0. 학습목표
- 체계적인 Data Wrangling의 과정을 설명할 수 있다.
- 데이터를 탐색해 데이터에 있는 다양한 이슈를 찾아낼 수 있다.
- 코드를 이용해 데이터를 정제할 수 있다.
1. 주요개념
1. Data cleaning(데이터 정제)
데이터를 분석하기 용이하도록 정제하는 것을 의미한다. 정제과정은 다음과 같은 3단계를 걸쳐 진행된다.
- 데이터의 문제점을 보고 어떻게, 어떤 부분을 정제할지 정의한다. (define)
- 데이터 정제를 위한 Code를 작성한다. (Code)
- 잘 정제가 되었는지 Test한다. (Test)
만약, 데이터 정제 과정이 중복적으로 이뤄저야 한다면, 절대 하나하나씩 일일이 수정해서는 안된다. 데이터 정제는 ,Code를 이용하여 자동적으로 진행되어야 한다.
또한, 많은 정제 과젖을 거치더라도, 추후에 original data를 확인하기 위하여 Code 작성시에는 Copy()를 시행하여 원본을 변수에 저장해두어야 한다.
2. 명령어
1. re.search()
re모듈의 함수로 정규표현식을 사용하여 문자열 전체에 정규표현식과 일치하는 데이터를 찾아낸다.
example_search = re.search('[_,!.\d+]',example)위 코드를 실행하면 example의 전체 데이터 중 정규표현식과 일치하는 데이터를 변수에 저장한다.
search()는 match()와 유사하지만 match()는 문자열의 처음부터 시작해서 패턴이 일치하는지 확인한다는 차이가 있다.
2. .str.replce
.str.replace를 알기 위해서는 우선 .replace를 알아여 한다. .replace는 문자열 치환에 사용되는 명령어이다. 문자열 일부만 치환하고 싶은 경우는 regex = True를 설정해 정규 표현식으로 문자열 치환을 원하는 부분만 할 수 있다.
이때 만일 특정 Column만 문자열을 치환하고 싶은 경우에 문자열 메서드인 .str.replace()를 사용한다.
❗ 참고 사이트:
1. StackOverflow
2. Pandas official .str.replace
3. .str.extract
특정 column에서 정규식과 일치하는 문자열을 추출할 때 사용한다. 사용 예시는 다음과 같다.
example_data.column_1.str.extract('(\d+)')❗ 참고사이트:
Pandas official .str.extract
4. .astype
열의 요소의 dtype을 변경하는 함수이다.
df.astype(dtype, copy = True, errors = 'raies')
dtype: 변경할 type이다.
copy: 사본을 생성할지 여부이다.
errors: {'raies','ignore'}:변경불가시 오류를 발생시킬 여부입니다.
copy를 False로 설정할 경우 원본 데이터의 값이 변경되어, 원본 데이터를 사용해 생성된 객체의 데이터도 변경되기 때문에 False를 설정할땐 유의해야 한다.
❗ 참고사이트:
python 완전정복 시리즈 .astype
5. .pad
.pad는 .fillna와 동일한 명령어이다. 문자열 형식이 정해져있어서 길이가 부족할 경우 채워 넣을 때 사용한다.
# 문자열 길이 20자, 왼쪽부터 "_"로 채우기
df['법정동명'].str.pad(width=20, side='left', fillchar='_').head(10)위의 Code는 .pad의 사용예시이다. 길이는 width, 방향은 side부터, fillchar에 부여된 문자로 채운다.
.str.pad의 경우 특정 문자열을 변경할 때 사용되며 대표적인 예시는 다음과 같다.
s.str.pad(width=10, side='right', fillchar='-')
두 명령어 모두 side의 default값은 left, fillchar의 default는 공백이다.
6. .isin()
Dataframe의 각 요소가 값에 포함되는지 여부를 판단하여 bool값으로 이루어진 dataframe을 반환한다.
Dataframe.isin(values)values에는 iterable, Series, DataFrame or Dict type의 data가 들어갈 수 있다.
❗참고사이트:
Pandas official .isin()
7. math.isnan()
데이터를 다룰 때 중요한 부분 중 하나는 null,NaN,None등의 값을 다루는 것이다.
어떤 데이터가 null값일 때에는 다른 숫자를 return한다던지, Pandas DataFrame의 어느 위치의 값이 NaN이면 해당 위치에 다른 값을 집어넣는다던지, 어떤 변수에 할당된 값이 NaN이라면 다른 값을 해당 변수에 재할당한다던지 등의 상황이 상당히 자주 발생한다.
NaN값은 모든 값과 다르다는 결과를 내놓기 때문에 단순한 등호==로는 NaN값을 테스트하는 것은 추천되지 않는다. 그래서 python에서는 math.isnan(), .isnan을 사용한다.
