
정말 오랜만에 벨로그 글을 작성하는 것 같다. 지난주에 프로젝트를 진행하느라 TIL할게 없었다. 빠른 시일내로 프로젝트 진행과정이랑 리뷰 정리해서 올려야 하는데...할게 너무 많아지는 느낌이다.
여하튼 이제 Section2로 들어왔다. Section2에서는 기본적인 머신러닝에 대해서 학습한다. 이제 시작해보자.
0. 학습목표
- 선형회귀모델을 이해한다.
- 지도학습(Supervised Learing)을 이해한다.
- 회귀모델에 기준모델을 설명할 수 있다.
- Scikit-learn을 이용하여 선형 회귀 모델을 만들어 사용하고 해석할 수 있다.
1. 주요개념
0. 머신러닝이란?
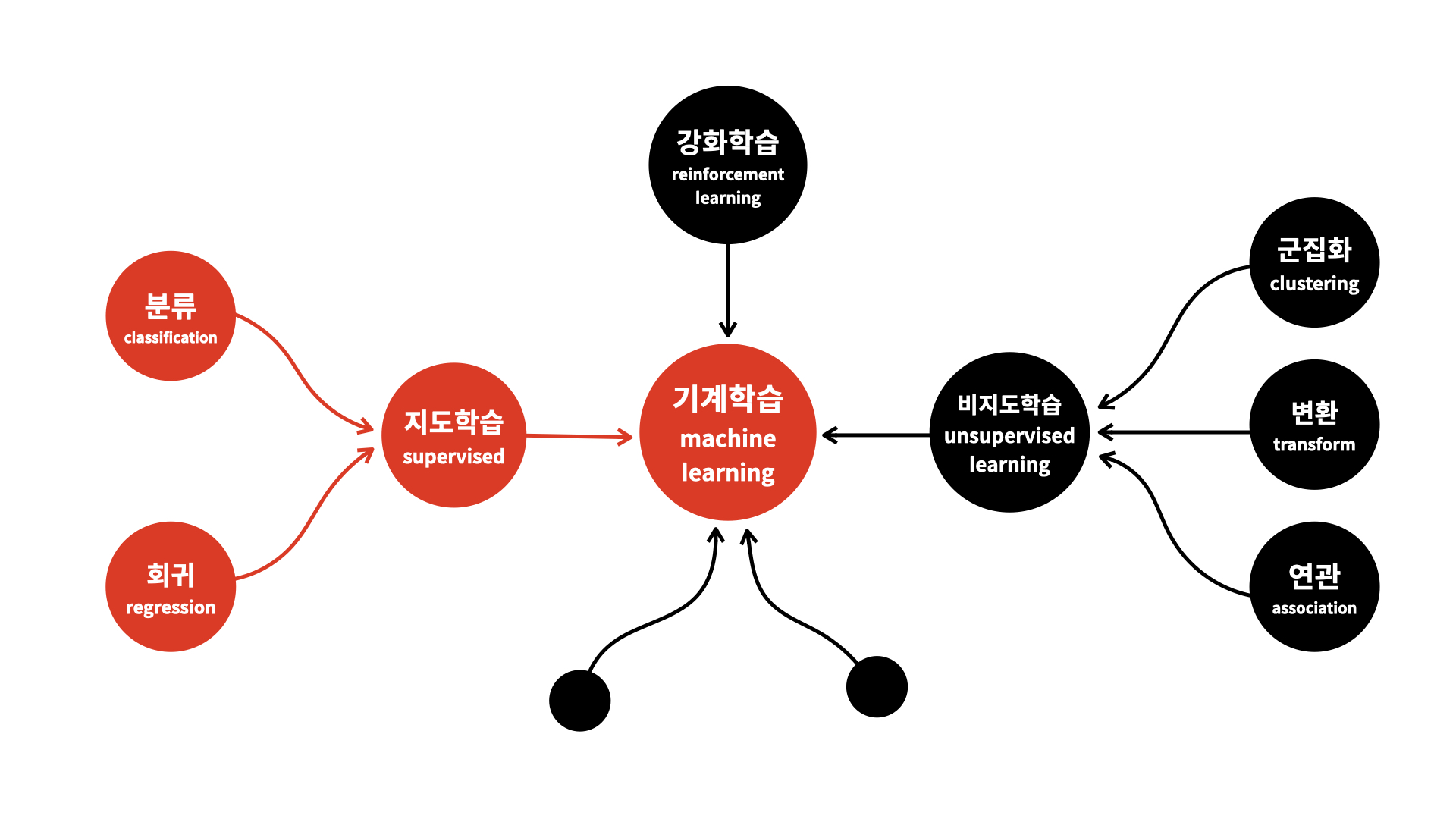 [출처1]:https://opentutorials.org/module/4916/28942
[출처1]:https://opentutorials.org/module/4916/28942
머신러닝(Machine Learning, 기계학습)이란 용어는 1959년, 컴퓨터 과학자 아서 사무엘(Arthur L. Samuel)이 처음 사용했다. 아서 사무엘은 머신러닝을 "컴퓨터가 명시적으로 프로그램되지 않고서도 학습할 수 있도록 하는 연구분야"라고 정의했다.
