0. 학습목표
- EDA에 대하여 이해한다.
- Feature Engineering의 목적을 이해할 수 있다.
- Business Insight를 도출할 수 있다.
- 통계 및 시각화 기법을 활용할 수 있다.
1. 주요개념
1. EDA
EDA는 exploratory Data Analysis의 약어로 탐색적 데이터 분석을 의미한다. 데이터를 다양한 각도에서 관찰하고 이해하는 모든 과정을 말한다. 데이터 분석에 있어 매우 중요한 초기 분석단계이며, 데이터를 분석하고 결과를 내는 과정에 있어 지속적으로 해당 데이터에 대한 “탐색과 이해”를 기본으로 가져아 한다.
1.1 EDA를 위한 데이터 수집 및 정제과정
데이터 수집 -> 데이터 전처리 -> 순수 데이터 -> EDA(탐색적 데이터 분석)
1.2 EDA의 이점
- 데이터의 잠재적인 문제 발견
- 데이터의 다양한 패턴 발견
- 자료수집을 위한 기반(추가 자료수집 포함)
- 적절한 통계 도구 제시
데이터에 대한 이해와 탐색이 바탕이 되어야 문제를 발견 및 해결은 물론, 데이터 분석 과정에서 필요한 통계도구, 자료수집 등을 결정하는데 도움을 준다.
1.3 EDA의 대상
1. Univariate(일변량): EDA를 통해 파악하려는 변수 1개
-> 데이터를 설명하고 패턴을 찾는 것이 목적
-> 독립변수에 하나의 종속변수가 있는 것
-> 일변량 분석은 어떤 대상의 성격을 규명하기 위하여 한가지 측면에서 그 대상을 관찰하고 분석하는 것에 유용
2. Multi-variate(다변량): EDA를 통해 파악하려는 변수 여러개
-> 변수들간의 관계를 보는 것이 목적
-> 여러 개의 독립변수에 여러 개의 종속변수를 동시에 분석하는 것
-> 여러 각도와 측면에서 변수들의 관계를 분석하는 것에 유용하다.
1.4 EDA의 종류
1. Graphic(시각화): 차트, 그림 등을 이용하여 데이터를 확인하는 방법
-> 데이터를 한눈에 파악하여 대략적인 형태 파악 가능
2. Non-Graphic(비시각화): 그래픽적인 요소를 사용하지 않고, 주로 Summary statistics으로 데이터 확인
-> 정확한 값을 파악하기 좋다.
-> 시각화 없이도 대략적인 데이터의 분포를 유추하고 정확한 값을 파악하기 좋다.
summary statistics: 요약 통계량으로 평균,중앙값, 최대/최소값, 사분위수 등이 있다.
1.5EDA의 유형
EDA의 대상과 종류의 조합으로 총 4가지가 나온다.
- Uni-Non Graphic(일변량 비시각화)
- Uni-Graphic(일변량 시각화)
- Multi-Non Graphic(다변량 비시각화)
- Multi-Graphic(다변량 시각화)
1.6 EDA의 단계
전체적인 데이터 분석 -> 데이터의 개별 속성값 관찰 -> 속성 간의 관계분석
1. 전체적인 데이터 분석
- 분석의 목적과 목적에 맞는 변수가 무엇인가
- 데이터형 확인/ 데이터의 오류나 누락이 없는지
- 데이터를 구성하는 각 속성값이 예측한 범위와 분포를 갖는지 -> 아니라면 그 이유 확인
2. 데이터의 개별 속성값 관찰
- 개별 데이터를 관찰하며 전체적인 추세와 특이사항 관찰
- 적절한 요약통계 지표사용 (평균, 중앙값, 분산 등)
- 시각화를. 통해 데이터의 개별 속성에 어떤 통계 지표가 적절한지 결정
3. 속성 간의 관계분석
- 개별 속성 관찰에서 찾아내지 못했던 속성들의 조합, 패턴 발견
- 그래프를 통해 시각화하여 속성간의 관계 분석
- 상관계수를 통한 상관관계 확인
❗ 정리: EDA는 데이터의 전체적인 부분을 파악하고 개별 속성값을 관찰한 후, 마지막으로 속성 간의 관계를 분석해보며 데이터를 탐색적으로 분석해보는 과정을 말한다.