NaN일 경우 True, 아니면 False를 반환한다.
❗ 참고사이트:
python math.isnan() Method
8. re.sub
정규표현식을 이용하여 원하는 형태로 데이터를 수정할 때 사용한다. replace()와 비슷하나 replace()는 단지 어떤 문자를 다른 문자로 대체한다면, re.sub는 정규표현식을 이용하여 표현한 패턴에 맞는 문자를 대체한다.
❗ 참고사이트:
re.sub 정리 blog
9. .enumerate()
반복문 사용 시 인덱스를 확인하기 위하여 사용하는 명령어이다. 인덱스 번호와 컬렉션의 원소를 tuple형태로 반환한다.
t = [1, 5, 7, 33, 39, 52]
for p in enumerate(t):
print(p)실행결과:
(0, 1)
(1, 5)
(2, 7)
(3, 33)
(4, 39)
(5, 52)
❗ 참고사이트:
파이썬의 enumerate()내장함수로 for루프 돌리기
10. pd.melt()
pandas.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None, ignore_index=True)id_vars변수를 기준으로 원래 데이터셋에 있던 여러개의 columns을 var_name이라는 이름을 가지는 column을 생성하여 value_vars에 입력된 데이터를 넣어준다. 이때 value_vars에 입력된 column의 원래의 value들은 value_name이라는 이름을 가진 column에 부여된다.
이런 과정을 거쳐 데이터프레임을 재구조화하는 명령어이다. 글로는 이해가 잘 가지 않으니 Code와 그 실행예제를 살펴보자.
df_clean = pd.melt(df_clean, id_vars =['Series_Title','Released_Year','Certificate','Runtime', 'Genre','IMDB_Rating','Meta_score','Director','No_of_Votes','Gross'],
value_vars = ['Star1','Star2','Star3','Star4'],
var_name ='Stars',value_name = 'Star_name')
df_clean = df_clean.sort_values(by = ['Series_Title','Stars'])
df_clean.tail()위 코드를 실행하게 되면 원래의 데이터가 다음과 같이 바뀌게 된다.
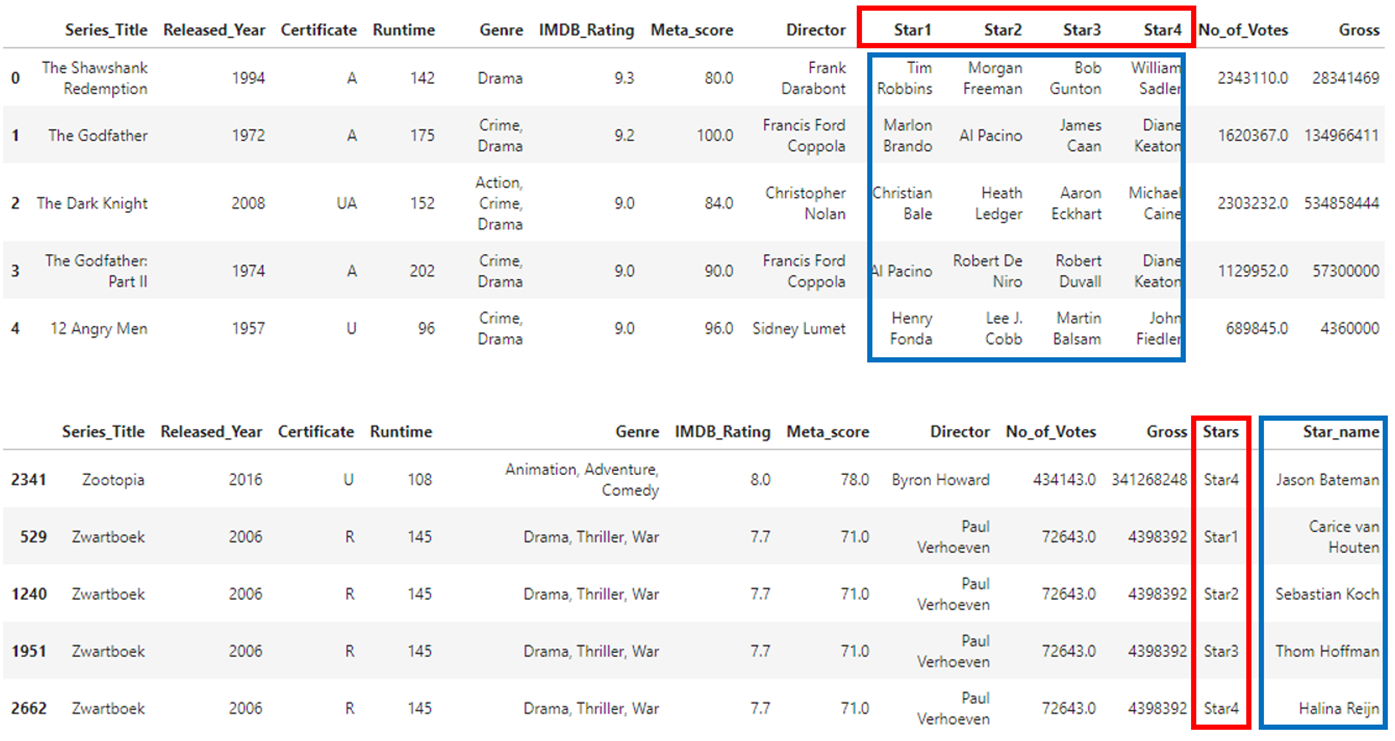
❗ 참고사이트:
pandas official pd.melt
11. subset = [ ]
subset을 duplicated와 같은 명령와 같이 사용하면 subset에 부여된 리스트 안의 값들만 출력하여 연산한다.