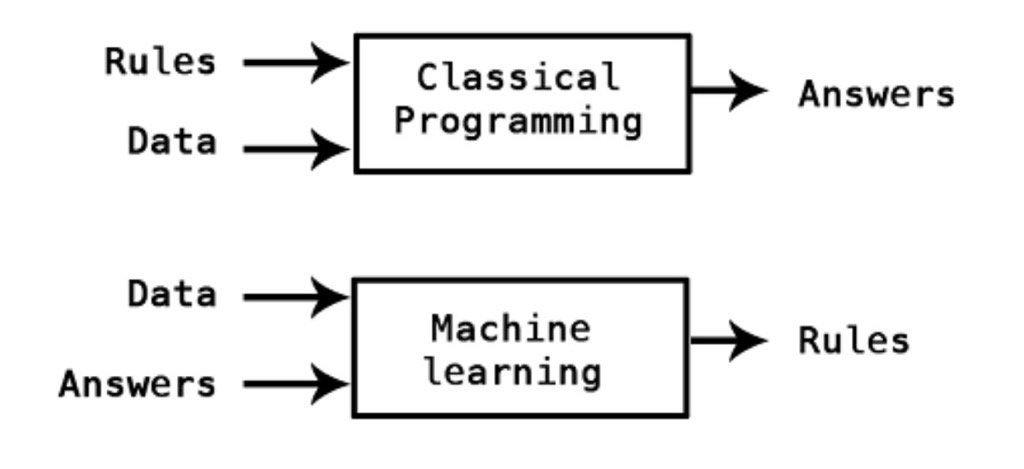
위의 사진에서도 볼 수 있듯이 기존의 프로그램은 'A라는 입력에 B라는 조건(규칙)이 성립하면 Y를 출력한다'를 전부 사람이 작성한다. 하지만 머신러닝은 'A라는 입력에 Y라는 출력이 정답이 되는 조건 B'를 기계가 찾을 수 있도록 학습시킨다.
즉, 정리하자면 기계가 직접 규칙을 찾도록 학습시키는 것을 머신러닝이라 할 수 있다.
💡 머신러닝의 종류
1. 지도학습
2. 비지도학습
3. 준지도학습
4. 강화학습
1. 지도학습(Supervised Learing)
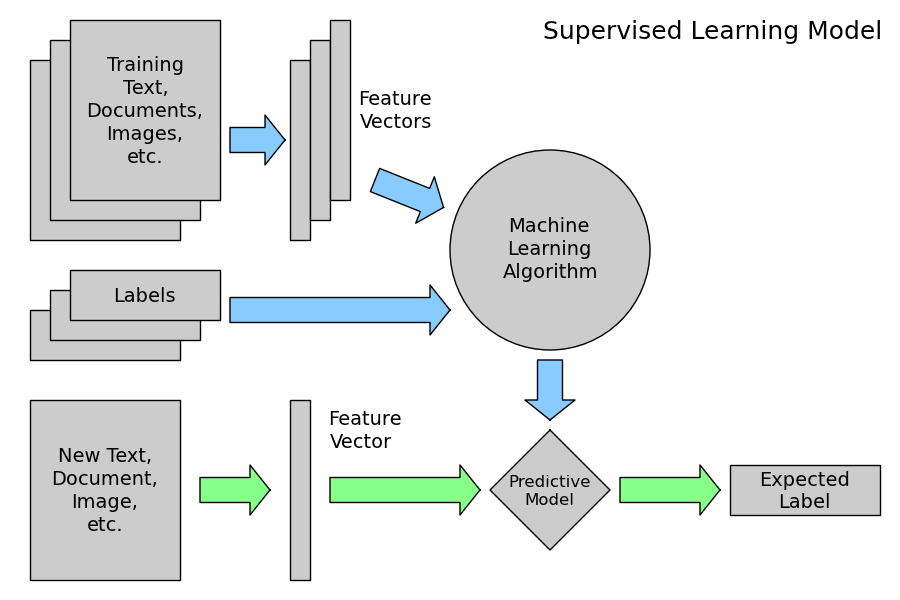
머신러닝의 한 분야로, 데이터에서 반복적으로 학습하는 알고리즘을 사용하여 컴퓨터가 어디를 찾아봐야 하는 지를 명시적으로 프로그래밍하지 않고도 숨겨진 통찰력을 찾을 수 있도록 하는 데이터 분석 방법이다. 지도 학습은 기계가 학습하는 방법 중 하나이다.
