0. 학습목표
- 체계적인 Data Wrangling의 과정을 설명할 수 있다.
- 데이터를 탐색해 데이터에 있는 다양한 이슈를 찾아낼 수 있다.
- 코드를 이용해 데이터를 정제할 수 있다.
1. 주요개념
1. Data Wrangling
Data wrangling은다양한 데이터 소스의 데이터를 통합하고 쉽게 액세스하고 분석할 수 있도록 정리하는 과정을 의미한다.
오늘날 수집되는 데이터의 양은 빠르게 증가하고 있다. 따라서 그에 따른 데이터 준비를 위한 작업절차를 단순화하는 것을 궁극적인 목표로 데이터를 처리하고 구성하는 프로세스를 구현해야 한다.
1. Data wrangling
데이터 랭글링은 총 5단계로 구분된다.
- Gather -> 2. Assess -> 3. Clean -> 4. Reassess and Iterate -> 5. Sort(optional)
1. Gather
데이터를 수집하는 과정이다. 데이터를 얻는 방법으로는 다운로드, 웹 스크레핑, API가 있다.
2. Assess
얻은 데이터를 읽어보며 탐색하는 과정이다. 데이터가 깨긋한지 아닌지 판단하는 단계이다.
3. Clean
데이터를 정제하는 방법으로는 Define, Code, Test가 있다. 2단계(Asssess)에서 발견된 데이터의 문제점을 보고 어떤 부분을 정제할지 정의하고(Define),정제하기 위한 코드를 작성하며(Code), 잘 정제가 되었는지 테스트(Test)해보는 것이다.
4. Reassess and Iterate
다시 2단계로 돌아가 데이터 정제가 잘 되었는지 판단한다. 추가로 정제 할 부분이 있다면 다시 2~4단계를 반복한다.
5. Store(optional)
나중에 다시 사용하기 위하여 수정된 데이터를 저장하는 단계이다.
2. 장점
1. 모든 데이터 소스에 접근 및 연결
구조적이던 비구조적이던 데이터를 매쉬업하고 일치시킴으로써 보다 명확하고 완전한 데이터프레임을 확보하고 통찰력을 얻을 수 있다. 현재 나온 최고의 데이터 랭글링 솔루션을 이용하면 다양한 소스의 모든 데이터를 연결할 수 있다.
2. 데이터 분석에 더 많은 시간을 투자할 수 있다.
데이터를 구성하는데 많은 시간을 소비하는 대신에 랭글링 솔루션을 통하여 시간과 비용을 절약할 수 있다.
3. 신뢰할 수 있는 데이터를 얻을 수 있다.
데이터 랭글링을 통해 정리된 데이터는 기존 데이터와 비교하여 신뢰성을 확보할 수 있다.
4. 쉬운 엑세스 및 협업
데이터를 단순화함으로써 조직 내에서 더 많은 청중에게 더 쉽게 이해할 수 있게 할 수 있다.
2. Data의 문제
1. 문제 탐색 방법
1. 시각적 탐색
text editor, Google sheet와 같이 프로그램을 활용하여 데이터 셋을 시각적으로관찰하는 탐색 기법을 의미한다. colab에서 데이터프레임을 직접 출력하여 살펴보는 것 또한 시각적 탐색 방법이라 할 수 있다.
2. 프로그래매틱 탐색
info(), describe()와 같은 functions와 methods를 이용하여 데이터를 확인하는 탐색 기법이다. Pandas에서 빈번하게 사용되는 methods는 다음과 같다.
❗ 자주 사용되는 methods:
.head(),.tail(),.sample(),.info(),.describe(),value_counts()->단, series only,.loc(), .iloc()
2. 품질의 문제
데이터에서 Content issue가 발생하는 경우로 중복(duplicate), 결측(Missing), 부정확한 데이터(inaccurate) 등의 content issue가 발생하였을 때의 문제이다.
3. 구조의 문제
데이터의 Structual issuse가 발생하는 경우 구조의 문제라 한다. 다음과 같은 3가지 요소를 갖추지 않을 경우, 구조적 문제가 발생했다고 판단한다.
- 각 변수(variable)는 하나의 열(column)을 구성한다.
- 각 관측치(observation)는 하나의 행(row)을 구성한다.
- 각 유형의 관측 단위가 표를 구성한다.
데이터의 구조적 문제가 해결되지 않으면 차우에 분석, 시각화, 모델링을 진행할 때 속도가 느려질 수 있으므로 주의해야 한다.
구조적 문제가 발생하지 않은 Data를 Tiny data라고 하고, 구조적 문제가 발생한 data를 untidy data라고 한다.
