반적으로 1:1 연관관계를 양방향으로 매핑하는 경우는
해당 데이터가 여러 곳에서 사용되거나, 추후 확장 가능성을 고려하는 경우가 많다.
하지만 현재 도메인 구조를 살펴보면 영양정보(nutritionInfo)를 조회하는 API는
상품 상세 조회 API 하나뿐이었다.
이 상태를 그대로 유지할 경우
N+1 문제를 해결하기 위해 장바구니 조회 API에서는 사용하지도 않는 영양정보까지
fetch join으로 함께 조회해야 하는 상황이 발생한다.
실제로 다른 곳에서 영양정보를 조회하는 경우가 없었기 때문에
양방향 연관관계를 제거하고 단방향 구조로 수정하였다.
결과적으로
상품 상세 조회 API에서는 영양정보를 별도의 쿼리로 조회하도록 분리했고
장바구니 조회 API에서는 영양정보를 fetch join 하지 않고도
필요한 데이터만 조회할 수 있도록 구조를 개선할 수 있었다.
3. 개선 결과
개선한 장바구니 조회 API(/users/cart)를 기준으로,
개선 전과 동일한 조건으로 상품을 장바구니에 담아 API를 호출해보았다.
그 결과,
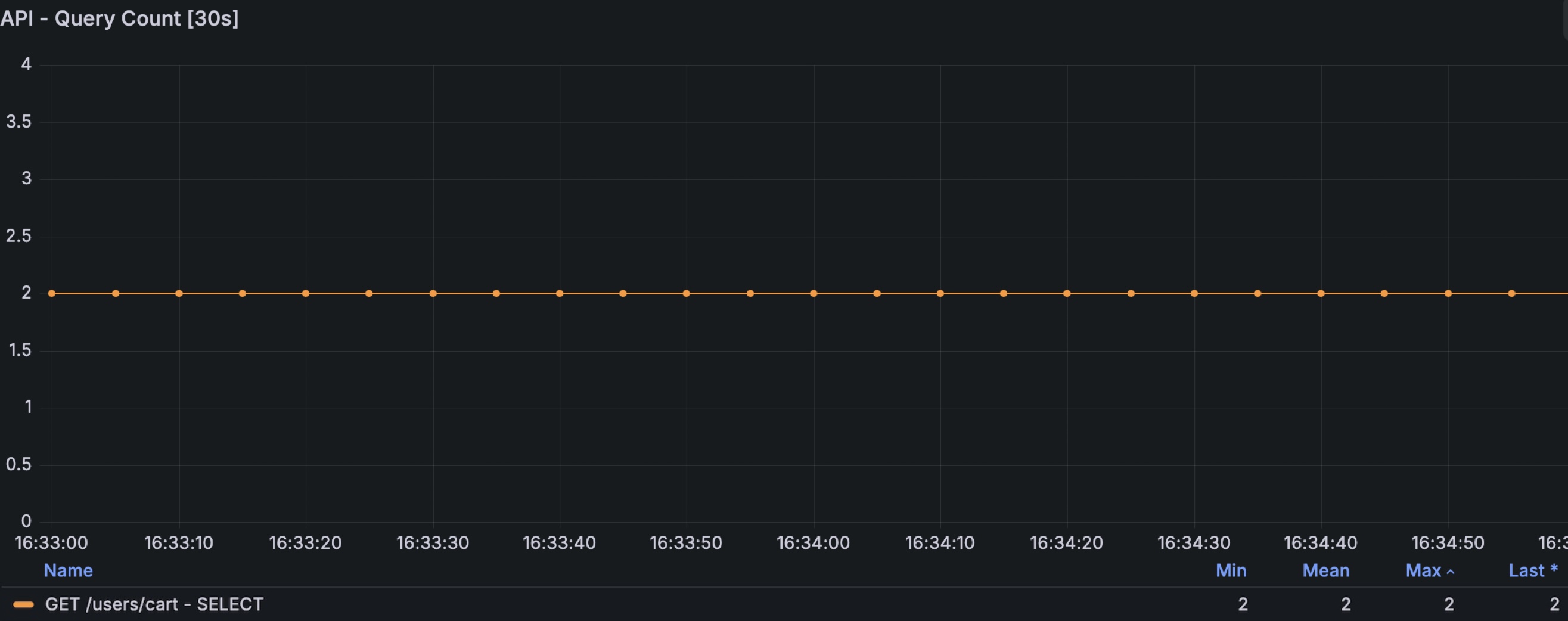
상품 개수와 상관없이 총 2개의 쿼리만 수행되는 것을 확인할 수 있었다.
Hibernate:
select
c1_0.cart_id
from
cart c1_0
where
c1_0.member_id=?