지도학습의 가장 큰 특징은 학습, 검정, test Data에 Labels(정답)이 존재한다는 것이다.
💡 지도학습의 종류
1. 분류(Classification)
2. 회귀(Regression)
1. 분류(Classification)
"가지고 있는 데이터에 독립변수와 종속변수가 존재하고, 종속변수가 범주형, 이산형 데이터일 때 분류를 사용한다."
이산 변수에 대한 입력 데이터를 분류하도록 알고리즘을 훈련하는 것을 말한다. 훈련 중에 알고리즘에는 Class레이블이 있는 훈련 데이터가 제공된다.
이진 분류, 다중 클래스 분류, 다중 레이블 분류 등 다양한 분류가 존재하지만 여기서 자세히 다루지는 않겠다.
2. 회귀(Regression)
"가지고 있는 데이터에 독립변수와 종속변수가 있고, 종속변수가 연속형 데이터일 때 회귀를 사용한다."
가능한 연속 값 범위에서 출력을 예측하도록 알고리즘을 훈련하는 지도학습 방법이다. 회귀에서 알고리즘은 입력 매개변수와 출력 사이의 기능적 관계를 식별해야 한다. 출력 값은 분류에서처럼 이산적인 것이 아니라 입력 매개변수의 함수이다. 회귀 알고리즘의 정확성은 정확한 출력과 예측된 출력 간의 분산을 기반으로 계산된다.
회귀에도 선형회귀, 로지스틱 회귀, 리지 회귀, 라쏘 회귀, 다항 회귀 등 다양한 회귀방법이 존재한다.
2. 선형회귀
독립변수(X)와 종속변수(y)의 선형상관관계를 파악하여 모델의 값을 예측하는 방식이다.
선형회귀 모델은 비교적 간단하며 예측을 생성하기 위한 해석하기 쉬운 수학적 공식을 제공한다. 선형회귀는 확립된 통계 기법으로 소프트웨어 및 컴퓨팅에 쉽게 적용할 수 있다는 장점이 있다.
선형 회귀 분석에서는 "잔차(Residual,예측값과 관측값의 차이) 제곱들의 합(RSS,residual sum of squares)"이 최소가 되는 직선의 방정식을 도출한다. 이 직선을 회귀선이라고 한다.
RSS는 SEE(Sum of Square Error)라고도 하며 이 값이 회귀모델의 비용함수(Cost function)이 된다. 머신러닝에서는 이 비용함수가 최소화하는 모델을 찾는 과정을 학습이라 한다.
이렇게 비용함수가 최소가 되는 직선 "회귀선"을 이용하여 값을 예측하는 방법을 선형회귀라고 한다.
3 회귀모델
회귀 모델을 한 마디로 정의하면 다음과 같다.
"어떤 자료에 대해서 그 값에 영향을 주는 조건을 고려하여 구한 평균"
즉, 어떤 주어진 조건(ex. OLS)에 따른 예측값을 구하는 함수를 회귀모델이라 한다.
이 회귀모델이 적절한 대푯값이 되려면 대상 데이터가 정규성을 만족해야한다. 이외에도 등분산성, 선형성, 독립성(다중선형회귀분석 시) 등 다양한 조건을 만족해야 한다.
여기서, 회귀 모형이 영향을 주는 조건을 고려하여 구한 평균이라고 하여서 전체 집단의 평균이라 생각하면 안된다. 조건부 평균이기 때문에 분포를 확인할 때도 전체 분포가 아닌 조건별 분포를 확인해야 한다.
회귀 분석을 통해 얻게 되는 회귀 모형이 의미하는 것은 x에 따라 달라지는 y의 조건별(x값 별) 평균이기 때문이다. 즉, 같은 x를 갖는 y들끼리만 모여 만들어진 분포가 각각의 x값마다 존재하는 모습니다. 따라서 회귀 모형에서 구한 평균이 적절한지 확인하려면 같은 조건(같은 x)을 갖는 값(y)들의 분포가 모두 종형 분포인지를 봐야한다.