example[example.duplicated(subset = ['aaa','bbb']위 코드를 설명하면 exmple이라는 데이터프레임에서 aaa와 bbb column에 담긴 두 정보가 중복되는 row만 출력한다.
12. .str.strip()
입력된 문자 집합에 대하여 column안의 value가 포함하고 있을 경우 삭제한다.
example['exam_col'].str.strip('_')문자열을 입력하지 않을 경우에는 공백을 제거한다.
❗ 참고사이트:
pandas official Series.str.strip
13. .str.split()
.str.split(pat = None, n = -1, expand = False, *, regex = None)pat: 분할할 정규표현식, 지정하지 않으면 공백으로 나눈다.
n: 출력의 분할 수를 제한한다. 0이나 -1은 모든 분할을 반환하는 것으로 해석한다.
expand: True인 경우 DataFrame을 반환, False인 경우 Series를 반환한다.
regex: True인 경우 전달된 패턴이 정규식이라고 가정한다. False일 경우는 literal 문자열로 처리한다.
DataFrame의 문자열 column을 분할할 때 사용한다. for 구문보다 속도가 빠르다는 장점이 있다.
❗ 참고사이트:
DataFrame의 문자열 칼럼을 분할
14. .merge
merge()는 두 데이터프레임을 각 데이터에 존재하는 고유값(key)을 기준으로 병합할 때 사용한다.
DataFrame.merge(frame, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)how: 병합 방법을 의미한다. inner,outer,right,left 총 4개의 방식이 있다.
on: 병합하고자 하는 두 프레임 모두에 있는 인덱스나 column명이다. 이를 기준으로 병합하게 된다.
다른 변수들은 그때그때 아래의 주소를 참조하여 사용하면 된다.
❗ 참고사이트:
pandas official DataFrame.merge
15. apply()
전체 데이터 프레임 혹은 특정한 column의 값들을 사용되는 함수에 따라서 일괄적으로 변경시키고자 할 때 사용하는 함수이다.
Dataframe.apply(func, axis = 0, raw =False, result_type = None, args =(),**kwargs)❗ 참고사이트:
Apply 함수란?
16. map()
주어진 iterable의 각 항목에 주어진 함수를 적용한 후 결과의 map객체를 반환한다.
map(func,iter)map은 인덱스에 따라서 값을 전환하는 기능이므로 데이터프레임에서는 사용할 수 없고, series에서만 사용할 수 있다.
데이터프레임에서는 map을 하고 싶다면 join과 replace로 대체한다.
❗ 참고사이트:
함수 적용하기(apply,map,applymap)
17. applymap()
applymap은 apply와 형식은 비슷한데 접근하는 개체가 개별적이다. 즉, 각 원소에 lambda를 적용하는 경우이다. 하나하나의 원소에 접근하기 때문에 Series에 한번에 사용하는 메서드와 함께 사용하면 오류가 발생할 수 있다.
3. 추가 공부 내용
1. .fillna
결측치를 다른 값으로 치환하여 주는 명령어이다.
❗ 참고사이트:
결측값 채우기
2. ~
논리 연산자로 not을 의미한다. 변수 할당 시 bool로 구성된 data 앞에 ~을 붙히면 반대의 값을 출력한다
❗ 참고사이트
파이썬 and, or, not 논리연산자
회고
N11x의 수업은 오늘로 마무리 되었다. 내일은 1주차 sprint challenge이다. N11x의 경우 Data의 수집 및 정제, 가공에 대해서 중점적으로 학습한 것 같다. 과제는 쉽게 풀 수 있었지만 다른 사람들이 짠 Code를 보면 아직 많이 부족한 것 같다. 확실히 수치해석 같은 과제하면서 내마음대로 반복문, 조건문, 함수를 너저분하게 만들었던 버릇이 이어지는 것 같다. 앞으로는 과제를 하면서 긴 문장은 피하도록 많은 라이브러리 메서드와 모듈, 함수 등을 이용하는 방법을 연습해야겠다.
