0. 학습목표
- 공분산, 상관계수의 목적과 차이점을 설명할 수 있다.
- Vector transformation에 대해서 이해한다.
- eigenvector / eigenvalue를 설명할 수 있다.
- linear projection에 대해서 이해한다.
- High dimensional data의 문제점을 이해하고, 이를 handling 하기 위한 방법을 설명할 수 있다.
- PCA의 목적과 기본원리를 설명할 수 있다.
1. 주요개념
1. 공분산(Covariance)
공분산은 2개의 확률변수의 상관 정도를 나타내는 값이다. 실수값을 지니는 2개의 확률변수 X와 Y에 대해서 공분산의 기댓값을 다음과 같이 정의 할 때,
위 식을 풀어서 정리하면 아래와 같은 식이 된다.
이때,만약 X,Y가 독립이면 공분산은 0이 되고, 아래와 같이 나타낼 수 있다.
즉, 공분산은 확률변수들의 벡터 공간상에서의 내적을 의미한다.
이러한 공분산으로 이루어진 행렬을 공분산 행렬이라고 한다. 공분산 행렬은 일종의 행렬로써, 데이터 구조를 설명해주며, 특히 특징 쌍(Feature pairs)들의 변동이 얼마나 닮았는가를 행렬에 나타내고 있다.
공분산은 단순한 상관관계의 방향만을 알려준다.
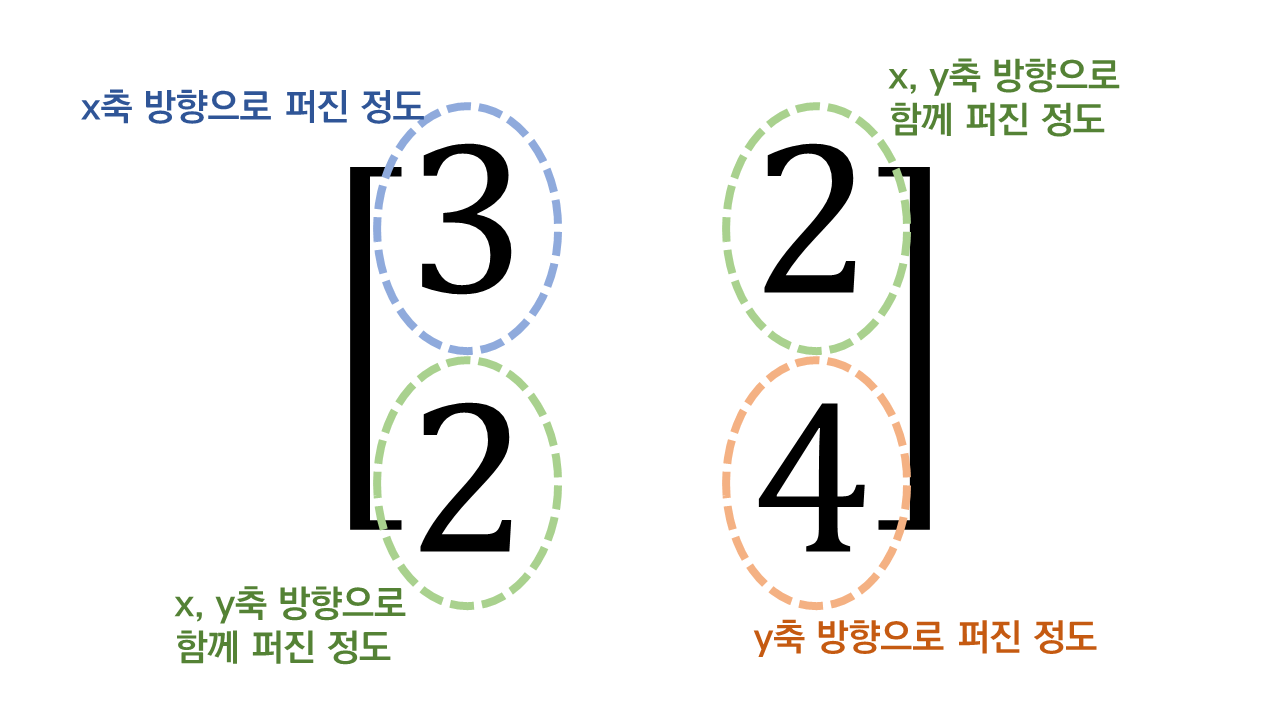
공분산의 기하학적 의미를 알아보자. 행렬이란 선형 변환이고 하나의 벡터 공간을 선형적으로 다른 벡터 공간으로 Mapping하는 기능을 가진다.