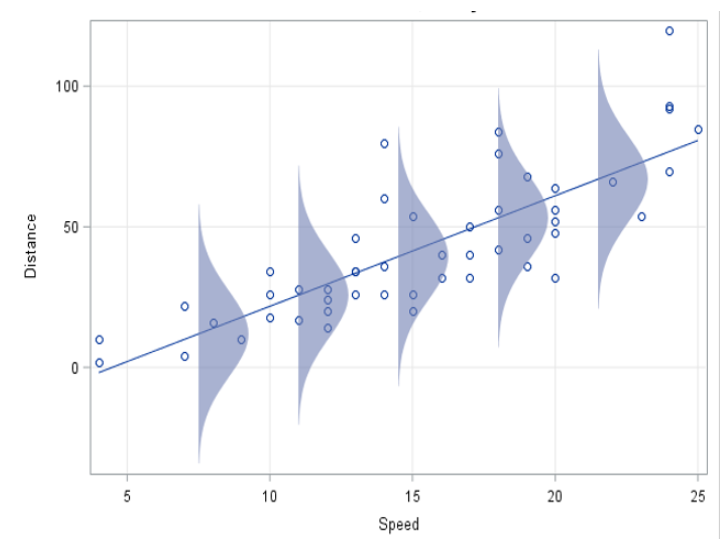 [출처2]: https://blogs.sas.com/content/iml/2015/09/10/plot-distrib-reg-model.html
[출처2]: https://blogs.sas.com/content/iml/2015/09/10/plot-distrib-reg-model.html
정리하여 설명하자면 잔차 분포가 정규성을 만족하면 된다.
그렇다고 잔차에 대한 정규성이 만족하지 않는다고 회귀 분석이 불가능하다는 것은 아니다. 실제 데이터 분석 시 모든 가정을 만족시키기 어렵고, 그러한 가정들을 모두 만족하는 모델은 거의 없다.
다만, 가정을 만족하지 못하는 모델의 신뢰도는 다소 낮을 수 있다. 따라서 분석 결과의 신뢰성을 검증하는 것이 반드시 필요하다.
1. 회귀모델의 기준모델(Baseline Model)
예측모델을 구체적으로 만들기 이전에 가장 간단하면서도 직관적이며 최소한의 성능을 나타내는 기준이 되는 모델을 기준 모델이라고 한다.
보통 회귀문제에서의 기준모델은 타겟(Target,Labels...)의 평균값을 사용한다.
2. 회귀모델의 예측모델(Predictive Model)
"Python에서는 Scatterplot에 가장 잘 맞는(best fit) 직선을 그려주면 그것이 회귀 예측모델이 된다."
회귀선을 이용하여 예측값을 계산하는 모델이다. 회귀분석에서 중요한 개념은 예측값과 잔차이다. 예측값은 예측모델이 추정하는 값이고, 잔차는 예측값과 관측값의 차이이다.
❗ Error(오차): 모집단에서의 예측값과 관측값의 차이를 의미
회귀선은 위에서도 말하였듯이 RSS를 최소화하는 직선을 의미하며, RSS를 최소화하는 방법 중 하나인 OLS에 대해서는 아래에 자세히 다루도록 하겠다.
5. RSS(Residual sum of squares)
RSS는 잔차제곱의 합 또는 SEE(Sum of Square Error)라고도 하며 이 값이 회귀모델의 비용함수(Cost function)이 된다. 머신러닝에서는 이 비용함수가 최소화하는 모델을 찾는 과정을 학습이라 한다.
6. OLS(Ordinary least squares,최소자승법)
RSS 식에서 계수 와 는 RSS를 최소화 하는 값으로 모델 학습을 통해서 얻어진다.
이렇게 잔차제곱합을 최소화 하는 방법을 최소제곱회귀 혹은 OLS(Ordinary least squares)라고 한다.
와 는 편미분을 사용하여 계산할 수 있다.
- 혹은 에 대한 1차 미분값이 0이다.
- 혹은 에 대한 2차 미분값이 양(+)이다.
위 두 조건을 모두 만족시키는 지점이 바로 RSS가 최소가 되는 지점이다. 자세한 식은 다음과 같다.
RSS 식
1번 조건.
위 식을 정리하여 주면 다음과 같다.
이 식을 정규 방정식이라고 한다.
2번 조건.
이 행렬이 양정치(Positive definite)행렬이 되어야 한다.
양정치란 과 을 만족시키는 것으로
즉 최소제곱법 OLS에서는 2번 조건을 모두 만족하는 것을 알 수 있다.
즉, 위의 정규방정식을 풀면 오차제곱합을 최소로하는 해 를 구할 수 있다.
이것이 최소제곱법을 이용하여 추정한 가 된다.