3. 결측치 처리
결측치(missing value)란 데이터상에서 표기되지 않은 값을 말한다. 주로 NA(Not available), NAN(Not a number) 등이 있다.
1. 결측치의 종류
1. 완전 무작위 결측(MCAR, Missing Completely At Random)
한 변수에서 발생한 결측치가 다른 변수들과 아무런 상관이 없는 경우에 해당하는 결측치입니다.
깜빡 잊고 입력이 안 된 데이터, 전산 오류로 인한 누락 데이터등이 여기에 해당합니다.
2. 무작위 결측(MAR, Missing At Random)
누락된 데이터가 특정 변수와 관련이 있지만, 그 변수의 결과는 관계가 없는 경우에 해당하는 결측치입니다.
3. 비 무작위 결측(MNAR, Missing At Not Random)
1,2 번 이외의 경우에 해당하며 결측치의 값이 다른 변수와 연관이 있는 경우를 말합니다.
2. 결측치 처리 방법
1. Deletion(제거)
보통 결측치가 해당 데이터의 50%가 넘어가거나, 직접 다룰 수 없을 만큼 많은 결측치가 존재하거나, 반드시 필요한 데이터가 아니라면 해당 변수를 제거하는 것이 추천된다. 목록 삭제와 단일값 삭제 방식으로 나룰 수 있다.
2. imputation(대치)
크게 두가지로 분류할 수 있다.
1. Single imputation
1. 평균값 대체(Mean Imputation)
결측치가 존재하는 변수에서 결측되지 않은 나머지 값들의 평균을 내어 결측치를 대체하는 방법입니다. 이 방법을 사용하면 평균 값이 변하지 않는다는 장점이 존재합니다.
2. 새로운 값으로 대체(Substitution)
해당 데이터 대신에 샘플링되지 않은 다른 데이터에서 값을 가져옵니다.
3. Hot deck imputation
다른 변수에서 비슷한 값을 갖는 데이터 중에서 하나를 랜덤 샘플링하여 그 값을 가져오는 방법입니다. 결측 값이 존재하는 변수가 가질 수 있는 값의 범위가 정해져 있을 때 장점을 갖습니다. 또한 값을 랜덤하게 가져오기 때문에 어느 정도 변동성을 더해줘 표준 오차의 정확도에 어느정도 기여합니다.
4. Cold deck imputation
Hot deck imputation과 비슷하지만 랜덤 샘플링을 하는 것이 아니라 어떠한 규칙에 의해 하나를 선정하는 것입니다.
5. Regression imputation
결측치가 없는 변수를 feature로 사용하여 결측치가 있는 변수를 regression task를 진행하는 것입니다. 즉, 데이터 내의 다른 변수들을 기반으로 결측치를 예측하는 것입니다.
6. Stochastic regression imputation
앞서 설명한 regression 방식에 random residual 값을 더해서 결측치를 예측한 방식입니다.
7. 보간법, 보외법(Interpolation, extrapolation)
같은 대상으로부터 얻은 다른 관측치로부터 결측치 부분을 추정하는 것입니다.
2. Multiple Imputation
single imputation을 거친 여러 개의 데이터 셋을 만들어 평가합니다.
1. 합리적 접근법
결측 값을 채우거나 재생하고자 하는 변수들 간의 관계를 이용합니다.
2. 완전 제거법
결측치가 있는 행 자체를 지워버리는 방법입니다.
3.다중 대체법
가장 어려운 방법 중 하나로 하나의 관측치에 2개 이상의 결측치가 존재할 때 사용하는 방법입니다. 결측값에 대한 반복 시뮬레이션 기반 접근법입니다.
3. prediction model(예측 모델)
4. Category와 Object의 차이(in Pandas)
1. Object
Pandas에서는 문자열을 object라는 자료형으로 나타내고, Python에서는 문자열을 string이라고 한다.
2. Category
가능한 값들이 고정적이고 한정적일 때 사용하며, 메모리 최적화에 이점이 있다.
3. 둘의 차이
일반적인 문자열을 갖는 칼럼은 object로 사용하고, 값의 종류가 고정적이고 제한적일 때 category를 사용할 수 있다.
예를 들어, 아침식사 여부에 대한 칼럼이라면 값을 ‘0=먹지 않음’, ‘1=먹음’으로 두 종류만 갖는다. 반대로 아침식사 종류에 대한 칼럼이라면 샐러드, 소고기, 생선, 바나나, 샌드위치, 된장찌개 등 다양한 값을 가질 수 있다. 이 경우 아침식사 여부는 category, 아침식사 종류는 object로 지정해주면 효율적으로 데이터 프레임을 관리할 수 있다.