즉, 조금 다르게 말하면 우리는 지금의 데이터의 분포에 대해서
"원래의 데이터가 선형변환에 의해 변환된 결과로써 보자"
라는 관점에서 데이터를 보고자한다.
공분산 행렬의 수식적 의미를 알아보자. 공분산 행렬은 2변량 이상의 변량이 있는 경우에 여러 개의 두 변량 값들 간의 공분산을 행렬로 표현한 것으로 정의하고 있다.
2. 상관계수(Correlation coefficient)
공분산은 단위 크기에 영향을 많이 받는다. 이러한 문제점을 해결하기 위하여 데이터의 절대적 크기에 영향을 받지 않도록 공분산을 단위화 시킨 것을 상관계수라고 한다.
즉, 공분산에 각 데이터의 분산을 나누어 준 것이다. 다시 말하면, 공분산을 정규화 시키면 상관관계를 알 수 있다.
상관계수의 절댓값은 1을 넘지 않으며, 두 확률변수 X,Y가 독립이면 상관계수는 0이다.
이외에도 피어슨 상관계수,스피어만 상관계수를 구할 수도 있다.
3. Vector transformation
2차원의 공간에서 벡터를 변환하는 것, 즉, 선형 변환은 임의의 두 벡터를 더하거나 혹은 스칼라 값을 곱하는 것을 의미한다.
다른 말로 표현하면, Transformation은 matrix를 곱하는 것을 통하여 벡터를 다른 위치로 옮긴다고 할 수 있다.
4. The Curse of Dimensionality(고차원의 저주)
고차원 데이터는 변수가 매우 큰 데이터를 의미한다. 단순하게 관측치를 설명하는 변수의 수가 많다는 것을 데이터에 대한 정보량이 그만큼 많다는 것을 의미하므로 데이터 분석 측면에서 긍정적으로 생각할 수 있다. 그리고 이에 따라서 데이터분석의 결과 역시 좋을 것으로 기대할 수 있다.
하지만 실제로 고차원 데이터는 시각화를 통한 개괄적인 데이터의 관계를 파악하기 쉽지 않으며, 저차원의 데이터 분석방법을 그대로 사용하기에 적합하지 않아 다루기 어렵다.
차원이 커질수록 필요한 데이터 공간의 크기는 지수적으로 증가한다. 그리고 이 확장된 공간을 채우기 위한 데이터의 수 역시 직관적으로 지수적으로 증가할 것이라 예측할 수 있다. 필요한 데이터의 지수적인 증가는 현실적을 처리하기가 어렵다. 이러한 불가피한 경우를 The Curse of Dimensionality(고차원의 저주)라고 한다.