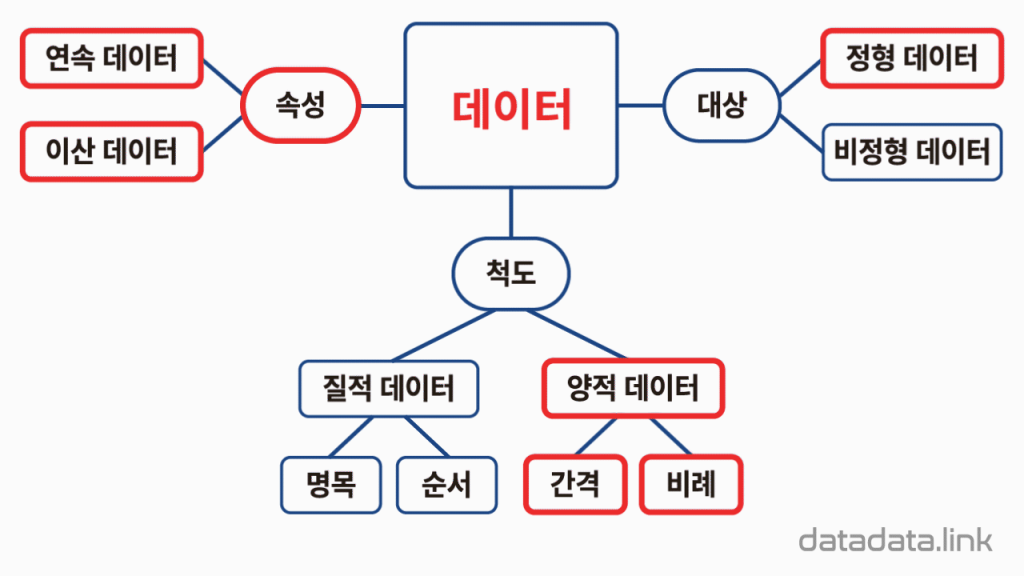
2. Type of data
 [참고 사이트] https://www.datadata.link/qa36/
[참고 사이트] https://www.datadata.link/qa36/
1. 형식에 따른 구분
1. Structured data(정형 데이터)
미리 정의된 형식이 있는 데이터를 의미한다. 따라서 정형데이터는 스프레드시트(구글 시트,엑셀)에서 형식을 지정하여 사용할 수 있다.
2. unstructured data(비정형 데이터)
미리 정의된 형식이 없는 데이터를 말한다. 비정형 데이터는 일반적으로 텍스트 중심으로 되어 있으나 "날짜에 따른 사건일지"와 같이 숫자 데이터도 포함될 수 있다.
2. 척도에 의한 분류
1. 질적데이터
등급, 순서와 같은 데이터이다. 하지만 남녀를 1과2로 표현하여 질적 데이터로 사용할 수도 있다. 질적 데이터는 다시 명목과 순서로 나뉘어진다.
- 명목 척도: 남자, 여자와 같은 질적 정의를
남자=1,여자=2처럼 수치화 시킨 것 - 순서척도: "일인당 국민수득이 높은 나라 순위"처럼 순서를 수치화 한 것.
2. 양적 데이터
- 간격 척도:
온도와시각처럼 간격을 수치화한 것 - 비례 척도:
비만도처럼 기준에 대한 비례를 수치로 표현한 것
3. 속성에 의한 분류
1. Continuous data(연속형 데이터)
키, 몸무게, 시간, 혈압, 경제성장률과 같이 연속적인 수치로 표현된 데이터이다. 연속형데이터는 아날로그라고 할 수 있다. 유한개의 숫자로는 표현이 안되고 무한한 숫자로 표현해야 하는 데이터를 의미한다.