Hibernate:
select
distinct ci1_0.cart_item_id,
ci1_0.cart_id,
co1_0.cart_item_id,
co1_0.cart_option_id,
co1_0.product_option_id,
po1_0.product_option_id,
os1_0.option_style_id,
os1_0.extra_price,
os1_0.option_name_id,
os1_0.option_style,
po1_0.product_id,
ci1_0.price,
ci1_0.product_id,
p1_0.product_id,
p1_0.category_id,
p1_0.favorite_count,
p1_0.price,
p1_0.product_content,
p1_0.product_name,
p1_0.product_photo,
p1_0.version,
ci1_0.quantity
from
cart_item ci1_0
left join
product p1_0
on p1_0.product_id=ci1_0.product_id
left join
cart_option co1_0
on ci1_0.cart_item_id=co1_0.cart_item_id
left join
product_option po1_0
on po1_0.product_option_id=co1_0.product_option_id
left join
option_style os1_0
on os1_0.option_style_id=po1_0.option_style_id
where
ci1_0.cart_id=?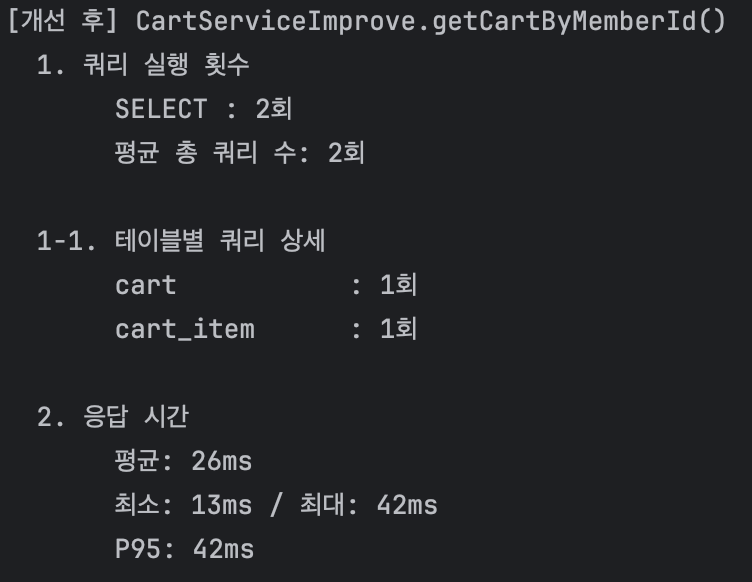
테스트 코드로 확인한 결과 역시 동일했다.
기존에는 상품 수에 따라 쿼리가 증가하던 구조였으나,
개선 이후에는 cart 조회 1회, cart_item 조회 1회로
항상 총 2개의 쿼리만 실행되도록 개선되었다.
또한 성능 측면에서도 눈에 띄는 개선이 있었다.
P95 기준 응답 시간은 472ms → 42ms로 감소했다.
개선 전 후 비교표
| 지표 | 개선 전 (N+1 발생) | 개선 후 (Fetch Join) | 개선율 |
|---|---|---|---|
| 총 쿼리 실행 횟수 | 46회 | 2회 | 95.6% ↓ |
| 평균 응답 시간 | 200ms | 26ms | 87.0% ↓ |
| P95 응답 시간 | 472ms | 42ms | 91.1% ↓ |
4. 배운점
모니터링만으로는 모든 문제를 발견할 수 없다
Grafana 대시보드를 통해
요청 수가 늘어날수록 쿼리 수가 함께 증가하는 현상은 확인할 수 있었지만,
어떤 연관 관계에서, 어떤 코드 지점에서 쿼리가 발생하는지까지는
모니터링만으로 파악하기 어려웠다.
결국 실제 서비스 코드와 쿼리 로그,
테스트 코드를 함께 보면서 문제를 추적해야
N+1이 발생하는 정확한 원인을 이해할 수 있었다.
N+1 문제는 단순한 로딩 전략 문제가 아닐 수 있다
처음에는 fetch = LAZY / EAGER 설정만의 문제라고 생각했는데 분석해보니,
연관 관계를 어떻게 설계했는지
특히 @OneToOne 관계에서 FK의 위치와 양방향 매핑 여부에 따라서도
의도하지 않은 쿼리가 발생할 수 있다는 것을 알게 되었다.
즉, N+1 문제는
단순히 fetch 전략을 바꾸는 것으로 해결되지 않고,
엔티티 매핑 설계 자체를 다시 고민해야 하는 문제일 수도 있었다.
N+1 문제는 다양한 원인과 상황에서 발생하고
Fetch Join, @BatchSize, @EntityGraph 등 여러 해결 전략이 존재한다.
각 전략의 특성을 이해하고 상황에 맞게 선택하는 것이 중요함을 배웠다.