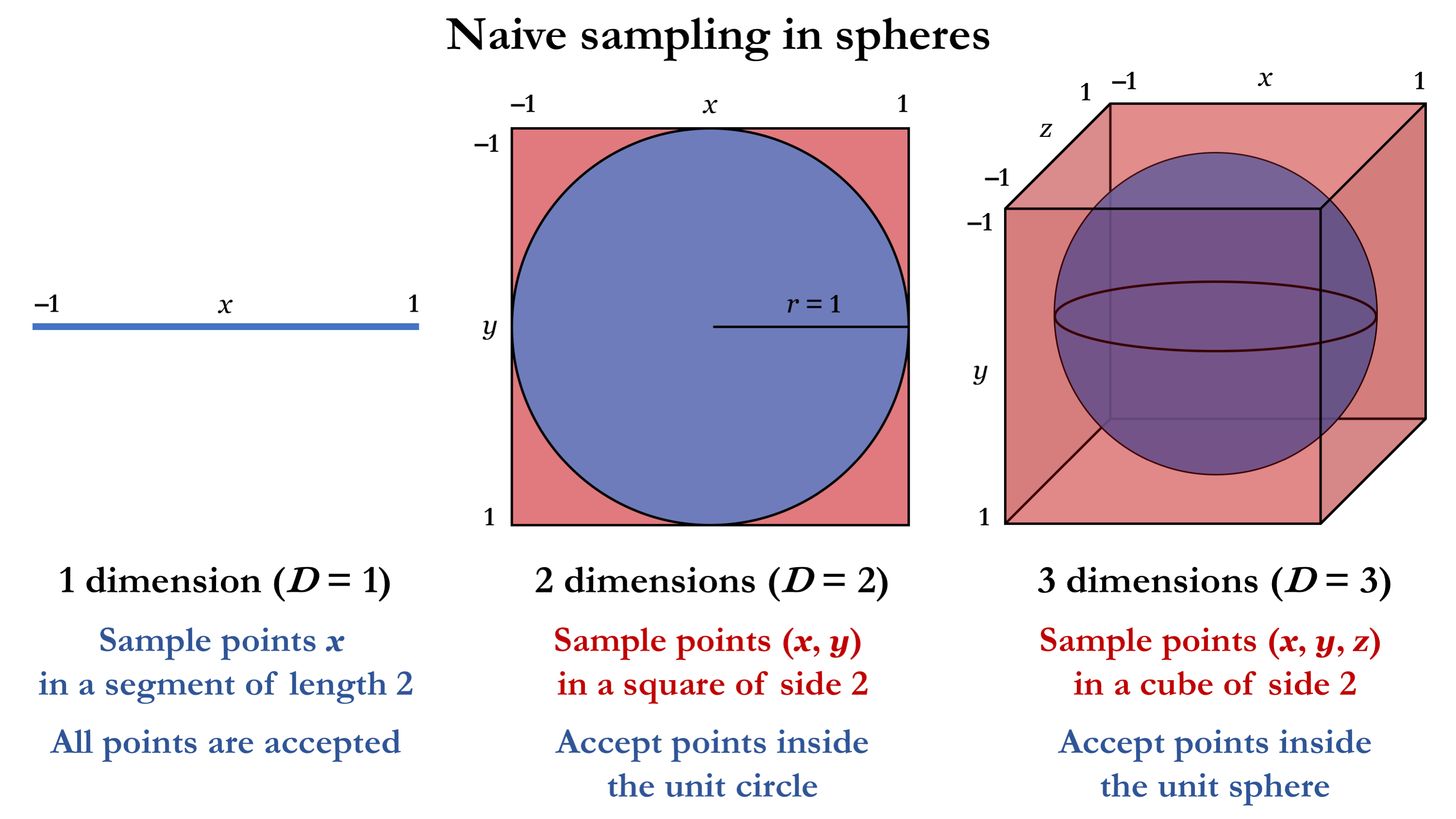
수학적으로 차원이 무한히 커진다면 초입방체(hypercube)와 초구(hypersphere)의 부피 비율은 0으로 수렴한다. 즉, 다차원 공간에서 대부분의 데이터는 데이터 공간의 표면에 가깝게 위치한다. (사실 뭔소린지 모르겠다.)
5. Dimensionality Reduction(차원 축소)
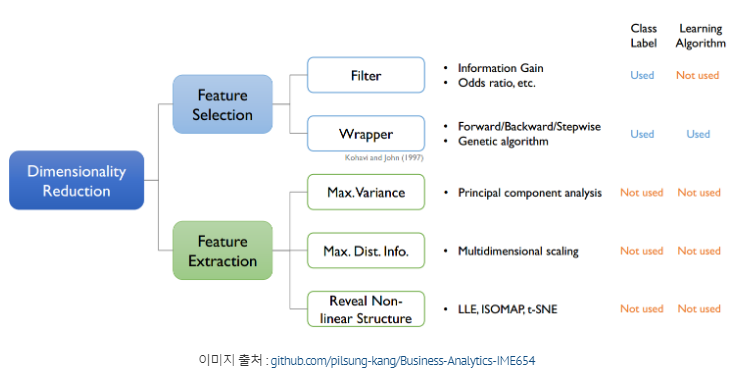
고차원 원본 데이터의 의미 있는 특성을 이상적으로 원래의 차원에 가깝게 유지할 수 있도록 고차원 공간에서 저차원 공간으로 데이터를 변환하는 것을 의미한다.