데이터 형식에 따라 가질 수 있는 값의 범위가 다르고, 메모리 사용공간에도 차이가 있다. 불필요한 메모리 사용량을 줄이기 위해 데이터를 잘 파악하고 알맞은 형식을 지정해주는 습관을 들이면 좋을 것 같다.
5. 정규표현식
특정한 규칙을 가진 문자열의 집합을 표현하는 데 사용하는 형식 언어이다. 입력 문자열의 처리와 범용성, 생산성의 증대 등과 같은 장점이 있지만, 반대로 배우고 익히는 것이 어렵고, 코드가 난해해질 수 있다. 또한 유용하지만 만능은 아닌 단점이 존재한다.
2. 명령어
1. .set_option()
시각적 탐색을 위해 모든 행과 열을 생략하지 않고 보고 싶을 때 사용하는 명령어로 보통 다음과 같은 형식으로 사용한다.
pd.set_option('display.max_columns',None)
pd.set_option('display.max_row',None)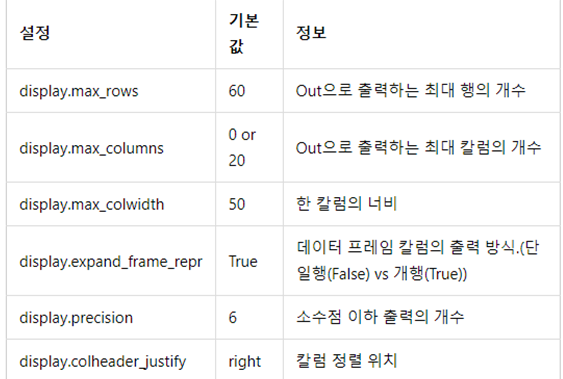
이때 ''안에 들어가는 주요 옵션은 위의 사진과 같다.
2. .sample()
Dataframe이나 Series에서 무작위로 몇개의 값(레이블)을 출력하는 메서드이다.
example.sample(n=None,frac=None,replace=False,weights=None,random_state=None,axis=None,ignore_index=False)n: 추출할 갯수 입니다. replace가 False면 n의 최댓값은 레이블의 갯수를 넘을수 없습니다.
frac: 추출할 비율입니다. 1보다 작은값으로 설정하며(예 : 0.3 이면 30%), n과 동시에 사용할 수 없습니다.
replace:중복추출의 허용 여부 입니다. True로 하면 중복추출이 가능하며 n의 최댓값이 레이블의 갯수보다 커도 됩니다.
weight: 가중치입니다. 즉 레이블마다 추출될 확률을 지정할 수 있습니다. 합계가 1(100%)이 아닐경우 자동으로 1로 연산합니다.
random_state: 랜덤 추출한 값에 시드를 설정할 수 있습니다. 원하는 값을 설정하면, 항상 같은 결과를 출력합니다.
axis: {0 : index / 1 : columns} 추출할 레이블입니다.
ignore_index: index의 무시 여부입니다. True일경우 출력시 index를 무시하고 숫자로 출력합니다.
3. .sort_value()
값을 기준으로 정렬하는 메소드이다.
example.example_col.sort_values()
example.sort_values(by = example_col, ascending = False)위와 같은 방식으로 사용할 수 있으며 ascending을 False로 설정할 경우 내림차순으로 값을 출력한다. 기본적으로는 오름차순으로 정렬한다.
3. 추가 공부 내용
dataframe에서 특정 columns전체에 한 번에 문자열을 추가할 수 있다.
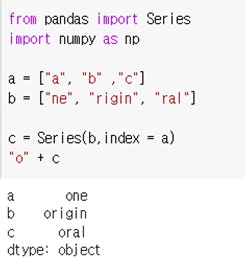
이 방법을 사용하면 for문을 사용하지 않고 한 번에 추가할 수 있을 거 같다.
- 속성(attribute)과 메서드(method)의 차이
클래스는 여러 함수와 변수들을 한 번에 묶어서 관리하기 위해 사용한다고 했다.이때 클래스에 포함되는변수를속성(attribute)이라고 부르며, 클래스에 포함되는함수를메소드(method)라고 부른다.
회고
과제는 빠르고 큰 어려움 없이 풀 수 있었다. 시작하기 전에 한권 때버린 python책이 한 몫하는 거 같다. 근데 아직 Code들이 다 익숙하지 않아서 맘대로 가져다가 못쓰는게 아쉽다. 많이 다루어보는게 정답일 거 같다. 그리고 Pandas스터디를 시작했다. 오늘부터 이번주 일요일까지 한권 독파하는게 목표인데 가능할지 의문이다.