- interval(구간 데이터): 관측 대상이 지닌 속성의 차이를 양적인 차이로 측정하기 위하여 척도간 간격을 균일하게 분할하여 측정하는 척도이다. 절대적 원점이 존재하지 않는다.
ex) 온도, 시간 - ratio(비율 데이터): 서열성, 등간성, 비율성의 세 속성을 모두 가진 척도를 말한다. 절대적 원점이 존재한다.
ex) 무게, 거리
2. Categorical data(범주형 데이터)
나이, 시험점수 등과 같이 명확한 자리수를 가지는 수치로 표현된 데이터이다. 범주형 데이터는 디지털이라고 할 수 있다. 즉 유한한 숫자로 표현할 수 있다. 여기서 범주형데이터는 다시 두 분류로 나눌 수 있다.
- ordinal: 범주 간 순서에 의미가 있다.(선호도, 등급)
- nominal: 범주 간 순서에 의미가 없다.(MBTI, 성별)
2. 명령어
1. .Groupby()
.groupby()를 이용하면 데이터를 그룹으로 묶어, 그룹별 통계연산과 집계, 요약을 빠르게 할 수 있다.
example.groupby('age').mean()위 Code를 실행하면 example dataframe의 age column에 따른 평균을 알 수 있다.
example.groupby('age')['pclass'].mean()위 Code의 경우는 age에 따른 pclass의 평균을 확인할 수 있다. 즉, 같은 나이로 묶은 후 그 나이에 따른 "pclass"의 평균을 구할 수 있는 것이다.
이때 주의할 점은 위 실행결과는 Series형태로 반환된다는 것이다. 만일 dataframe형식으로 결과를 출력하고 싶으면 다음과 같은 두가지 방법을 통하여 dataframe형식으로 출력을 할 수 있다.
example.groupby('age')['pclass'].mean().reset_index()
example.groupby('age',as_index = False)['pclass'].mean()as_index를 False로 하게되면 기존의 index열을 버리게 된다.
2. .cut
Continuous data를 Category data로 변경할 때 사용하는 pandas의 function이다.
pandas.cut(x =example['특정 열 이름'], bins = "구간을 나눌 때 기준 값들", labels = "각 구간의 이름")보통 위와 같은 형식으로 사용한다.bins파라미터는 .describe()를 통하여 확인한 4분위수와 최대/최소 값을 활용할 수도 있다. 아니면 다른 기준을 통하여 구현할 수도 있다.
3. .plot(kind = '형식')
"형식"에 입력된 값에 따라 그래프를 출력한다.
- 미입력: 일반적인 꺾은선 그래프를 출력
- bar: 일반적인 막대그래프 출력
- barh: 수평방향으로 누운 막대그래프 출력
example_data = example.groupby(['quality','color'])['sugar'].mean()
example_data.plot(kind = "bar")위 Code를 실행하면 exmaple이라는 dataframe안에서 qulity와 color에 따른 sugar의 평균값을 bar그래프 형태로 출력한다. 이때 quality와 color는 x축, sugar의 평균이 y축의 값이 된다.
그래프 관련 참고 사이트
https://benn.tistory.com/36
https://wikidocs.net/92112
4. .scatter()
보통 Continuous data의 상관관계를 나타낼 때 사용되는 산점도를 출력해주는 명령어이다.
#import matplotlib.pyplot as plt
plt.scatter(example['weight'],example['speed']);위 Code를 실행하면 x축은 weight, y축은 speed인 산점도가 출력된다.
5. .query()
dataframe에서 원하는 rows를 선택하기 위해 사용하는 방법에는 두가지가 있다.
- index를 사용.
.query()함수를 사용.
두 방법은 같은 결과를 도출하지만, 아래와 같이 사용법이 다른다.
malignant_cancer = df[df['diagnosis'] == 'Maligant']
malignant_cancer = df.query('diagnosis' == 'Maligant')즉, query()는 괄화안에 들어오는 조건에 부합하는 row만 골라서 새로운 dataframe을 생성한다.
❗ example
light_body = df.query("alchol <= 12.5") medium_body = df.query("(alchol>12.5) and (alchol <13.5)") full_body = df.query("alchol >= 13.5")이 경우 df라는 데이터에서
alchol을 기준으로 만족하는 부분만 모아서 dataframe을 만든다.
회고
무엇을 알고 무엇을 모르는지 아직 잘 구분이 안되는 것 같다. 어떻게 공부해야 잘 공부하는 건지도 모르겠다. 과제는 열심히 풀고 있는데 이거면 충분한건지 살짝 의구심이 든다.