직관적으로 변수를 줄이는 것을 의미한다고 생각하면 된다.
차원 축소는 기계학습 측면에서는 차원축소가 앞 서 언급한 차원의 저주를 피하고, 과적합을 방지하는데 효과적이다. 또한 더 나은 성능의 모델과 더 빠른 모델을 만들기 위해 사용한다.
5-1. Feature selection(차원 선택)
특징 랭킹(Feature Ranking) 또는 특징 중요도(Feature Importance)라고도 한다. 특징 선택의 목적은 모든 특징의 부분 집합을 선택하거나, 불필요한 특징을 제거하여 간결한 특징 집합을 만드는 것이다.
이런 특징선택은 분석자가 사전의 배경 지식을 이용해서 진행할 수도 있지만, 자동 특징 선택 (automatic feature selection methods)을 사용할 수도 있다. 해당 방법들은 특징 중 몇 개를 제거해 보고 개선된다면 성능을 확인해보는 방법이며 이것은 대부분의 특징 선택 알고리즘의 기본 동작방식이다.
- 간단하거나 무시할 수 있는 피처를 사용하지 않는 방식
- 장점 : 선택한 피처의 해석이 용이하다
- 단점 : 피처의 상관관계를 고려하기 힘들다
❗ 방식
1. Filter methods
2. Wrapper methods
3. Embedded method
5-2. Feature extraction(차원 추출)
특징 추출이 특징 선택과 다른 점은 원본 특징 들의 조합으로 새로운 특징을 생성하는 것이다. 고 차원의 원본 feature 공간을 저차원의 새로운 feature 공간으로 투영시킨다. 새롭게 구성된 feature 공간은 보통은 원본 feature 공간의 선형 또는 비선형 결합이다.
기존 변수들과 완전히 다른 값을 가지게 되어 추출된 변수의 해석이 어렵다는 단점이 있다.
- 기존의 피처들로 새로운 피처를 생성하며 피처를 줄이는 방식
- 장점 : 피처 간 상관관계를 고려하기 용이하고 피처의 개수를 많이 줄일 수 있다
- 단점 : 추출된 변수의 해석이 어렵다
❗ 방법
1. PCA
가장 대표적인 차원 축소 기법으로 여러 특성간 존재하는 상관관계를 이용하여 대표하는 주성분을 추출해 차원을 축소하는 기법이다.
2. LDA
PCA에서 확장된 차원 축소 기법으로 지도학습에서 적용하는 차원 축소 기법이다. 입력 데이터의 클래스(정답)를 최대한 분리할 수 있는 축을 찾아 차원을 축소하는 방법이다.
3. t-SNE
고차원 상의 이웃 간의 거리를 저차원 상에서도 최대한 보존하도록 차원을 축소하는 방식이다. 먼저 무작위로 차원에 데이터들을 배치한 후 각 데이터를 고차원 상에서 배치와 비교하면서 위치를 변경하여 학습하는 방법이다.
6. PCA(Principal Component Analysis,주성분 분석)
😏 PCA가 말하는 것!
"데이터들을 정사영 시켜 차원을 낮춘다면, 어떤 벡터에 데이터들을 정사영 시켜야 원래의 데이터 구조를 제일 잘 유지할 수 있을까?"
PCA는 가장 널리 사용되는 차원 축소 기법 중 하나로, 원 데이터의 분포를 최대한 보존하면서 고차원 공간의 데이터들을 저차원 공간으로 변환한다.
PCA는 기존의 변수를 조합하여 서로 연관성이 없는 새로운 변수, 즉 주성분(Pricipal Component,PC)를 만들어 낸다. 첫 번째 주성분이 원 데이터의 분포를 가장 많이 보존하고, 두 번째 주성분이 그 다음으로 원 데이터의 분포를 많이 보존하는 식이다.