2. 명령어
1. pandas.set_option()
pandas에서 다양한 옵션을 설정할 수 있는 명령어이다.
# 최대 출력 행 개수 지정
pandas.set_option('display.max_rows', n)
# 최대 출력 열 개수 지정
pandas.set_option('display.max_columns', n)
pd.set_option('display.width', n)
# 출력 소수점 자릿수 설정 (n자리수 만큼 출력)
pandas.set_option('display.float_format', '{:,.nf}'.format)위의 예시 외에도 다양한 설정을 바꿀 수 있다.
2. seaborn.pairplot()
이변수 데이터의 분포에 대한 그래프를 출력한다.
인자로 전달되는 데이터프레임의 열(변수)들을 두 개씩 짝 지을 수 있는 모든 조합에 대해서 표현한다. 이때, 각 열의 data type은 정수 또는 실수형 데이터여야 한다.
각 그리드에는 두 변수 간의 관계를 나타내는 그래프를 하나씩 그리며, 같은 변수끼리 짝을 이루는 행렬의 대각선 요소에는 히스토그램을 그린다. 그 외에는 산점도를 출력한다.
seaborn.pairplot(data,hue='parameter',palette='???',
markers=['?','?'],vars=['보고싶은 칼럼들'],
height= '크기조절(정수)',
corner= boolean(True=대각선 기준 아래, False = 대각선 기준 위))3. seaborn.regplot()
Scatter plot과 line plot을 동시에 그려준다. 이때 line은 선형 회귀 모델을 통해 적합된 직선이다.
seaborn.regplot(data=None, x=None, y=None,....)자세한 내용은 seaborn.regplot의 공식문서를 참조하자.
4. Library: sklearn.linear_model.LinearRegression
1. LinearRegression()
OLS를 사용한 선형회귀 모델을 사용하기 위한 명령어이다. .fit()명령어를 통해 데이터를 학습하고, 이를 이용하여 잔차 제곱합이 최소가 되는 모델을 생성한다.
model = LinearRegression()2. .fit()
데이터를 학습시키는 명령어이다. 입력변수로는 특성테이블과 타겟벡터가 있다.
model.fit(X_train,target)이때 입력되는 특성 데이블의 열 이름과 타겟벡터의 열이름이 동일하거나(사실 이건 안해봐서 무슨 말인지 모르겠음) 값만 추출하여 입력해주어야 warning message가 발생하지 않는다.
3. .predict()
생성된 모델을 이용하여 test value가 입력되면 그것에 대한 예측값을 반환하는 명령어이다.
model.predict(X_test)4. .coef_
생성된 모델의 회귀계수를 출력한다. 이때 회귀계수는 보통은 회귀직선의 기울기를 의미하는데, R의 경우(통계에 주로 사용되는 프로그래밍 언어)에서는 회귀직선의 기울기, 절편 두 개 모두 계수라고 출력된다.
model.coef_5. .intercept_
생성 모델의 함수의 절편을 출력한다.
model.intercept_5. Library: ipywidgets.interact
ipywidgets는 UI라이브러리로 함수를 전달하면 셀렉트 박스나 슬라이더의 조작으로 인수를 변경하면서 함수를 실행할 수 있게된다.
다른 말로 정리하자면 인터렉티브 위젯을 사용할 수 있게 해주는 라이브러리로 데이터를 제어하고 이에 따른 변경 사항을 시각화할 수 있는 라이브러이이다.
가중치를 바꾸어가면서 산점도의 변화를 볼수도 있고, 함수의 각 요소를 변경하면서 그 변화를 시각화 할 수도 있다.
3. 회고
이제 본격적인 머신러닝 학습이 시작됐다. 나도 내 자신을 맘대로 학습 못시키는데 내가 기계를 학습시킬 수 있을까?...그래도 뭔가 본격적으로 시작되는 기분이다. 시작한지 한 달만에 나의 코딩과 데이터 과학에 대한 밑바닥을 만난 거 같다.
진짜 지금까지는 말로만 시간을 아껴써야겠다. 아껴써야겠다 했는데 진짜, 진짜로 아껴 써야겠다. 일단 오늘 시간표를 알뜰하게 짜봐야겠다.
❗ 참고사이트
회귀모델: 회귀 모델에 대한 설명 velog주소
최소자승법: 최소자승법의 수식 설명
머신러닝: 머신러닝의 기초적인 내용 설명
pairplot: pairplot에 대한 설명
ipywidgets: ipywidgets에 대한 간단한 사용법 설명
모델 성능 평가지표: 모델 성능 평가지표에 대한 설명

대박 !!! ..본받고 갑니다..