주성분의 단위벡터는 데이터의 공분산 행렬에 대한 eigenvector이다.
PCA의 과정은 다음과 같다.
- 데이터셋을 불러온다.
- 데이터를 표준화한다. (※표준화의 의미는 아래에서 다룬다.)
- 표준화한 데이터셋의 공분산행렬 구하기
- 공분산행렬의 Eigenstuff(Eigenvalue+Eigenvector)구하기
- 데이터를 eigenvector에 projection하기
7. Normalization(정규화)와 Standardization(표준화)
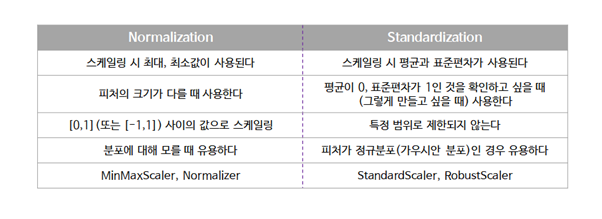
1. Normalization(정규화)
정규화의 목적은 데이터셋의 numerical value 범위의 차이를 왜곡하지 않고 공통 척도로 변경하는 것입니다. 기계학습에서 모든 데이터셋이 정규화 될 필요는 없고, 피처의 범위가 다른 경우에만 필요합니다. 특성 벡터의 길이는 상관없고 방향만이 중요할 때 많이 사용한다.
- 값의 범위(scale)을 0 ~ 1사이의 값으로 바꿔주는 것.
- 학습 전에 scaling하는 것
- 머신러닝에서 scale이 큰 feature의 영향이 비대해지는 것을 방지
- 딥러닝에서 Local Minima에 빠질 위험 감소(학습 속도 향상)
- scikit-learn에서
MinMaxScaler사용
min-max Normalization 수식:
단점: 이상치의 영향에 매우 취약하다.
2. Standardization(표준화)
데이터셋이 표준정규분포의 속성을 갖도록 피처가 재조정되는 것이다. 표준화 방법은 특성의 최솟값과 최댓값 크기를 제한하지 않는다. 즉, 이상치(outer)를 파악할 수 있는데, Z-score를 구함으로써 데이터가 평균으로부터 얼마나 떨어져 있는지 구한 다음, 특정 범위를 벗어난 데이터는 이상치로 간주하여 제거할 수 있다.
ex) 수학 시험과 영어 시험을 봤는데 수학 점수는 평균이 80점이고 표준편차가 20이었고, 영어 점수는 평균이 60이고 표준편차가 10였다. 이런 상황에서 자녀가 수학을 90점 맞았고, 영어를 80점 맞았다면 어떤 것을 더 칭찬해줘야 할까?
수학을 90점 이상 받는 것과, 영어를 80점 이상 맞는 것이 각각 상위 몇 %에 속하는 것인지 정규분포의 표준화를 이용해서 구할 수 있다. → 표준화를 통해 확률을 계산하여 판단 가능.
언제 정규화를 하고 표준화를 하는지 명확한 답은 존재하지 않는다. 통상적으로는 표준화를 통해 이상치를 제거하고, 그 다음에 데이터를 정규화 해 상대적 크기에 대한 영향력을 줄인 다음 분석을 시작한다.
둘 중 어떤 것이 더 나은지에 대해서는 판단하기 어려우며, Case By Case이다. 하지만 정규화나 표준화를 하지 않은 것과는 분석에 있어서 엄청난 차이가 존재하므로 해주는 것이 좋다.
2. 회고
하...어려웠다. 오늘 하루 솔직히 명령어도 복습해야하는데 지금 벌써 시간이 새벽 2시다. 자야한다. 명령어는 진짜 주말에 한 번 싸악 몰아서 정리해야할 것 같다. 그래도 개념들에 대해서 아직 두리뭉슬하지만 약간 잡힌거 같아서 기분은 좋다. 근데 SQL이랑 파이썬 공부는 언제하지...더 부지런해야겠다.
